データが足りないなら増やせば良いじゃない。
パンがなければケーキを食べれば良いじゃない。
データ不足や不均衡なときにデータを増殖する手法をざっと調べたのでまとめます。
TLDR
- テーブルデータ(構造化データ)はSMOTEが便利
- 画像データは画像処理(左右反転、傾ける、ノイズ追加等々)
- テキストデータは異音同義語や類語、ルールベースで単語置換
- 音声データは数値配列にしてノイズを乗せたり伸ばしたり
前置き
機械学習やディープラーニングで学習するとき、充分なデータが用意されているとは限りません。
またはデータの総量は充分にあるけど、偏っている(インバランスになっている)ということも稀ではありません。
そういう場合の対策は概ね2つあると思います。
- データを集めてくる
- データを増やす
1.のデータを集める場合は、Webを探索してからオープンデータを集めたり社内調整したり、いろいろがんばります。
Web探索はスクレイピングをがんばることもあると思います。
社内調整の場合は技術力よりも人間関係と力関係が重要だったりします。
まあいろいろ苦労しますが、1.については今回は範囲外です。
2.のデータを増やすほうはData Augmentationとして機械学習、ディープラーニングの分野では研究課題のひとつになっているように思います。
この記事では2.データの増やし方について、ざっとまとめます。
テーブルデータ
実際のビジネスで最も頻繁に扱うのはリレーショナルデータベース(またはエクセル)に格納された構造化データだと思います。
売上データやマーケットデータ、人事データまで、ビジネスデータは構造化されテーブル形式になっていることが多いです。
こうしたデータが偏っていたり不均衡だったりすることは度々あります。
テーブルデータはSMOTEという手法を使ってデータを増やすことができます。
SMOTE (Synthetic Minority Oversampling TEchnique)
SMOTEは不均衡データを均衡させる手法です。
分類問題で特定のクラスが多すぎる(または少なすぎる)ときに、SMOTEを使ってバランスを取ることができます。
具体的にはUndersampling(多すぎるクラスを減らす)とOversampling(少なすぎるクラスを増やす)しています。
Pythonであればimbalanced-learnという名前通りのライブラリを使って以下のようにすればデータの不均衡を正すことができます。
SMOTEでは主にマイナーデータを増やします(Oversampling)。メジャーデータを多少Undersamplingしますが、重要なのは主にOversamplingのほうです。
Oversampling手法では、以下イメージのように2つのマイナーデータの間から値をサンプリングします。

以下、imbalanced-learnの使い方を説明します。
インストール
# install
pip install -U imbalanced-learn
不均衡データを用意
import numpy as np
import matplotlib.pyplot as plt
# generate imbalanced dataset
x = np.array([[np.random.randint(1,101) for _ in range(1000)],[np.random.randint(1,101) for _ in range(1000)]]).T
y = np.array([0 if 50<x[i][0]*x[i][1]<9000 else 1 for i in range(1000)])
# scatter plot to see imbalanceness
x_0 = x[np.where(y==0)[0],:]
x_1 = x[np.where(y==1)[0],:]
# plot
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.scatter(x_0[:,0],x_0[:,1], c='red')
ax.scatter(x_1[:,0],x_1[:,1], c='blue')
ax.set_xlabel('x')
ax.set_ylabel('y')
fig.show()
print("0 rate: {0}%".format(len(np.where(y==0)[0])/10))
print("1 rate: {0}%".format(len(np.where(y==1)[0])/10))
以下のような不均衡データができあがります。
1000行のデータのうち、0ラベルが96.8%、1ラベルが3.2%です。
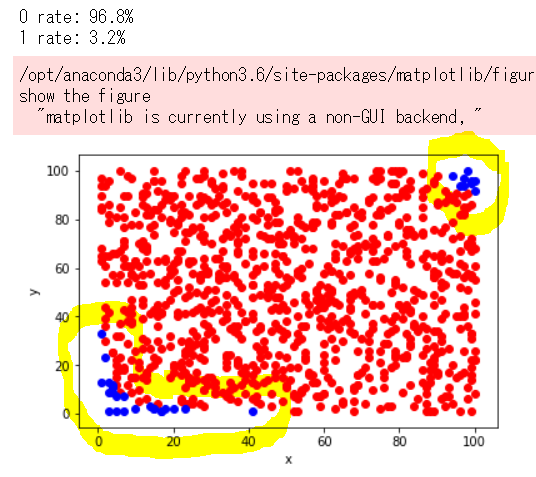
このデータで分類器を学習しても、全て0と予測すれば最悪96.8%は正解するモデルが出来上がったりします。
マイノリティの3.2%をしっかり検知したい(ROC AUC)ことのほうが多いので、この割合だと困ります。
不均衡を正す
from imblearn.over_sampling import SMOTE
# SMOTE to balance dataset
sm = SMOTE(kind='svm')
x_resampled, y_resampled = sm.fit_sample(x, y)
# scatter plot
x_resampled_0 = x_resampled[np.where(y_resampled==0)[0],:]
x_resampled_1 = x_resampled[np.where(y_resampled==1)[0],:]
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.scatter(x_resampled_0[:,0],x_resampled_0[:,1], c='red')
ax.scatter(x_resampled_1[:,0],x_resampled_1[:,1], c='blue')
ax.set_xlabel('x')
ax.set_ylabel('y')
fig.show()
print("0 rate: {0}%".format(len(np.where(y_resampled==0)[0])/10))
print("1 rate: {0}%".format(len(np.where(y_resampled==1)[0])/10))
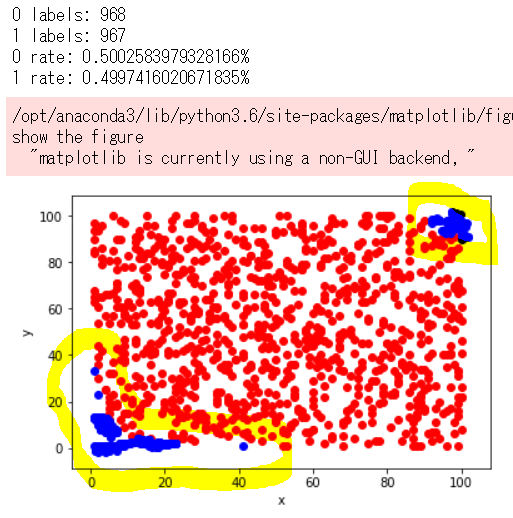
下記のように、1ラベルのデータ数が増え、割合も約50%ずつになっています。
参考URL
http://contrib.scikit-learn.org/imbalanced-learn/stable/index.html
http://ohke.hateblo.jp/entry/2017/08/18/230000
http://tekenuko.hatenablog.com/entry/2017/12/11/214522
https://qiita.com/shima_x/items/370587304ef17e7a61b8
画像データ
画像データのAugmentationの場合、既存の画像をもとにバリエーションを増やします。
具体的には、同じ被写体、同じ画像でも、左右反転したり色合いを暗くすることで、バリエーションを増やすことができます。
画像データを増やすのに使えるライブラリですが、以下は定番だと思います。
上記以外にも、画像をピクセルの配列とすれば、numpyでData Augmentationすることができます。
その他、ディープラーニングのライブラリに画像のData Augmentationが同梱されているものもあります。
サンプル
以下、簡単なサンプルです。
import numpy as np
import random
from PIL import Image
from skimage import transform
from skimage import util
# load image data
img = Image.open("cat.jpg")
np_img = np.asarray(img)
img
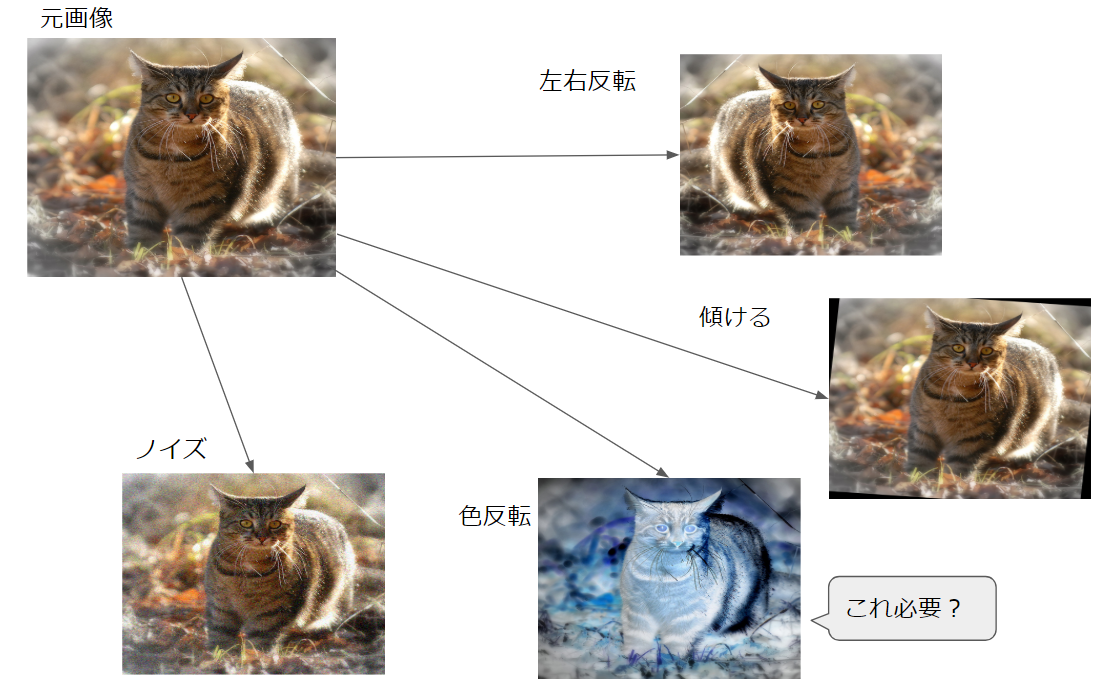
この猫ちゃんを元画像にしてAugmentしていきます。

# horizontal flip
def horizontal_flip(image):
return image[:, ::-1, :]
hf_img = horizontal_flip(np_img)
Image.fromarray(hf_img)
左右反転

# rotate
def rotate_image(image):
return transform.rotate(image, angle=random.randint(-15, 15), resize=False, center=None)
rt_img = rotate_image(np_img)
Image.fromarray((rt_img*255).astype(np.uint8))
回転

# add random noise
noise_img = util.random_noise(np_img)
Image.fromarray((noise_img*255).astype(np.uint8))
ノイズ

# invert color
inv_img = np.invert(np_img)
Image.fromarray(inv_img)
ビカッ!

注意点
画像をAugmentするときに大切なのは、目的に合わないパターンや実データに出てこないバリエーションは極力作らないことだと思います。
たとえば日中の屋外でスマホで撮った明るい写真だけを学習データとして物体検知をやりたい場合、左右反転やズームは有効でしょう。
しかし入力データは日中の明るい画像のみなので、色合いを暗く変更する必要性は高くないと思います。
もちろんモデルの汎用性を高めるために(夕方とか木陰とか想定して)多様なAugmentationを加えるのを否定しませんが、実際に推論する画像に登場しないようなパターンまで学習すると、学習時間が長期化して困ります。
GAN
GANで作った画像データを学習用データに転用する、ということをGAN界隈の展望として語られているのをよく見かけます。
ちょっと実例を見つけられなかったので、ここでは省略します。
参考URL
画像データのData Augmentation手法はいろいろあるので以下をご参照ください。
http://aidiary.hatenablog.com/entry/20161212/1481549365
http://www.kumilog.net/entry/numpy-data-augmentation
https://machinelearningmastery.com/image-augmentation-deep-learning-keras/
http://cs231n.stanford.edu/reports/2017/pdfs/300.pdf
https://qiita.com/dsanno/items/d32f3c928cdbcbe5de60
https://www.kaggle.com/tomahim/image-manipulation-augmentation-with-skimage
テキストデータ
画像データと違い、テキストデータにノイズを乗せたり反転させたりすることはできません。
テキストにノイズを乗せたり反転させた例:
元文 隣の客はよく柿食う客だ
ノイズ 隣のあ客はいよくう柿食うえ客だ
反転 だ客う食柿くよは客の隣
これだと誤字脱字検知のデータにはなりそうですが、それ以外の目的だとテキストデータとしては不正なものになります(注)。
テキストのAugmentationでは、意味を変えずに文法的に正しいテキストが必要になります。
テキストデータのAugmentationは文献で論じられていますが、主に以下の手法があります。
- 単語ベクトルを作り、類似する単語で置換する。
- シソーラス(類語辞典)で置換する。
- ルールベースで置換する(「赤いシャツ」→「赤い服」、「である・だ」→「です・ます」等々)。
WordNet
日本語の類語辞典としては、WordNetを使うと便利です。
上記のWordNetは国立研究開発法人情報通信研究機構が提供しているものです(具体的な使い方)。
元文 隣の客はよく柿食う客だ
単語置換 隣家の客はたくさん柿食べる客だ
これなら意味を変えずに文法も正しいままでテキストを作れます。
難点
同音異義語や同字異義語が多い単語だと、置換されたテキストの意味が変わる可能性があります。
元文 隣の客はよく柿食う客だ
単語置換 隣の客は巧みに柿食う客だ
よくという単語は多様な意味を持ち文脈によって意味が決まるため、シソーラスで置換すると違う意味になることがあります。
注
テキストにノイズを乗せる試みもあります。
https://arxiv.org/pdf/1703.02573.pdf
音声データ
音声データのData Augmentationには以下のような手法があるようです。
- ノイズを加える。
- 音を伸ばす。
- 発生、発音の時間をずらす。
- ピッチを上げたり下げたり。
https://www.kaggle.com/CVxTz/audio-data-augmentation
https://arxiv.org/pdf/1608.04363.pdf
ライブラリとしてはlibrosaというものが便利です。
インストール方法はpip install librosaです。
サンプルデータ
音声データを変換してみます。
なお、使用したデータはESC-50というオーディオデータの1-56380-A-5.wavファイルです。
中身は猫の鳴き声です。
Qiitaで音声の乗せ方がわからないので、聞きたい方はファイルをダウンロードしてください。
やってみる
猫の鳴き声をData Augmentationしてみます。
なお、変換後の音声を再生するかわりに、変換後の波データとMFCCを画像で表示します。
まずは事前準備です。
import librosa
import librosa.display
from sklearn import preprocessing
import matplotlib.pyplot as plt
import seaborn as sn
import IPython.display as ipd
# load a wave data
def load_wave_data(file_name, audio_dir="./"):
file_path = os.path.join(audio_dir, file_name)
x, fs = librosa.load(file_path, sr=44100)
return x,fs
# change wave data to mfcc
def calculate_mfcc(x, n_fft=2048, hop_length=128):
stft = np.abs(librosa.stft(x, n_fft=n_fft, hop_length=hop_length))**2
log_stft = librosa.power_to_db(stft)
melsp = librosa.feature.melspectrogram(S=log_stft)
mfcc = librosa.feature.mfcc(S=melsp)
mfcc = preprocessing.scale(mfcc, axis=1)
return mfcc
# display wave in plots
def show_wave(x):
plt.plot(x)
plt.show()
# display mfcc in heatmap
def show_mfcc(mfcc, fs):
librosa.display.specshow(mfcc, sr=fs)
plt.colorbar()
plt.show()
続いて猫の鳴き声データをロードして波形とMFCCにします。
音声データはnumpy配列としてロードされます。
なお、表示結果は最後にまとめて一枚にしています。
# raw data
x, fs = load_wave_data("meow.wav")
mfcc = calculate_mfcc(x)
print("CAT'S MEOW!")
print("wave size:{0}\nmfcc size:{1}".format(x.shape, mfcc.shape))
show_wave(x)
show_mfcc(mfcc, fs)
ipd.Audio(x, rate=fs)
ちなみにJupyter Notebookではipd.Audio(x, rate=fs)で音声を再生できるようになります。
ノイズを乗せてみます。
# data augmentation: add white noise
def add_white_noise(x, rate=0.005):
return x + rate*np.random.randn(len(x))
print("ADD WHITE NOISE")
x_wn = add_white_noise(x)
mfcc = calculate_mfcc(x_wn)
print("wave size:{0}\nmfcc size:{1}".format(x_wn.shape, mfcc.shape))
show_wave(x_wn)
show_mfcc(mfcc, fs)
ipd.Audio(x_wn, rate=fs)
時間をずらしてみます。
# data augmentation: shift sound in timeframe
def shift_sound(x, rate=2):
return np.roll(x, int(len(x)//rate))
print("SHIFT SOUND")
x_ss = shift_sound(x)
mfcc = calculate_mfcc(x_ss)
print("wave size:{0}\nmfcc size:{1}".format(x_ss.shape, mfcc.shape))
show_wave(x_ss)
show_mfcc(mfcc, fs)
ipd.Audio(x_ss, rate=fs)
音を伸ばしてみます。
# data augmentation: stretch sound
def stretch_sound(x, rate=1.1):
input_length = len(x)
x = librosa.effects.time_stretch(x, rate)
if len(x)>input_length:
return x[:input_length]
else:
return np.pad(x, (0, max(0, input_length - len(x))), "constant")
print("STRETCH SOUND")
x_st = stretch_sound(x)
mfcc = calculate_mfcc(x_st)
print("wave size:{0}\nmfcc size:{1}".format(x_st.shape, mfcc.shape))
show_wave(x_st)
show_mfcc(mfcc, fs)
ipd.Audio(x_st, rate=fs)
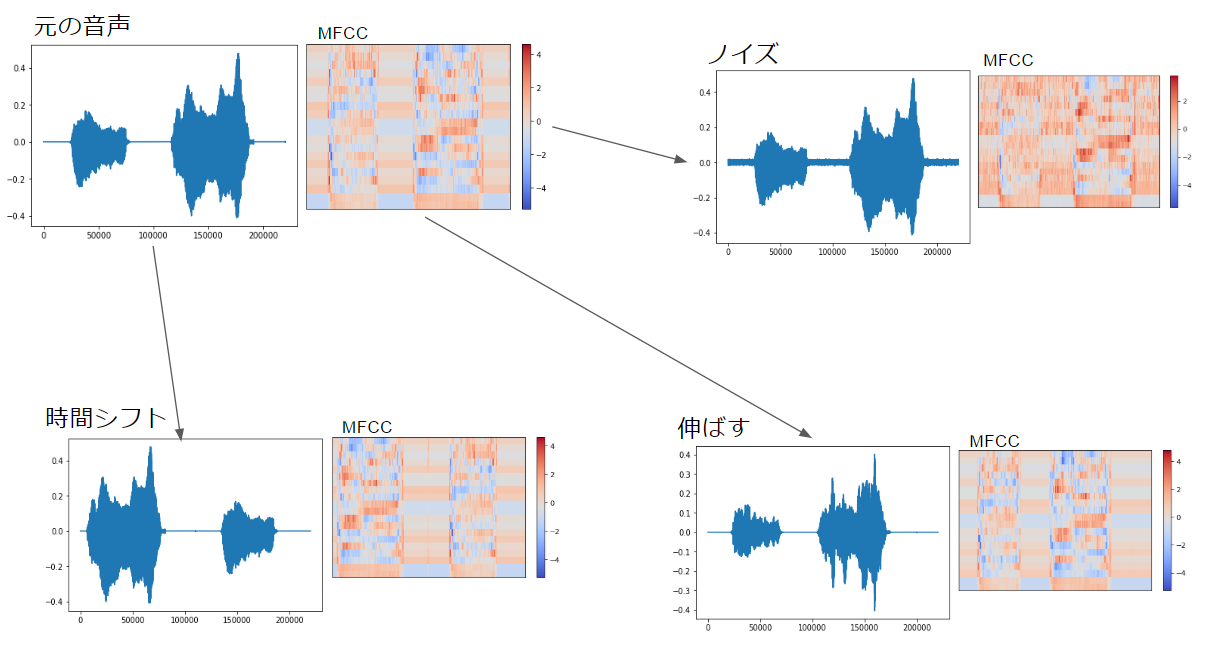
再生できないのが残念ですが、以下のように猫の鳴き声がいろいろ変換されています。
音声データは変換前、変換後ともにnumpy配列になっています。
参考URL
https://qiita.com/martin-d28jp-love/items/34161f2facb80edd999f
https://qiita.com/deaikei/items/57b9cd0a4517c69943ca
https://github.com/karoldvl/ESC-50
https://www.kaggle.com/CVxTz/audio-data-augmentation
余談
足りないデータの増やし方をざっとまとめました。
データ不足は大きく2種類あると思います。
- データ数が足りない
- 特徴量が足りない
今回書いたのは1.のほうです。
データ数を増やしても、ターゲットと相関のある特徴を入力できていないと、やはり学習はうまくいきません。
2.はData Augmentationで増やせるものではないので、がんばって集める必要があります。