KerasとKubernetesによるディープラーニングの並列学習
KerasがCNTKに対応したことは以前書きました。
CentOSからKeras with CNTK backendを動かす
これでKerasはTheano、TensorFlow、CNTKをバックエンドにして、同じプログラムで違うフレームワークを使うことができるようになりました。
Kerasのバックエンドが増える利点は、環境変数を変更するだけでフレームワークを入れ換えて学習することができる点だと思います。
フレームワークを変えても、プログラムが同じであればニューラルネットワークのモデル自体は(たぶん)変わりませんが、精度やスピードが多少変わったりします。
または、各フレームワークで学習したモデルをアンサンブルして推論するということも可能です。
複数フレームワークのアンサンブルを思いついたので、実際にやってみました。
プログラムやKubernetesのymlは以下にあります。
https://github.com/shibuiwilliam/keras_multibackend
Kerasの複数バックエンドを並列学習する
Kerasから複数のディープラーニングフレームワークを同じプログラムで順次試すだけではつまらないので、Kubernetesを使って各フレームワークを並列で学習させてみました。
以下のようなイメージです。
順次学習させるだけではつまらない。
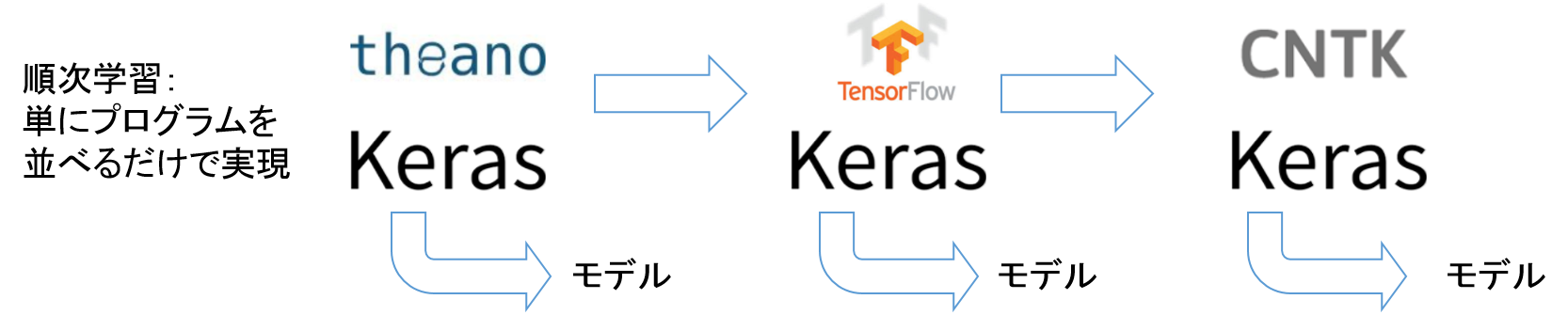
並列学習させてみる。
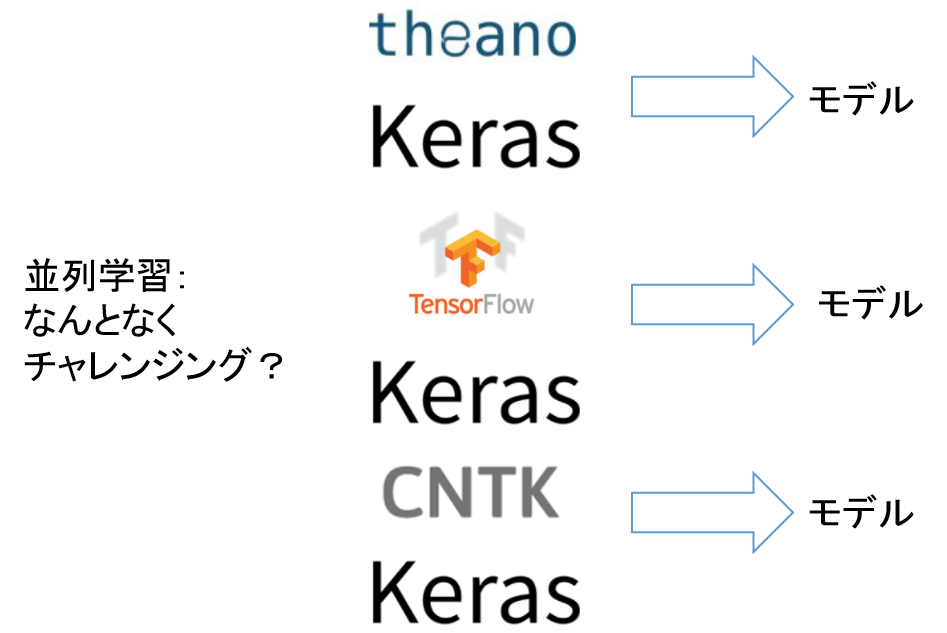
全体像
ディープラーニングをKubernetesでDockerコンテナ上で並列学習させます。
全体像としては以下のようになります。
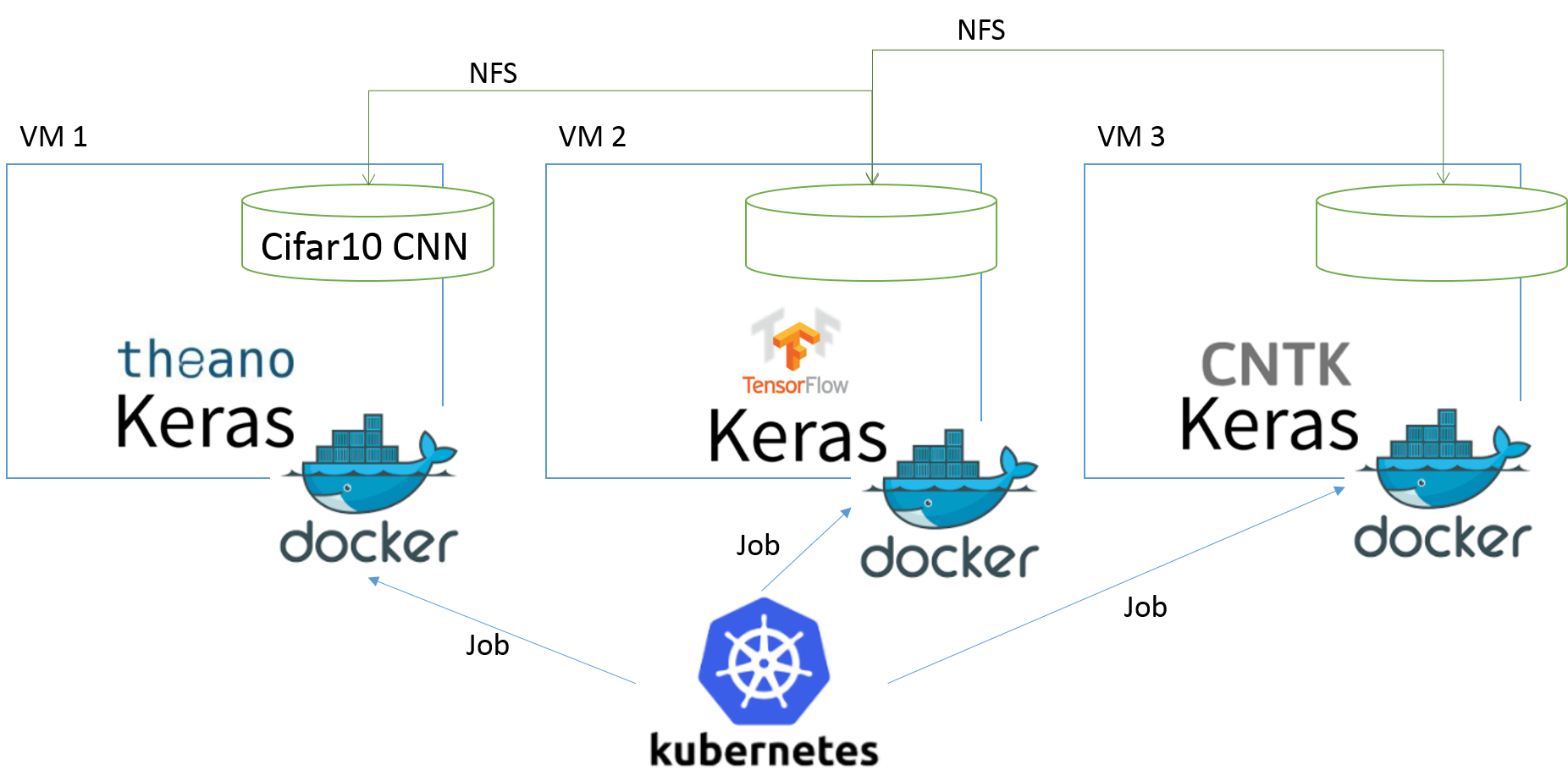
プラットフォームとプログラム両方の構成が必要です。
プラットフォーム
仮想マシンを3台用意します。今回はCentOS7.3です。
VM1をNFSサーバにし、VM2, VM3に共有ディレクトリをマウントします。
共有ディレクトリにKerasの学習用プログラムと推論用プログラムを配置します。
VM1,2,3はいずれもKerasの学習用、推論用プログラムにアクセス可能になります。
VM1,2,3でKubernetesクラスターを形成します。
Keras、Theano、TensorFlow、CNTK、その他もろもろのインストールされたDockerイメージをVM1,2,3をbuildしておきます。
なお、今回使ったDockerfileは以下にあります。
Kubernetesはjobとして各フレームワークによるCifar10のCNN学習を実行します。
Jobのymlは3種類用意します。それぞれの環境変数KERAS_BACKENDの値をTheano、TensorFlow、CNTKと定義します。
KubernetesのJob定義ymlは以下になります。
まずは学習用です。
CNTKを例示していますが、Tensorflow、TheanoはKeras_BackendのValueを変更するだけです。
apiVersion: batch/v1
kind: Job
metadata:
name: kerascntk
spec:
template:
spec:
restartPolicy: Never
volumes:
- name: nfstest
nfs:
server: 10.249.20.65
path: "/tmp/nfstest/"
containers:
- name: kerascntk
image: jupyter:1.52
volumeMounts:
- name: nfstest
mountPath: "/tmp/nfstest/"
env:
- name: KERAS_BACKEND
value: "cntk"
command: ["python"]
args: ["/tmp/nfstest/cifar_train.py"]
推論用です。
推論はPythonで3バックエンドの推論と合計を取るので、以下一つだけでOKです。
apiVersion: batch/v1
kind: Job
metadata:
name: pred
spec:
template:
spec:
restartPolicy: Never
volumes:
- name: nfstest
nfs:
server: 10.249.20.65
path: "/tmp/nfstest/"
containers:
- name: pred
image: jupyter:1.52
volumeMounts:
- name: nfstest
mountPath: "/tmp/nfstest/"
command: ["python"]
args: ["/tmp/nfstest/cifar_pred.py"]
プログラム
Kerasの学習用プログラム、推論用プログラムを用意します。
各フレームワークで分けてつくる必要はありません。
Kubernetes Jobのymlで環境変数KERAS_BACKENDを定義して分割しているので、プログラムは学習用1つ、推論用1つです。
それぞれのプログラムは以下のとおりです。
まずは学習用です。
とくに工夫はしていません。普通のVGGライクなCNNです。
エポック数は50ですが、EarlyStoppingも設定しているので、実質20エポック程度で終了するようになっています。
また、推論用で使うために、テストデータの100画像をEvaluationから外しています。
# 学習用
# see its environment variable
import os
kerasBKED = os.environ["KERAS_BACKEND"]
print(kerasBKED)
# imports
import keras
from keras.models import load_model
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.callbacks import EarlyStopping, ModelCheckpoint
import pickle
import numpy as np
# variables
batch_size = 32
num_classes = 10
epochs = 50
# loading and reshaping cifar10 data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
# leave out 100 images for prediction
x_test1 = x_test[100:,:]
x_test2 = x_test[:100,:]
y_test1 = y_test[100:,:]
y_test2 = y_test[:100,:]
print(x_test1.shape, x_test2.shape, y_test1.shape, y_test2.shape)
# only test1 data is used for validation
# VGG-like neural network model
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
opt = keras.optimizers.adam()
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
# Add checkpoint and earlystopping
chkpt = '/tmp/nfstest/cifar_weights/' + kerasBKED + '_weights.{epoch:02d}-{loss:.2f}-{val_loss:.2f}.hdf5'
cp_cb = ModelCheckpoint(filepath = chkpt, monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
es_cb = EarlyStopping(monitor='val_loss', patience=1, verbose=1, mode='auto')
# fit the model
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test1, y_test1),
callbacks=[cp_cb, es_cb],
shuffle=True)
# score and save the model
score = model.evaluate(x_test1, y_test1, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
saveDir = "/tmp/nfstest/cifar_model/"
if not os.path.isdir(saveDir):
os.makedirs(saveDir)
modelName = "{0}_{1}_model.hdf5".format(kerasBKED, score[1])
model_path = os.path.join(saveDir, modelName)
model.save(model_path)
学習の最後でモデルをNFSディレクトリに保存します。結果として3種類のモデルがNFSディレクトリに保存さてます。
推論ではこの3モデルを利用します。
推論にはテストデータから抜いておいた100画像を使います。
学習で作った3種類のモデルファイル(Theano、Tensorflow、CNTK)を呼び出して推論します。
各モデルで学習のAccuracyに差がありますので、推論にAccuracyを掛けて、最後にAccuracyの和で割っています。
アンサンブルモデルっぽくしていますが、理論的な裏付けがあるわけではありません。
# 推論用
# import
import keras
from keras.models import load_model
from keras.datasets import cifar10
import os
# variables
batch_size = 32
num_classes = 10
# load and reshape data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
x_test1 = x_test[100:,:]
x_test2 = x_test[:100,:]
y_test1 = y_test[100:,:]
y_test2 = y_test[:100,:]
# test2 data is used for prediction
# get a list of model files
backList = ["cntk", "tensorflow", "theano"]
saveDir = "/tmp/nfstest/cifar_model/"
files = os.listdir(saveDir)
filesList = [f for f in files if os.path.isfile(os.path.join(saveDir, f))]
filesList
# predict using each model
prediction = 0
sumAcc = 0
for bk in backList:
os.environ["KERAS_BACKEND"] = bk
kerasBKED = os.environ["KERAS_BACKEND"]
modelName = [m for m in filesList if bk in m][0]
modelAcc = float(modelName.split("_")[1])
print("MODELNAME {0} \t for BACKEND {1} \t with ACCURACY {2}".format(modelName, kerasBKED, modelAcc))
model = load_model(os.path.join(saveDir, modelName))
prediction += model.predict(x_test2, batch_size=batch_size, verbose=0) * modelAcc
sumAcc += modelAcc
prediction = prediction / sumAcc
print(prediction)
# output predictions to csv
import csv
with open("/tmp/nfstest/cifar_model/preds.csv", 'w') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerows(prediction)
predlist = []
for i in prediction:
pred = max(enumerate(i), key=lambda x: x[1])[0]
predlist.append([pred, i[pred]])
print(predlist)
# output overall summary to csv
import csv
with open("/tmp/nfstest/cifar_model/pred.csv", 'w') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(predlist)
やってみた結果
学習では3フレームワークともほぼ同じAccuracyに落ち着きました。
| Backend | Accuracy | Loss |
|---|---|---|
| Theano | 0.785 | 0.62 |
| TensorFlow | 0.772 | 0.63 |
| CNTK | 0.771 | 0.67 |
同じニューラルネットワークで学習しているので、当たり前です。
しかし、推論になると多少バックエンドで差が出ます。
以下に10個のテストデータを各バックエンドで推論した一覧表を記載します。
(上記のプログラムでは100個の画像データで推論していますが、多すぎるので10個にしぼります)
1つ目の画像データに対して、CNTKが4が49.498%と推論しているのに対して、TensorflowとTheanoは3をそれぞれ55.225%、67.820%と推論しています。
各バックエンドの推論とAccuracyを掛けて合計したものをAccuracyの合計で割ると、結果として3を57.855%と推論したことにします。
なお、各画像データの正解はensembleの左にanswerとして記載しています。
\frac{0.49498 * 0.771 + 0.55225 * 0.772 + 0.67820 * 0.785}{0.771 + 0.772 + 0.785} \\
= 0.57855
2つ目の画像データはCNTK、Tensorflow、Theanoともに8です。
しかし、3つ目のデータには、CNTKが0を41.421%、Tensorflowが8を72.917%、Theanoが1を52.288%としています。
| data | backends | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | cntk | 0.039% | 0.053% | 2.518% | 11.623% | 49.498% | 6.068% | 4.404% | 2.736% | 0.075% | 0.108% |
| tensorflow | 0.049% | 0.002% | 0.289% | 55.225% | 0.055% | 20.520% | 0.399% | 0.143% | 0.495% | 0.015% | |
| theano | 0.002% | 0.005% | 0.028% | 67.820% | 0.068% | 3.543% | 6.598% | 0.017% | 0.027% | 0.347% | |
| answer:3 | ensemble | 0.039% | 0.026% | 1.218% | 57.855% | 21.318% | 12.945% | 4.898% | 1.244% | 0.257% | 0.202% |
| 2 | cntk | 19.015% | 6.447% | 0.027% | 0.125% | 0.007% | 0.001% | 0.001% | 0.004% | 51.443% | 0.052% |
| tensorflow | 0.000% | 0.019% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 77.173% | 0.000% | |
| theano | 0.045% | 2.147% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 76.233% | 0.030% | |
| answer:8 | ensemble | 8.188% | 3.700% | 0.012% | 0.053% | 0.003% | 0.000% | 0.000% | 0.002% | 88.006% | 0.035% |
| 3 | cntk | 41.421% | 2.234% | 0.902% | 0.223% | 1.573% | 0.006% | 0.062% | 0.070% | 21.528% | 9.104% |
| tensorflow | 1.056% | 3.040% | 0.000% | 0.028% | 0.000% | 0.000% | 0.002% | 0.000% | 72.917% | 0.147% | |
| theano | 0.356% | 52.288% | 0.012% | 0.305% | 0.005% | 0.000% | 0.001% | 0.001% | 23.977% | 1.508% | |
| answer:8 | ensemble | 18.402% | 24.729% | 0.393% | 0.239% | 0.678% | 0.003% | 0.028% | 0.031% | 50.876% | 4.622% |
| 4 | cntk | 44.158% | 6.019% | 1.613% | 4.033% | 1.339% | 0.091% | 0.133% | 0.150% | 11.250% | 8.334% |
| tensorflow | 68.420% | 0.740% | 0.175% | 0.296% | 0.010% | 0.004% | 0.029% | 0.006% | 6.932% | 0.580% | |
| theano | 37.302% | 2.057% | 0.594% | 2.029% | 0.348% | 0.086% | 0.043% | 0.029% | 33.511% | 2.455% | |
| answer:0 | ensemble | 64.391% | 3.788% | 1.023% | 2.731% | 0.729% | 0.078% | 0.088% | 0.079% | 22.208% | 4.884% |
| 5 | cntk | 0.005% | 0.001% | 27.413% | 1.284% | 8.657% | 0.023% | 39.720% | 0.001% | 0.017% | 0.001% |
| tensorflow | 0.000% | 0.000% | 0.020% | 0.884% | 71.491% | 0.001% | 4.796% | 0.000% | 0.000% | 0.000% | |
| theano | 0.000% | 0.000% | 2.550% | 0.190% | 1.722% | 0.000% | 73.993% | 0.000% | 0.000% | 0.000% | |
| answer:6 | ensemble | 0.002% | 0.000% | 12.881% | 1.013% | 35.172% | 0.011% | 50.913% | 0.000% | 0.007% | 0.000% |
| 6 | cntk | 0.001% | 0.000% | 3.774% | 23.424% | 8.258% | 0.708% | 40.913% | 0.036% | 0.001% | 0.005% |
| tensorflow | 0.002% | 0.000% | 0.401% | 41.210% | 1.115% | 4.864% | 29.589% | 0.006% | 0.004% | 0.001% | |
| theano | 0.000% | 0.000% | 0.009% | 0.263% | 0.005% | 0.072% | 78.107% | 0.000% | 0.000% | 0.000% | |
| answer:6 | ensemble | 0.001% | 0.000% | 1.797% | 27.881% | 4.029% | 2.425% | 63.844% | 0.018% | 0.002% | 0.003% |
| 7 | cntk | 3.350% | 0.113% | 14.258% | 12.193% | 0.190% | 4.802% | 0.295% | 41.802% | 0.021% | 0.097% |
| tensorflow | 0.048% | 41.460% | 0.462% | 9.073% | 0.000% | 0.737% | 0.079% | 0.602% | 0.044% | 24.686% | |
| theano | 0.008% | 49.193% | 0.053% | 2.381% | 0.001% | 0.065% | 0.183% | 0.015% | 0.024% | 26.531% | |
| answer:1 | ensemble | 1.463% | 38.994% | 6.347% | 10.159% | 0.082% | 2.408% | 0.240% | 18.224% | 0.038% | 22.045% |
| 8 | cntk | 0.014% | 0.001% | 14.742% | 5.123% | 42.021% | 0.048% | 15.141% | 0.020% | 0.008% | 0.004% |
| tensorflow | 0.108% | 0.000% | 9.300% | 6.686% | 31.076% | 0.310% | 29.625% | 0.072% | 0.008% | 0.007% | |
| theano | 0.023% | 0.000% | 33.777% | 0.185% | 1.431% | 0.096% | 42.927% | 0.013% | 0.002% | 0.000% | |
| answer:6 | ensemble | 0.062% | 0.000% | 24.840% | 5.153% | 32.018% | 0.195% | 37.674% | 0.046% | 0.007% | 0.005% |
| 9 | cntk | 0.005% | 0.000% | 4.104% | 43.597% | 17.353% | 5.953% | 5.485% | 0.624% | 0.000% | 0.001% |
| tensorflow | 0.000% | 0.000% | 0.067% | 70.856% | 2.242% | 3.932% | 0.091% | 0.004% | 0.000% | 0.000% | |
| theano | 0.000% | 0.000% | 0.001% | 78.418% | 0.011% | 0.021% | 0.002% | 0.003% | 0.000% | 0.000% | |
| answer:3 | ensemble | 0.002% | 0.000% | 1.792% | 82.860% | 8.423% | 4.256% | 2.396% | 0.271% | 0.000% | 0.000% |
| 10 | cntk | 8.810% | 7.715% | 8.225% | 13.706% | 6.575% | 3.413% | 8.631% | 4.522% | 5.751% | 9.773% |
| tensorflow | 0.482% | 68.974% | 0.012% | 0.014% | 0.001% | 0.001% | 0.213% | 0.000% | 4.088% | 3.405% | |
| theano | 0.480% | 48.363% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 3.134% | 26.477% | |
| answer:1 | ensemble | 4.199% | 53.724% | 3.539% | 5.895% | 2.825% | 1.467% | 3.799% | 1.943% | 5.574% | 17.036% |
眺めていくと面白いのは、個々のバックエンドだと不正解のものでも、アンサンブルしてみると正解になる点です。
例えば画像3はCNTK,Tensorflow,Theanoが別々の推論をしていますが、Tensorflowが最も高い確率で8を推論しているため、アンサンブルも8になります。
まとめ
学習フェーズでは、いずれのバックエンドも大差ない精度になりました。
しかし推論させてみると、各々で違う結果を出すことがあります。
さらにアンサンブルすることで、1バックエンドで推論するよりも高い精度で正解を得られるようです。
Kubernetesで並列学習させることは成功しました。
Kubernetes Jobでクラスター内で指定したプログラムを実行してくれるので、とても便利です。
KubernetesにはCron Jobもあって、時限式でJob実行できるようです。
ディープラーニングの学習計画にあたり、KubernetesのCron Jobで自動化すると便利な気がします。
というわけで、次回はKubernetes Cron Jobによるディープラーニング学習の自動実行を検証してみます。