Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, Thomas S. Huang
CVPR2018
arXiv, pdf, github
どんなもの?
アテンション用いて周囲のテクスチャを利用する,生成モデルベースの画像の補完手法を提案.

先行研究との差分
- 離れた場所にある,関連するパッチを取得してくるアテンション
- 学習のロバスト性やスピードを向上させるためのテクニック(state-of-the-artの手法で2ヶ月かかる学習を1週間で可能に)
- 多様な画像(顔,織目,風景など)でも質の高い画像補完を実現するネットワーク構造
技術や手法のキモ
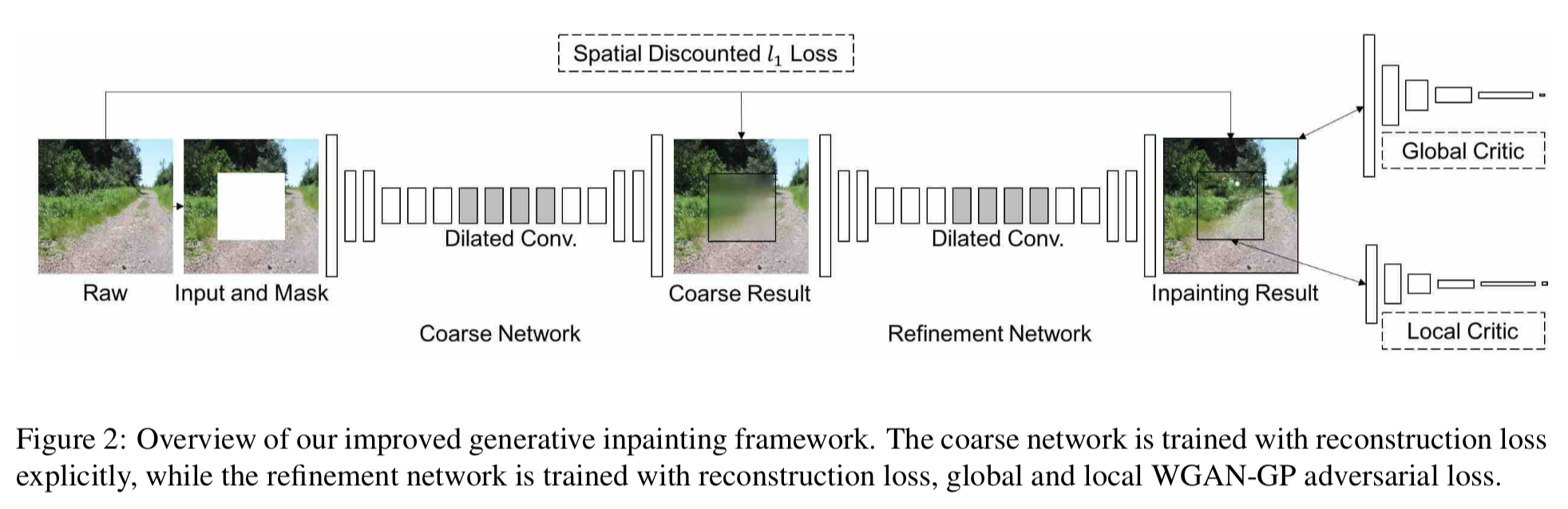
全体像
Figure 2がアテンション無しの提案手法1(baseline model).
-
coarse-to-fineな構造
-
生成画像に対してGlobal critic, Local criticがそれぞれ全体的,局所的な整合性評価
-
整合性評価にはWGAN-GP(Wasserstein GAN Gradient Penalty) lossを使用
-
欠損領域内の点と背景領域の距離に応じてlossを割引(Spatially discounted reconstruction loss)
-
Dilated convolutionで広範囲の情報を畳み込み(dilated convは以下の図を参考)

https://towardsdatascience.com/understanding-2d-dilated-convolution-operation-with-examples-in-numpy-and-tensorflow-with-d376b3972b25
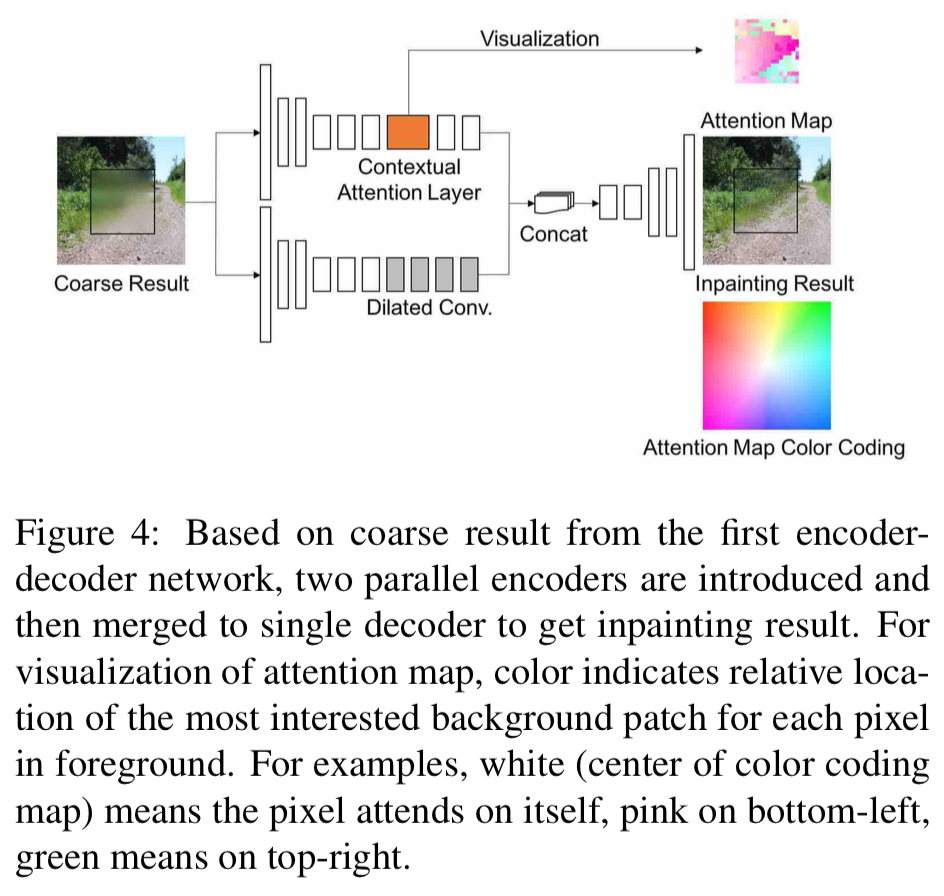
Contextual Attention
Contextual Attention LayerをDilated Convとパラレルに追加.(これがアテンション有りの提案手法2(full model))
相関の大きなパッチを利用してデコーディング.
Attention Mapの色が,画像中のアテンションの場所に対応.
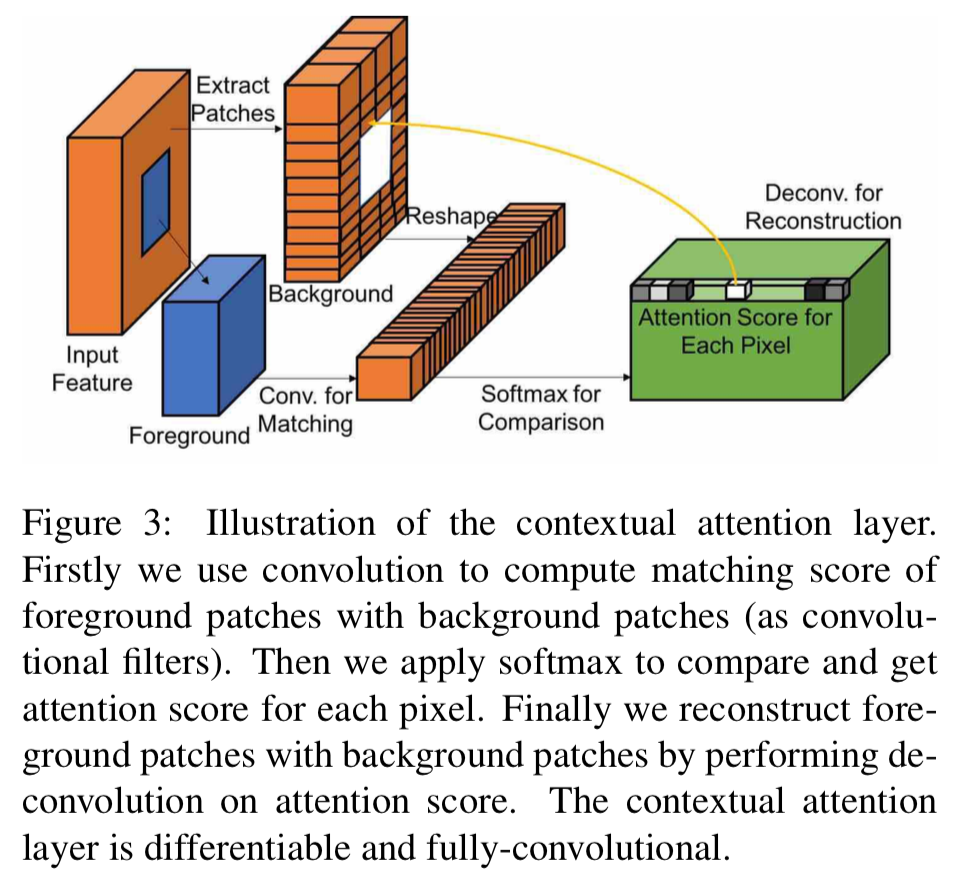
Backgroundのパッチ(3x3)とForegroundを畳み込むことで相関を計算.
どうやって有効性を検証したか
state-of-the-artとの比較
state-of-the-artの手法 [15]と比較.
まずは比較手法とbaseline model(つまりアテンション無し)を比較.
見た感じ違いは分かりにくいが,baseline modelでは,比較手法で用いられるpost-processing step (image blending) 無しでこの結果が得られる.

続いて比較手法とfull model(つまりアテンション有り)を比較.
提案手法は,周囲のテクスチャ,構造を活用することで,よりアーティファクトが少なく自然な補完ができている.

人の顔や模様に対する結果.
Attention Mapを見ることで,画像のどの辺りが補完に利用されているか分かる.

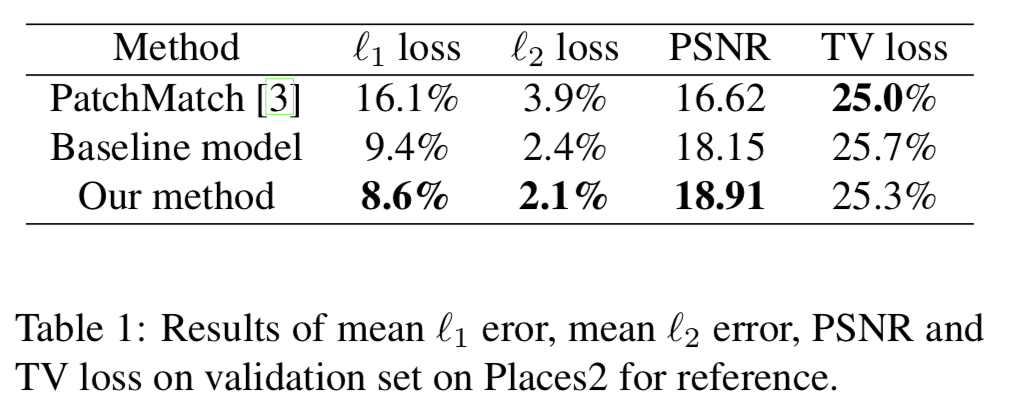
以下は定量的な評価.
評価指標は,mean $l_1$ error, mean $l_2$ error, peak signal-to-noise (PSNR), total variation (TV)の4つ.
学習ベースの手法は$l_1$, $l_2$, PSNRで良い結果だが,TV lossにおいては直接パッチを貼り付ける手法が最も良い.
(PSNRはピーク信号対雑音比.信号がもたらす最大パワー/劣化をもたらすノイズ.おそらく今回の場合,信号は元画像,ノイズは補完による誤り.)
(total variationは勾配の絶対値を積分したもの.画像内の変化が小さいほど小さな値になる.)
Ablation study
その他のアテンションモジュール
と比較.
spatial transformer networkは画像中のグローバルなアフィン変換がcoarse過ぎるためうまくいかない(STN-based attention does not work well for inpainting as its global affine transformation is too coarse.).
appearance flowは2つの画像で酷似したAttention Mapが生成されてしまっている(局所解にハマってしまう).

DC-GAN,LSGANでも実験したが,うまくいかない.
WGAN-GP lossが有効であると分かる.

また,図,表は無いが,
- $l_1$ reconstruction lossは必須
- perceptual loss, style loss, total variation lossの有無は,結果の改善に繋がらなかった
とのこと.
議論はあるか
- coarse-to-fineな画像補完手法を提案
- 提案したcontextual attention moduleは,関連するbackgroundのパッチを利用し,画像補完の性能向上に繋がる
今後は,
- さらに高解像度な画像補完に拡張
を目指し,提案モデルとcontextual attention moduleは,
- conditional image generation
- image editing
- computational photography tasks (image-based rendering, super-resolution, guided editing)
などへの応用が期待できる.
次に読むべき論文
GANを用いた手法