ソフトウェアやWebアプリケーションにAIエージェントを組み込むことが広まってきていると思います。皆様の会社でも、アプリケーションにAIエージェントを追加して利便性や体験を改善する取り組みがあるのではないでしょうか?
AIエージェントの浸透に伴い、各システムにLLMやAIエージェントのObservabilityを組み込む監視設計することも増えているでしょう。そのメトリクスとして多くのチームが真っ先に意識するのは「LLM API のトークン課金」だと思います。LangFuseやLangSmithのようなLLM用監視ツールをインストールし、ダッシュボードを睨み、プロンプトを削り、モデルを使い分け、キャッシュを検討するーーこれはこれで正しい取り組みです。
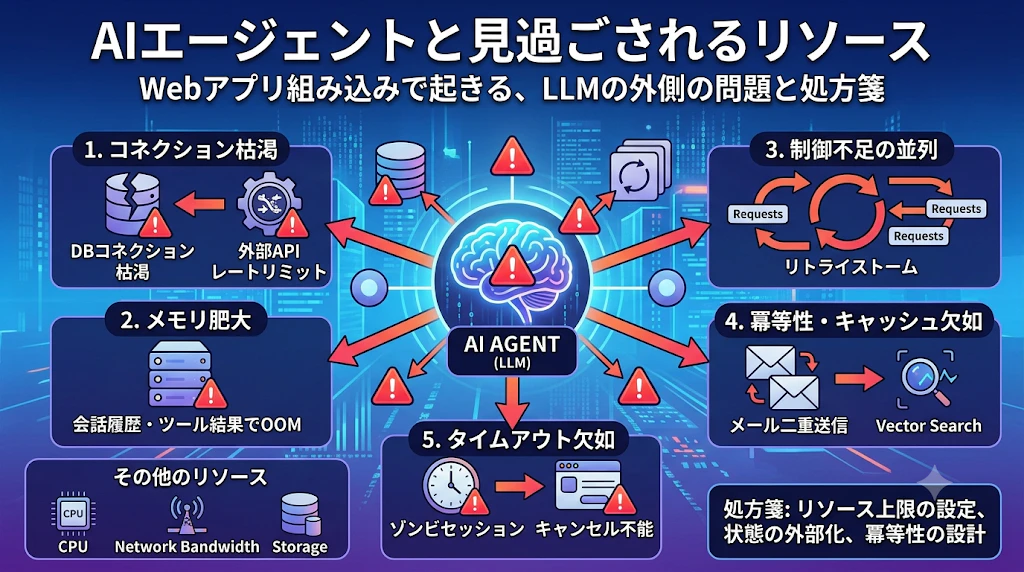
しかし実運用に乗せてみると、別のところから問題が噴き出すことが多々あります。たとえば以下のようなケースは散見されますし、私も経験しています。
- 並列に動かしたら外部APIにレートリミットで弾かれる。
- タイムアウトが効かずプロセスがハングする。
- RDBコネクションが枯渇する。
- メモリが膨らみOOMで落ちる。
いずれも LLMの外側で起きる、見過ごされがちなリソース問題 です。
多くの場合、これらの根本原因は共通しています。従来のWebアプリは前提として「リクエストが短時間、ステートレス、予測可能」という性質を持ちます。Webスタックの各レイヤは、その前提のうえで何十年もチューニングされてきました。しかしAIエージェントを組み込んだソフトウェアでは、この前提が適用されるとは限りません。前提が崩れれば、当然どこかで歪みが生じます。
この記事では、Webアプリケーションに AIエージェントを導入したときに 見過ごされがちなリソース問題 を、レイヤごとに整理します。最後に、それらに通底するアンチパターンと処方箋をまとめます。
1. コネクション・ソケット系
典型的で顕在化しやすいのがコネクション問題です。
従来のWebリクエストは数百ミリ秒で完結する前提でコネクションプールがサイジングされています。ところがAIエージェント処理は数秒から数十分かかる可能性があります。ナイーブに実装すると、その間コネクションを握りっぱなしになるでしょう。
何が起きるか
# アンチパターン: エージェントセッションがDBコネクションを保持し続ける
class AgentSession:
def __init__(self, user_id: str):
self.user_id = user_id
self.conn = None # エージェントが保持するDBコネクション
async def start(self):
# エージェント開始時にプールからコネクションを取得し、
# セッション全体を通じて保持する
self.conn = await db_pool.acquire()
async def run(self, query: str):
# 自身のコネクションで初期コンテキストを取得
context = await self.conn.fetch(
"SELECT * FROM context WHERE user_id = $1", self.user_id
)
# LLM応答を数十秒待つ間、コネクションは握ったまま遊休状態
plan = await llm.complete(prompt(context, query))
for step in plan.steps:
# ツール実行(外部API呼び出し等)の間もコネクションは保持されたまま
result = await execute_tool(step)
# 同じコネクションを使い回してDBに書き込む
await self.conn.execute("INSERT INTO agent_log ...", result)
return plan
async def close(self):
# コネクションが返却されるのはエージェント処理が全て終わった後(数十分後)
await db_pool.release(self.conn)
このコードは、エージェントセッションの全寿命にわたってコネクションを占有します。同時に走るエージェントが10個いれば、それだけでプールから10コネクションが消費されます。LLM応答待ちの間、他のWebリクエストはコネクション待ちで詰まるでしょう。
問題はRDBだけではありません。同じ構造の問題はWebアプリのあらゆるコネクション層で同時発生するでしょう。
- HTTPクライアントのコネクション: 外部API・LLMプロバイダへの keep-alive が並列ツール呼び出しが増大する
- Redis / Memcached の接続数: ワーカー数 × エージェント並列度で線形増加
- gRPC / メッセージブローカのチャネル: 長寿命なエージェントが切断検知できず半開状態で滞留
- WebSocket / SSE: クライアントへのストリーミング配信用ソケットがエージェント処理時間ぶん占有
- ファイルディスクリプタ上限: 上記すべてが合算され、OSの ulimit に到達する
改善案
コネクションは「使う直前に借り、使い終わったら即返す」ことを推奨します。そもそもライフサイクルの異なるエージェントセッションとRDBコネクションの寿命を切り離すことが重要です。トランザクションも同様で、LLM呼び出しや外部APIを跨ぐことは避けます。
# 推奨: コネクションは個々のDB操作の単位で借りて返す
async def run_agent(user_id: str, query: str):
# コネクションは借りない
context = await db.fetch_one("SELECT * FROM context WHERE user_id = $1", user_id)
# LLM呼び出し中、コネクションは解放されている
plan = await llm.complete(prompt(context, query))
for step in plan.steps:
result = await execute_tool(step)
# 書き込み時だけ短いトランザクション
await db.execute("INSERT INTO agent_log ...", result)
プールサイズも「エージェント同時実行数」だけでなく「同時にアクティブなDB操作数」でも見積もると良いでしょう。エージェント並列度100でも、実際にDBを叩いている瞬間が常時10程度なら、プールは 10 + α あれば足りるのです。
2. メモリ・ヒープ系
続いてメモリについて考えます。ここで言うメモリは所謂エージェントメモリではなく、コンピュータ基盤のメモリです。
エージェントは「会話履歴」「中間状態」「ツール出力」といったコンテキストをプロセス内に保持しがちで、ナイーブな実装ではコンテキストは無制限に増大します。
よくある失敗
# アンチパターン: 会話履歴とツール結果を全部メモリに蓄積
class Agent:
def __init__(self):
self.messages = [] # 全会話履歴
self.tool_results = [] # 全ツール結果(生データ)
async def run(self, query: str):
self.messages.append({"role": "user", "content": query})
for _ in range(MAX_STEPS): # 多段の推論ループ
# 毎ターン、全履歴 + 全ツール結果をそのままLLMに送信
response = await llm.complete(
messages=self.messages,
context=self.tool_results, # 1万行のDBダンプも含まれ得る
)
self.messages.append({"role": "assistant", "content": response.text})
if response.tool_call:
# ツール結果を生のまま保持(数MBの画像バッファ、巨大なJSON等)
raw_result = await execute_tool(response.tool_call)
self.tool_results.append(raw_result)
self.messages.append({"role": "tool", "content": raw_result})
return self.messages[-1]
この実装は、ステップを重ねるごとに messages と tool_results の文量が単調増加します。ツールの結果が大きければ1ステップで数十MBも膨らみますし、結果としてLLMへの入力トークン数もO(n²)で増えていきます。Pythonの場合、asyncio のタスクが互いに参照を持ち合うとGCで回収されず、メモリリークの調査も難しくなります。
典型的な肥大化パターン
- 会話履歴の累積: メッセージ配列を持ち回るうちに巨大化し、GC圧迫
- ツール結果の生データ保持: DBクエリ結果やスクレイピング結果を要約せず丸ごとメモリに展開
- 添付ファイル・画像のデコード済みバッファ: マルチモーダル入力が解放されず滞留
- ベクトル埋め込みのオンメモリキャッシュ: RAGで全件をプロセスメモリに載せる素朴な設計
- ストリーミング応答のバッファリング: 逐次返さず全文蓄積してから返す実装
特に厄介なのが「 中間結果をそのまま次のサブタスクへ渡してしまう 」パターンです。たとえば「データベースから1万行取得 → LLMに要約させる → 結果をユーザに返す」というフローを考えます。取得した1万行のオブジェクトをそのままLLMに送ろうとして、コンテキスト上限に弾かれてから初めて問題に気づく、ということが起こり得ます。
改善案
中間データは早期に要約または参照化することを推奨します。
# アンチパターン
rows = await db.fetch_all("SELECT * FROM orders WHERE ...") # 1万行
summary = await llm.complete(f"以下を要約: {rows}") # X コンテキスト増大
# 推奨: 必要なフィールドだけ抽出 → 縮約してから渡す
rows = await db.fetch_all("SELECT id, amount, status FROM orders WHERE ...")
aggregated = aggregate_by_status(rows) # 数件の集計に
summary = await llm.complete(f"以下の集計を解釈: {aggregated}")
要約するか、参照化するかはAIエージェントのロジックやユースケースによって検討します。ざっと選択方法を分けると、常に情報が必要であれば要約し、必要なときだけ思い出せば良い場合は参照化します。
エージェントの状態は**プロセスメモリではなく外部ストア(ストレージ等)**に置く、というのも重要です。後述するライフサイクル管理やスケーリングの議論にも直結します。
3. 同時実行・並列性の制御不足
エージェントが「複数のツールを並列実行」できることは強力な機能ですが、制御なしに並列化すると後段の処理で障害になる可能性があります。
よくある失敗
# アンチパターン: 並列度の上限なし
async def search_all_sources(query: str):
sources = await db.fetch_all("SELECT * FROM sources") # 数百件
results = await asyncio.gather(*[
fetch_from_source(s, query) for s in sources # 全部同時に発火
])
return results
これは内部API・外部APIを問わず、相手側で簡単にレートリミットやサーキットブレーカに到達します。さらに悪いことに、エージェントが「失敗したらリトライ」と設定されている場合、再度全件並列リトライをかける、いわゆる リトライストーム が発生し、自分自身のサービスをDoS攻撃してしまいます。
他にも次のような問題があります。
- バックプレッシャの欠如: エージェントが処理しきれない速度でイベントを生成
- ワーカープールの誤サイジング: I/O待ち中心のエージェントにCPUコア数基準のワーカー数を割り当て、実質シリアル実行
- スレッド / ファイバーリーク: 中断されたエージェントの子タスクが残留
- デッドロック: 複数エージェントが同じ行ロックや分散ロックを取り合う
改善案
原則として、並列度には明示的な上限を設けると良いでしょう。セマフォ、キュー、専用のレートリミッタなど、適切な手段を選定して、「書いていなければ無制限になり得る」ことに対策することが重要です。
# 推奨: 並列度に上限
sem = asyncio.Semaphore(10)
async def fetch_with_limit(source, query):
async with sem:
return await fetch_from_source(source, query)
results = await asyncio.gather(*[
fetch_with_limit(s, query) for s in sources
])
リトライも同様で、指数バックオフ + ジッタ + 最大試行回数を必ずセットで設計します。エージェントが「賢く」リトライを判断する前に、機械的に止める仕組みを置くのが鉄則です。
4. キャッシュ・冪等性の欠如
エージェント処理は従来のソフトウェアに比べて 非決定的でリトライが頻発 します。にもかかわらず、キャッシュも冪等性も考慮されていない実装を多々見かけます。
よくある失敗
# アンチパターン: 冪等性なしのリトライで二重実行が起きる
async def send_invoice_email(user_id: str, amount: int):
for attempt in range(3):
try:
# 初回は成功したが、応答が返る前にネットワークエラーになった場合、
# クライアント側ではタイムアウト扱いになり、リトライが走る
return await mail_provider.send(user_id, f"請求額: {amount}円")
except NetworkError:
await asyncio.sleep(2 ** attempt)
continue # 実は前回送信成功していてもリトライ → 二重送信
# アンチパターン: 決定的な処理をキャッシュせず毎回呼び出す
async def search_similar_docs(query: str):
# 同じクエリでも毎回 embedding API を叩く(課金 + レイテンシ)
embedding = await embedding_model.embed(query)
# 同じクエリでも毎回ベクトル検索を実行
return await vector_db.search(embedding, top_k=10)
特に上のメール送信は、エージェントが「ツール実行が失敗したように見えたから再実行しよう」と判断するだけで、ユーザに同じ請求メールが2通届く事故になります。エージェントの非決定性とリトライの組み合わせは、副作用のあるツールにとって危険です。
何が起きるか
- 同一プロンプトの再実行: 決定的なクエリでも毎回LLM呼び出し
- プロンプトキャッシュ未活用: プロバイダ側のプロンプトキャッシュ機能を使わず、長いsystem promptを毎回送信
- 冪等性キーなしのリトライ: ネットワークエラーで再試行 → 同じ書き込みが二重適用
- RAG検索結果のキャッシュ無し: 同じ質問で毎回ベクトル検索
特に深刻なのは二重書き込みでしょう。例えば、エージェントが「メール送信ツール」を呼び、ネットワークタイムアウトで失敗を検知してリトライしたが、しかし実は最初の呼び出しは成功していて、メールが2通送られるーーお金の動く処理なら大事故です。
改善案
エージェントが呼ぶ外部副作用のあるツールには、必ず冪等性キーを設計すると良いでしょう。
# 推奨: 冪等性キーで二重実行を弾く
async def send_email(to: str, body: str, idempotency_key: str):
existing = await db.fetch_one(
"SELECT result FROM idempotency WHERE key = $1", idempotency_key
)
if existing:
return existing.result # 既に実行済み
result = await mail_provider.send(to, body)
await db.execute(
"INSERT INTO idempotency (key, result) VALUES ($1, $2)",
idempotency_key, result
)
return result
キャッシュも、決定的に同じ結果になる処理には積極的に適用すると良いでしょう。同じテキストの埋め込みベクトル、同じクエリのRAG結果、安定したsystem promptのプレフィックス ―― これらはキャッシュ候補と言えます。
5. タイムアウト・ライフサイクル管理
最後に、地味ですが本番障害に直結しやすいのがタイムアウトとライフサイクル管理です。
よくある失敗
# アンチパターン: HTTPハンドラ内で同期的にエージェントを実行
@app.post("/agent/run")
async def run_agent_endpoint(request: Request):
query = request.json["query"]
# タイムアウト指定なし、キャンセル機構なし
# ユーザがブラウザを閉じてもバックエンドの処理は続行する
result = await agent.run(query)
return {"result": result}
# アンチパターン: 各層のタイムアウトが未設定、もしくは整合していない
async def call_tool(tool_name: str, args: dict):
# LLM呼び出しにタイムアウト無し → 上流(HTTP)のタイムアウトより長くハングし得る
plan = await llm.complete(...)
# HTTPクライアントのタイムアウトも未設定
return await http_client.post(f"https://tool.example/{tool_name}", json=args)
このエンドポイントの場合、ユーザが30秒で諦めてブラウザを閉じても、サーバ側のエージェントは止まりません。LLMにトークンを送り続け、DBを書き続け、外部APIを叩き続けるーーつまり、誰も見ていないところでコストだけが発生し続けるわけです。さらに、各層のタイムアウトが整合していないと、HTTPは切れてもLLM呼び出しは継続している、という捻れた状態も発生します。
何が起きるか
- タイムアウト未設定: 各層(HTTP・LLM・ツール・DB)でタイムアウトがバラバラまたは未設定で、ハングが累積
- キャンセル伝播の欠如: ユーザが画面を閉じてもバックエンドのエージェントが走り続ける
- ゾンビセッション: クラッシュしたエージェントの中間ロックやセマフォが残留
- リソースクリーンアップ漏れ: 一時ファイル・一時テーブル・サンドボックス環境が残る
- ロードバランサの idle timeout: ALB/NLBの上限よりエージェント処理が長く、勝手に切断される
特にやっかいなのが「キャンセルされたエージェント」の滞留です。ユーザは数十秒待って諦め、ブラウザを閉じるが、しかしバックグラウンドではエージェントが処理を続け、LLMにトークンを送り続け、DBを書き続け、外部APIを叩き続けるーーユーザのいないところでコストだけが発生し続けるわけです。
改善案
タイムアウトとキャンセルは設計の最初に決めることを推奨します。
- 各層のタイムアウトは「内側 < 外側」の順で短く設定(DB < ツール < LLM < エージェント全体 < HTTP)
- 非同期ジョブとして実行し、キャンセルAPIを用意する
- 状態は外部ストアに小刻みに保存し、途中で失敗・停止しても途中から再開できるようにする
- 一時リソースは明示的なTTLを持たせ、忘れられても勝手に消える設計にする
エージェントを「いつでも安全にキャンセルできる」状態に保つことが、運用上の柔軟性と安全性の前提になります。
6. その他の見過ごされやすい領域
上記に加えて、以下も短く触れておきます。実プロジェクトではこれらも問題化することが多々あるでしょう。
- CPU: トークナイザの繰り返し実行、JSON Schemaの再コンパイル、埋め込みの再計算など、LLM外で意外と消費する
- ネットワーク帯域: 会話履歴全体を毎ターン送る冗長性、無圧縮でツール結果を扱う、TLSハンドシェイクの繰り返し
- ストレージ: 全思考過程の生ログ保存、会話履歴のO(n²)蓄積、ベクトルDBの孤児エントリ、無期限キャッシュ
-
オブザーバビリティ自体のコスト: 全LLM入出力テキストの同期ロギング(≒大容量ログ)、span生成過多、メトリクスのカーディナリティ爆発
- オブザーバビリティは重要だが、観測を入れすぎてパフォーマンスを落とすのは失敗の典型例
- セキュリティ起因のコスト: ツール権限チェックの認可サーバ往復、コード実行サンドボックスのコールドスタート、監査ログの同期I/O
- インフラ層: CPU基準のオートスケールがI/O待ちエージェントを評価できない、コンテナのコールドスタート、CDN/プロキシのバッファリングでストリーミングのTTFB悪化
いずれも「 従来のWebアプリの常識的なチューニングが、エージェントの長時間・非決定的な性質に対して効くとは限らない 」ことが共通していると言えます。
7. 横断的な設計上のアンチパターン
ここまで個別の問題を見てきましたが、これらを生み出している根本的な設計の癖は、実は数えるほどしかありません。
同期的なエージェント実行:HTTPリクエスト・レスポンスの中でエージェント処理を完結させようとする設計です。これをやると、コネクション占有・タイムアウト・キャンセル不能・ロードバランサ切断が問題となります。回避策の一つとして「非同期ジョブとして起動し、進捗をSSEやポーリングで返す」ことを検討しましょう。
ステートフルなエージェントインスタンス:プロセスメモリに状態を持ち、特定ノードに固定する設計です。これをやると水平スケール不能・障害復旧不能・デプロイで状態消失、と運用上の柔軟性を失います。状態は外部ストアへ、プロセスはステートレスへ設計することを推奨します。
「とりあえずLLMに投げる」設計:ルールベースで済む判断、決定的な計算、構造化された分岐 ―― これらまでLLMに任せると、コストもレイテンシも非決定性も悪化します。LLMは「判断が曖昧で、構造化が難しく、自然言語の理解が必要な部分」に限定して使い、残りは普通のコードで書くのが鉄則です。
エージェントをブラックボックスとして扱う:内部のサブタスク・ツール呼び出し・LLMコールを可視化せず、リソース問題が起きてから原因特定に走る設計です。エージェントは最初から内部を観測可能に作ることを原則とします。トレーシング、構造化ログ、サブタスク単位のメトリクス等の後付けは手間がかかります。
まとめ
長くなったので、最後に処方箋を3行にまとめます。
第一に、エージェントの時間軸とリソースの時間軸を分離する:エージェントは数秒〜数十分動きます。一方コネクション、ロック、メモリバッファは数ミリ秒〜数秒で完結すべきリソースです。両者を縛り付けないように設計し、短命であるべきものを長命なエージェントセッションに紐づけないように実装します。
第二に、境界ごとに明示的な上限を設ける:並列度、メモリ、時間、トークン、リトライ回数、コネクション数 ―― いずれも「書いていなければ無制限となり得る」のです。エージェントは賢く振る舞いますが、賢さは上限の代わりにはなりません。機械的に止める仕組みを置くべきです。
第三に、状態は外部化し、処理は冪等にする:これでスケール・障害復旧・キャンセル・観測が容易になります。プロセスはいつでもキャンセルできて、いつでも再開できて、何度実行しても同じ結果になる ―― この性質が、エージェント運用のあらゆる柔軟性の土台となるのです。
もちろんLLM自体の非決定性(同じプロンプトに異なるレスポンス)は回避できませんが、不確実性に対処する原則は「不確実な要素を局所化して制限すること、そして評価すること」です。LLMの非決定性をLLM外に染み出す設計は避けるべきです。
AIエージェントは「賢いコンポーネント」ではなく「長時間・非決定的・リソース消費パターンが従来と異なるサブシステム」として扱うことが重要です。この視点に切り替えるだけで、見過ごされていたリソース問題のかなりの部分は、設計段階で予見できるようになるでしょう。
LLMのコストはダッシュボードで見えます。ダッシュボードに映らない場所で静かに膨らんでいるリソースにも目を向けることが大切なのです。
最後に
こうしたエージェント開発の課題に対処するため、AIエージェントを組み込むときに見過ごされるリソースの問題を判定するClaude code skillを開発しました。
試しに使ってみていただけると幸いです。