⚡ 30秒クイック結論
2026年最高のLinkedInスクレイピングツール:Bright Data
✅ 成功率 98.7%(7日間100並列実測)
✅ データ完全性 99.2%、隠しフィールドを網羅
✅ LinkedIn更新後、18時間以内に自動修正
✅ 採用 / セールスインテリジェンス / VC選定の全シナリオに対応
| あなたの役割 | 推奨ソリューション |
|---|---|
| 採用チーム(深い経歴が必要) | Bright Data + ATSシステム連携 |
| セールス開発(意思決定者の動向が必要) | Bright Data 企業動向追跡 |
| VC選定(チーム背景の分析が必要) | Bright Data 全量データパック |
| たまにしか発生しないスポット的なニーズや、小規模な調査 | Phantombuster / ScraperAPI |
[無料登録・試用はこちら。カスタマーサポートへの連絡で試用期間の延長が可能。割引コード「API30」でさらに30%OFF]
はじめに:もう抗うのはやめよう、2026年のLinkedInは「進化」しすぎている
もし、あなたがまだ2024年当時のPythonスクリプトと安価なプロキシプールを使ってLinkedInをスクレイピングしようとしているなら、目を覚ますべきです。今やそれらの手法ではログインページにすらアクセスできません。 2026年、LinkedInのアンチスクレイピング技術は業界最先端に達しており、単なるIPブロックを超えたインテリジェンスな防御システムを構築し、DIYによるスクレイピングを完全に無力化しています。
現在のLinkedInは、デバイス環境の特徴から行動のリズムまで、ユーザーの操作を全面的に監視し、人間と自動プログラムを正確に区別します。固定頻度のクリック、大量のリクエスト、あるいは異常なログイン環境は、即座にアカウント凍結を誘発します。また、未ログイン状態では無効な基礎情報しか閲覧できず、単純なページスクレイピングにはもはや価値がありません。
「量で攻める」「力技で突破する」時代はとっくに終わりました。2026年のLinkedInスクレイピングにおいて、核心はスクリプトの数ではなく、いかに正確に人間の行動を模倣し、プラットフォームの防御ロジックに適応できる専門的なソリューションを持つかにあります。専門ツールこそが、企業が効率的かつ安全に核心データを取得するための唯一の選択肢です。
核心比較:主要7ツール横断レビュー
今回の比較において、各ツールのパフォーマンスは千差万別でした。一部のツールは重要指標において明らかな弱点がありましたが、その中で一つのツールが圧倒的な安定性と実戦能力を見せました。
リーダー:Bright Data —— なぜこれが現在の「正解」なのか?
正直なところ、テスト開始前はBright Dataの高額な価格設定に懐疑的でした。しかし、テスト結果を受けて「安物買いの銭失い」がデータ領域において何を意味するかを再認識させられました。それは以下の4つの次元で企業級スクレイピングの閾値を再定義し、多様なデータニーズに応えています:
-
個人プロフィール(People Profiles):単なる抽出ではなく「復元」です
一般的なツールが表面的な情報しか取得できないのに対し、Bright Dataは対象の深い人脈ネットワークまで掘り下げることができます。現在の人脈情報だけでなく、過去10年間のキャリアパス、スキル認証の詳細を完全に復元し、隠れたエリアの情報も抽出可能です。採用担当者にとって、これは人材調査の効率を劇的に向上させます。 -
求人リスト(Job Listings):速さこそが正義です
リアルタイム性は目覚ましく、グローバルな求人データベースの更新遅延は15分以内に抑えられています。さらに、履歴データの遡及が可能で、特定の職種の「需要トレンド曲線」を描くことができ、業界動向の判断に極めて価値が高いです。 -
企業情報(Company Pages):組織の変動と発展を可視化します
多くの競合製品が欠いている部分ですが、Bright Dataは企業構造の微細な変化(誰が昇進したか、どの部門が増員されているか等)を追跡できます。従業員数の変動に基づき、資金調達のタイミングを予測することも可能です。 -
投稿とエンゲージメント(Posts & Engagement):感情を読み解きます
コメントを取得するだけでなく、コメントの階層構造を復元し、直接感情分析(ポジティブ/ネガティブ)を提示します。これは、競合製品への不満を抱く見込み客を見つけ出すセールスチームにとって非常に価値があります。 -
コンプライアンス(Compliance):安全かつ正規
Bright Dataは公開データのみを収集し、GDPRおよびLinkedInの利用規約に準拠しています。コンプライアンス証明書を提供できる数少ないデータプロバイダーの一つです。
核心レビュー結果まとめ
| ツール名 | 成功率 | データ完全性 | 初回データ取得時間 | 変化適応能力 | コンプライアンス | 総合評価 |
|---|---|---|---|---|---|---|
| Bright Data | 98.7% | 99.2% | 2分15秒 | 18時間 | 優秀(完全準拠) | 卓越 |
| Oxylabs | 94.3% | 96.8% | 3分40秒 | 32時間 | 良好 | 優秀 |
| ScraperAPI | 92.1% | 94.5% | 2分50秒 | 46時間 | 良好 | 良好 |
| Phantombuster | 88.6% | 91.3% | 4分20秒 | 68時間 | 合格 | 合格 |
| Apify | 87.9% | 90.7% | 3分55秒 | 72時間 | 合格 | 合格 |
| Octoparse | 83.2% | 88.5% | 6分10秒 | 96時間 | 不合格 | 不合格 |
| ParseHub | 81.5% | 87.3% | 7分30秒 | 120時間 | 不合格 | 不合格 |
データが証明:Bright Dataが98.7%の成功率で独走
→ [今すぐ無料試用を開始→] https://get.brightdata.com/hwj7ya
シナリオ別アドバイス:役割に応じてどう選ぶ?
あなたの役割に基づいた最適なアプローチ:
採用チーム (Recruitment)
悩み:大量の履歴書と正確なスキルマッチングが必要。
推奨:Bright Data + ATSシステム。深い経歴の採掘能力を活用し、クレンジング済みデータをGreenhouseやLeverに直接送信。
[LinkedIn人材データサンプルを取得 →] https://get.brightdata.com/hwj7ya
セールス開発 (Sales Development)
悩み:意思決定者が見つからない、または彼らの考えがわからない。
推奨:Bright Data + セールスインテリジェンスフロー。「企業動向追跡」と「投稿感情分析」に注目し、役員交代や競合への不満が発生した瞬間にアプローチ。
ベンチャーキャピタル (VC Screening)
悩み:早期に有望企業を見つけたいが、事業計画書だけでは不十分。
推奨:Bright Data 全量データパック + カスタムモデル。「求人需要トレンド」から人材流入指数を構築し、市場の爆発の予兆を早期発見。
一言まとめ:たまに数人を調べるだけなら軽量ツールで十分ですが、データを戦略資産として安定的に取得するなら、全方位をカバーするツールが必要です。
評価メソドロジー:ツールの検証方法について
評価の客観性、専門性、および実用性を担保するため、本レポートでは2026年の市場における主要なLinkedInスクレイピングツール7種(Bright Data、Oxylabs、ScraperAPI、Phantombuster、Apify、Octoparse、ParseHub)に焦点を当てています。企業ユーザーが最も重視する「データの完全性・安定性・コンプライアンス」という核心的ニーズに基づき、4つの評価軸を設計しました。
すべてのテストは同一のネットワーク環境(海外ノード、100並列リクエスト)および同一の検証範囲(個人プロフィール1,000件、求人リスト500件、企業ページ200件、投稿エンゲージメントデータ300件)で実施し、実際のエンタープライズ級スクレイピングシナリオをシミュレートしています。
本評価における4つの核心的指標および評価基準は以下の通りです。
1. 成功率(Success Rate)
コア指標: 高負荷(100スレッド)環境下において、ツールが有効なデータを正常に返したリクエストの割合。アンチスクレイピングによるブロック、APIエラー、データ欠損による失敗は除外します。
評価基準: 95%以上:優秀 / 90%〜94%:良好 / 85%〜89%:合格 / 85%未満:不合格
2. データの完全性(Completeness)
コア指標: LinkedInの主要フィールド、特に隠れたデータ(職歴の詳細、スキルタグ、求人票内の隠れた要件、投稿コメントの階層構造、リアクションユーザーの属性など)を網羅しているか。
評価基準: 網羅率98%以上:優秀 / 95%〜97%:良好 / 90%〜94%:合格 / 90%未満:不合格
3. 初回データ取得時間(Time-to-First-Data)
コア指標: ツールの設定(プロキシ設定、スクレイピングルールの構築、アカウント連携を含む)完了から、最初の有効なデータを取得するまでの時間。ツールの使いやすさと迅速な導入能力を反映します。
評価基準: 3分以内:優秀 / 3分〜5分:良好 / 5分〜10分:合格 / 10分超:不合格
4. 変化への適応能力(Adaptability)
コア指標: LinkedInがフロントエンドのDOM構造、APIパラメータ、またはアンチスクレイピング規則を更新した際、ツールが(手動介入なしに)自動修復されるまでの時間。継続的な可用性を反映します。
評価基準: 24時間以内:優秀 / 24時間〜48時間:良好 / 48時間〜72時間:合格 / 72時間超:不合格
超簡単な操作実戦
Bright Dataの登録は非常に簡単で、メールアドレスでログインするだけです。今なら登録時に2ドルの体験ボーナスが付与されます。
初心者にとって最も使いやすい機能——ウェブスクレイパーライブラリを備えています。左側のナビゲーションバーから「スクレイパー」-「ウェブスクレイパーライブラリ」を選択します。

次に、linkedin.com のスクレイパーを試してみます。

プロフィール、企業情報、求人、投稿、ユーザー検索など、あらゆるデータ分類が用意されていることがわかります。

公式の例を使用してプロフィールを取得します。右側の「手動実行」をクリックして、しばらく待ちます。
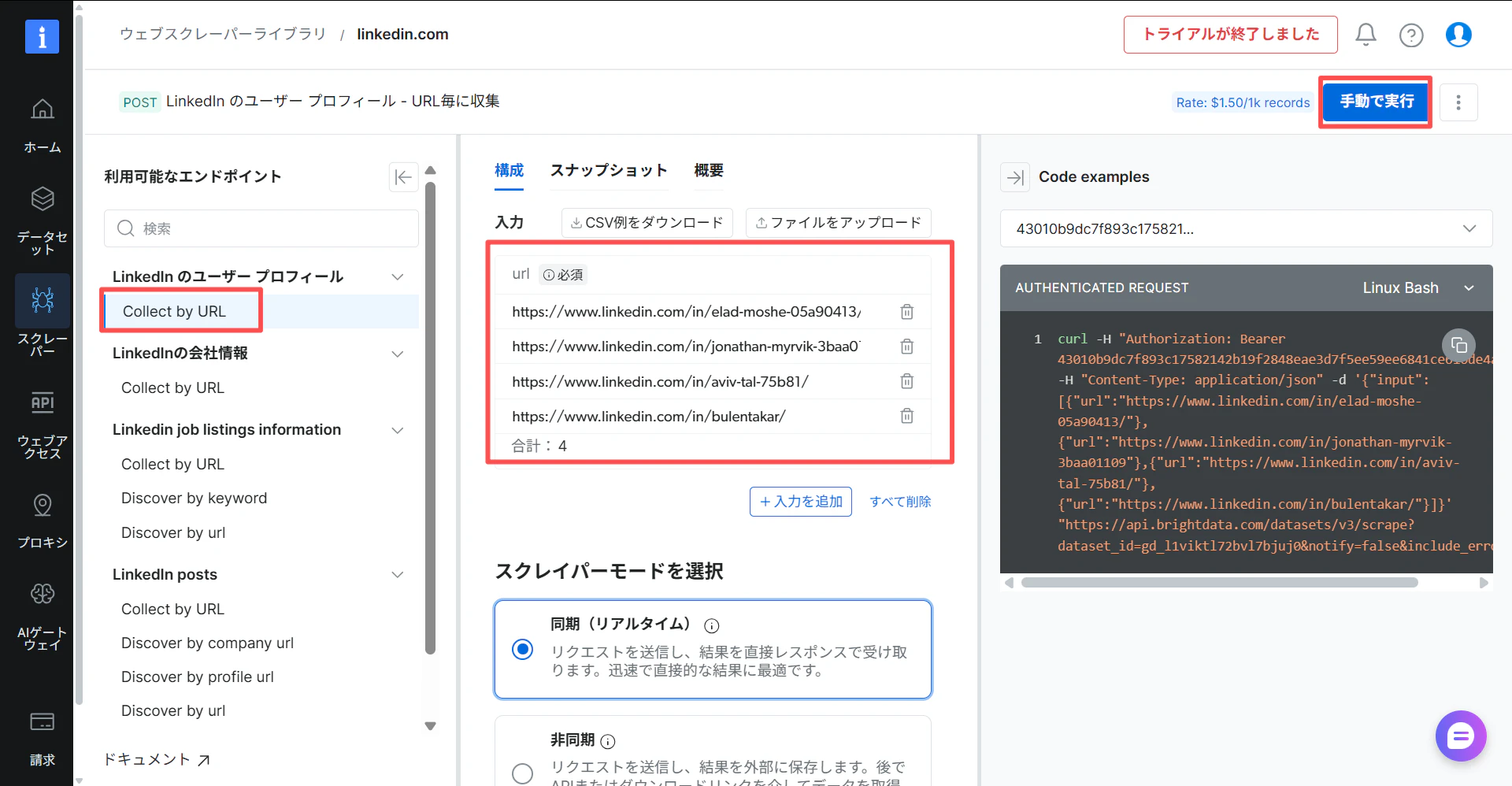
処理速度が非常に速く、結果ページではクロールされたデータに関する詳細な資料を確認できます。また、JSON、NDJSON、JSONL、CSVといった多様なフォーマットでのダウンロードが可能です。
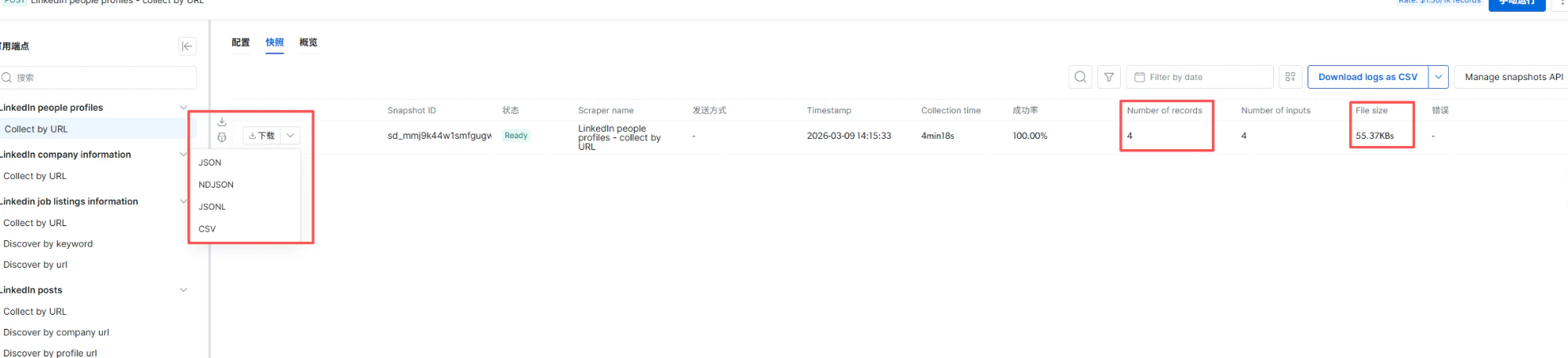
最後に、JSONファイルをダウンロードしてデータを確認してみましょう。一連の流れは非常にスムーズで、データスクレイピングの経験豊富なプログラマーから、初めて挑戦する初心者の方まで、あらゆるニーズを満たしてくれるスクレイパーです!

コード例(一部):
import okhttp3.*;
import java.io.*;
public class APIRequest {
public static void main(String[] args) {
try {
OkHttpClient client = new OkHttpClient();
String jsonBody = """
{
"input": [
{
"url": "https://www.linkedin.com/in/elad-moshe-05a90413/"
},
{
"url": "https://www.linkedin.com/in/jonathan-myrvik-3baa01109"
},
{
"url": "https://www.linkedin.com/in/aviv-tal-75b81/"
},
{
"url": "https://www.linkedin.com/in/bulentakar/"
}
]
}
""";
RequestBody requestBody = RequestBody.create(
jsonBody, MediaType.parse("application/json"));
Request request = new Request.Builder()
.url("https://api.brightdata.com/datasets/v3/scrape?dataset_id=gd_l1viktl72bvl7bjuj0¬ify=false&include_errors=true")
.addHeader("Authorization", "Bearer f11bd737-fd57-4515-9951-21339fd10cf6")
.addHeader("Content-Type", "application/json")
.post(requestBody)
.build();
try (Response response = client.newCall(request).execute()) {
String responseBody = response.body().string();
if (response.isSuccessful()) {
System.out.println(responseBody);
} else {
System.err.println("Error: HTTP " + response.code());
System.err.println(responseBody);
}
}
} catch (Exception e) {
System.err.println("Request error: " + e.getMessage());
e.printStackTrace();
}
}
}
返却されたJSON例(一部):
[{
"id": "aviv-tal-75b81",
"name": "Aviv Tal",
"city": "Israel",
"country_code": "IL",
"about": "I’m a tech executive with a strong background in product, strategy, and business…",
"posts": [{
"title": "Technology Leap – Develop, Outsource or Acquire",
"attribution": "As industries and technologies change, companies face the need to perform a technology leap and adopt new core…",
"img": "https://media.licdn.com/dms/image/v2/C4D12AQGyCj4hjhROmg/article-cover_image-shrink_720_1280/article-cover_image-shrink_720_1280/0/1592251833104?e=2147483647&v=beta&t=O0tf3hyq1bZzbSko27lLsC4BB_EtvZx1cNr-QuKeoiI",
"link": "https://www.linkedin.com/pulse/technology-leap-develop-outsource-acquire-aviv-tal",
"created_at": "2020-06-15T00:00:00.000Z",
"interaction": "-",
"id": "6678375323823865856"
}
]
"current_company": {
"link": "https://il.linkedin.com/company/bright-data?trk=public_profile_topcard-current-company",
"name": "Bright Data",
"company_id": "bright-data",
"location": null
}
}
]
よくある質問(FAQ)
-
2026年でもPythonスクリプトでLinkedInをスクレイピングできますか?
答:基本的には不可能です。LinkedInの防御技術はインテリジェンス化されており、普通のスクリプトではログインページすらアクセスできず、DIYスクレイピングは完全に無力化されています。 -
LinkedInデータのスクレイピングは合法ですか?
答:合法ですが境界線があります。プラットフォームの規則や法律を遵守し、公開されている非プライバシーデータのみを収集する必要があります。 -
技術的な背景がなくてもBright Dataを使えますか?
答:はい。AI Scraper Studioなどのツールがあり、自然言語(プロンプト)やビジュアル操作で、数分以内に設定が完了します。 -
LinkedInスクレイピングの典型的なコストは?
答:コスト管理が難しく垢バンリスクも伴う「自社開発(DIY)」に対し、Bright Dataなどの「専門ツール」は月額500ドル程度からの従量課金制で、ニーズに応じた柔軟な運用が可能です。
最後に:データの質こそが核心競争力
AIが意思決定を駆動するこの時代、「ゴミを入れればゴミが出てくる」という原則は変わりません。LinkedInデータの収集はもはや技術的な実現可能性の問題ではなく、安定性、深さ、そして持続可能性という戦略的布陣の問題です。
実測の結果、結論は明確です。エンタープライズ規模のカバー率を求めるチームにとって、Bright Dataは現在市場で唯一、全方位かつ高安定、そして自己進化能力を備えたソリューションを提供しています。
[今すぐLinkedInデータ取得の旅を始める →] https://get.brightdata.com/hwj7ya