弱教師あり学習は何を見ているのか?
機械学習で分類モデルを学習する際、通常であれば正しくラベリングされたデータを入力としますが、弱教師あり学習では誤ったラベルから学習します。
たとえば「飛行機」、「腕時計」、「ヒョウ」を分類するモデルを学習するとき、すべての「飛行機」画像に「腕時計」、「ヒョウ」のいずれかのラベルがついている(=誤ってラベリングされている)とします。
この場合、「腕時計」画像、「ヒョウ」画像の特徴を持たない画像を「飛行機」画像と学習します。この学習を実装するには損失関数を工夫します。具体的には、学習で誤りラベルを推論すると損失が大きくなるように損失関数を設定します。通常であれば(正しいラベルがついている場合は)、ラベリングされたクラスを推論すれば損失関数が小さくなりますが、弱教師あり学習ではその逆の処理を行います。
詳細は以下論文で論じられているので説明は省きますが、ざっくりイメージとしては入力データは「ラベリングされたものではないもの」と学習している、と考えれば良いと思います。
Learning from Complementary Labels
参考に、誤りラベルによる分類モデルの学習が可能であることは、以下で検証しました。
https://qiita.com/cvusk/items/66252eb48e89435824f5
さて、「飛行機」画像を「腕時計」、「ヒョウ」でないものと学習するとき、分類モデル自体は「飛行機」のどういう特徴を抽出して「飛行機」と分類しているのでしょうか?
正しいラベルからの学習であれば、他のクラスにない「飛行機」の形態に反応して「飛行機」と分類するでしょう。
しかし「腕時計」、「ヒョウ」ではないものとして「飛行機」を学習した場合、分類モデルは「飛行機」っぽさを学習しているのか、それとも『「腕時計」、「ヒョウ」』でないっぽさを学習しているのか。
今回は弱教師あり学習で「飛行機」、「腕時計」、「ヒョウ」の分類モデルを学習し、そのモデルが何を見ているのか、可視化してみようと思います。
データ
Caltech101の一部の画像を用います。
具体的にはCaltech101のうち、「飛行機」、「腕時計」、「ヒョウ」の画像を利用します。
これらのクラスを選んだ理由は、いずれも200枚以上と、学習するのに充分な画像数があると判断したからです。
Caltech101は101クラスの画像を提供していますが、ほとんどのクラスは100枚以下で学習するのに心許ないと思い、画像数の多い「飛行機」、「腕時計」、「ヒョウ」を選びました。



なお、「飛行機」の画像は800枚以上ありますが、「腕時計」「ヒョウ」(いずれも200枚程度)とバランスをとるため、「飛行機」画像の中から200枚ずつをランダムに選出しています。
やること
- データを用意する
- 正しいラベルで分類モデルを学習する(このモデルを「正しい分類モデル」と呼ぶ)
- 誤りラベルを設定し、弱教師あり学習で学習する(このモデルを「誤り分類モデル」と呼ぶ)
- Grad-Camで正しい分類モデルと誤り分類モデルを可視化する
コード全文
検証環境
- Google Colaboratory(GPU利用)
- Python3.6
- Tensorflow
- Keras
- OpenCV
データを用意する
データはCaltech101でダウンロード可能です。
画像自体は.tgzで固められています。解凍すると、画像ファイル.jpgがラベル名のディレクトリに整理して格納されています。
画像数は以下です。
| | 腕時計 | ヒョウ | 飛行機 | 合計 |
|:--:|:--:|:--:|:--:|:--:|:--:|
| 画像数 | 239 | 200 | 200 | 639 |
前述のとおり飛行機はもともと800枚以上用意されていますが、今回はそのなかからランダムに200枚を抽出して利用しています。
画像サイズはまちまちなのですが、以下の分類モデルにXceptionを使うので、画像はすべて同一サイズ(2992993(RGB))に変換しておきます。
上記のデータを学習データ80%、テストデータ20%に分割して使用します。
正しいラベルで分類モデルを学習する
分類モデルはXceptionで学習します。
import keras
from keras.utils import np_utils
from keras.models import Model
from keras import layers
from keras.layers import Dense
from keras.layers import Input
from keras.layers import BatchNormalization
from keras.layers import Activation
from keras.layers import Conv2D
from keras.layers import SeparableConv2D
from keras.layers import MaxPooling2D
from keras.layers import GlobalAveragePooling2D
from keras.layers import GlobalMaxPooling2D
from keras.callbacks import EarlyStopping
from keras.callbacks import ModelCheckpoint
from keras import backend as K
from keras.preprocessing.image import ImageDataGenerator
from keras import metrics
# the shape of image is (299,299,3) array
input_shape = (299,299,3)
# defining Xception
def Xception(input_shape=(299,299,3), classes=4):
img_input = Input(shape=input_shape)
x = Conv2D(32, (3, 3), strides=(2, 2), use_bias=False, name='block1_conv1')(img_input)
x = BatchNormalization(name='block1_conv1_bn')(x)
x = Activation('relu', name='block1_conv1_act')(x)
x = Conv2D(64, (3, 3), use_bias=False, name='block1_conv2')(x)
x = BatchNormalization(name='block1_conv2_bn')(x)
x = Activation('relu', name='block1_conv2_act')(x)
residual = Conv2D(128, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(128, (3, 3), padding='same', use_bias=False, name='block2_sepconv1')(x)
x = BatchNormalization(name='block2_sepconv1_bn')(x)
x = Activation('relu', name='block2_sepconv2_act')(x)
x = SeparableConv2D(128, (3, 3), padding='same', use_bias=False, name='block2_sepconv2')(x)
x = BatchNormalization(name='block2_sepconv2_bn')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same', name='block2_pool')(x)
x = layers.add([x, residual])
residual = Conv2D(256, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = Activation('relu', name='block3_sepconv1_act')(x)
x = SeparableConv2D(256, (3, 3), padding='same', use_bias=False, name='block3_sepconv1')(x)
x = BatchNormalization(name='block3_sepconv1_bn')(x)
x = Activation('relu', name='block3_sepconv2_act')(x)
x = SeparableConv2D(256, (3, 3), padding='same', use_bias=False, name='block3_sepconv2')(x)
x = BatchNormalization(name='block3_sepconv2_bn')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same', name='block3_pool')(x)
x = layers.add([x, residual])
residual = Conv2D(728, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = Activation('relu', name='block4_sepconv1_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name='block4_sepconv1')(x)
x = BatchNormalization(name='block4_sepconv1_bn')(x)
x = Activation('relu', name='block4_sepconv2_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name='block4_sepconv2')(x)
x = BatchNormalization(name='block4_sepconv2_bn')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same', name='block4_pool')(x)
x = layers.add([x, residual])
for i in range(8):
residual = x
prefix = 'block' + str(i + 5)
x = Activation('relu', name=prefix + '_sepconv1_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name=prefix + '_sepconv1')(x)
x = BatchNormalization(name=prefix + '_sepconv1_bn')(x)
x = Activation('relu', name=prefix + '_sepconv2_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name=prefix + '_sepconv2')(x)
x = BatchNormalization(name=prefix + '_sepconv2_bn')(x)
x = Activation('relu', name=prefix + '_sepconv3_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name=prefix + '_sepconv3')(x)
x = BatchNormalization(name=prefix + '_sepconv3_bn')(x)
x = layers.add([x, residual])
residual = Conv2D(1024, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = Activation('relu', name='block13_sepconv1_act')(x)
x = SeparableConv2D(728, (3, 3), padding='same', use_bias=False, name='block13_sepconv1')(x)
x = BatchNormalization(name='block13_sepconv1_bn')(x)
x = Activation('relu', name='block13_sepconv2_act')(x)
x = SeparableConv2D(1024, (3, 3), padding='same', use_bias=False, name='block13_sepconv2')(x)
x = BatchNormalization(name='block13_sepconv2_bn')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same', name='block13_pool')(x)
x = layers.add([x, residual])
x = SeparableConv2D(1536, (3, 3), padding='same', use_bias=False, name='block14_sepconv1')(x)
x = BatchNormalization(name='block14_sepconv1_bn')(x)
x = Activation('relu', name='block14_sepconv1_act')(x)
x = SeparableConv2D(2048, (3, 3), padding='same', use_bias=False, name='block14_sepconv2')(x)
x = BatchNormalization(name='block14_sepconv2_bn')(x)
x = Activation('relu', name='block14_sepconv2_act')(x)
x = GlobalAveragePooling2D()(x)
x = Dense(classes, activation='softmax', name='predictions')(x)
model = Model(img_input, x, name='xception')
return model
# model trained with regular labels
model = Xception()
# define optimization, using ADAM with learning rate of 0.00001 with decay and amsgrad
opt = keras.optimizers.adam(lr=0.00001, decay=1e-6, amsgrad=True)
model.compile(loss="categorical_crossentropy",
optimizer=opt,
metrics=['accuracy'])
# early stopping
es_cb = EarlyStopping(monitor='val_loss', patience=3, verbose=1, mode='auto')
# data augmentation
datagen = ImageDataGenerator(
rotation_range=90,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
vertical_flip=True
)
datagen.fit(x_train)
# train model
batch_size = 16
epochs = 1000
model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=x_train.shape[0] // batch_size,
validation_data=(x_test, y_test),
epochs=epochs,
verbose=1,
shuffle=True,
callbacks=[es_cb])
KerasであればImagenetで学習したXceptionモデルから転移学習することも可能なのですが、今回は0から学習します。理由としては、弱教師あり学習を誤りラベルのみで学習するためです。正しいラベルのほうも弱教師あり学習に条件を合わせるため、転移学習はしません。
正しい分類モデルの学習結果は以下になります。
- テストデータの正解率:93.75%
誤りラベルを設定し、弱教師あり学習で学習する
弱教師あり学習ではXceptionモデル自体は正しい分類モデルと同じですが、誤りラベルと損失関数を設定する必要があります。
誤りラベルには、「飛行機」は「ヒョウ」、「腕時計」のいずれかをランダムに設定します。
「ヒョウ」、「腕時計」についても同様に誤りラベルを付けます。
# generate complementary labels for training targets
# if the right label if 0, then the complementary label is either 1 or 2.
y_ctrain = np.zeros((len(y_train),1))
for i,v in enumerate(y_train):
if v == 0:
y_ctrain[i] = np.random.choice([1,2],1)
elif v == 1:
y_ctrain[i] = np.random.choice([0,2],1)
elif v == 2:
y_ctrain[i] = np.random.choice([0,1],1)
損失関数は誤りラベルに分類すると損失が大きくなるようにします。
また、目安程度に擬似的なAccuracyの関数も用意します(正しいラベルを使わないので、正しい正解率は計算できませんが)。
# defining sigmoid loss for complementary label training
def sigmoid_loss (target, output):
return 1 / (1 + math.e ** K.categorical_crossentropy(target, output))
# defining pseudo accuracy for complementary label training
# this does not calculate right accuracy rate
def caccuracy (target, output):
return 1 - metrics.categorical_accuracy(target, output)
この状態で弱教師あり学習を実施します。
# a model for complementary label
cmodel = Xception()
# define optimization, using ADAM with learning rate of 0.00001 with decay and amsgrad
opt = keras.optimizers.adam(lr=0.00001, decay=1e-6, amsgrad=True)
cmodel.compile(loss=sigmoid_loss,
optimizer=opt,
metrics=[caccuracy])
# data augmentation
datagen = ImageDataGenerator(
rotation_range=90,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
vertical_flip=True
)
datagen.fit(x_train)
# train model
batch_size = 16
epochs = 1000
cmodel.fit_generator(datagen.flow(x_train, y_ctrain, batch_size=batch_size),
steps_per_epoch=x_train.shape[0] // batch_size,
validation_data=(x_test, y_ctest),
epochs=epochs,
verbose=1,
shuffle=True,
callbacks=[es_cb])
# calculating the right accuracy, compared to the right labels
cpred = cmodel.predict(x_test)
score = 0
for i in range(len(y_test)):
if np.argmax(y_test[i]) == np.argmax(cpred[i]):
score += 1
print(score / len(y_test))
誤り分類モデルの学習結果(正しいラベルに対する正解率)は以下になります。
- テストデータの正解率:91.41%
Grad-Camで正しい分類モデルと誤り分類モデルを可視化する
正しい分類モデル(model)と誤り分類モデル(cmodel)ができあがったので、これらのモデルが入力画像のどういう特徴に反応しているか、Grad-Camで可視化します。
Grad-Camの詳細な理論は以下論文を参照すれば良いと思います。
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
日本語の説明は、以下ブログがとてもわかりやすい説明をしてくれています。ありがたやありがたや。
深層学習は画像のどこを見ている!? CNNで「お好み焼き」と「ピザ」の違いを検証
簡単に説明すると、Grad-Camでは入力画像をニューラルネットワークに通し、途中レイヤーで画像のどの部位に反応しているのかをヒートマップで可視化することができます。
畳み込みニューラルネットワークでは画像にフィルターをかけることで重要な部位の特徴を抽出します。Grad-Camでは画像の中のどの部位に反応しているのか(特徴抽出しているのか)を可視化します。

全体像は以下のような構造になります。
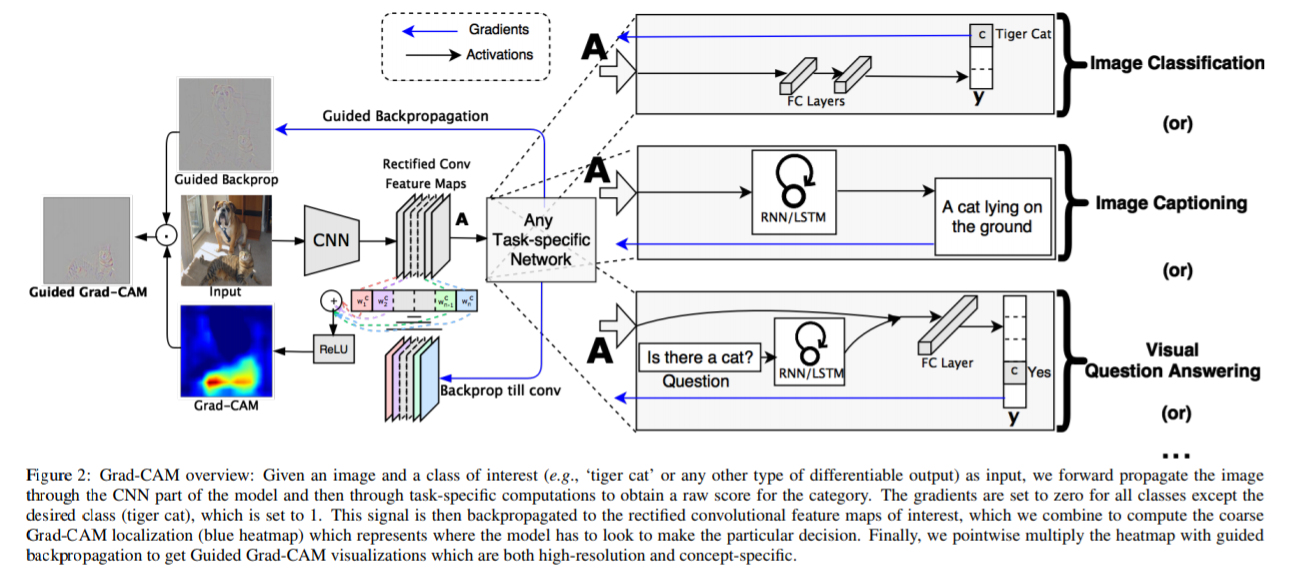
論文オリジナルのコードは以下で公開されており、LuaとTorchで実装されています。
grad-cam
Kerasで作ったモデルをGrad-Camにかけるコードは以下です。
import cv2
# convert image file to numpy array
def convert_img_to_np(img, size=(299,299)):
img = Image.open(img)
if img.mode != "RGB":
img = img.convert("RGB")
np_img = np.asarray(img)
return transform.resize(np_img, size)
# convert numpy array to image
def convert_np_to_img(np_img):
np_img *= 255
return Image.fromarray(np.uint8(np_img))
# standardize pixels
def preprocess_img(np_img):
np_img = np.expand_dims(np_img, axis=0)
np_img = np_img.astype('float32')
return np_img / 255.0
# get model output for image
def get_model_output(model, np_img):
label = np.argmax(model.predict(np_img)[0])
print("label:\t{0}".format(label))
return model.output[:, label]
# get conv function
def get_grad_func(model, layer, model_output):
conv_output = model.get_layer(layer).output
grads = K.gradients(model_output, conv_output)[0]
return K.function([model.input], [conv_output, grads])
# get output from the function
def get_grads_val(gradient_function, np_img):
output, grads_val = gradient_function([np_img])
return output[0], grads_val[0]
# get grad cam
def get_grad_cam(output, grads_val, np_img, size=(299,299)):
weights = np.mean(grads_val, axis=(0, 1))
cam = np.dot(output, weights)
cam = cv2.resize(cam, size, cv2.INTER_LINEAR)
cam = np.maximum(cam, 0)
cam = cam / cam.max()
gradcam = cv2.applyColorMap(np.uint8(255 * cam), cv2.COLORMAP_JET)
gradcam = cv2.cvtColor(gradcam, cv2.COLOR_BGR2RGB)
return (np.float32(gradcam) + np_img / 2)
# grad cam
def grad_cam(model, img, layer):
np_img = convert_img_to_np(img)
prep_np_img = preprocess_img(np_img)
model_output = get_model_output(model, prep_np_img)
gradient_function = get_grad_func(model, layer, model_output)
output, grads_val = get_grads_val(gradient_function, prep_np_img)
gradcam = get_grad_cam(output, grads_val, np_img)
return gradcam
実装は以下を参考にさせていただきました。
ありがとうございます。
keras-gradcam
kerasでGrad-CAM 自分で作ったモデルで
いろいろやっていますが、指定したレイヤーの出力を平均して入力画像に半透明なフィルターとして被せています。
強く反応している箇所は赤、中くらいは緑、弱く反応している箇所は青になります。
出力画像は以下で可視化します。
def show_img(img):
plt.imshow(img)
plt.show()
# show grad cam image
def show_gradcam(model, img, layer):
gcam = grad_cam(model, img, layer)
show_img(convert_np_to_img(gcam))
# show original and grad cam image
def show_img_and_gradcam(model, img, layer):
show_img(convert_img_to_np(img))
show_gradcam(model, img, layer)
# WATCH in shallow layer
for j in range(5):
img = caltech_dict[0][1][j]
print(img)
print("ORIGINAL")
show_img(convert_img_to_np(img))
print("GRAD CAM REGULAR MODEL")
show_gradcam(model, img, "add_1")
print("GRAD CAM COMPLEMENTARY MODEL")
show_gradcam(cmodel, img, "add_13")
# WATCH in middle layer
for j in range(5):
img = caltech_dict[0][1][j]
print(img)
print("ORIGINAL")
show_img(convert_img_to_np(img))
print("GRAD CAM REGULAR MODEL")
show_gradcam(model, img, "add_8")
print("GRAD CAM COMPLEMENTARY MODEL")
show_gradcam(cmodel, img, "add_20")
# WATCH in deep layer
for j in range(5):
img = caltech_dict[0][1][j]
print(img)
print("ORIGINAL")
show_img(convert_img_to_np(img))
print("GRAD CAM REGULAR MODEL")
show_gradcam(model, img, "block14_sepconv2_act")
print("GRAD CAM COMPLEMENTARY MODEL")
show_gradcam(cmodel, img, "block14_sepconv2_act")
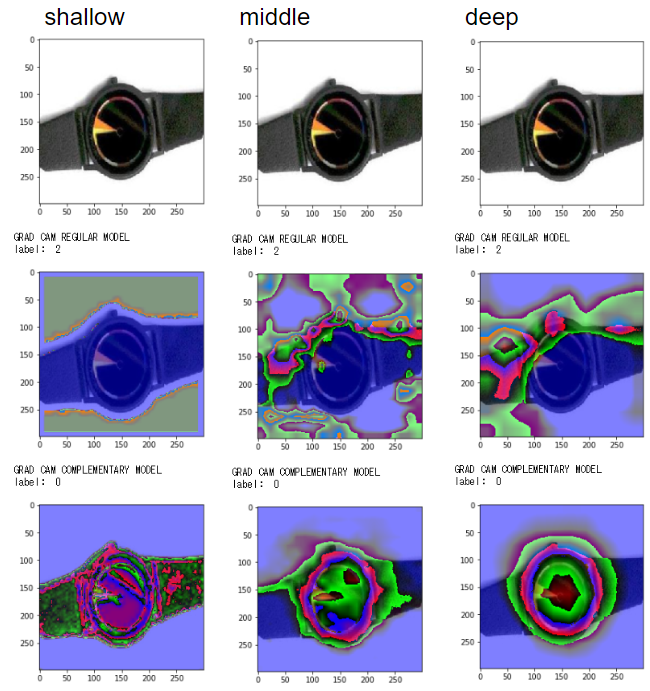
以下に各クラス画像の元画像、正しい分類モデルによるGrad-Cam、誤り分類モデルによるGrad-Camを提示します。
それぞれについて、浅いレイヤー、中位のレイヤー、GlovalAveragePooling直前の深いレイヤーでのGrad-Camを出力しています。
(浅いレイヤーのGrad-Camはなんかオーラをまとっているみたいに見えますね・・・)
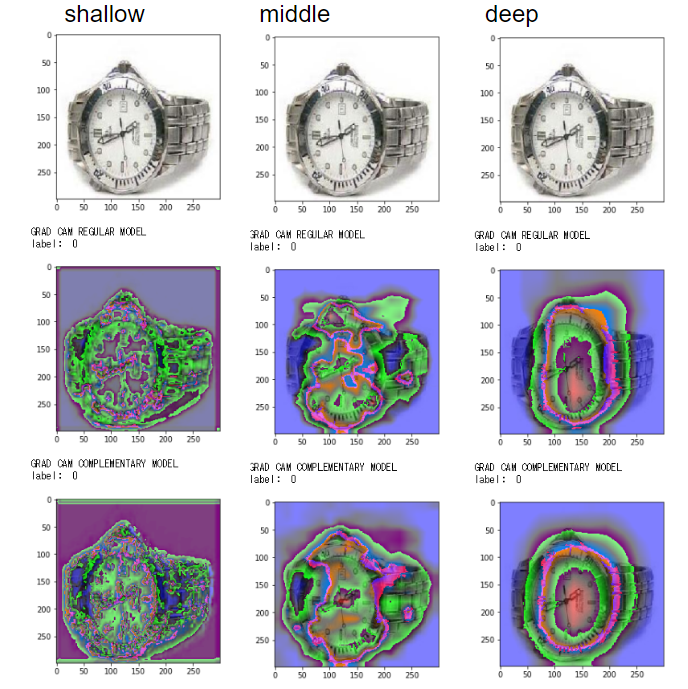
腕時計
深いレイヤーで丸いフォルムに反応
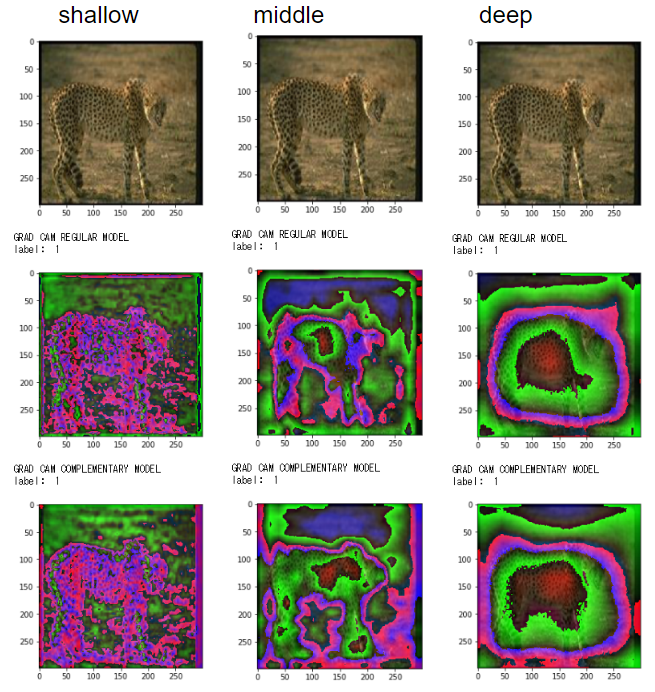
ヒョウ
深いレイヤーで身体の形とお腹あたりに反応
飛行機
深いレイヤーで翼の形と周囲の空に反応
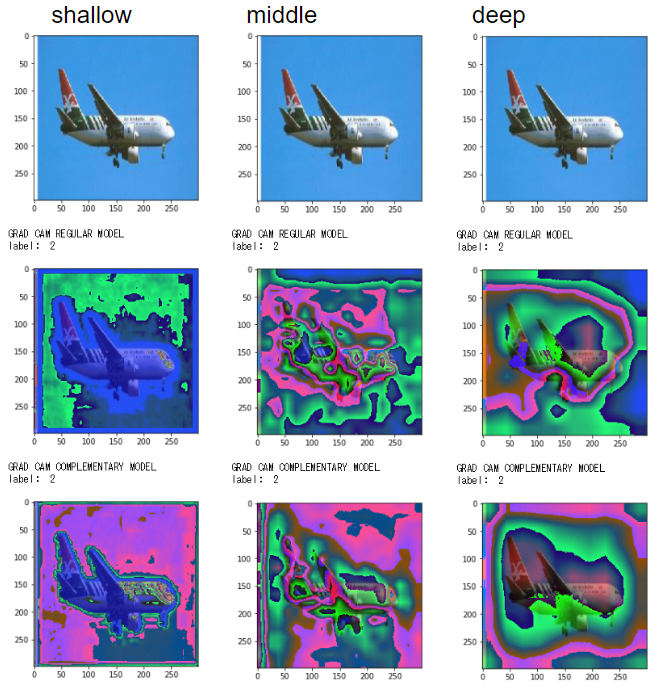
画像によって多少の差異はありますが、深いレイヤーでは正しい分類モデルによるGrad-Camと誤り分類モデルによるGrad-Camの反応している箇所(緑や赤の部位)に大きな違いがないことがわかります。
ただし、浅いレイヤー、中くらいのレイヤーでは正しい分類モデルと誤り分類モデルで違った反応をしていることが見て取れます。
どうやら中間レイヤーの過程は違えど、通常の教師あり学習と弱教師あり学習は、最終的に深いレイヤーで正解画像の特徴を抽出しているようです。
分類が間違っている場合
なお、間違った分類をしている場合は反応の仕方が違ってきます。
以下は腕時計で、誤り分類モデルが間違っているときのGrad-Camです。
正しい分類モデルが腕時計の丸いフォルムに収束していっているの対し、誤り分類モデルはフォルムを捉えきれていないようです。

次に正しい分類モデルが間違っているときです。
同様に、間違っている正しい分類モデルは丸いフォルムに収束していません。
最後に
今回は「飛行機」、「ヒョウ」、「腕時計」という見た目のだいぶ違う3クラスの分類を教師あり学習、弱教師あり学習で可視化しました。
クラス数を増やすと弱教師あり学習の学習が難しくなる(収束しなくなる)ので、今回は3クラスにしましたが、もっとクラス数を増やしたり、似た画像(犬と猫とうさぎか)でのどうなるのか、暇があったらやってみます。
なお、「飛行機」「ヒョウ」「腕時計」に「バイク」を加えた弱教師あり学習も試してみたのですが、正解率が60%程度で微妙でした。
https://github.com/shibuiwilliam/complementary_labels_keras/blob/master/what_complementary_sees_Xception2.ipynb