はじめに
「シェイクスピアに影響を受けた作家を探したい」「ドストエフスキーの作品と関連する文学運動を横断的に検索したい」——こうしたエンティティ間の関係性を活用した検索を実現する場合、一般的に知識グラフ(ナレッジグラフ、KG)を構築します。作家と作品の wrote 関係、作家同士の influencedBy 関係、作品と文学運動の belongsTo 関係など、多様なエンティティの関係をグラフとして表現し、それを辿ることで豊かな検索体験を提供します。
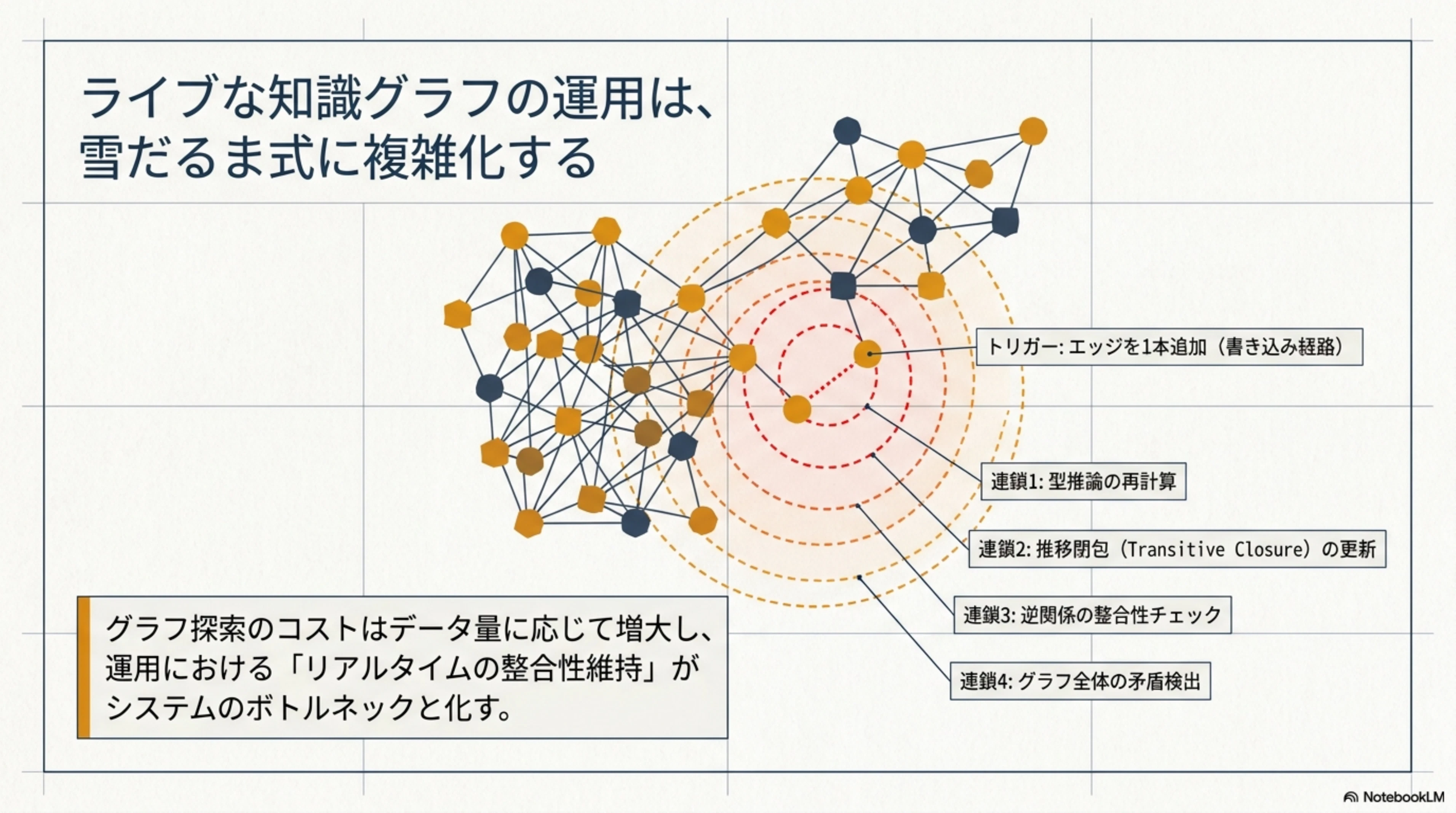
しかし、知識グラフの運用は想像以上に大変です。エッジを1本追加するたびに推移閉包や逆関係の更新が連鎖し、データの整合性を保つための運用コストが雪だるま式に膨らんでいきます。型階層の管理、矛盾検出、グラフ探索のパフォーマンス——これらすべてを「ライブな書き込み経路の中で」同時に維持し続けるのが、知識グラフ運用の本質的な難しさです。
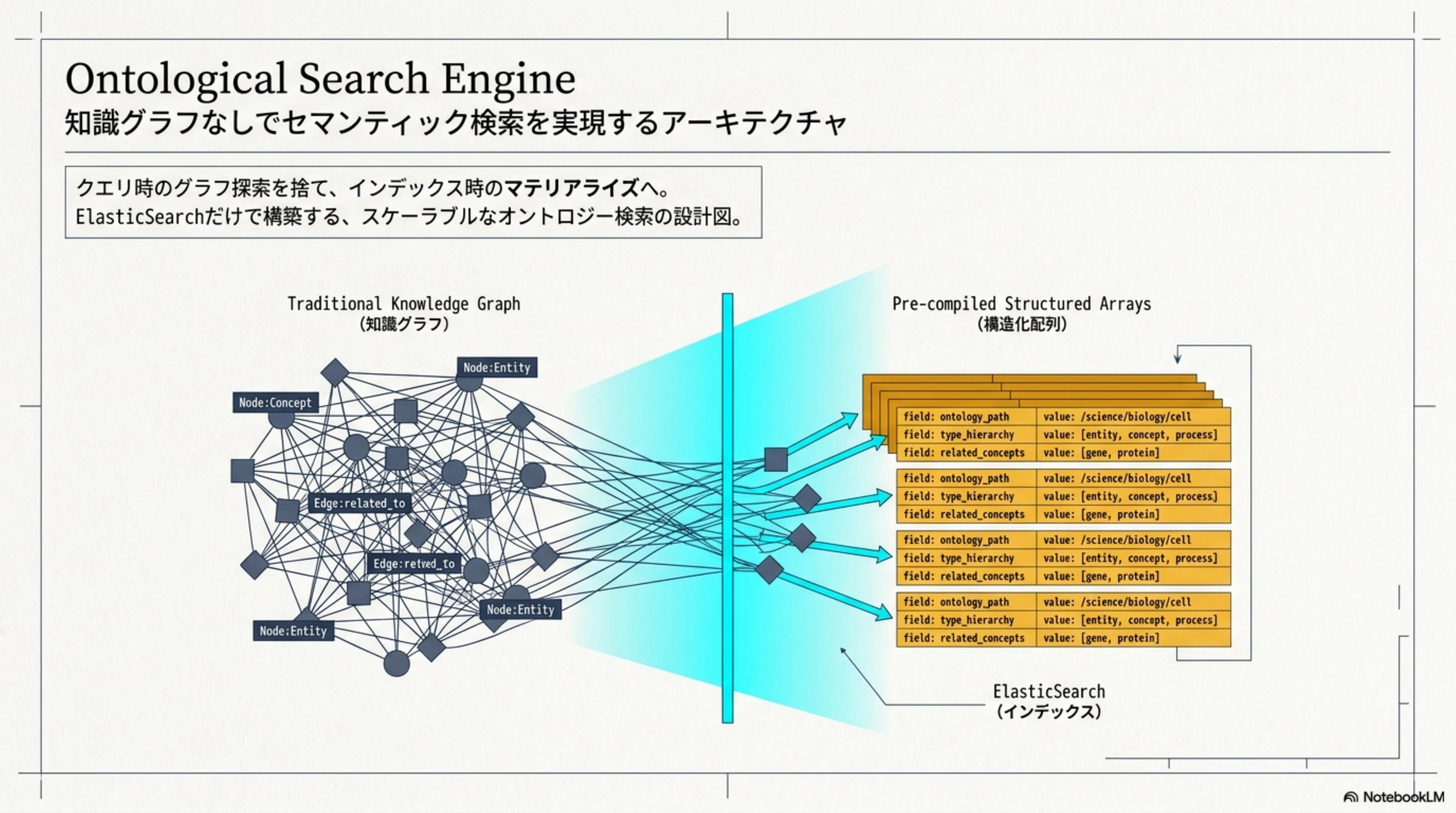
本記事では、 知識グラフを使わずに、検索エンジン(ElasticSearch)だけでオントロジーに基づくセマンティック検索を実現する アプローチを紹介します。このアプローチを実装したサンプルプロジェクト「Ontological Search Engine(OSE)」を通じて、その仕組みと実装の詳細を解説します。
なお、このプロジェクトはあくまで「知識グラフなしでオントロジー検索を実現する方法の一例」を示すものであり、すべてのユースケースに最適なソリューションではありません。特に、任意深さのグラフ探索や複雑な推論が必要なケースでは、専用のグラフデータベースとの併用を検討することをお勧めします。
1. Ontological Search Engine の目的
なぜ知識グラフなしで?
知識グラフは強力なツールですが、構築と運用面が大変です。
- リアルタイムの整合性維持が難しい: エンティティや関係を追加・更新するたびに、型推論・推移閉包・逆関係・矛盾検出が連鎖的に発生します
- スケーラビリティの問題: グラフの探索コストはデータ量に応じて増大し、クエリ時のパフォーマンスが不安定になりがちです
- 運用の複雑さ: 専用のグラフデータベースの運用ノウハウが必要で、チームの学習コストも高くなります
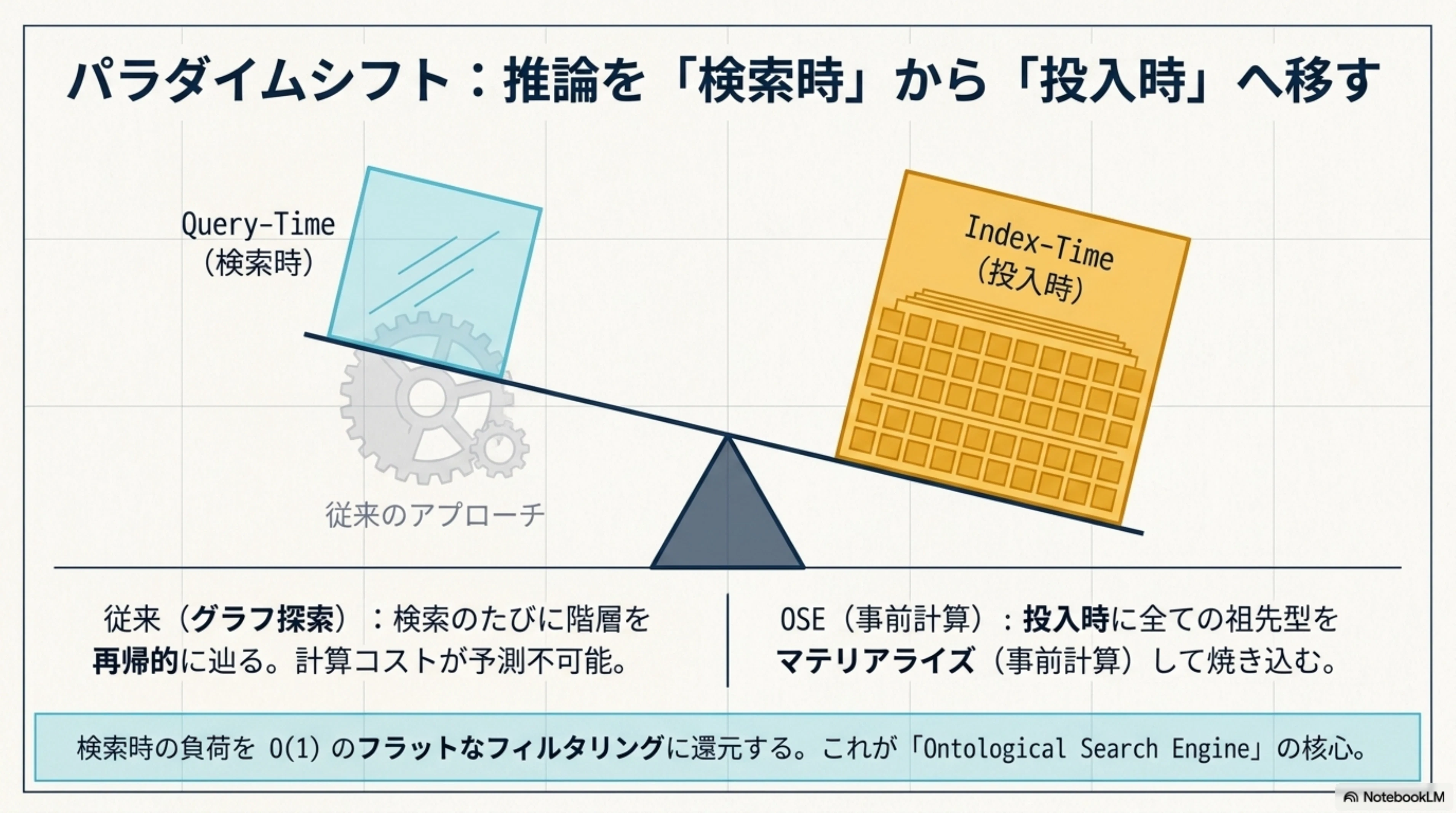
OSE のコアなアイデアは次のひとことに集約されます。
推論を「クエリ時のグラフ探索」から「投入時の事前計算(マテリアライズ)」へ移す。
ケーススタディ:文学作品データベース
具体例で考えてみましょう。世界中の作家・作品・文学運動を管理するデータベースがあるとします。
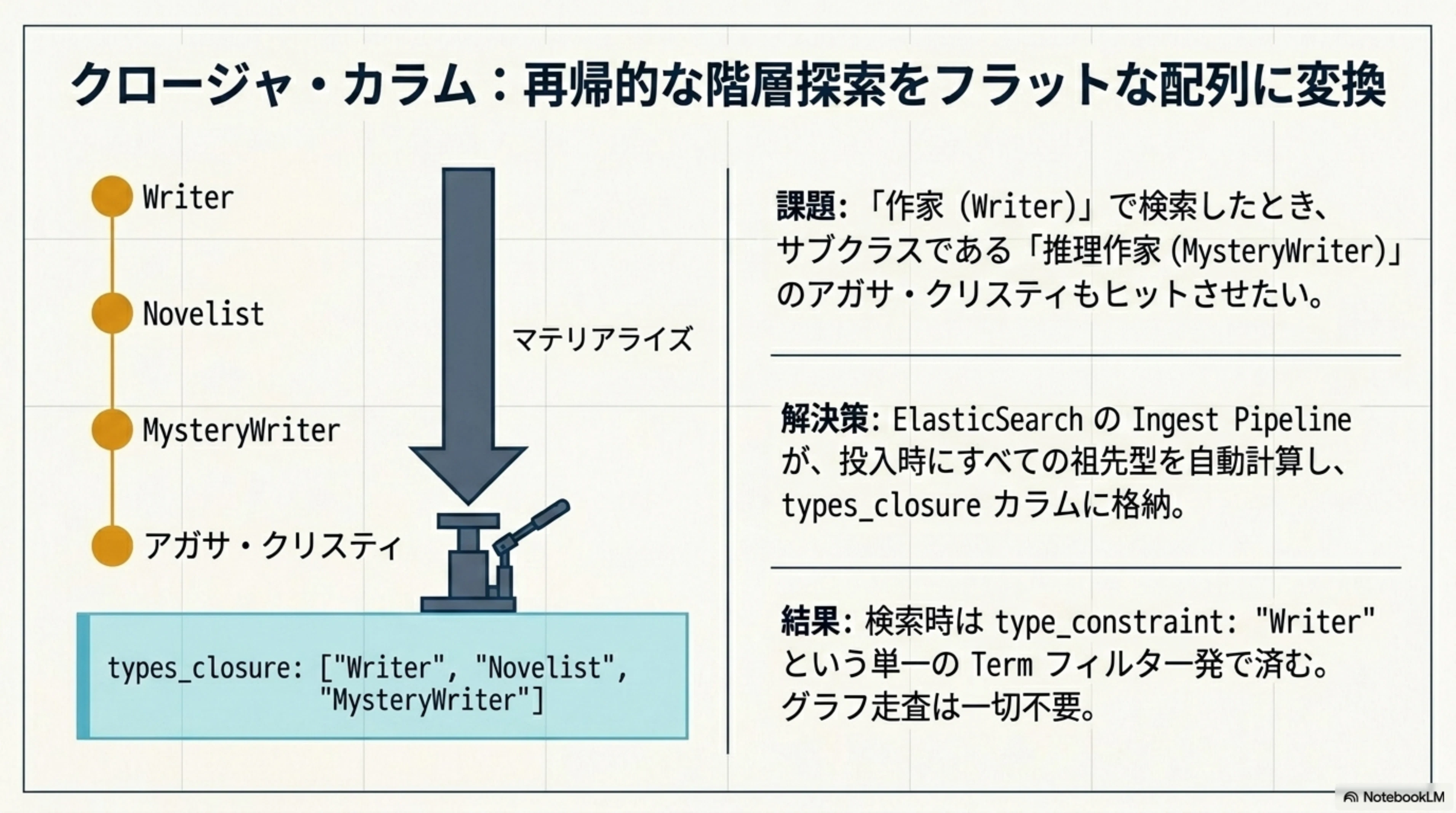
シェイクスピアは「劇作家(Playwright)」として登録されています。ドストエフスキーは「純文学作家(LiteraryNovelist)」、アガサ・クリスティは「推理作家(MysteryWriter)」です。ここで、ユーザーが「作家(Writer)を検索」したとき、これら全員がヒットしてほしいですよね。
知識グラフ的アプローチでは、クエリ時に Writer → Novelist → MysteryWriter という階層を再帰的に辿る必要があります。一方、OSE では 投入時に全ての祖先型を事前計算 しておきます。
シェイクスピアの投入時:
direct_types: ["Playwright"]
↓ ES の ingest pipeline が自動計算
types_closure: ["Playwright", "Writer", "Person", "Thing"]
検索時は、この types_closure フィールドに対して単純な term フィルタをかけるだけです。
{"term": {"types_closure": "Writer"}}
再帰探索なし、グラフ走査なし。O(1) のフラットなフィルタで、型サブサンプション(上位概念での包含検索)が実現できます。
2. 概要
OSE は以下の特徴を持つサンプル実装です。
- ElasticSearch をベースにオントロジー(型階層・プロパティ・公理)を構築
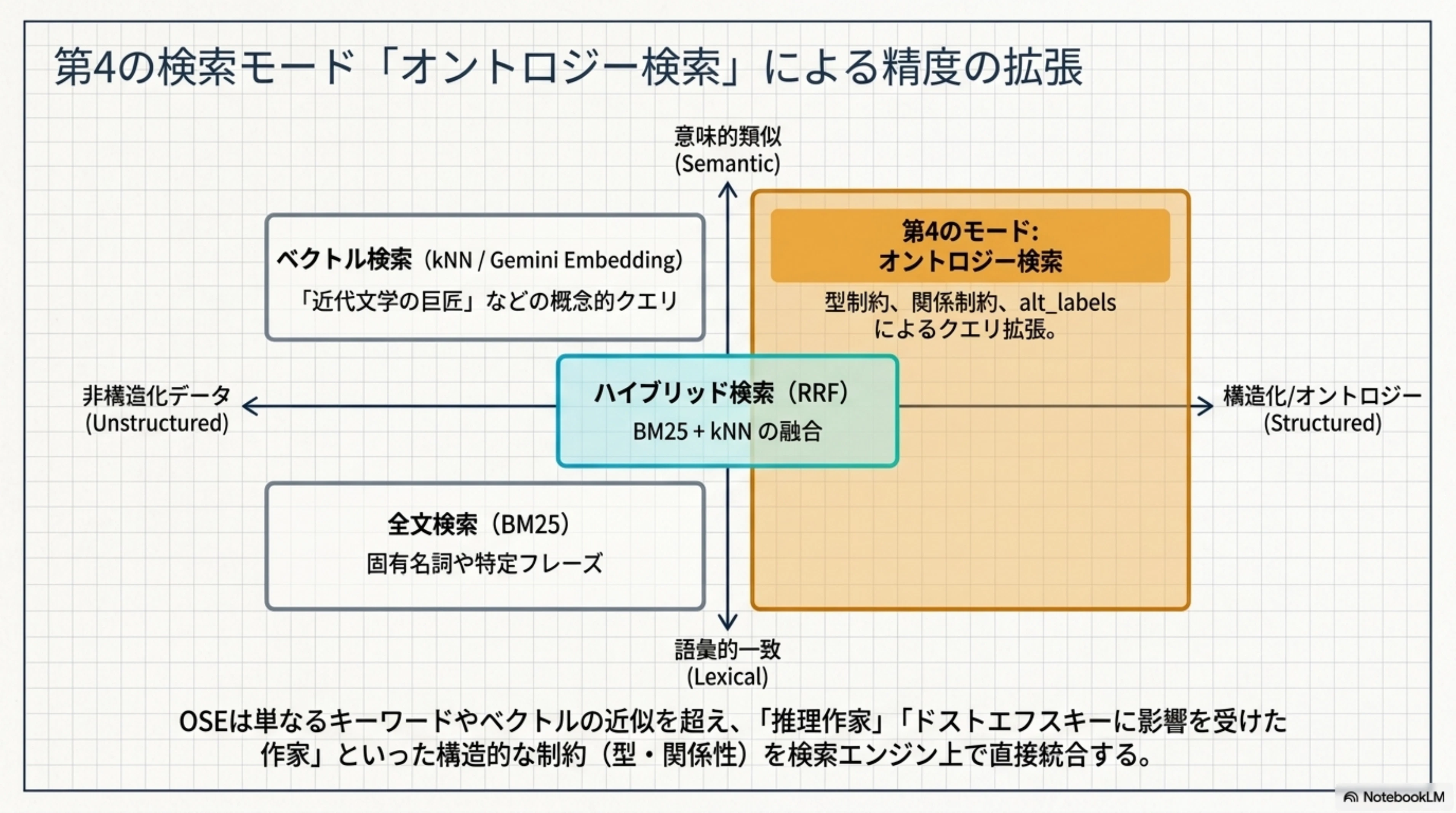
- 全文検索・ベクトル検索・ハイブリッド検索に加えて、「オントロジー検索」を第4の検索モードとして提供
- Docker Compose で完結するローカル検証環境
- Next.js ダッシュボードで視覚的にデータを探索
サンプルデータとして、シェイクスピアからドストエフスキーまで世界中の80名以上の作家、代表作品、文学運動、影響関係を含む5,000件のコーパスを同梱しています。
4つの検索モード
| モード | 仕組み | ユースケース |
|---|---|---|
| 全文検索(BM25) | テキストの語彙的一致 | 固有名詞や特定のフレーズでの検索 |
| ベクトル検索(kNN) | 埋め込みベクトルの意味的類似 | 「近代文学の巨匠」のような概念的クエリ |
| ハイブリッド検索(RRF) | BM25 + kNN の融合 | 語彙と意味の両面で最適なランキング |
| オントロジー検索 | 型制約 + 関係制約 + クエリ拡張 | 「推理作家を検索」「ドストエフスキーに影響を受けた作家」 |
3. アーキテクチャ
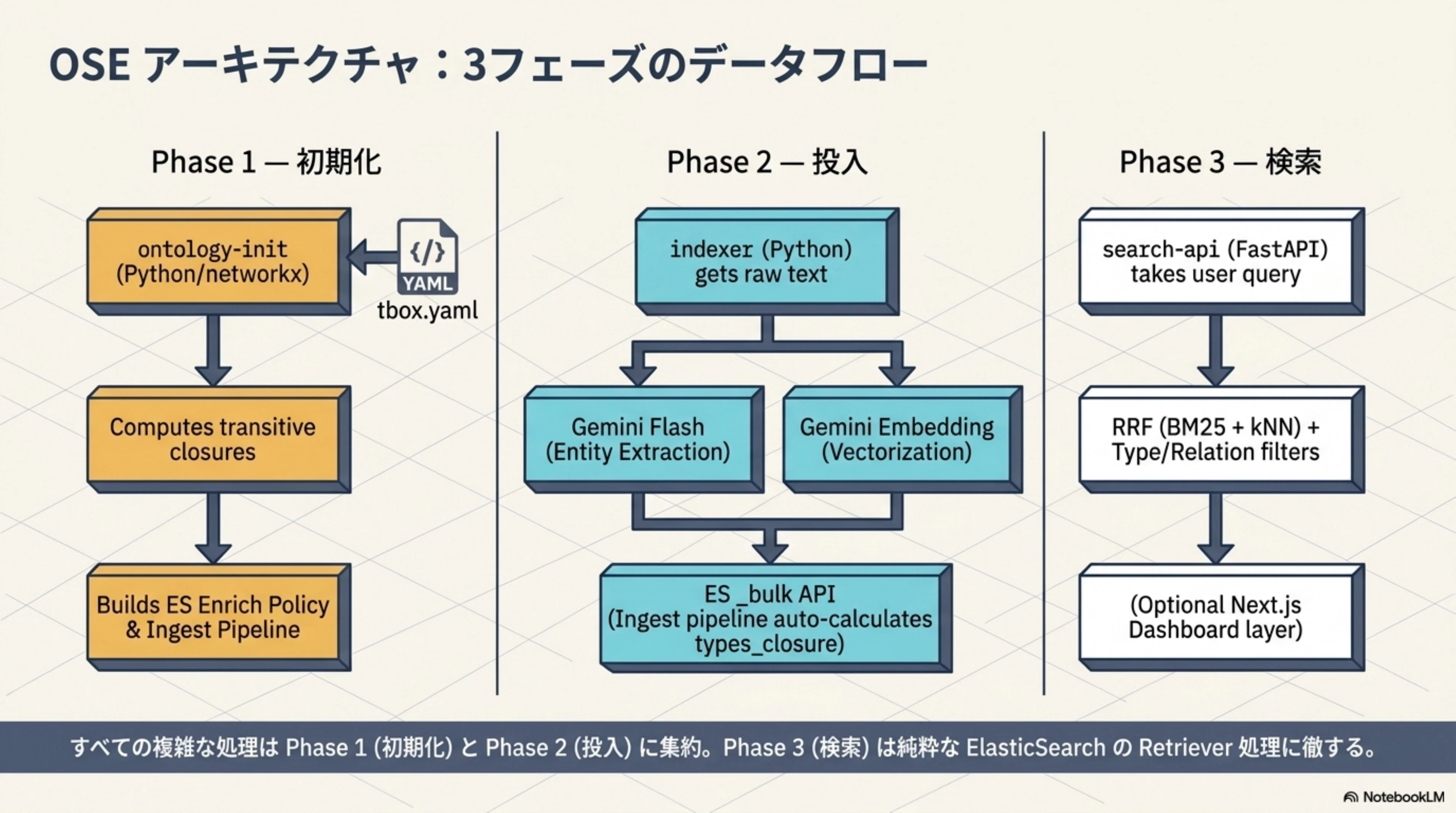
OSE は6つのサービスで構成されています。
┌─────────────┐ ┌──────────────────────────────────────────────┐
│ tbox.yaml │────→│ ontology-init │
│ (型階層定義) │ │ networkx で閉包計算 → ES にインデックス構築 │
└─────────────┘ └──────────────────────┬───────────────────────┘
│
┌─────────────┐ ┌──────────────────────▼───────────────────────┐
│ corpus.jsonl│────→│ indexer │
│ (5,000件) │ │ Gemini Flash で抽出 → Gemini Embedding で │
└─────────────┘ │ ベクトル化 → ES に _bulk 投入 │
│ (投入時に types_closure を自動計算) │
└──────────────────────┬───────────────────────┘
│
┌──────────────────────▼───────────────────────┐
│ search-api (FastAPI :8080) │
│ RRF(BM25 + kNN) + 型/関係フィルタ │
└──────────────────────┬───────────────────────┘
│
┌──────────────────────▼───────────────────────┐
│ dashboard (Next.js :3000) │
│ TBox/ABox 可視化 + 検索プレイグラウンド │
└──────────────────────────────────────────────┘
サービス一覧
| サービス | 役割 | 技術 |
|---|---|---|
| elasticsearch | コアの検索・インデックスエンジン | ElasticSearch 9.x |
| kibana | Dev Tools / 可視化(任意) | Kibana 9.x |
| ontology-init | TBox → 閉包計算 → ES パイプライン構築 | Python + networkx |
| indexer | エンティティ抽出 + 埋め込み + 投入 | Python + Gemini API |
| search-api | オントロジー検索 API | FastAPI |
| dashboard | ダッシュボード UI | Next.js + Tailwind CSS |
3フェーズのデータフロー
Phase 1 — 初期化(ontology-init)
tbox.yaml に定義されたクラス階層から推移閉包を計算し、ES の enrich policy と ingest pipeline を構築します。これは一度だけ実行する初期化処理です。
Phase 2 — 投入(indexer)
生テキストから Gemini Flash でエンティティを構造化抽出し、Gemini Embedding でベクトル化して ES に投入します。投入時に ingest pipeline が direct_types から types_closure を自動計算します。
Phase 3 — 検索(search-api)
ユーザーのクエリを受け取り、Gemini Embedding でクエリベクトルを生成。BM25 + kNN を RRF で融合し、型制約や関係制約のフィルタを適用して検索結果を返します。
4. オントロジーと検索エンジン
TBox と ABox の分離
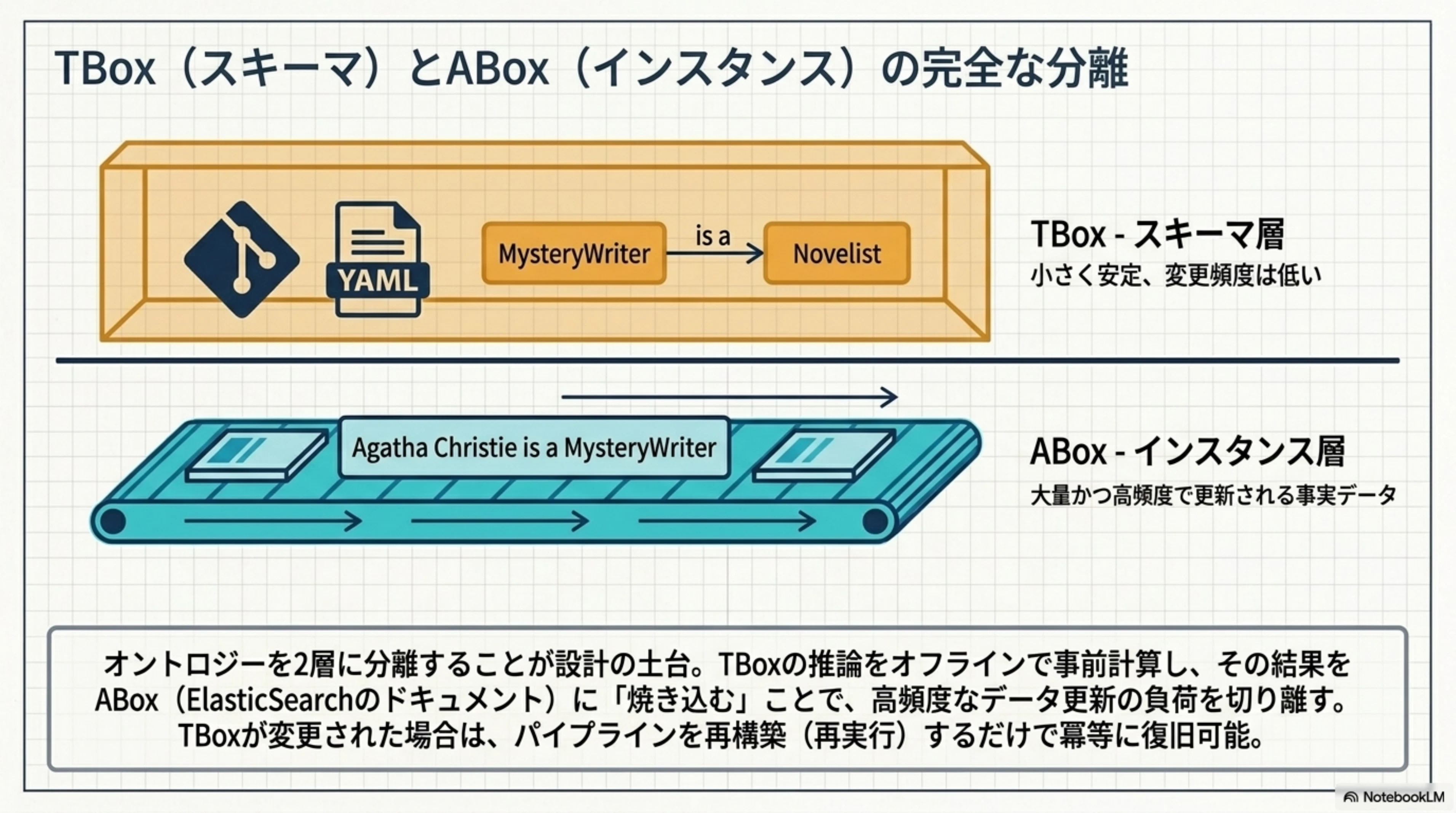
オントロジーを2つの層に分離するのが、設計の土台です。
TBox(スキーマ層) は、クラス階層やプロパティの定義です。「MysteryWriter は Novelist のサブクラスである」「wrote の逆関係は writtenBy である」といった宣言的な知識を保持します。小さく安定しており、変更頻度は低いです。Git で管理し、YAML ファイルとして定義します。
ABox(インスタンス層) は、具体的なエンティティとその属性・関係です。「アガサ・クリスティは MysteryWriter である」「シェイクスピアは Hamlet を wrote した」といった事実を保持します。大量かつ高頻度で更新される可能性があります。
この分離により、TBox の推論をオフラインで事前計算し、結果を ABox に焼き込むことが現実的になります。
クロージャ・カラム ー 最大のレバー
OSE の威力の大半は「クロージャ・カラム」に集約されます。これは、再帰的な型階層の探索を、フラットな term フィルタに変換するための事前計算フィールドです。
# ontology/tbox.yaml の型階層(一部)
Thing:
Person:
Writer:
Novelist:
LiteraryNovelist # ドストエフスキー、トルストイ、ディケンズ...
MysteryWriter # アガサ・クリスティ、コナン・ドイル...
SFWriter # アシモフ、ブラッドベリ...
Poet # ネルーダ、ダンテ、ホイットマン...
Playwright # シェイクスピア、チェーホフ、イプセン...
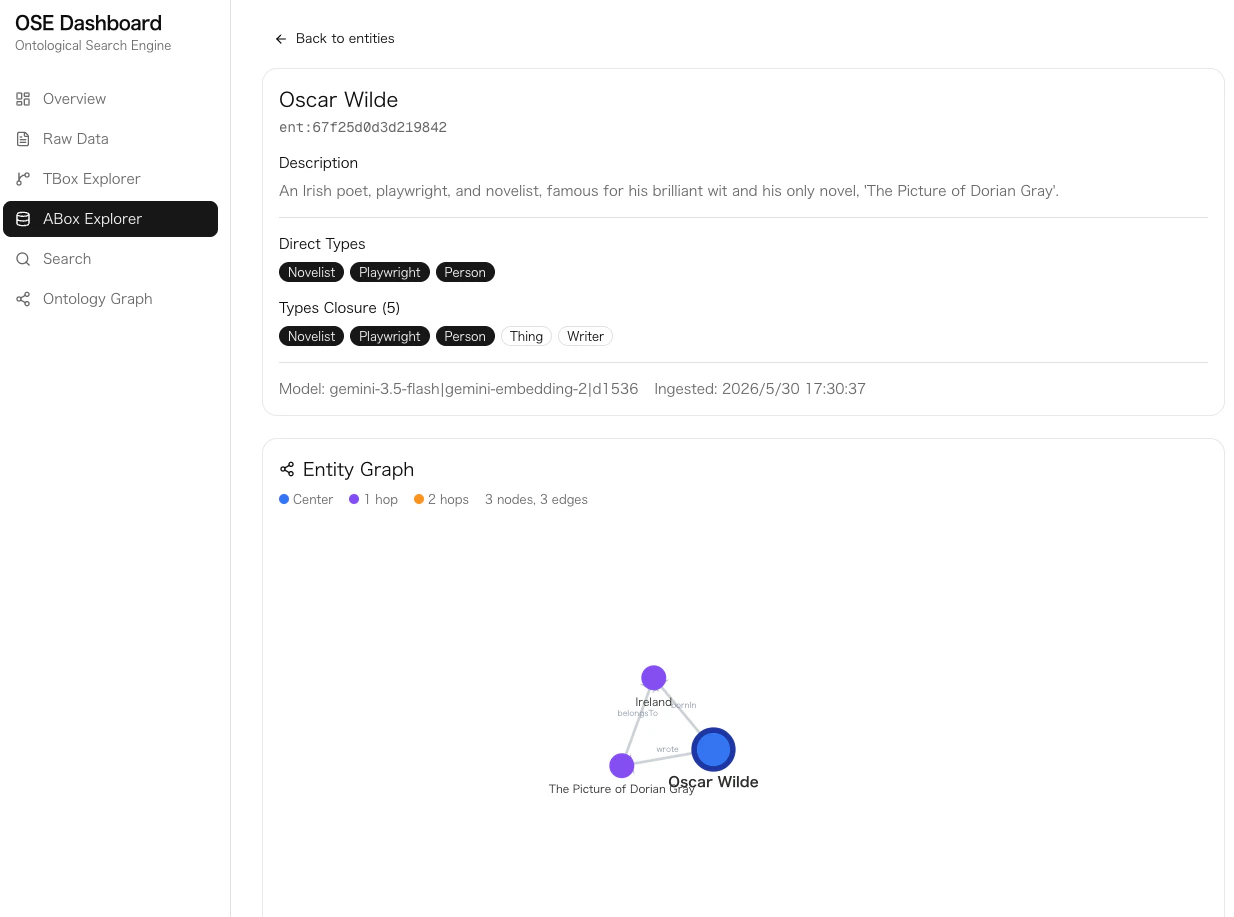
MysteryWriter のインスタンス(アガサ・クリスティ)を投入すると、ES の ingest pipeline が自動的に全祖先型を計算します。
直接の型: ["MysteryWriter"]
閉包後の型: ["MysteryWriter", "Novelist", "Writer", "Person", "Thing"]
これにより、type_constraint: "Writer" で検索すると、MysteryWriter も SFWriter も Poet も——Writer 配下のすべてのサブクラスがフラットなフィルタ一発でヒットします。
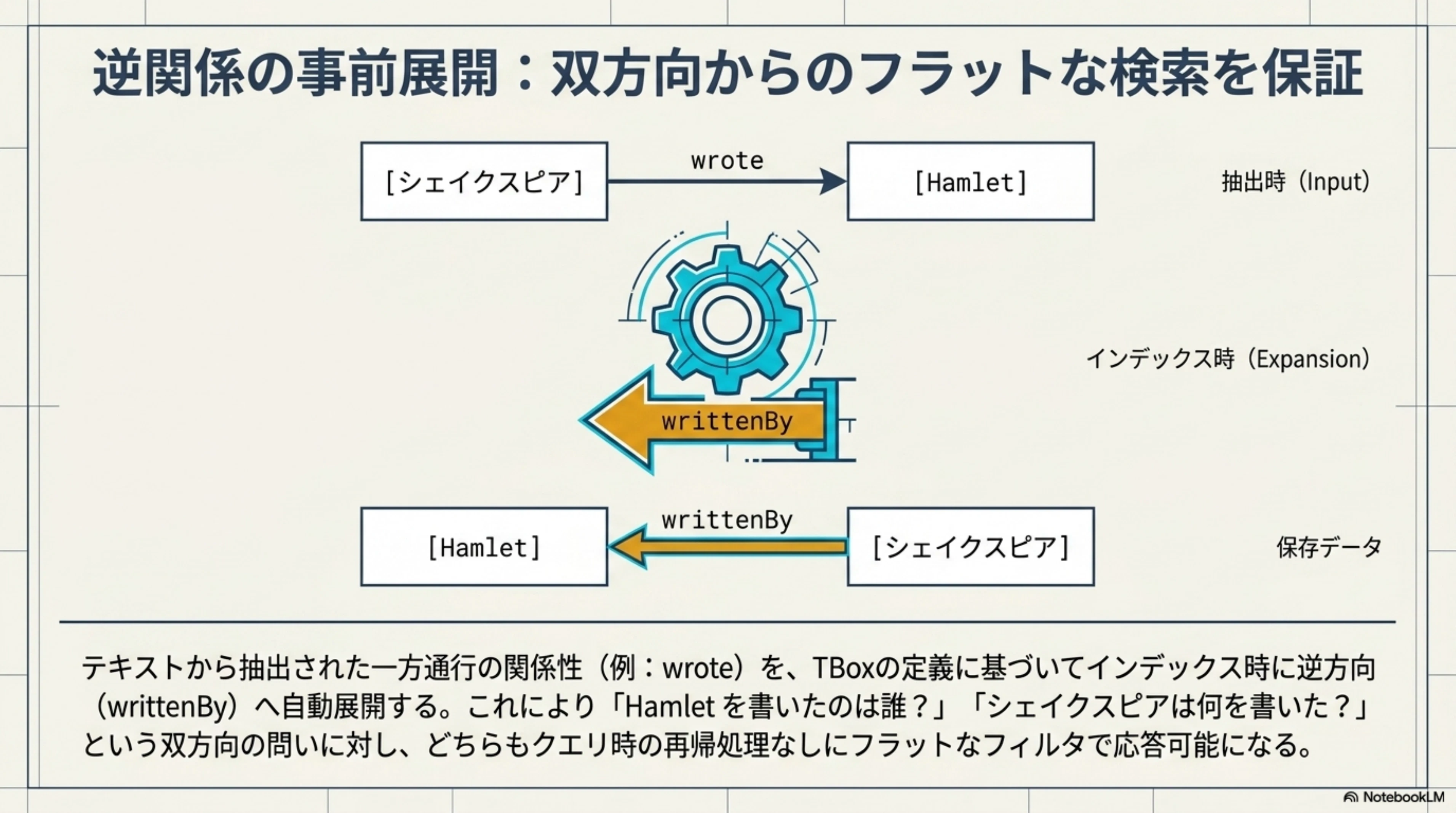
逆関係の事前展開
もう一つの重要な仕組みが、逆関係の事前展開です。
たとえば、シェイクスピアに wrote → Hamlet という関係が抽出された場合、インデックス時に自動的に Hamlet 側に writtenBy → William Shakespeare という逆関係を生成します。
シェイクスピア: wrote → Hamlet (抽出された関係)
Hamlet: writtenBy → シェイクスピア (自動生成された逆関係)
これにより、「Hamlet を書いたのは誰?」という検索も、「シェイクスピアは何を書いた?」という検索も、どちらの方向からでもフラットなフィルタで実現できます。
5. 実装の詳細
5.1 オントロジー定義(tbox.yaml)
オントロジーは YAML ファイルで宣言的に定義します。クラス階層、代替ラベル(表記ゆれの吸収用)、プロパティ(関係の種類と逆関係)を一箇所で管理します。
classes:
Thing:
parent: null
Person:
parent: Thing
Writer:
parent: Person
alt_labels: ["作家", "著者", "文筆家"]
MysteryWriter:
parent: Novelist
alt_labels: ["推理作家", "ミステリー作家"]
properties:
wrote:
parent: relatedTo
inverse: writtenBy
influencedBy:
parent: relatedTo
inverse: influenced
alt_labels は、検索時のクエリ拡張に使われます。たとえば type_constraint: "MysteryWriter" で検索すると、「推理作家」「ミステリー作家」といった表記ゆれも自動的にブーストされます。
5.2 閉包計算(reasoner.py)
ontology-init サービスが起動時に行う処理の流れです。
-
tbox.yamlを読み込み、networkx で有向グラフを構築 - 各クラスの全祖先(
ancestors)と全子孫(descendants)を計算 - ES の
ontology_classes(lookup インデックス)にクラス情報を投入 - ES の
enrich policyを作成・実行(direct_typesからancestorsを引けるようにする) - ES の
ingest pipelineを作成(投入時にtypes_closureを自動計算する Painless スクリプト) -
entitiesインデックスを作成(ベクトル検索用のdense_vectorフィールドを含む)
この一連の処理は冪等(何度実行しても同じ結果)に設計されています。TBox を変更した場合は、ontology-init を再実行してパイプラインを再構築するだけです。
5.3 エンティティ抽出と投入(indexer.py)
インデクサーは以下の4フェーズで動作します。
Phase 1: 並列抽出 — 5,000件のテキストから、Gemini Flash を使ってエンティティ・型・関係を構造化抽出します。ThreadPoolExecutor で並列処理し、結果はファイルキャッシュされるため、2回目以降は API 呼び出しをスキップできます。
Phase 2: エンティティ統合 — 同一エンティティが複数のテキストから抽出されるため、entity_id(ラベルのハッシュ)をキーにして統合します。型は和集合、関係は重複排除した和集合、説明文は最も長いものを採用します。さらに、TBox で定義された逆関係を自動生成します。
統合前: シェイクスピアが71回抽出され、各テキストで異なる関係を持つ
統合後: 1つのシェイクスピアエンティティに16の関係が集約される
(wrote→Hamlet, wrote→Macbeth, bornIn→England, ...)
Phase 3: 並列埋め込み — エンティティの説明文を Gemini Embedding で 1,536 次元のベクトルに変換します。バッチ処理と並列化により効率的に処理します。
Phase 4: 一括投入 — ES の _bulk API で一括投入します。ingest pipeline が types_closure を自動計算するため、direct_types だけ指定すれば OK です。
5.4 検索 API(app.py)
検索 API は、ES の retrievers フレームワークを使って RRF(Reciprocal Rank Fusion)による複合検索を実現します。
# RRF クエリの概要
{
"retriever": {
"rrf": {
"rank_window_size": 100,
"rank_constant": 20,
"retrievers": [
# BM25 リトリーバ: canonical_label, aliases, description で検索
{"standard": {"query": {"bool": {"should": [...], "filter": [...]}}}},
# kNN リトリーバ: 埋め込みベクトルの類似度で検索
{"knn": {"field": "embedding", "query_vector": [...], "k": 50}}
]
}
}
}
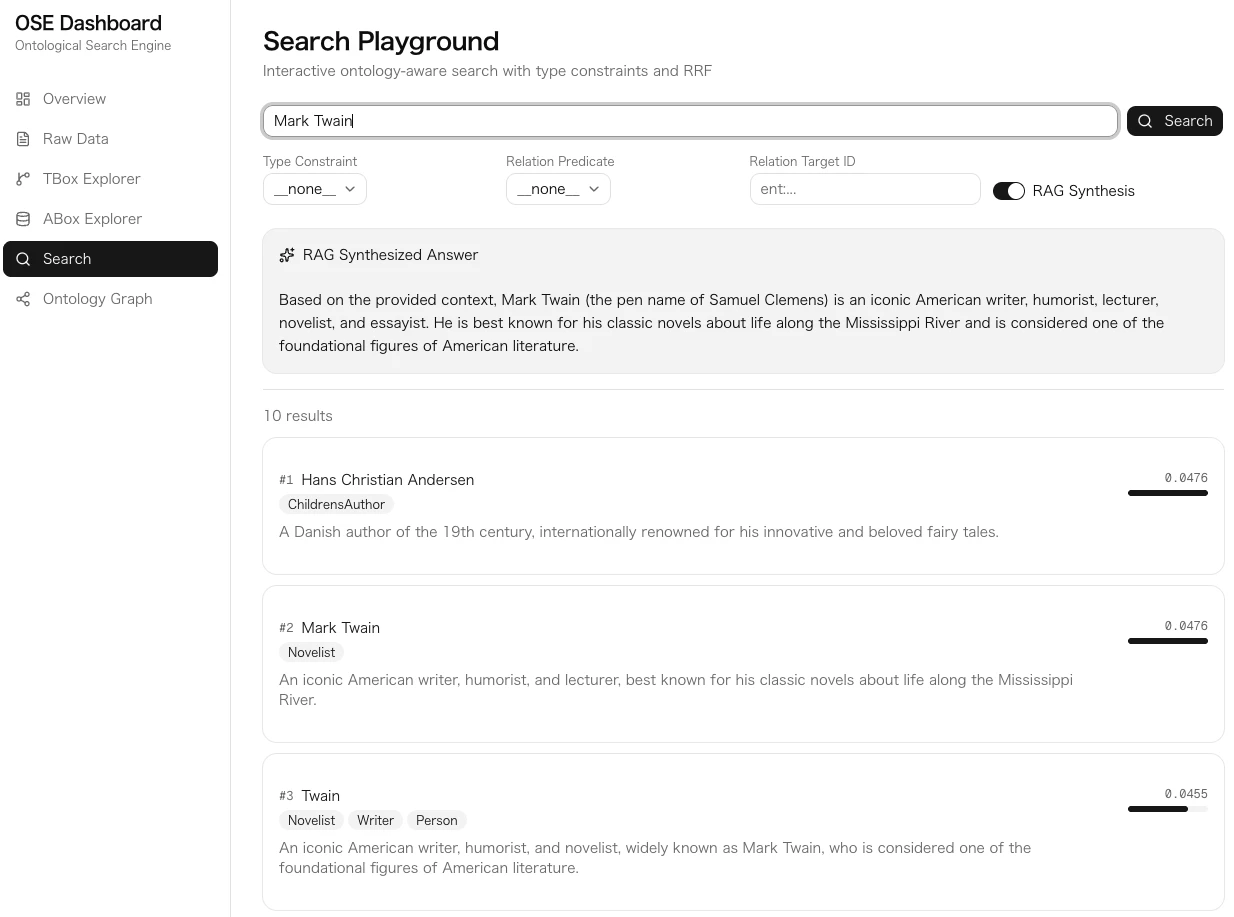
関係述語による検索も柔軟に対応しています。relation_predicate を指定すると、その述語と逆述語の両方で検索します。たとえば wrote を指定すると、wrote を持つエンティティ(作家)と writtenBy を持つエンティティ(作品)の両方がヒットします。
さらに、rag: true を指定すると、検索結果を文脈として Gemini に渡し、自然言語で回答を生成する RAG(Retrieval-Augmented Generation)機能も利用できます。
5.5 関係キャッシュ(Relation Cache)
関係述語を使った検索(例:relation_predicate: "wrote")は、ES の nested クエリを伴うため、通常のフラットなフィルタより計算コストが高くなります。同じエンティティ・関係の組み合わせが繰り返し検索されるケースも多いため、search-api にインメモリの LRU キャッシュを導入しています。
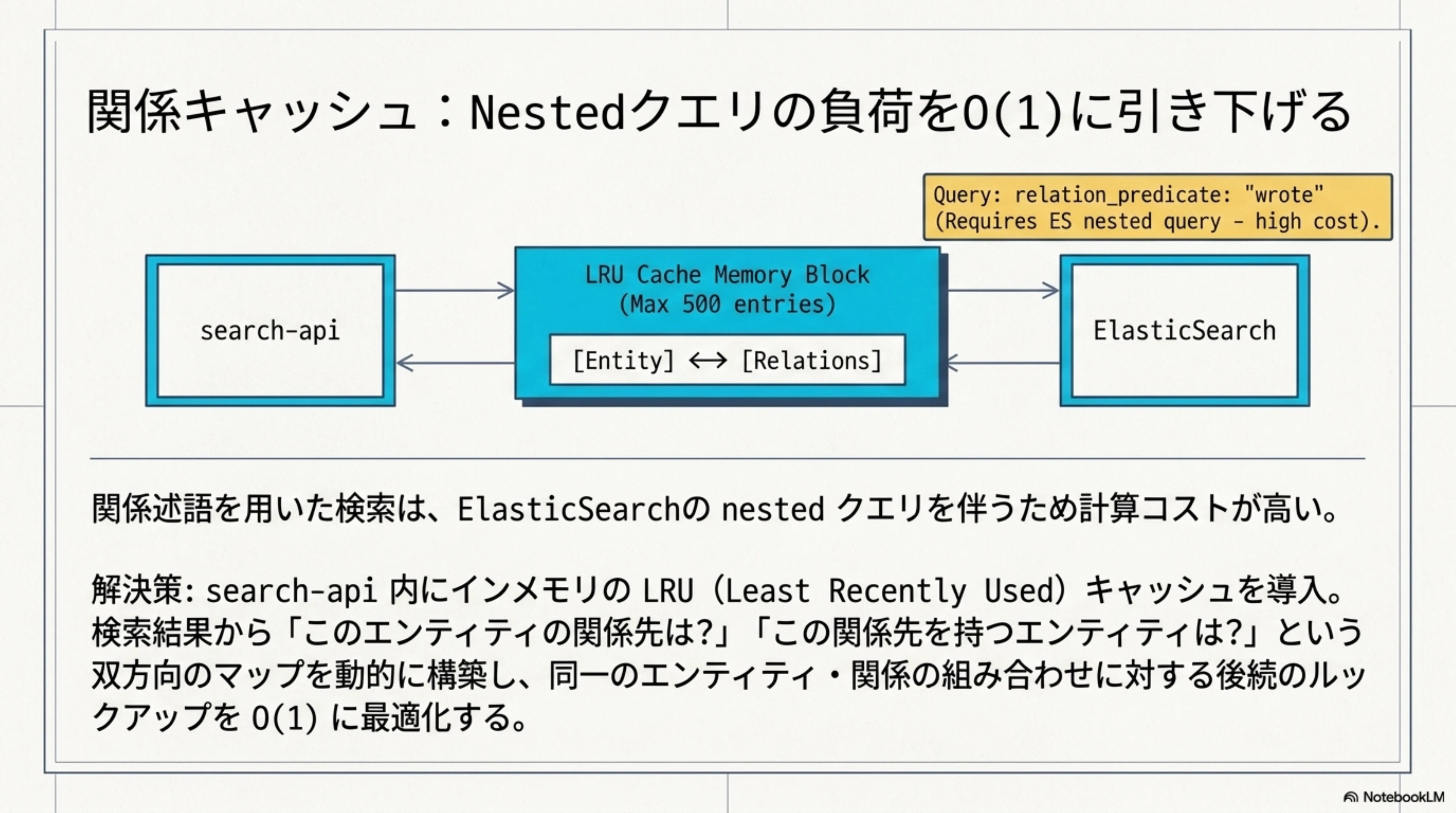
キャッシュの仕組み
検索時に relation_predicate が指定されると、検索結果の各エンティティが持つ関係(relations)から、正方向と逆方向の両方をキャッシュに登録します。
検索: "Shakespeare" + relation_predicate: "wrote"
→ 結果にシェイクスピアがヒット、relations に wrote→Hamlet, wrote→Macbeth が含まれる
正方向キャッシュ:
(shakespeare, wrote) → [hamlet, macbeth]
逆方向キャッシュ:
(hamlet, wrote) → [shakespeare]
(macbeth, wrote) → [shakespeare]
正方向は「このエンティティの関係先は?」、逆方向は「この関係先を持つエンティティは?」という双方向の引き方を O(1) で可能にします。1つの entity-relation に複数の値がある場合(シェイクスピアが複数の作品を書いた場合など)は、リストにすべて追加されます。
LRU 管理
キャッシュは上位 500 エントリを保持し、容量を超えた場合は最も長くアクセスされていないエントリから削除されます(LRU: Least Recently Used)。同一キーへの追加は既存リストにマージされ、重複は排除されます。スレッドセーフな設計のため、FastAPI の並行リクエストでも安全に動作します。
5.6 ダッシュボード(Next.js)
ダッシュボードは Next.js 15 + TypeScript + Tailwind CSS + shadcn/ui で構築されており、以下のページを提供します。
- Overview: システムの健全性、インデックス統計、最近の投入状況
- Raw Data: 生データ(コーパス)のブラウジング
- TBox Explorer: オントロジーのクラス階層をインタラクティブなツリーで表示
- ABox Explorer: エンティティの一覧・フィルタ・詳細表示
- Search Playground: 型制約・関係制約付きのインタラクティブ検索
- Ontology Graph: クラス階層とエンティティの関係をフォースレイアウトで可視化
6. 使い方
レポジトリ:https://github.com/shibuiwilliam/OntologicalSearchEngine
必要なもの
- Docker と Docker Compose(Docker Desktop で 6GB 以上のメモリを割り当て)
-
Gemini API キー(Google AI Studio で取得)
- API キーなしでも
FAKE_GEMINI=1で動作確認可能 - なお、Geminiでサンプルデータを登録する場合、1時間ほどかかります。また、金額は1万円程度になります。
- API キーなしでも
セットアップと起動
# 1. リポジトリをクローンして環境変数を設定
cp .env.example .env
# .env を編集して GEMINI_API_KEY を設定
# 2. 全サービスを起動(ES起動 → 初期化 → データ投入 → API → ダッシュボード)
make all
# 3. 動作確認
curl -s localhost:8080/health | jq # ヘルスチェック
open http://localhost:3000 # ダッシュボードを開く
検索してみる
# 型サブサンプション: "Writer" で全種類の作家がヒット
curl -s localhost:8080/search -H 'content-type: application/json' \
-d '{"query":"English mystery writers","type_constraint":"Writer"}' | jq
# 関係検索: シェイクスピアが書いた作品を検索
curl -s localhost:8080/search -H 'content-type: application/json' \
-d '{"query":"Shakespeare","relation_predicate":"wrote"}' | jq
# RAG: 検索結果に基づいた自然言語回答
curl -s localhost:8080/search -H 'content-type: application/json' \
-d '{"query":"Mark Twain","rag":true}' | jq
英語/日本語コーパスの切り替え
.env の CORPUS_LANG を変更するだけで、英語版・日本語版のコーパスを切り替えられます。
CORPUS_LANG=en # 英語
CORPUS_LANG=ja # 日本語
切り替え後は make reset && make all で再構築してください。
7. おわりに:今後の展望と課題
このアプローチの強み
- 運用の安定性: 推論をオフラインの事前計算に閉じ込めることで、知識グラフの「ライブな整合性維持」という最大の運用課題を回避できます
- 検索エンジンの成熟したエコシステム: スケーリング、モニタリング、バックアップ、セキュリティなど、ES の豊富な運用ノウハウをそのまま活用できます
- 再構築可能な設計: インデックスは「再構築可能な射影」として設計されているため、スキーマ変更やデータ修正を恐れる必要がありません。Blue/Green デプロイで無停止切替が可能です
トレードオフと限界
| 項目 | OSE のアプローチ | 含意 |
|---|---|---|
| ストレージ | クロージャ・カラムで増幅 | 読み取り速度との引き換え |
| TBox 変更 | 影響エンティティの再マテリアライズが必要 | TBox が頻繁に変わる場合は不利 |
| 多段探索 | 有界ホップは可、任意深さの探索は不可 | グラフ DB の領域は対象外 |
| 書き込み増幅 | 逆関係・推移関係で書き込みが増加 | 超高頻度更新には不向き |

真の知識グラフが必要なケース
以下のような要件が中心であれば、専用のグラフデータベースとの併用を検討してください。
- 任意深さのパス探索や最短経路計算
- サブグラフ同型やコミュニティ検出
- ACID トランザクションでの関係更新
- 推論の実行時説明保証
今後の展望
- weighted RRF の重み最適化: ベクトル検索と語彙検索のバランスを、クエリの特性に応じて動的に調整する仕組み
- Semantic Reranker の導入: Cross-encoder による最終的なリランキングで検索精度を向上
- ES|QL LOOKUP JOIN の活用: 有界多段ホップのアドホックな分析クエリ対応
- グラフ特徴量の導入: PageRank や中心性といったグラフ構造の指標を、ランキング信号としてエンティティに焼き込む

OSE は「検索が主、グラフ分析が従」というユースケースで最も輝くアプローチです。知識グラフの運用コストに悩んでいる方、検索エンジンの上にオントロジーを載せたいと考えている方にとって、一つの実践的な選択肢になれば幸いです。
ソースコードは GitHub リポジトリで公開しています。make all 一発で動く環境を用意していますので、ぜひお手元で試してみてください。