12月25日の2022MLOpsアドベントカレンダーです。
澁井と申します。機械学習界隈では機械学習を実用化するためのシステム開発の本を書いてたります。もし良かったら読んでみてください。
『機械学習システムデザインパターン』
『機械学習システム構築実践ガイド』
このブログの内容は2022年年忘れMLOps LT大会で話した内容になりますので、ご興味あればそちらもご参照ください。

疑問
2022年のAI界隈で最も話題となった技術革新の一つにGenerative AIがあります。Generative AIは文字通りAIによって画像やテキストを生成、編集する技術です。流行した技術やサービスにはStable DiffusionやMidJourneyによる画像生成や、ChapGptによるチャットがあります。
おそらく読者の中にはこれらのサービスを実際に触って楽しんだ方も多いのではないでしょうか?
私もその一人で、画像生成はGAN(Generative Adversarial Network)やNeural Style Transferの時代からいろいろと試していました。Stable Diffusionはモデルと使い方が公開されており、私も面白がって使っています。
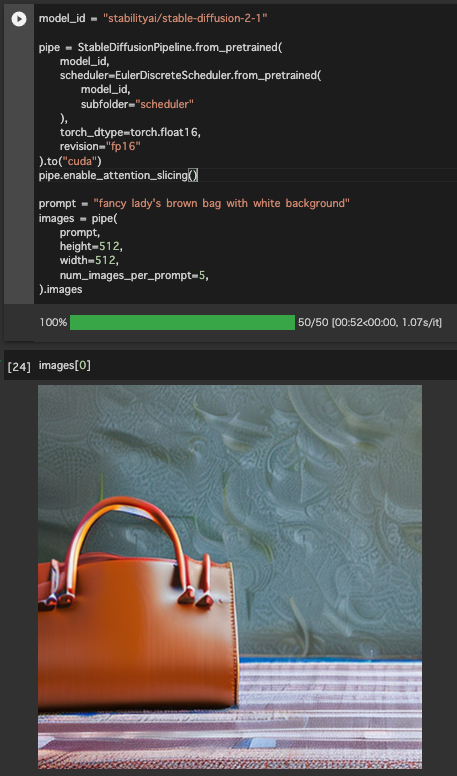
品質の高いGenerative AIで遊んでいて疑問に思ったことがあります。世の中の多くの人は、Generative AIを使ってまでクリエイティブな作業をしたいでしょうか? というのも、おそらくスマホの利用時間の殆どは、クリエイティビティよりもコンテンツや情報の閲覧のほうが長いと思います(調査したわけではないけど)。もちろんInstagramやTikTok、YouTubeに投稿するためにコンテンツの作成者になることも増えているでしょう。しかしそれ以上に多くの人は、投稿されたコンテンツを見たり、ゲームで遊んだり、ECで買い物することに時間を費やすほうが長いのではないかと思います(調査したわけではないけど)。
こうした仮説に立つと、一般的にクリエイティビティが必要になるのは、ほしいコンテンツを検索して、見つからなかったり存在しなかったりして、どうしてもコンテンツを生成しなければならないときではないかと推察します。
というわけで、本ブログではGenerative AIをクリエイティビティ以外の分野で活用する方法として検索を取り上げ、プロトタイプとともに検討してみます。
検索、類似ベクトル検索、Generative AI
IT技術による検索では多くの場合、テキストやカテゴリ、年月日を入力して、データベースや検索システムに登録されているコンテンツを検索します。対象のコンテンツは多岐に渡ります。Googleで汎用的なWebサイトを検索するときもあれば、Amazon等で検索する売り物、Pixiv等に投稿された絵、YouTube等に投稿された動画もあります。世の中の多くのWebサイトやアプリには検索システムが組み込まれて、自社・他社の提供するコンテンツを検索可能にしています。
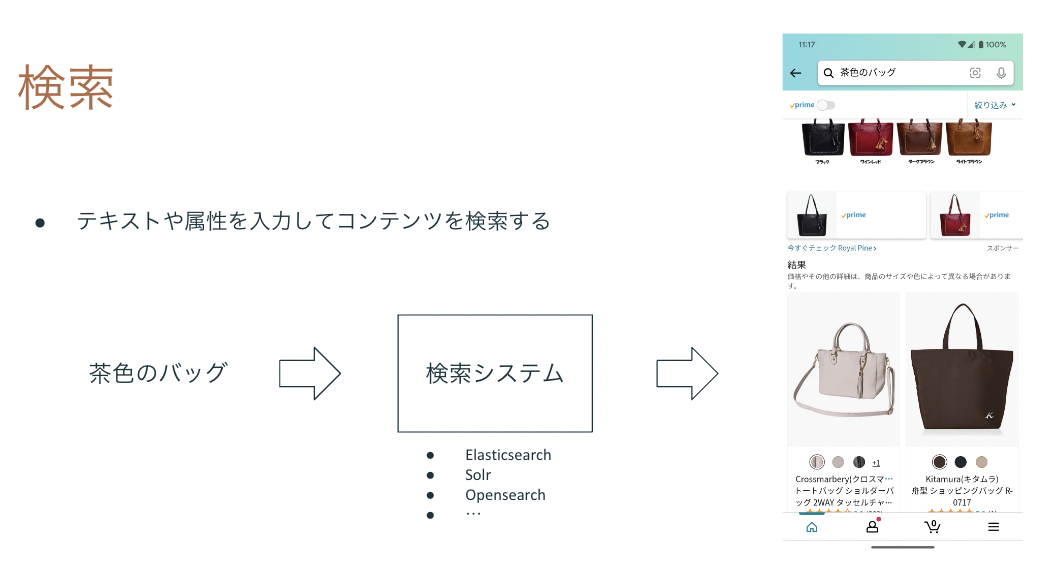
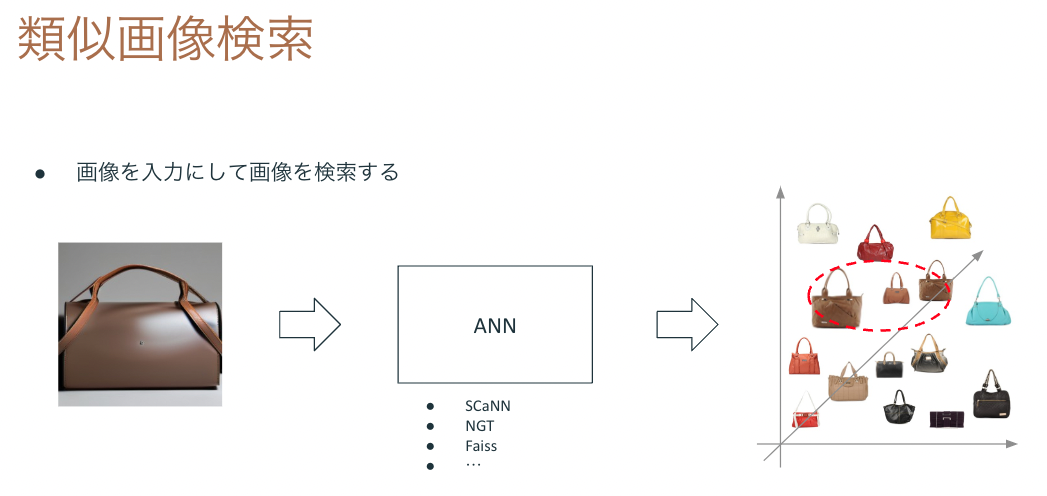
最近ではテキストのみならず、検索対象のコンテンツを入力として、似ているコンテンツを検索することも可能です。たとえばEC系のサービスで提供されている類似画像検索はその例で、買いたいものの写真を入力として、売り物の中から似ているものを検索する仕組みです。類似画像検索はディープラーニングで入力画像の特徴ベクトルを抽出し、ANN(Approximate Nearest Neighbor)を用いて距離の近いベクトルを持つコンテンツを検索します。
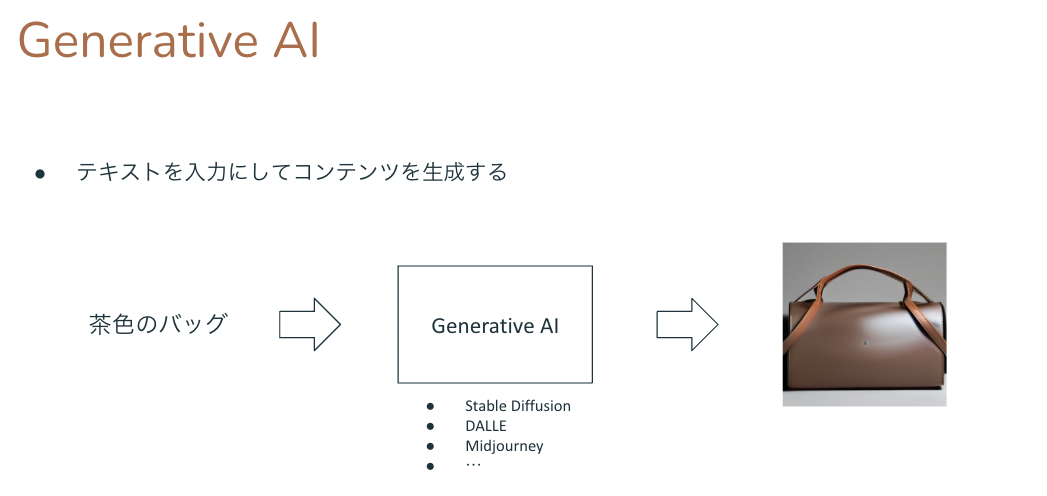
Generative AI、特にDiffusion Modelをベースにしたモデルでは、テキストを入力にして、そのテキストで説明されている状況や対象物の画像を生成します。Diffusion Modelによる生成系モデルは多々あります。Webサービスとして利用可能なものとしてOpen AIのDALL-E 2があります。または学習済みモデルや実行プログラムを含めて公開しているものとしてStable Diffusionがあります。Stable DiffusionはGoogle ColaboratoryでGPUを使って動かすことができます。いずれも手軽に画像生成を試すことができます。
テキストから画像を生成できるということは、その画像に近いベクトルの画像コンテンツを検索することも可能ということです。仕組み自体はStable DiffusionとSCaNNによる類似画像検索を組み合わせれば実現できるので、実際に作ってみました。
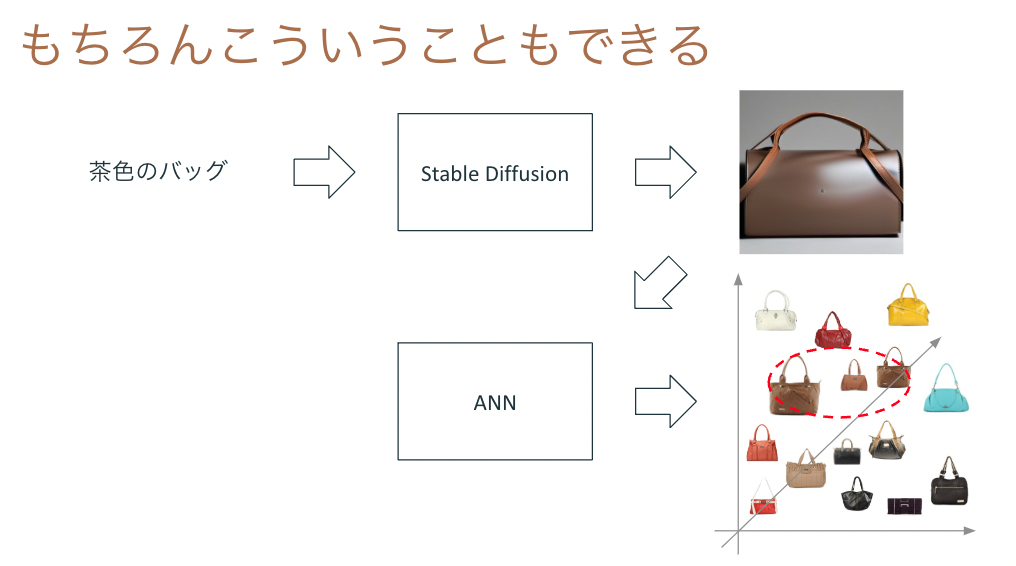
検索対象の画像コンテンツはKaggleのFashion Product Images Datasetから持ってきたファッション商品の画像を利用しています。
アーキテクチャはこんな感じです。
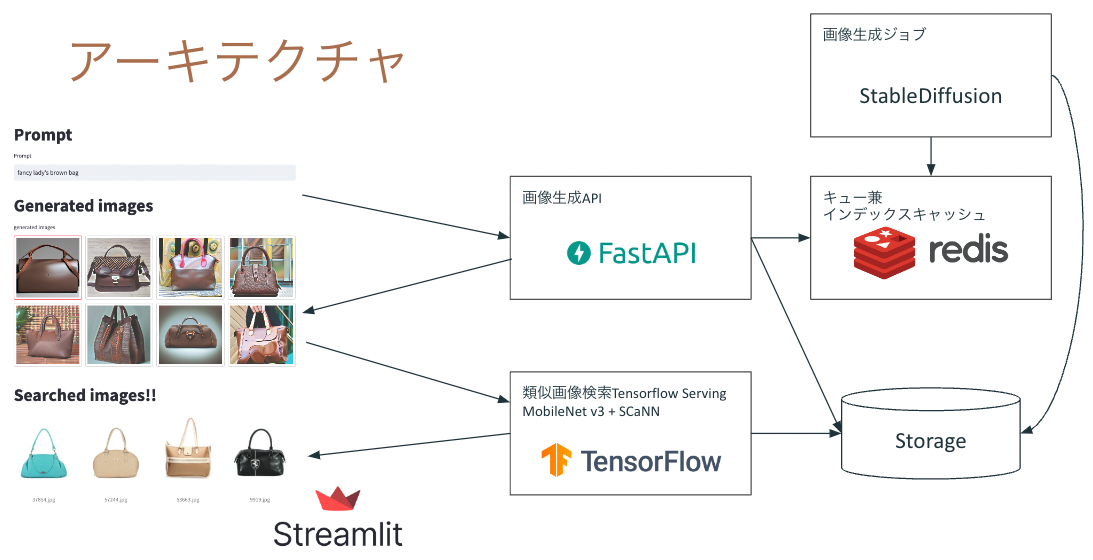
上記では入力したテキストからStable Diffusionで生成した画像を入力ベクトルとして、画像コンテンツを検索しています。仕組み自体はシンプルですが、一箇所工夫として、以前生成した画像はテキストとペアにして保存しています。Stable Diffusionの画像生成は遅いため、生成した画像自体を検索して再利用できるようにしておくことが必要です。
CLIPでマルチモーダルに検索してみる
生成した画像から類似画像検索する場合、どうしても入力テキストの情報が落脱します。テキストが生成画像で表現されていれば良いですが、常にそうとも言えません。そこで、検索時の特徴ベクトルを抽出する段階でCLIPによってテキストと画像両方の特徴量を抽出し、検索します。Fashion Product Images Datasetではファッション商品の画像だけでなく、その商品の簡単な説明文も用意されています。
テキストと画像の特徴ベクトル両方をSCaNNに埋め込んで類似ベクトル検索した結果が以下になります。
類似画像検索よりもテキストで指定しているbagやbrown、redの要素が検索に貢献しているように見えます。
アーキテクチャは以下のようになります。TensorflowのMobileNetV3で画像の特徴量抽出していた箇所を、CLIPによる画像とテキストの特徴量抽出に置き換えています。
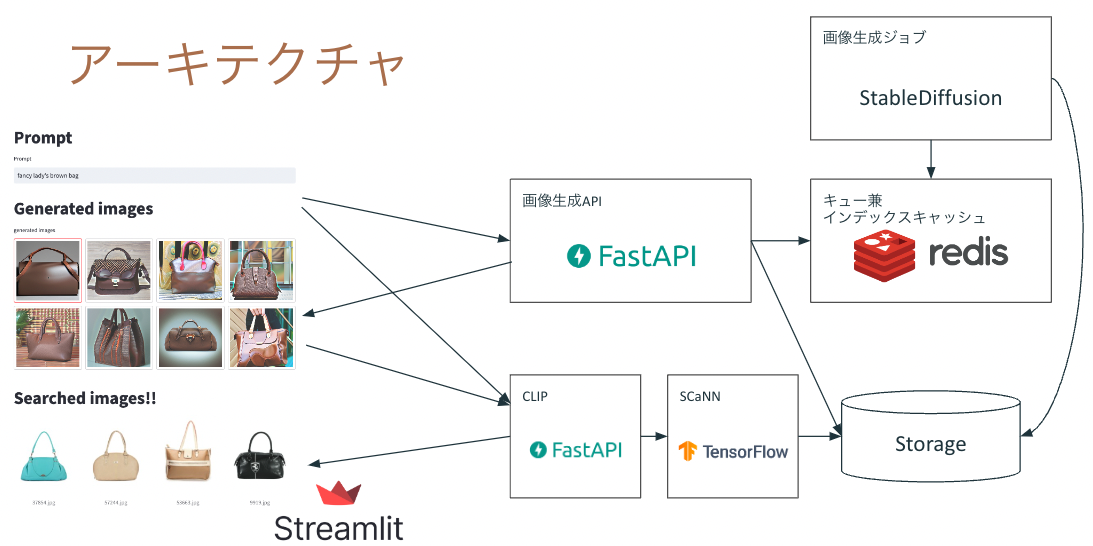
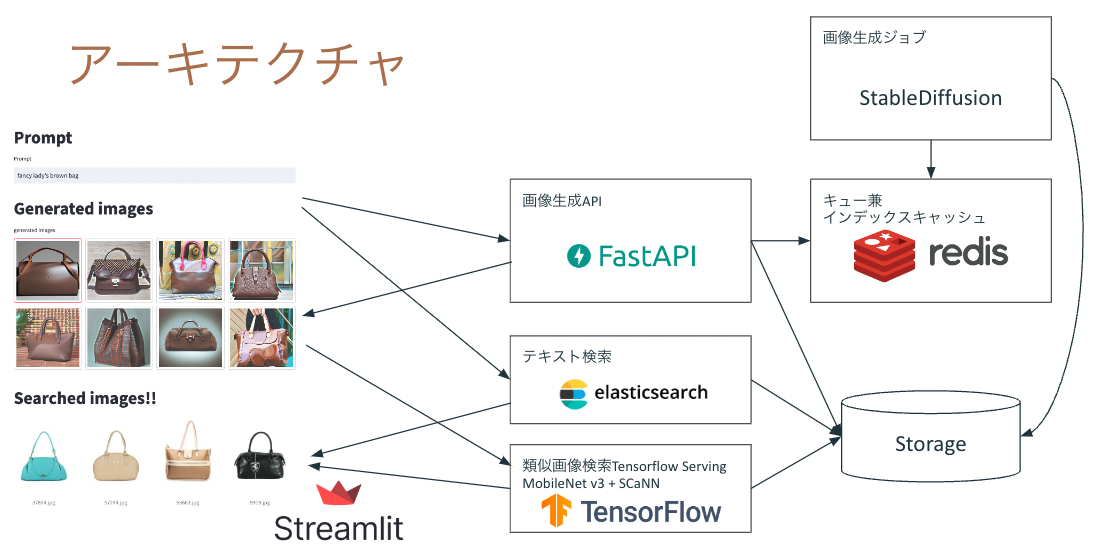
なお、単純なテキスト検索であればElasticsearchやSolrのような検索システムを使って実現するほうが一般的です。マルチモーダルに検索することに必然性がないのであれば、ElasticsearchやSolrを使うほうがおそらく手軽でしょう。その場合は類似画像検索の結果とテキスト検索の結果を何らかの評価指標に基づいて混ぜて並べたり、UIで見せ方を工夫したりする必要があります。
Generative AIと検索の可能性
従来の検索ではテキストで表現した商品や、自分が持っている画像から類似した画像を検索することができました。
今回の実験で示した新規性は、自分のほしいものをテキストと画像でデザインしながら検索できることです。特にDiffusion ModelではImage2Imageでベース画像を用意して、テキストで表現を変えたりアレンジして新しい画像を生成することが可能であるため、自分のデザインを発展させながらほしいものを鮮明にしていくことが可能です。こうした体験は従来の検索だけでは難しいでしょう。
課題
ただし、従来のサービス(EC、SNS、コンテンツサービス等々)にGenerative AIによる検索を組み込むことが簡単かというと、そうとは言い切れなさそうです。以下に実際に作ってみて苦労したことや課題になりそうなことを書きます。
遅さの問題
Diffusion Modelは画像生成のためにU-Netによるデノイズを繰り返し実行するため、相応の計算が発生します。高品質な画像を生成する手順とはいえ、GPUを使っても1枚の画像生成に数分を要するのは、Webサービスで一般ユーザに提供するには大きな壁となるでしょう。
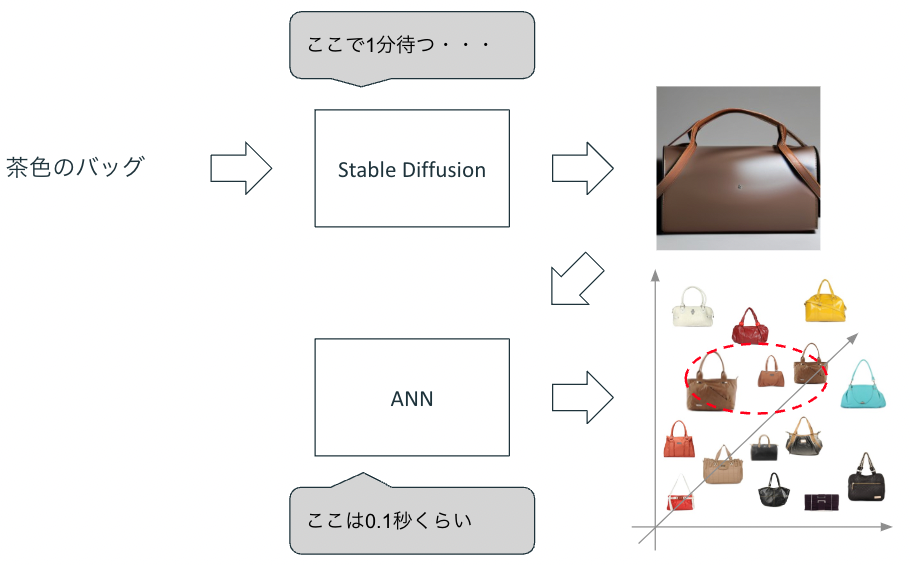
私は今回は生成済みの画像をテキストとともに保存して検索できるようにして回避しました。つまり、生成する画像を事前にキャッシュしておいて、検索可能にしておいています。この手法には明確な弱点があります。世の中のすべての検索テキストを想定して事前に生成しておくことは不可能です。さらには生成モデルの更新やImage2Imageでのテキストの組み合わせは更に多くなるため、生成画像の検索方式で完全に解決できるものではありません。
Prompt Engineeringの課題
生成モデルで適切な画像を作るためにPromptと呼ばれるテキストを書きますが、Promptは人間が一般的に使う文章とは多少異なります。人間の文章は常に何らかのコンテキスト(文脈や背景)とともに伝達されるため、コンテキストを共有しているほうが理解しやすい傾向にあります。しかし生成モデルはテキストを書く人間のコンテキストを理解しているわけではないため、一般的でない情報(家族構成や地域性、季節性、個人の立場や性格等)は考慮されません。言い換えると、現在の生成モデルで自分のほしい画像を生成するためには、生成モデルに伝わる表現をする必要があります(Prompt Engineeringという)。つまり、個々人の慣れ親しんだ表現ではなく、生成モデルに伝わる表現をしないと、自分のほしいものに辿り着くことが難しいのが現状です。

この課題に関しては、将来的には改善されていくと楽観視しています。もしかしたら人間の表現を生成モデルの言語モデルに変換するText2Textモデルが誕生するかもしれませんし、さらに個人の都合のようなデータを考慮してパーソナライズされたText2Textモデルが提供されるかもしれません。いずれにしても、生成モデルが広く使われて、Prompt Engineeringが重大な課題になっていけば解決策が提供されるでしょう(たぶん)。
生成画像の倫理と違反検知・異常検知・品質検査
AIの倫理は最近頻繁に議論されているテーマの一つです。生成画像についても同様に倫理性は求められるでしょう。たとえば日本でモザイクをかけなければならないような画像や、グロテスクな画像のように、ビジネスとして違法や違反に該当するような画像が生成される可能性は否めません。厄介なのは、そうした違反性の高い画像やグロテスクな画像を学習データに含めなければ生成を必ず回避できるというものではないことです。たとえば人間の画像が入っている場合、1つ目の顔や指が変な方向に曲がった画像が生成されることもあります。
生成される可能性のある画像を事前に検査しておくということも考えられますが、しかしすべてのテキストと画像のパターンを生成して検査することは不可能です。実際の検査では、ユーザがテキストを入力したときや、生成した画像を提示するときに、違反検知や異常検知を実施することになると思います。
こうした検査を確立することはGenerative AIの品質保証(低い品質、ありえない状況、著作権違反になる表現、倫理性の担保・・・)につながると考えられます。Generative AIを活用したプロダクトがより広まるためには、コンテンツの検知とセットで提供する必要があるでしょう。
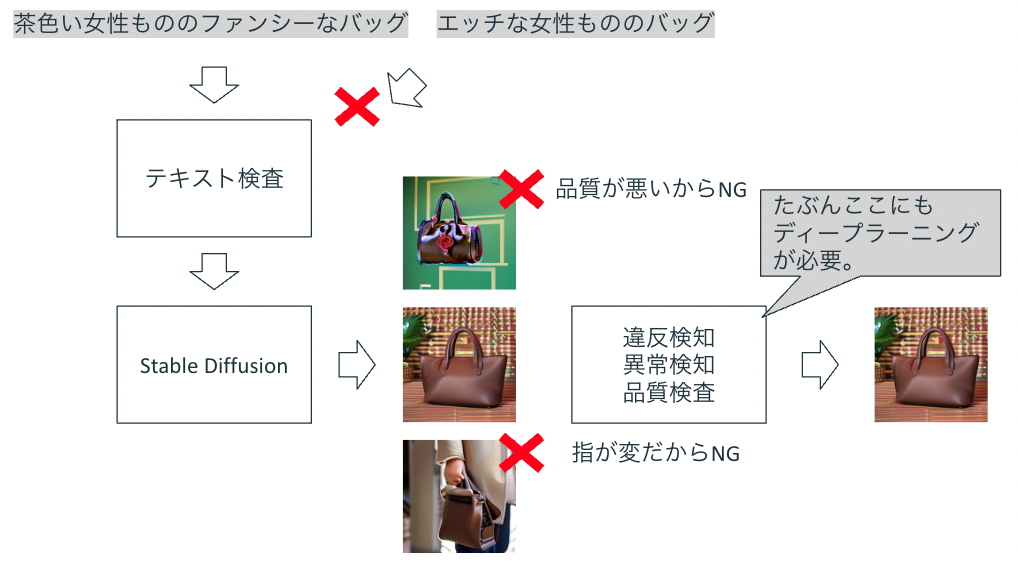
UIの課題
テキストでコンテンツを生成しながら検索する新しい体験が実用化されるために重要な要素がUIです。テキストを入力してそこから出力と検索結果を得ることを繰り返していくUIが必要になります。思いつく方式としては、LINEのようなメッセージングをベースにしたUIや、AmazonのようなECのUIへの組み込みが挙げられます。
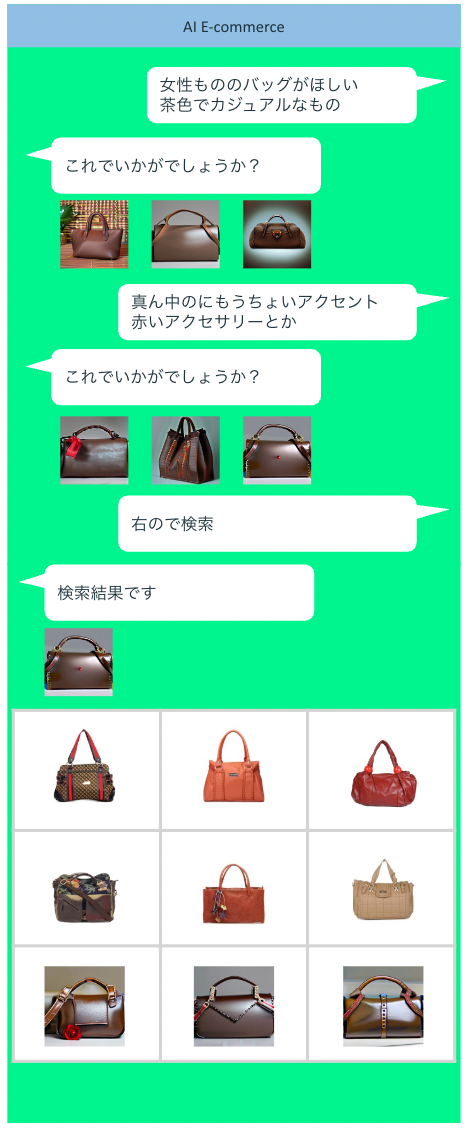
特にECの場合、検索対象の商品にはテキストが用意されているため、そのテキストから重要な単語を抽出して、その単語の組み合わせでもって画像を生成するという体験も可能でしょう。
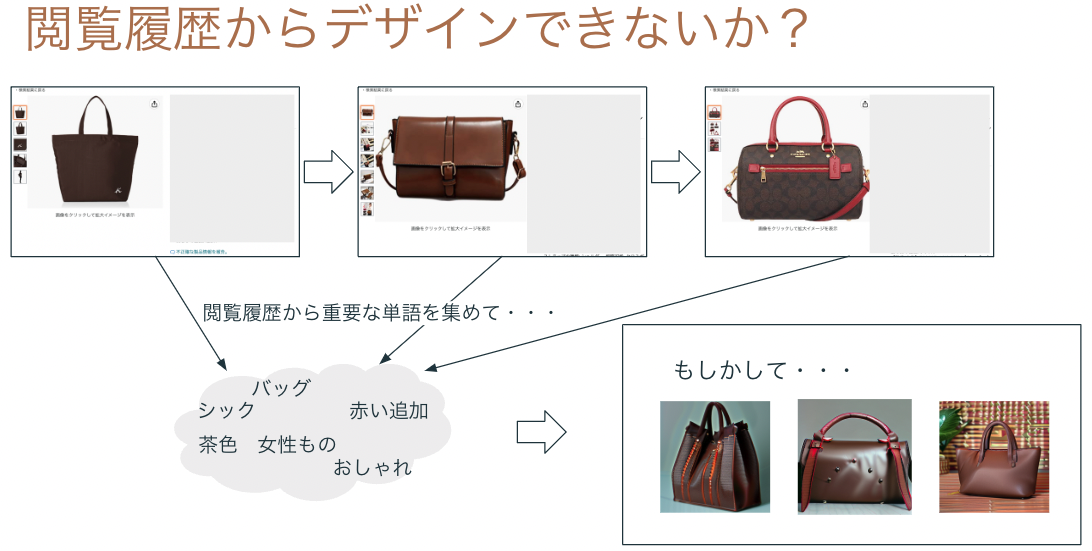
しかしいずれにしても、ほしいものをデザインしながらスムーズに生成と検索を繰り返すUIが必要になります。
まとめ
ユーザがデザインしながら検索する場合、そのデザインが常に検索対象のデータに存在しているとは限りません。Diffusion Modelに埋め込まれた表現とANN等の検索インデックスに埋め込まれたデータは必ずしも一致しないため、Diffusion Modelで表現できるけど検索できないデザインのコンテンツは存在するでしょう。そのデザインが一回きりの検索であれば良いですが、頻繁に共通点が見出だせるような特徴を持つ場合、検索コンテンツに存在しない流行が生まれていると言えるでしょう。それが複数のユーザからリクエストされるようであれば世間的な流行の可能性があるでしょうし、一人のユーザが頻繁に検索するようであればデザイナーやクリエイターが一回きりで販売するチャンスも考えられます。
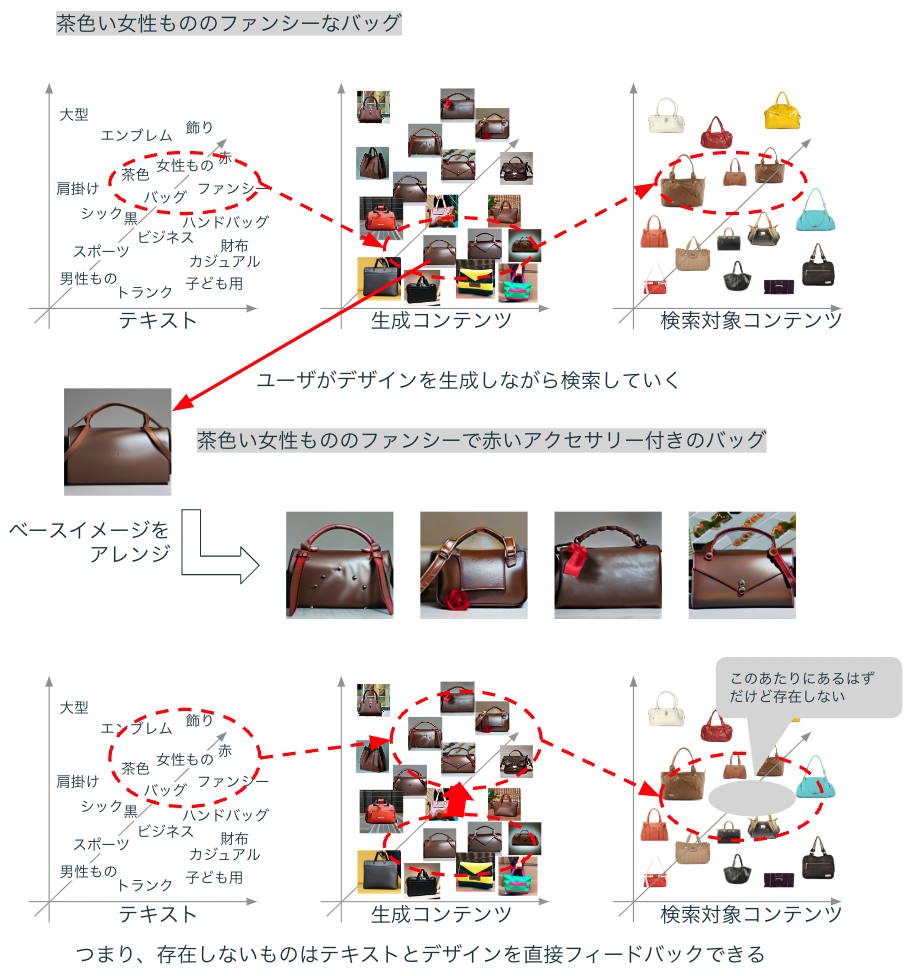
いずれにしても、Generative AIによって消費者が求めるものを自らデザインしながら検索することができるようになるかもしれません(検索や推薦同様に、もしかしたら特定の個人やグループに最適化されパーソナライズされたGenerative AIによって、最速で個人やグループの好みに合ったコンテンツ生成ができるようになるかもしれません)。そうした未来が到来した場合、ECやWebサービスの運営者はユーザの行動ログや購入ログから需要を分析するだけでなく、消費者の直接的な需要を入手できるようになるでしょう。もちろんGenerative AIと検索の組み合わせはファッションやECだけでなく、旅行や地図、本や映画、Web広告等、何らかのコンテンツやデータを用いるビジネスで活用できるでしょう。いろいろ課題はありますが、Generative AIと検索の新たな発展が楽しみです。
最後に言い訳
なんかMLOpsっぽくない妄想を垂れ流したような内容になったけど言い訳:機械学習を使って新しいことをやるときは、まずは画面を含めてプロトタイピングして体験を作りながらプレゼンすると、イメージが伝わりやすいし、実際のビジネス的・技術的課題を深堀りして共有しやすくて便利ですし、機械学習を実用化するためのコアな部分を検証できます。ということを伝えたい内容です。
メリークリスマス&良いお年を〜。