Tensorflow Serving を使い倒す
有望なディープラーニングのライブラリは Tensorflow と PyTorch で勢力が二分されている現状です。それぞれに強み弱みがあり、以下のような特徴があると思います。
- Tensorflow:Tensorflow Serving や Tensorflow Lite のような豊富な推論エンジン、Keras の便利な学習 API
- PyTorch:Define by Run による強力な学習、TorchVision による便利な画像処理
研究や学習では PyTorch が圧倒的になっていますが、推論器を動かすとなると Tensorflow のほうが有力な機能を提供していると思います。PyTorch は ONNX で推論することが可能ですが、モバイル向けや End-to-end なパイプラインサポートとなると、Tensorflow Lite や TFX 含めて Tensorflow が便利です。
本ブログでは Tensorflow Serving を用いた推論器とクライアントの作り方を説明します。Tensorflow Serving を動かすだけであれば多様な記事がありますが、本ブログではデータの入力から前処理、推論、後処理、出力まで、End-to-end で Tensorflow でカバーする方法を紹介します。
今回書いたコード:https://github.com/shibuiwilliam/e2e_tensorflow_serving
問題意識
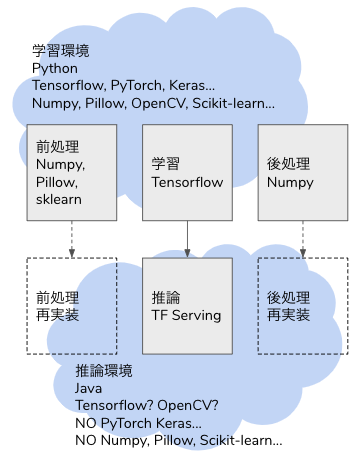
ディープラーニングでモデルを学習した後、モデルは saved model や ONNX 形式で出力できても、前処理や出力が学習時の Python コードしかなく、推論へ移行するときに書き直すことになります。
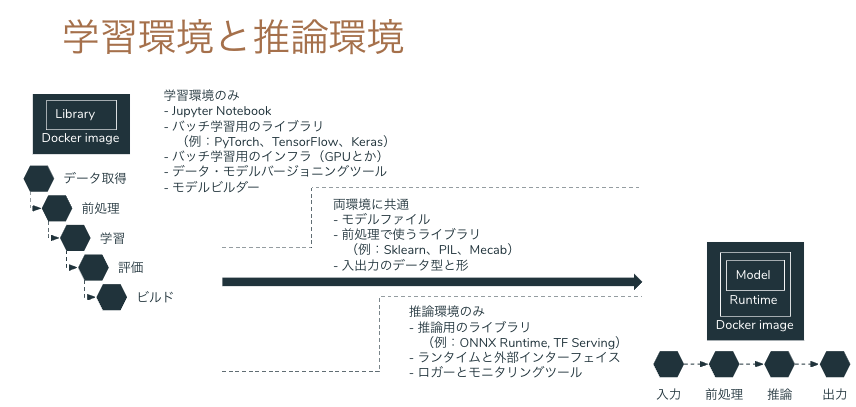
学習も推論も Python で、Python コードをそのまま使い回せるなら良いですが(それでも間違うことが多々ありますが)、本番システムは Java や Golang、Node.js で Python を組み込む基盤や運用がないということがあります。Python 以外の言語で画像やテーブルデータの処理が Python ほど豊富であるとは限りませんし、Python で実行している前処理をそのまま動かすことができるとは限りません。
解決策のひとつは、機械学習の推論プロセスをサポートする推論器を作ることです。推論プロセスのすべてを Tensorflow の saved model に組み込んでしまい、Tensorflow Serving へ生データをリクエストすれば推論結果がレスポンスされる API を作れば、連携するバックエンドは REST クライアントや GRPC クライアントとして Tensorflow Serving にリクエストを送るだけで良くなります。
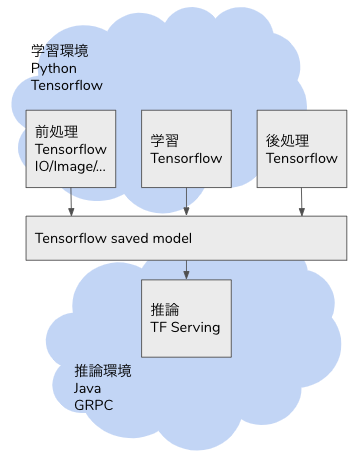
Tensorflow の Operator はニューラルネットワークだけでなく、画像のデコードやリサイズ、テーブルデータの One Hot 化等、機械学習に必須な処理が可能になっています。従来であれば Python の Pillow や Scikit-learn に依存していた処理が Tensorflow の計算グラフに組み込まれているため、推論のデータ入力から推論結果の出力まで、全工程を Tensorflow Serving でカバーすることができます。
本ブログでは Tensorflow Serving による画像分類、テキストの感情分析、テーブルデータの 2 値分類を使い、Tensorflow Serving の可能性を示していきたいと思います。
Tensorflow Serving
Tensorflow Serving は Tensorflow や Keras のモデルを推論器として稼働させるためのシステムです。Tensorflow の saved model を Web API(GRPC と REST API)として稼働させることができます。また単なる Web API だけでなく、バッチシステムとして動かすこともできます。複数バージョンのモデルを同一の Serving に組み込み、エンドポイントを分けることも可能です。Tensorflow Serving は Docker で起動させることが一般的です。

画像分類
ディープラーニングの重要な使い途の一つが画像処理です。今回はInception V3を使った画像分類を Tensorflow Serving で動かします。
画像分類のプロセスは以下になります。
- 生データの画像ファイルを入力データとして受け取る。
- 画像をデコードする。
- 画像をリサイズして Inception V3 の入力 Shape である(299,299,3)に変換する。
- Inception V3 で推論し、Softmax を得る。
- 各ラベルに Softmax の確率をマッピングする。
- 最も確率の高いラベルを出力する。
Inception V3 が担うのは常勤お 4 のみで、1,2,3,5,6 は前処理や後処理として周辺システムでカバーする必要があります。学習時は Python で Pillow や OpenCV、Numpy 等々を使って書きますが、推論時に同様のライブラリを使えるとは限りません。特に Python 以外の言語で構築する場合、OpenCV を使うことはできるかもしれませんが、他の Pillow や Numpy は他のライブラリで代替するか、自作する必要があります。
しかし Tensorflow であれば、1,2,3,5,6 も Tensor Operation に組み込み、推論の全行程をカバーすることができます。そのためには tf.function に前処理(1,2,3)と後処理(5,6)の Operation を記述します。
以下のdef serfing_fnがその Operation になります。Pillow や Numpy でも同様の処理を書くことがあると思いますが、記述量も複雑さも大差ない実装が可能です。
from typing import List
import tensorflow as tf
from tensorflow import keras
class InceptionV3Model(tf.keras.Model):
def __init__(self, model: tf.keras.Model, labels: List[str]):
super().__init__(self)
self.model = model # Inception V3 model
self.labels = labels # ImageNet labels in list
@tf.function(
input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string, name="image")]
)
def serving_fn(self, input_img: str) -> tf.Tensor:
def _base64_to_array(img):
img = tf.io.decode_base64(img)
img = tf.io.decode_jpeg(img)
img = tf.image.convert_image_dtype(img, tf.float32)
img = tf.image.resize(img, (299, 299))
img = tf.reshape(img, (299, 299, 3))
return img
img = tf.map_fn(_base64_to_array, input_img, dtype=tf.float32)
predictions = self.model(img)
def _convert_to_label(candidates):
max_prob = tf.math.reduce_max(candidates)
idx = tf.where(tf.equal(candidates, max_prob))
label = tf.squeeze(tf.gather(self.labels, idx))
return label
return tf.map_fn(_convert_to_label, predictions, dtype=tf.string)
def save(self, export_path="./saved_model/inception_v3/0/"):
signatures = {"serving_default": self.serving_fn}
tf.keras.backend.set_learning_phase(0)
tf.saved_model.save(self, export_path, signatures=signatures)
上記InceptionV3Modelクラスのインスタンスを saved model として保存し、Tensorflow Serving として起動することができます。起動した Tensorflow Serving は GRPC として 8500 ポート、REST API として 8501 ポートが開放されます。
docker run -t -d --rm \
-p 8501:8501 \
-p 8500:8500 \
--name inception_v3 \
-v $(pwd)/saved_model/inception_v3:/models/inception_v3 \
-e MODEL_NAME=inception_v3 \
tensorflow/serving:2.3.0
エンドポイントの定義は以下のようになっています。inputs以下が入力定義で、outputs以下が出力定義です。inputsではimageタグのデータを取ります。Shape が-1となっていますが、これは画像の base64 エンコードされたデータを入力とするためです。この時点で Tensorflow Serving への入力は(299,299,3)次元の配列ではなく、画像データそのものとなっています。
`curl localhost:8501/v1/models/inception_v3/versions/0/metadata`
$ curl localhost:8501/v1/models/inception_v3/versions/0/metadata
{
"model_spec":{
"name": "inception_v3",
"signature_name": "",
"version": "0"
}
,
"metadata": {"signature_def": {
"signature_def": {
"serving_default": {
"inputs": {
"image": {
"dtype": "DT_STRING",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_image:0"
}
},
"outputs": {
"output_0": {
"dtype": "DT_STRING",
"tensor_shape": {
"dim": [],
"unknown_rank": true
},
"name": "StatefulPartitionedCall:0"
}
},
"method_name": "tensorflow/serving/predict"
},
"__saved_model_init_op": {
"inputs": {},
"outputs": {
"__saved_model_init_op": {
"dtype": "DT_INVALID",
"tensor_shape": {
"dim": [],
"unknown_rank": true
},
"name": "NoOp"
}
},
"method_name": ""
}
}
}
}
}
リクエストは以下のように実行することができます。GRPC と REST API の例を書いていますが、どちらも画像をバイナリデータとして読み込み、base64 エンコードして Tensorflow Serving のエンドポイントにリクエストします。クライアントは前処理することなく Tensorflow Serving にデータをリクエストします。
注意点は Tensorflow のtf.io.decode_base64がbase64.urlsafe_b64encodeされたデータでないとデコードできないという点です。
def read_image(image_file: str = "./a.jpg") -> bytes:
with open(image_file, "rb") as f:
raw_image = f.read()
return raw_image
# GRPC
def request_grpc(
image: bytes,
model_spec_name: str = "inception_v3",
signature_name: str = "serving_default",
address: str = "localhost",
port: int = 8500,
timeout_second: int = 5,
) -> str:
serving_address = f"{address}:{port}"
channel = grpc.insecure_channel(serving_address)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
base64_image = base64.urlsafe_b64encode(image)
request = predict_pb2.PredictRequest()
request.model_spec.name = model_spec_name
request.model_spec.signature_name = signature_name
request.inputs["image"].CopyFrom(tf.make_tensor_proto([base64_image]))
response = stub.Predict(request, timeout_second)
prediction = response.outputs["output_0"].string_val[0].decode("utf-8")
return prediction
# REST
def request_rest(
image: bytes,
model_spec_name: str = "inception_v3",
signature_name: str = "serving_default",
address: str = "localhost",
port: int = 8501,
timeout_second: int = 5,
):
serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}:predict"
headers = {"Content-Type": "application/json"}
base64_image = base64.urlsafe_b64encode(image).decode("ascii")
request_dict = {"inputs": {"image": [base64_image]}}
response = requests.post(
serving_address,
json.dumps(request_dict),
headers=headers,
)
return dict(response.json())["outputs"][0]
推論結果は以下のようになります。
# GRPC
$ python request_inceptionv3.py -f GRPC
Siamese cat
# REST API
$ python request_inceptionv3.py -f REST
Siamese cat
テキストの感情分析
続いてテキスト分類です。テキスト処理も画像と同様で、入力、前処理、後処理、出力になる箇所を
Tensorflow でカバーします。
今回はサンプルデータとしてKaggle にある感情分析の NLP データを使用します。感情分析の英文データで、[anger, fear, joy, love, sadness, surprise]の 6 クラス分類となっています。
- anger: i felt anger when at the end of a telephone call
- fear: i pay attention it deepens into a feeling of being invaded and helpless
- joy: i am feeling totally relaxed and comfy
- love: i want each of you to feel my gentle embrace
- sadness: i realized my mistake and i m really feeling terrible and thinking that i shouldn't do that
- surprise: i feel shocked and sad at the fact that there are so many sick people
Tensorflow のテキスト処理で使えるライブラリは複数あります。
- Tensorflow Text
- Tensorflow Transform
- Tensorflow Keras Preprocessing
- Tensorflow Keras Layers Preprocessing
今回はTensorflow Keras Layers Preprocessingを使います。これを選んだのは API が使いやすいという理由です。
テキスト分類では以下の手順をたどります。前処理はテキストや目的次第ですが、今回は簡単のために tfidf を使います。
- 生データのテキストを入力データとして受け取る。
- テキストを前処理してベクターにする。
- ニューラルネットワーク で推論し、Softmax を得る。
- 各ラベルに Softmax の確率をマッピングする。
- 最も確率の高いラベルを出力する。
Tensorflow Keras Layers PreprocessingではTextVectorizationで テキストデータの tfidf のベクター化が可能です。
以下は TextVectorization を使用したサンプルコードです。TextVectorization.adaptでテキストデータに対して変換マップを作ることができます。adapt した TextVectorization はtf.keras.layerとして Keras Model の 1 レイヤーに組み込むことができます。今回は入力レイヤーに使います。
def make_text_vectorizer(
data: np.ndarray,
) -> tf.keras.layers.experimental.preprocessing.TextVectorization:
text_vectorizer = tf.keras.layers.experimental.preprocessing.TextVectorization(
output_mode="tf-idf", ngrams=2
)
text_vectorizer.adapt(data)
return text_vectorizer
def define_model(
text_vectorizer: tf.keras.layers.experimental.preprocessing.TextVectorization,
optimizer: str = "adam",
loss: str = "categorical_crossentropy",
metrics: List[str] = ["accuracy"],
) -> tf.keras.Model:
inputs = keras.Input(shape=(1,), dtype="string")
x = text_vectorizer(inputs)
x = layers.Dense(1)(x)
x = layers.Dense(256, activation="relu")(x)
x = layers.Dense(256, activation="relu")(x)
outputs = layers.Dense(6, activation="softmax")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer=optimizer, loss=loss, metrics=metrics)
return model
fit したモデルを使って saved model を作成します。今回は TextVectorization が入力データの前処理を担うため、後処理(手順 4,5)の分類部分のみ追加実装しています。
class TextModel(tf.keras.Model):
def __init__(self, model: tf.keras.Model, labels: List[str]):
super().__init__(self)
self.model = model
self.labels = labels
@tf.function(
input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string, name="text")]
)
def serving_fn(self, text: str) -> tf.Tensor:
predictions = self.model(text)
def _convert_to_label(candidates):
max_prob = tf.math.reduce_max(candidates)
idx = tf.where(tf.equal(candidates, max_prob))
label = tf.squeeze(tf.gather(self.labels, idx))
return label
return tf.map_fn(_convert_to_label, predictions, dtype=tf.string)
def save(self, export_path="./saved_model/text/"):
signatures = {"serving_default": self.serving_fn}
tf.keras.backend.set_learning_phase(0)
tf.saved_model.save(self, export_path, signatures=signatures)
保存した saved model で Tensorflow Serving を起動します。
docker run -t -d --rm \
-p 8501:8501 \
-p 8500:8500 \
--name text \
-v $(pwd)/saved_model/text:/models/text \
-e MODEL_NAME=text \
tensorflow/serving:2.3.0
Tensorflow Serving のメタデータは以下のとおりになっています。入力としてtextフィールドにテキストデータを入れてリクエストします。出力はoutout_0に推論結果のラベルがレスポンスされます。
`curl localhost:8501/v1/models/text/versions/0/metadata`
$ curl localhost:8501/v1/models/text/versions/0/metadata
{
"model_spec":{
"name": "text",
"signature_name": "",
"version": "0"
}
,
"metadata": {"signature_def": {
"signature_def": {
"serving_default": {
"inputs": {
"text": {
"dtype": "DT_STRING",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_text:0"
}
},
"outputs": {
"output_0": {
"dtype": "DT_STRING",
"tensor_shape": {
"dim": [],
"unknown_rank": true
},
"name": "StatefulPartitionedCall:0"
}
},
"method_name": "tensorflow/serving/predict"
},
"__saved_model_init_op": {
"inputs": {},
"outputs": {
"__saved_model_init_op": {
"dtype": "DT_INVALID",
"tensor_shape": {
"dim": [],
"unknown_rank": true
},
"name": "NoOp"
}
},
"method_name": ""
}
}
}
}
}
今回も GRPC と REST のリクエスト例を示します。テキストデータをそのままリクエストに入れることができます。事前に前処理する必要はありません。
def read_text(text_file: str = "./text.txt") -> str:
with open(text_file, "r") as f:
text = f.read()
return text
# GRPC
def request_grpc(
text: str,
model_spec_name: str = "text",
signature_name: str = "serving_default",
address: str = "localhost",
port: int = 8500,
timeout_second: int = 5,
) -> str:
serving_address = f"{address}:{port}"
channel = grpc.insecure_channel(serving_address)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = model_spec_name
request.model_spec.signature_name = signature_name
request.inputs["text"].CopyFrom(tf.make_tensor_proto([text]))
response = stub.Predict(request, timeout_second)
prediction = response.outputs["output_0"].string_val[0].decode("utf-8")
return prediction
# REST API
def request_rest(
text: str,
model_spec_name: str = "text",
signature_name: str = "serving_default",
address: str = "localhost",
port: int = 8501,
timeout_second: int = 5,
):
serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}:predict"
headers = {"Content-Type": "application/json"}
request_dict = {"inputs": {"text": [text]}}
response = requests.post(
serving_address,
json.dumps(request_dict),
headers=headers,
)
return dict(response.json())["outputs"][0]
テーブルデータ 2 値分類
最後にテーブルデータです。
モデル自体は Tensorflow のサンプルで公開されているClassify structured data with feature columnsを使用します。以下のようなデータ構成になっています。
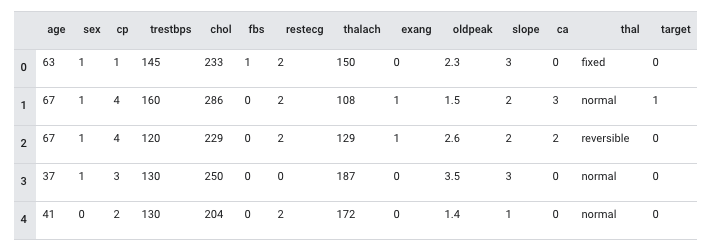
テーブルデータの前処理は tensorflow.feature_columnで各種データの変換をサポートしています。tensorflow.feature_columnを使用した推論の流れは以下のようになります。
- データを入力データとして受け取る。
- データをカラムに応じて前処理する。
- ニューラルネットワーク で推論し、Sigmoid を得る。
- 陽性の確率を出力する。
前処理含めて学習時にカラムの前処理を定義することができます。使い方はシンプルで、データの特徴に応じて変換方法を適用するだけで使えます。
from tensorflow import feature_column
from tensorflow.keras import layers
feature_columns = []
for header in ["age", "trestbps", "chol", "thalach", "oldpeak", "slope", "ca"]:
feature_columns.append(feature_column.numeric_column(header))
age = feature_column.numeric_column("age")
age_buckets = feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65]
)
feature_columns.append(age_buckets)
thal = feature_column.categorical_column_with_vocabulary_list(
"thal", ["fixed", "normal", "reversible"]
)
thal_one_hot = feature_column.indicator_column(thal)
feature_columns.append(thal_one_hot)
thal_embedding = feature_column.embedding_column(thal, dimension=8)
feature_columns.append(thal_embedding)
crossed_feature = feature_column.crossed_column(
[age_buckets, thal], hash_bucket_size=1000
)
crossed_feature = feature_column.indicator_column(crossed_feature)
feature_columns.append(crossed_feature)
feature_columnで定義したデータの前処理をモデルの入力レイヤーとして活用することが可能です。
def define_model(
feature_columns: List[Any],
optimizer: str = "adam",
loss: str = "binary_crossentropy",
metrics: List[str] = ["accuracy"],
) -> tf.keras.Model:
feature_layer = tf.keras.layers.DenseFeatures(feature_columns)
model = tf.keras.Sequential(
[
feature_layer,
layers.Dense(128, activation="relu"),
layers.Dense(128, activation="relu"),
layers.Dense(1, activation="sigmoid"),
]
)
model.compile(optimizer=optimizer, loss=loss, metrics=metrics)
return model
これでモデルは完成です。モデルを保存して saved model とし、Tensorflow Serving として起動することができます。
docker run -t -d --rm \
-p 8501:8501 \
-p 8500:8500 \
--name table_data \
-v $(pwd)/saved_model/table_data:/models/table_data \
-e MODEL_NAME=table_data \
tensorflow/serving:2.3.0
Tensorflow Serving への入力データはカラム毎にフィールドを指定する形式になります。metadata を取ると以下のようになっています。長くなっていますが、各カラムで入力フィールドを定義しており、受け付けるデータ型や Shape が明示されています。
`curl localhost:8501/v1/models/table_data/versions/0/metadata`
$ curl localhost:8501/v1/models/table_data/versions/0/metadata
{
"model_spec":{
"name": "table_data",
"signature_name": "",
"version": "0"
}
,
"metadata": {"signature_def": {
"signature_def": {
"serving_default": {
"inputs": {
"oldpeak": {
"dtype": "DT_DOUBLE",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_oldpeak:0"
},
"restecg": {
"dtype": "DT_INT64",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_restecg:0"
},
"trestbps": {
"dtype": "DT_INT64",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_trestbps:0"
},
"slope": {
"dtype": "DT_INT64",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_slope:0"
},
"sex": {
"dtype": "DT_INT64",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_sex:0"
},
"ca": {
"dtype": "DT_INT64",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_ca:0"
},
"exang": {
"dtype": "DT_INT64",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_exang:0"
},
"fbs": {
"dtype": "DT_INT64",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_fbs:0"
},
"chol": {
"dtype": "DT_INT64",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_chol:0"
},
"thalach": {
"dtype": "DT_INT64",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_thalach:0"
},
"thal": {
"dtype": "DT_STRING",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_thal:0"
},
"cp": {
"dtype": "DT_INT64",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_cp:0"
},
"age": {
"dtype": "DT_INT64",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "serving_default_age:0"
}
},
"outputs": {
"output_1": {
"dtype": "DT_FLOAT",
"tensor_shape": {
"dim": [
{
"size": "-1",
"name": ""
},
{
"size": "1",
"name": ""
}
],
"unknown_rank": false
},
"name": "StatefulPartitionedCall_1:0"
}
},
"method_name": "tensorflow/serving/predict"
},
"__saved_model_init_op": {
"inputs": {},
"outputs": {
"__saved_model_init_op": {
"dtype": "DT_INVALID",
"tensor_shape": {
"dim": [],
"unknown_rank": true
},
"name": "NoOp"
}
},
"method_name": ""
}
}
}
}
}
たとえば json でリクエストする場合、以下のようなデータでリクエストすることができます。
{
"age": [[71]],
"sex": [[0]],
"cp": [[4]],
"trestbps": [[112]],
"chol": [[149]],
"fbs": [[0]],
"restecg": [[0]],
"thalach": [[125]],
"exang": [[0]],
"oldpeak": [[1.6]],
"slope": [[2]],
"ca": [[0]],
"thal": [["normal"]]
}
PythonでGRPC、RESTでリクエストする場合は以下になります。
def request_grpc(
data: Dict[str, Any],
model_spec_name: str = "inception_v3",
signature_name: str = "serving_default",
address: str = "localhost",
port: int = 8500,
timeout_second: int = 5,
) -> str:
serving_address = f"{address}:{port}"
channel = grpc.insecure_channel(serving_address)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = model_spec_name
request.model_spec.signature_name = signature_name
age = np.array(data["age"], dtype=np.int64)
sex = np.array(data["sex"], dtype=np.int64)
cp = np.array(data["cp"], dtype=np.int64)
trestbps = np.array(data["trestbps"], dtype=np.int64)
chol = np.array(data["chol"], dtype=np.int64)
fbs = np.array(data["fbs"], dtype=np.int64)
restecg = np.array(data["restecg"], dtype=np.int64)
thalach = np.array(data["thalach"], dtype=np.int64)
exang = np.array(data["exang"], dtype=np.int64)
oldpeak = np.array(data["oldpeak"], dtype=np.float64)
slope = np.array(data["slope"], dtype=np.int64)
ca = np.array(data["ca"], dtype=np.int64)
thal = np.array(data["thal"], dtype=str)
request.inputs["age"].CopyFrom(tf.make_tensor_proto(age))
request.inputs["sex"].CopyFrom(tf.make_tensor_proto(sex))
request.inputs["cp"].CopyFrom(tf.make_tensor_proto(cp))
request.inputs["trestbps"].CopyFrom(tf.make_tensor_proto(trestbps))
request.inputs["chol"].CopyFrom(tf.make_tensor_proto(chol))
request.inputs["fbs"].CopyFrom(tf.make_tensor_proto(fbs))
request.inputs["restecg"].CopyFrom(tf.make_tensor_proto(restecg))
request.inputs["thalach"].CopyFrom(tf.make_tensor_proto(thalach))
request.inputs["exang"].CopyFrom(tf.make_tensor_proto(exang))
request.inputs["oldpeak"].CopyFrom(tf.make_tensor_proto(oldpeak))
request.inputs["slope"].CopyFrom(tf.make_tensor_proto(slope))
request.inputs["ca"].CopyFrom(tf.make_tensor_proto(ca))
request.inputs["thal"].CopyFrom(tf.make_tensor_proto(thal))
response = stub.Predict(request, timeout_second)
prediction = response.outputs["output_1"].float_val[0]
return prediction
def request_rest(
data: Dict[str, Any],
model_spec_name: str = "table_data",
signature_name: str = "serving_default",
address: str = "localhost",
port: int = 8501,
timeout_second: int = 5,
):
serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}:predict"
headers = {"Content-Type": "application/json"}
request_dict = {"inputs": data}
response = requests.post(
serving_address,
json.dumps(request_dict),
headers=headers,
)
return dict(response.json())["outputs"][0][0]
まとめ
Tensorflow の Operation を活用すれば、ディープラーニングのモデルだけでなく、データ入力から前処理、後処理までを計算グラフに組み込むことができます。学習から推論器へとシステムを移管する際、コードの書き換えが発生して非効率なシステム開発や設計になることがあります。End-to-end でテンソル演算に組み込んで Tensorflow Serving で推論することで、機械学習の学習時と同様の推論 API を構築することできます。