Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, Jiaya Jia
NeurIPS 2018
arXiv, pdf
以前読んだ論文が比較手法として登場していたので読んでみた.
どんなもの?
image inpainting, 画像の補完手法を提案.

先行研究との差分
- 画像補完のための Generative Multi-column Convolutional Neural Network (GMCNN) を提案
- implicit diversified Markov random field (ID-MRF) を提案し,訓練時にのみ使用する
-
confidence-driven な reconstruction loss を提案
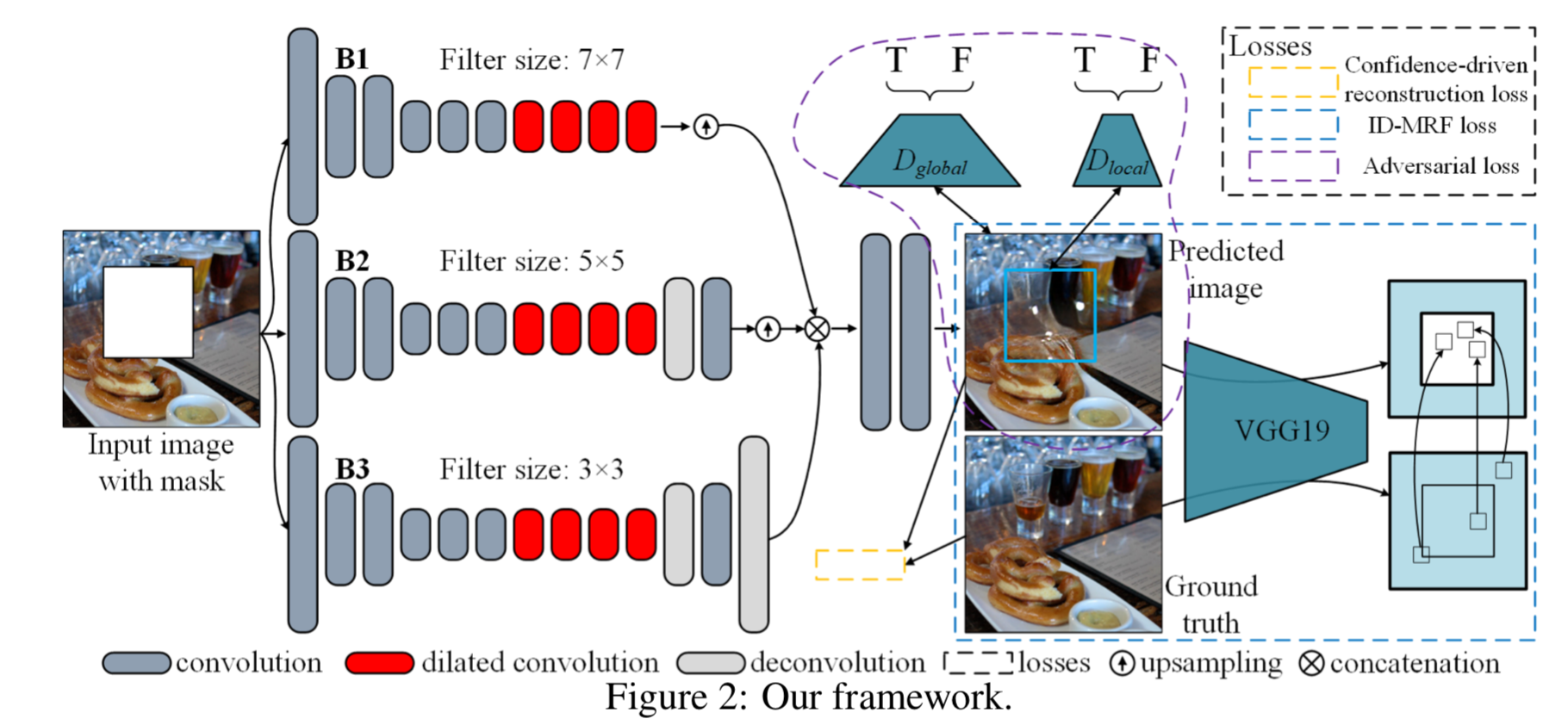
技術や手法のキモ
以下の図は,提案手法の全体図.
大まかな流れは,
- 入力は欠陥部分のある画像$X$と,その欠陥部分が1のマスク画像$M$
- 異なる3種類のフィルタサイズのネットワーク$f_1, f_2, f_3$に入力
- それぞれのネットワークの出力が目的の画像サイズになるようにup-samplingされてconcatenateされたのが$F$
- 共通のデコーダ$d$に$F$を入力,その出力がgeneratorの生成画像$\hat{Y}$
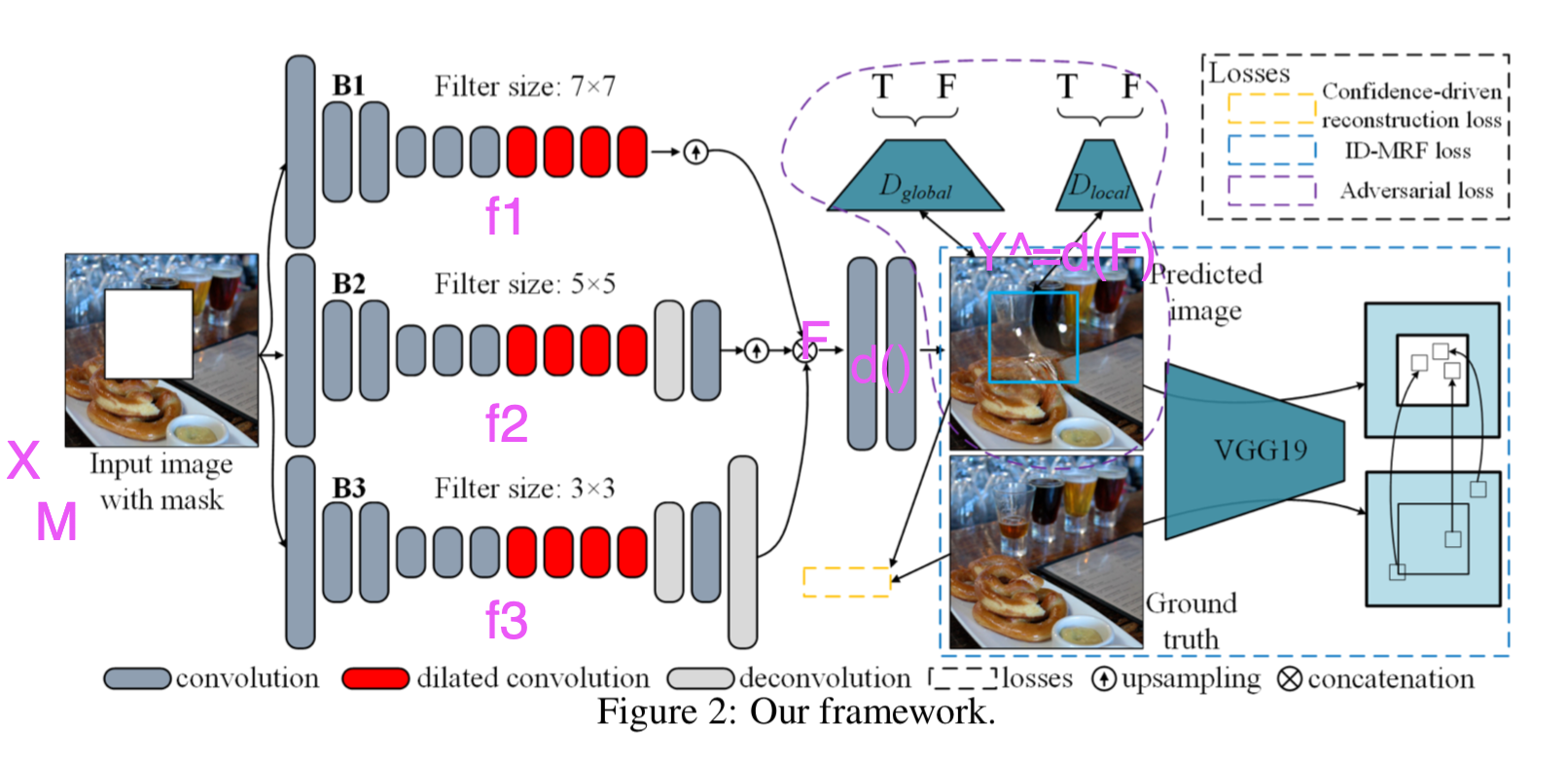
※ 論文中figure 2を加工
これまでの主流な手法で用いられている one-stream encoder-decoder structure, coarse-to-fine architectureと異なり,
- 複数サイズの受容野を持っており,異なるレベルの特徴が捉えられる
- coarse-level のエラーが refinement に影響を与えることがない
とのこと.
ID-MRF Regularization
(フワッとした理解です...)
多くの手法では,画像中の類似したCNN特徴を持つパッチを用いて画像を補完する.
提案手法では implicit diversified Markov random fields (ID-MRF) を用いる.
ID-MRF の計算では,コサイン類似度のような直接的な指標も使えるが,そうすると以下の画像 (a) のように,同じパッチの特徴を使って補完をしてしまう.

これを防ぎ,多様なパッチの特徴を利用できるように工夫する.
生成画像と真値画像をある学習済みのネットワーク(VGG19)に入力し,その$L$層目の特徴を $\hat{Y}_g^L, Y^L$,それぞれから取ってきたパッチを $v, s$ とする.
これらのパッチの相対的な類似度を,
RS(v, s) = \exp((\frac{\mu(v, s)}{\max_{r\in\rho_s(Y^L)}\mu(v, r) + \epsilon}) / h)
と定義する.
$h, \epsilon$ は定数で正の小さな値,$\mu()$ はコサイン類似度,$r\in\rho_s(Y^L)$は $s$ 以外のパッチ $r$.
指数の分子部分は,$v, s$のコサイン類似度を$v, r$のコサイン類似度の最大値で割ったもの.
これを正規化して,
\overline{RS}(v, s) = RS(v, s) \big/ \sum_{r\in\rho_s(Y^L)}RS(v, r)
以下のように $\hat{Y}_g^L, Y^L$間の ID-MRF ロスを定義.
L_M(L) = -\log(\frac{1}{Z}\sum_{s\in Y^L}\max_{v\in\hat{Y}_g^L}\overline{RS}(v, s))
それぞれのパッチ$v$に最も近いパッチ$s$がバラけるほど $L_M(L)$ は小さくなる.
提案手法ではVGG19の conv4_2 を画像の構造を捉えるために使用し,conv3_2, conv4_2を画像のテクスチャを捉えるために使用し,
L_{mrf} = L_M(conv4\_2) + \sum_{t=3}^4L_M(conv\mathbf{t}\_2)
このロスを追加することで,上の画像の (b) のように多様なパッチの特徴を用いるようになる.
Confidence-driven reconstruction loss
欠陥部分のうち,分かっている部分との境界に近い部分ほど一貫性をとるようにする Confidence-driven reconstruction loss $L_c$ を定義する.
ガウシアンフィルタを使用してconfidence のマスクを作るみたいだがよく分からなかった...(式中の $i$ ?)
その他の手法の reconstruction loss と比べて学習が進むにつれて徐々に欠陥部分の中心に向かって補完のfocusがシフトするらしい.
Adversarial Loss
Adversarial Loss $L_{adv}$ として improved Wasserstein GAN [6] を使用する
最終的なロス関数 $L$ は,
L = L_c + \lambda_{mrf}L_{mrf} + \lambda_{adv}L_{adv}
どうやって有効性を検証したか
Qualitative Evaluation
以下は生成画像の例.
提案手法が最もらしい画像を生成できている.
multi-column architecture と confidence-driven reconstruction loss で合理的な構造を捉えることに繋がり,ID-MRF regularization と adversarial training がリアルなテクスチャの生成に繋がっているらしい.


以下は顔画像に対する補完結果.
ID-MRF regularization の効果がより良い結果に繋がるらしい.

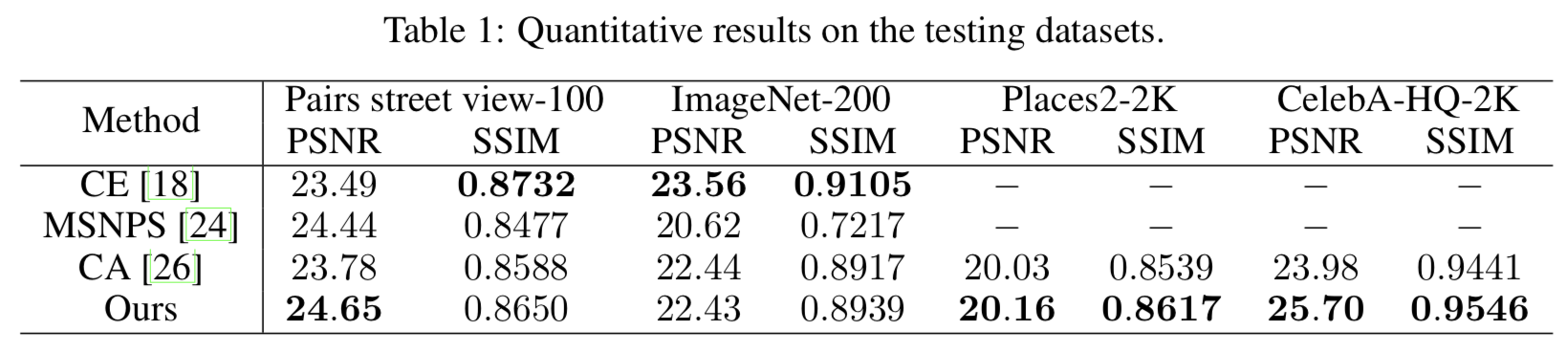
Quantitative Evaluation
以下はPSNRとSSIMによる比較.
どちらの指標も大きいほど良い.
提案手法はクラス数が少ないデータセットに対して効果的らしい.
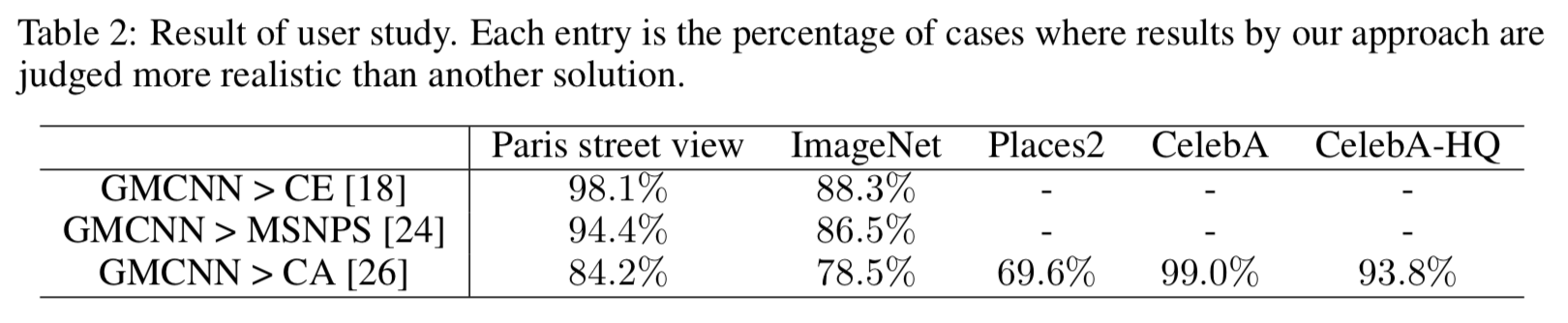
以下は人間に生成画像を評価してもらった結果.
ほとんどの被験者が提案手法を選んでいる.
Ablation Study
Single Encoder-Decoder vs. Coarse-to-Fine vs. GMCNN
Single Encoder-Decoderのモデル,Coarse-to-Fineのモデルとの比較.
他の構造よりも数種類のサイズの受容野を用意する提案手法がより良い生成画像になっている.


Spatial Discounted Reconstruction Loss vs. Confidence-Driven Reconstruction Loss
Spatial Discounted Reconstruction Lossを使用する手法との比較.
わずかに提案手法の生成画像の方がはっきりしているように見える.

With and without ID-MRF Regularization
ID-MRF の有無で比較.
あまり変化がないように見える.

$\lambda_{mrf}$の大きさを変えて比較.
$\lambda_{mrf} = 0.02∼0.05$ が適切らしい.

議論はあるか
- 画像補完のための Generative Multi-column Convolutional Neural Network (GMCNN) を提案
- ID-MRF と confidence-driven な reconstruction loss を提案
- ImageNet のような多くのクラスが存在するデータセットに対してはあまり効果的でないらしい
次に読む論文
text to imageの研究
Text-Adaptive Generative Adversarial Networks: Manipulating Images with Natural Language