LLM開発のためのデータエンジニアリング
MLOps Advent Calendar 2023の24日目です。
Stability AIでデータ系のソフトウェアエンジニアをやっているcvuskです。主な仕事は日本語LLMのためのデータ開発です。Stability AIでは日本語LLMも各種開発しています。LLMの学習というと大量のGPUを用意して巨大なデータでモデルを学習する、というキラキラしたイメージ(?)が強いかもしれませんが、データが重要かつ苦労が耐えない課題であることは他の機械学習やディープラーニングモデルと違いありません。日本語のテキストデータは英語ほど入手しやすいわけではないのと同時に、データエンジニアリングや品質面でもいろいろと大変なことが多々あります。今回はLLMのためのテキストデータの用途やエンジニアリングについて整理します。
LLMの学習
LLMの学習は大きく分けて事前学習とファインチューニングの2段階に分けられます。事前学習は基盤になるLLMを作る過程で、巨大なデータで大量のGPUを要して汎用的なモデルを作ります。ChatGPTで提供されているGPT3.5やGPT4が事前学習済みモデルの一例になります。事前学習済みモデルに独自データやInstructionデータを用いて追加学習させるのがファインチューニングで、OpenAI GPTでもファインチューニングのためのAPIを使って自分だけのためのLLMを作ることができるようになっています。
GPTに限らず独自モデルを学習する場合に広く用いられているのがOSSとしてMeta社から提供されているLlamaモデルです。GPTがOpenAI内部で提供されモデル自体をユーザが入手できない一方で、Llamaモデルはダウンロードして独自にファインチューニングすることができることもあり、様々なLLMの祖先となっています(下図参照)。
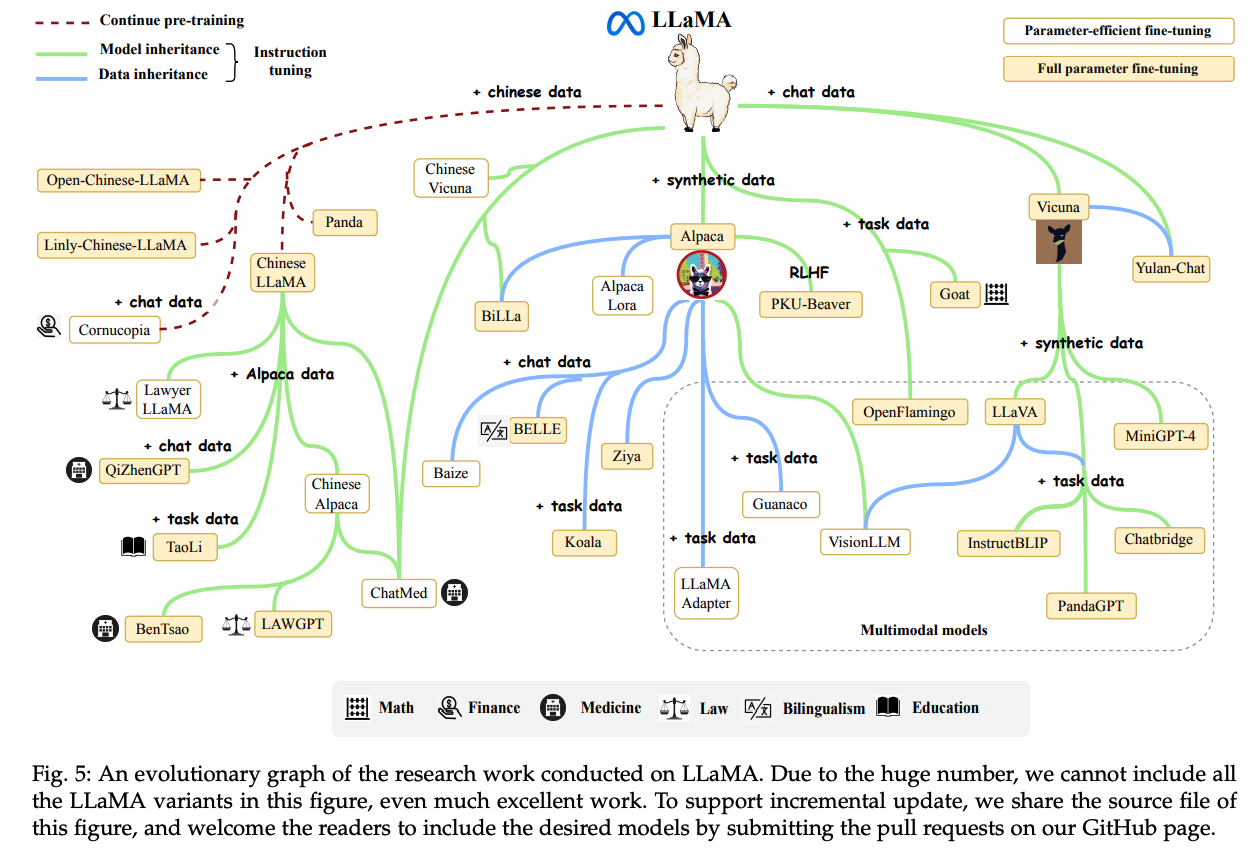
日本語のLLMはこちらで整理されているように各社で開発が進んでおり、国内でもLLM開発競争が激化したのが2023年でした。
ファインチューニングは独自のデータセットで学習させると書きましたが、ファインチューニングの中には事前学習済みモデルに特定の能力を学習させるInstructionチューニング(Instruction Tuning, IT, Supervised Fine-Tuning, SFT)という手法があります。InstructionチューニングはたとえばOpen Questionの回答や文章要約、ブレスト、分類等のタスクを実行する能力をLLMに付加するもので、各種Instruction向けのデータセットを用いて学習します。
なお、LLMの全体像はこちらのサーベイが詳しく書いているのでご参照ください。また、LLMの学習手法についてはこちらのブログがわかりやすく整理されていますので、ここでは詳細は省きます。
データセット
LLMの開発ではインフラとしてGPUを確保することや、有望な事前学習済みモデルを活用すること、さらには優秀なエンジニアを登用することは重要ですが、データの量や品質も同じくらい重要で見過ごしてはいけない要素です。
データセットの入手方法は多岐にわたります。主な方法は以下になります。
- インターネットでライセンスフリーで利用可能なデータセットを入手する。
- 有料のデータセットを購入する。
- 独自にデータセットを作る。
- 他言語のデータセットを翻訳する。
- 音声データから文字起こしする。
上記に加えて、HuggingFaceのDatasetはとても有益なデータソースです。
https://huggingface.co/datasets
ユーザが登録したデータセットが主になりますが、テキストだけでなく画像、音声、マルチモーダルのデータが揃っています。テキストだけでも各言語、各タスクごとに整理されており、ほしいデータを探すときは最初にHuggingFaceを検索するのがおすすめの手順です。
ただし、HuggingFaceのデータセットが全てライセンスフリーで使えるとは限りません。データセットそれぞれにライセンスが設定されているので、目的や用途にあったライセンスを選択する必要があります。
一般的なデータの入手方法はインターネットからダウンロードすることですが、そうしたデータの殆どは英語です。現状では日本語や他言語のデータは圧倒的に少量なことが多いです。
また、データセットにも出処や用途によって多様な種類があります。
- 事前学習で利用するデータ: 事前学習では巨大で多様なテーマやフォーマットをカバーしているデータを入手することが望ましいと言われています。
- インターネットのデータ
- Wikipediaのデータ - 本のデータ
- プログラムのコード
- 音声の文字起こしデータ
- インターネットのデータ
- ファインチューニング用のデータ: 事前学習済みモデルに特定の知識や能力を付加するためのデータです。
- 質問と回答がセットになったデータ
以下に英語と日本語のデータセットを用途に応じて整理していきます。
英語のデータセット
事前学習用
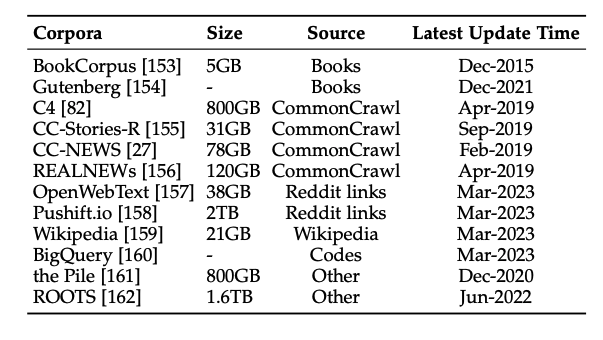
Common Crawl
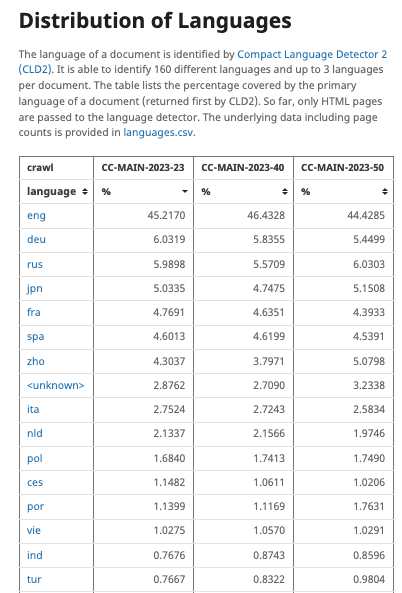
英語のデータセットとして有名なのがCommon CrawlというインターネットからWebサイトをスクレイピングしたデータで、各バージョンで100TB近いデータが用意されています。言語を問わずスクレイピングしているらしいですが、以下表にあるとおり約半数が英語になっています。
Common CrawlはWebサイトをスクレイピングして用意しているため、データにはHTMLタグのような自然言語にならない文字が含まれています。また、重複データや有害なデータ、果てはPIIも含まれている可能性があるため、高品質で有害でないLLMを学習するためには前処理が必要です。こうした生データの前処理については後述します。
Wikipedia
Wikipediaももちろん重要なデータです。Wikipediaのデータは各言語で書かれており、相応に品質の高い文章になっていることが期待されます。そのため、他データソースで得た文章の品質を評価するための基準として用いられることがあります。
arxiv
言わずと知れた論文投稿サイトです。Wikipedia同様に、正確な言葉遣いで正しい情報を提供するテキストデータセットとして期待できます。
本
BookCorpusは11,000件以上の書籍データを提供しています。また、Project Gutenbergも同様に70,000件以上の書籍を無料で公開しています。
コード
プログラムのデータソースとしてGitHubが有望なことは疑いようがないでしょう。
Google BigQueryではGitHubレポジトリのデータを一般公開データセットとして提供しており、コードデータを入手することが容易になっています。
また、Stack Overflowも有用な情報源です。特にInstructionチューニングに必要な質問と回答がセットになったQAデータとして、Stack Overflowは他にないデータフォーマットになっています。
この他にも、the stackというライセンス上利用可能なプログラミングデータを整理したデータセットもあります。
多様なデータセットの集合
各データセットを集めて1つの集合的なデータセットにしているものもあります。特にWebサイトをスクレイピングしたデータはHTMLタグや重複排除、言語分類、品質評価等の前処理が必要になりますが、それらを通してすぐ使える状態にして提供しているデータセットもあり、ありがたい限りです。
- MADLAD-400: Common Crawlデータセットをもとに複数言語のデータセットを整理したものです。
- OSCAR: これもCommon Crawlをもとにしたデータセットです。
- C4: 同様にCommon Crawlデータセットを整理しクレンジングしたデータセットです。
- Refined Web: 同様にCommon Crawlデータセットを整理してクレンジングしたデータセットです。
- The Pile: Common Crawl, Wikipedia, Books等、複数のデータソースを集合した多様性に富んだデータセットです。
- RedPajama: Common Crawl、Wikipedia, C4, GitHub, Arxiv, Stack Exchange, Gutenberg, Booksデータセットを集合したデータセットになります。
- CulturaX: C4とOSCARデータセットを集合させた多言語データセットです。
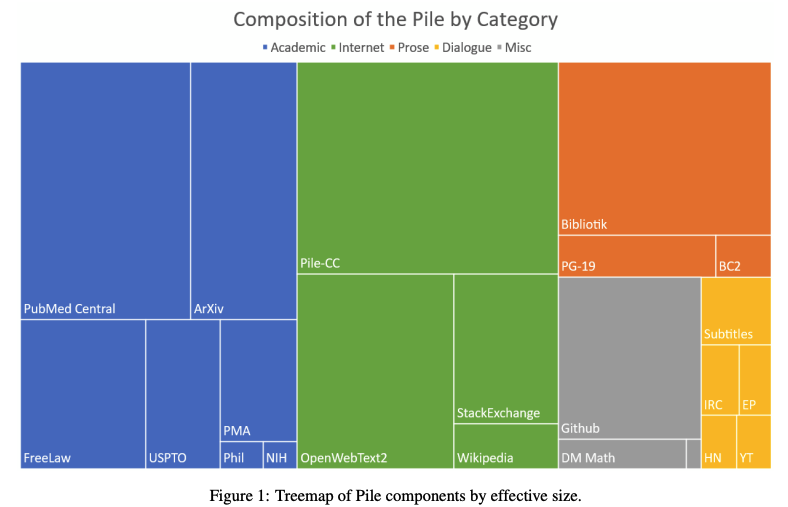
集合的なデータセットには多様な分野やテーマが含まれています。たとえばThe Pileで集計しているデータは以下のような構成になっています。
Instructionチューニング用
ここまでは事前学習用のデータセットになります。Instructionチューニングの手法やデータセットはInstruction-Tuning-Survey(論文)とAligning Large Language Models with Human: A Survey(論文)が詳しいです。
Instructionチューニング向けのデータは上記Stack Overflowに加えて、汎用的・専門的な用途として以下の種類があります。
NLPタスク用のデータセット
自然言語処理系のタスク(テキスト分類や要約等)向けに作られたデータセットです。
- P3: Public Pool of Promptsの略称で、英語のプロンプトテンプレート集です。
- FLAN: Instructionチューニング用のデータセットで、v2も用意されています。
- xsum: Extreme Summarization(XSum)データセットです。
- squad_v2: 回答可能・不可な質問を含めたデータセットです。
- JSQuAD: SQuADの日本語版です。
- QuAC: 質問、回答のデータセットです。
会話データセット
実際の人間のコミュニケーションや、LLMを用いた会話データセットです。データにはOpen QuestionやClosed question、ブレスト、普通の会話が含まれます。
- ShareGPT: ShareGPTを経由してChatGPTやGPT4で行った会話集です。
- Instruct Wild: 上記同様にGPTを使って生成したデータセットです。
- OpenAssistant: こちらもAIとの会話データ集になります。
- Natural instructions: 人間が作成した会話集です。
- Dolly: DataBricks社が提供するInstructionチューニング用データセット集になります。
Dollyに含まれるInstructionのカテゴリには以下があります。各Instructionにカテゴリが振られているため、特定カテゴリのみフィルターして使用することも可能です。

上記はいずれも人間(とAI)が作ったデータセットになりますが、LLMに指示することでLLMだけで会話データセットを作ることも可能です。こうしたデータセットをSynthetic Dataset(合成データセット)と呼びます。
論理的な推論能力
算数の文章問題のように、問題文を読んで数式で問題解決するためのデータセットです。
Alignmentデータセット
特定タスクや会話以外にもInstructionチューニングに必要なデータとして、Alignmentデータセットがあります。Alignmentデータセットでは、LLMを人間の志向に合うように、丁寧な態度や無害な回答を学習させることを目的としています。
上記は丁寧で無害な回答データセットにしていますが、逆に有害なデータセットを用意することで、LLMの有害さを評価することを可能にしています。もちろんこのデータセットで学習させることはLLMを攻撃的にする可能性がありますが、逆にLLMが攻撃的または有害な回答をするリスクを評価のためには重要なデータセットになるでしょう。
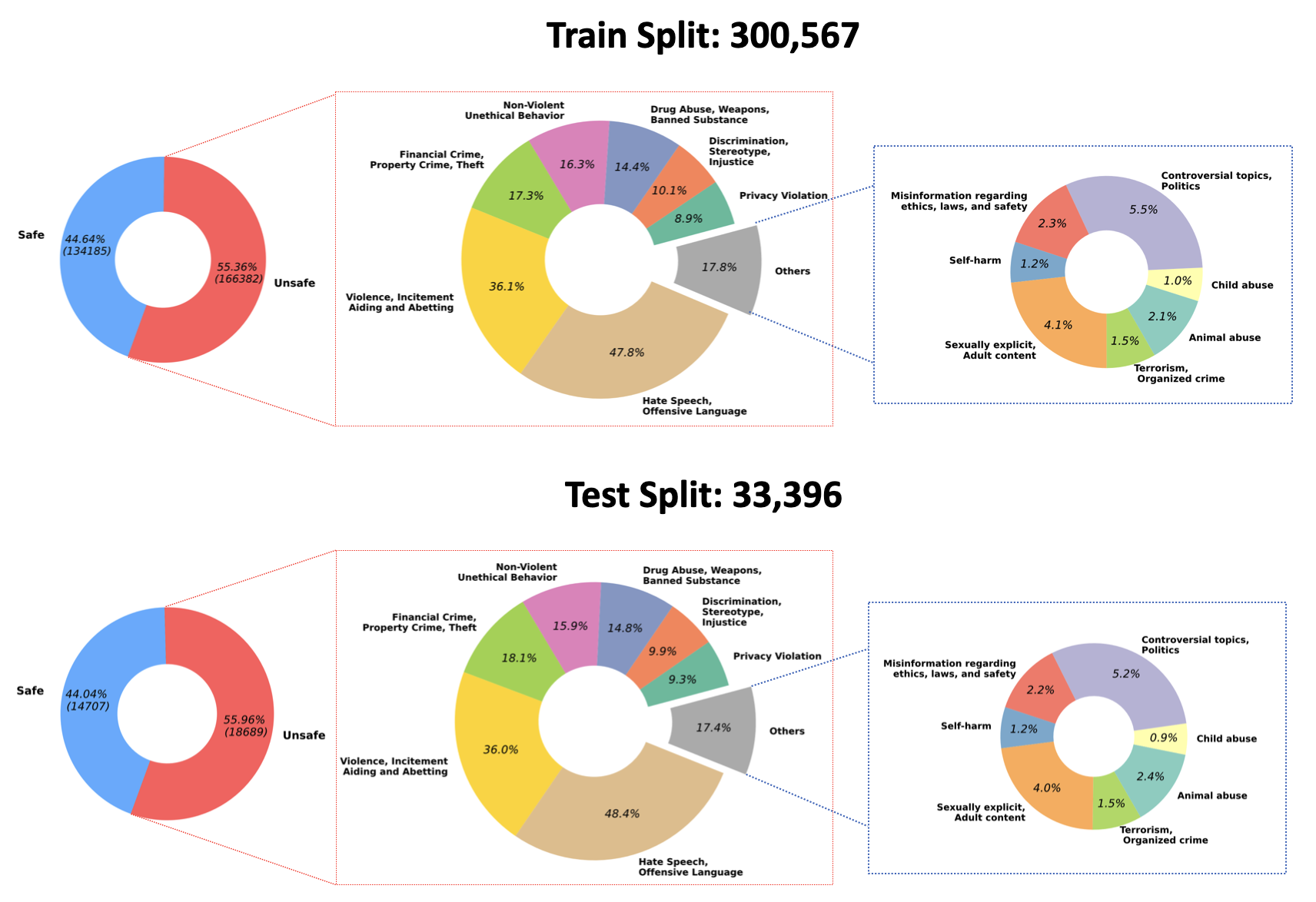
日本語のデータセット
日本語の包括的なデータセットとしてはCommon CrawlやWikipediaの日本語データや、本のデータとしては青空文庫が有力です。その他にもMADLAD-400やOSCAR、CulturaX、mC4のような集合的なデータセットにも日本語データは含まれています。
またYahoo JapanのJGLUEも包括的な日本語タスクデータセットを用意しており、とても有名です。
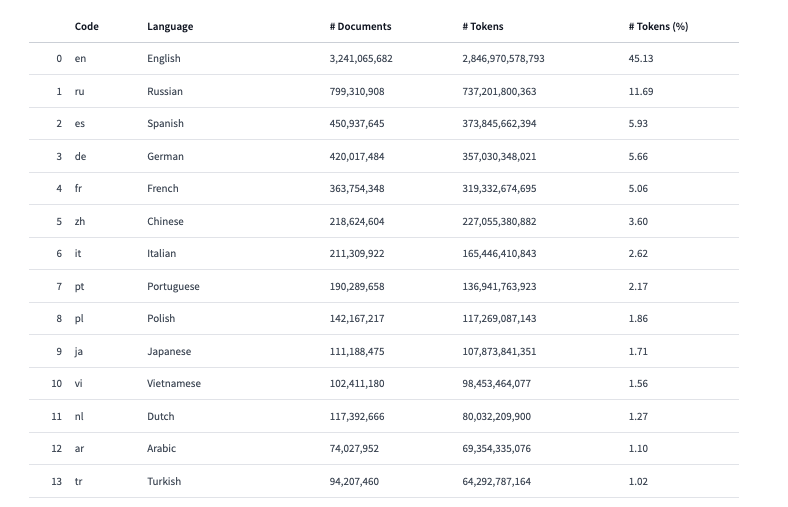
しかしCommon Crawl(前述)やCulturaX(以下テーブル)の言語比率が示すように、日本語のデータセット量は英語に比べて圧倒的に少ないのが現状です。
Instructionチューニング用
Instructionチューニング用のデータセットも英語に比べて日本語は少ないですが、もともとのテキスト量が事前学習用データよりも少ないこともあり、英語を日本語に翻訳したデータセットが多様にあります。
- llm-japanese-dataset: 日本語のインストラクション(チャット)データセットです。もともと日本語で用意されており、品質も高いです。
- dolly-15k-ja: Dollyを日本語に翻訳したデータセットです。
- HH RLHF 49k ja: HH RLHFの日本語訳です。
- ELYZA-tasks-100: 日本の自然言語スタートアップELYZAによる100件の日本語データセットです。
- rakuda-questions: 日本独自の情報に即した40件の日本語データセットです。
- japanese_alpaca_data: alpaca_data.jsonの日本語訳です。
- oasst1-89k-ja-reformat-v1: OpenAssistant Conversations Dataset (OASST1)の日本語訳です。
以下のレビューで指摘されているとおり、日本語のInstructionチューニング用データセットの一部、特に英語テキストを日本語訳したものには品質上の課題があるものが含まれており、きれいなデータを用意することが今後の課題の一つとなるでしょう。
A Review of Public Japanese Training Sets
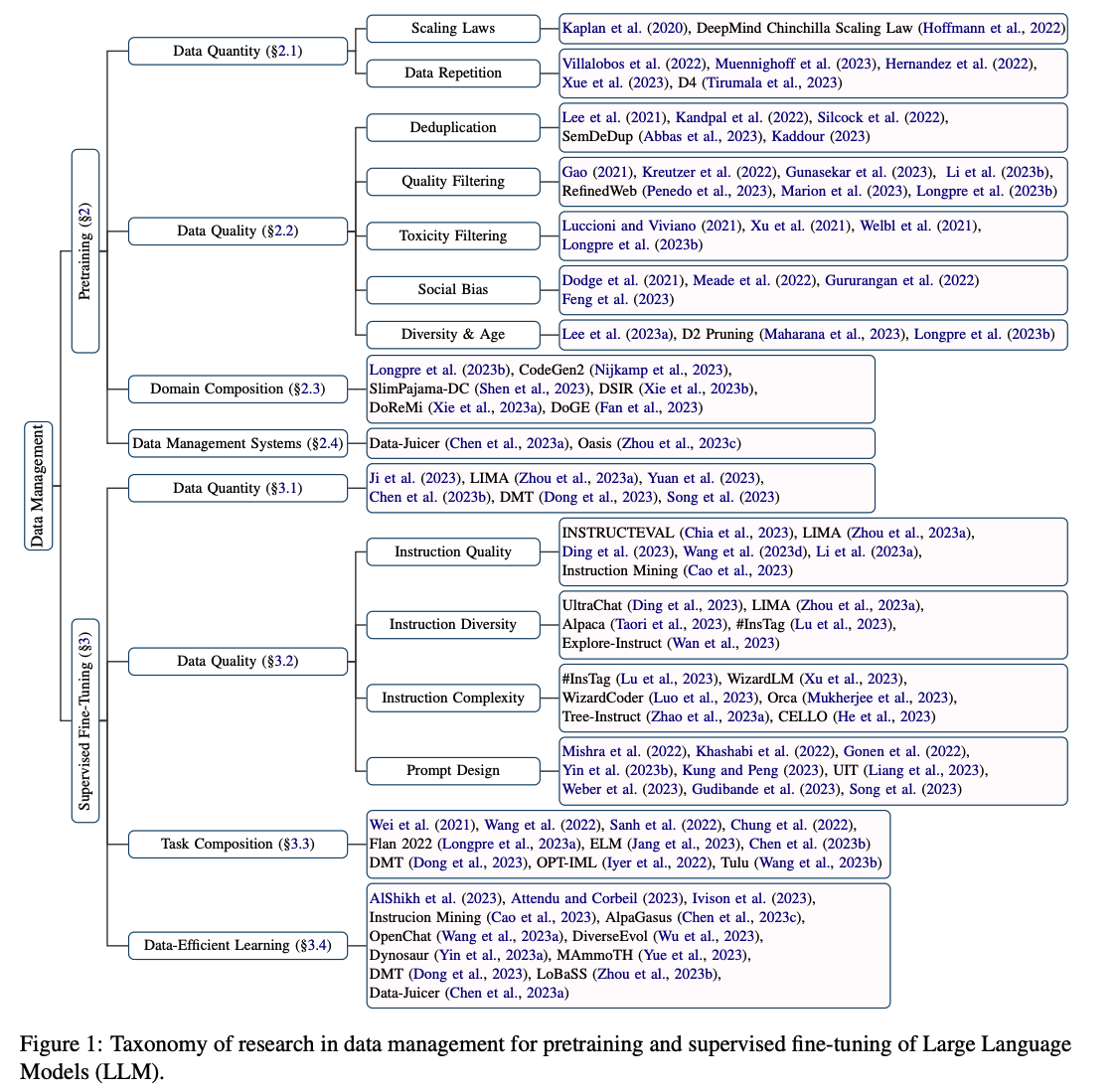
データマネジメント
LLM以外の機械学習でもデータを集計、整理、クレンジング等する必要があるのと同様に、LLMでもテキストデータを扱うための課題が多々あります。
各種情報はData Management For Large Language Models: A SurveyやInstruction Tuning for Large Language Models: A Surveyで調査されていますが、データマネジメントは大きく以下のように整理することができます。
Data Management For Large Language Models: A Surveyより
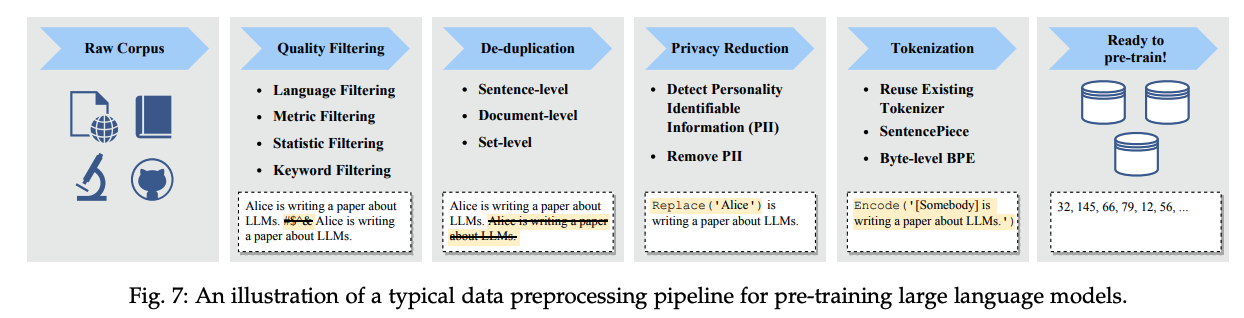
データセットを作る手順は概ね以下のような手順になります。巨大な生データ(Raw data)を収集し、重複排除と品質フィルタリングを通して一定品質以上のデータセットを作り、PIIを排除し、トークナイズします。
事前学習用データセットの場合
データの品質
品質の高いデータセットで学習させたほうが良いモデルが出来上がるのは周知のとおりですが、LLMのためのデータセットは巨大であり、品質を維持するのも一苦労です。
学習では目的に合致した一定品質以上のテキストを用いることが望ましいです。テキストを選定する方法は多々あります。
- 言語: たとえば日本語LLMを学習したい場合、日本語以外のデータを省くことができます。そのためにはデータセットの各テキストに対して言語判定を実行し、日本語とそれ以外を分類する必要があります。
- キーワードフィルタリング: 特定のキーワード(攻撃的な単語等)や要素(HTMLタグ等)を削除します。
- 統計的フィルタリング: 単語や記号の分布等を集計することで、テキストの品質を評価します。たとえば日本語で通常の文では句読点や記号が異常に多いことは稀なため、品質が低いデータとして除外することができます。
- メトリクスフィルタリング: テキストを何らかの指標(Perplexity等)で評価しフィルタリングします。
- PIIフィルタリング: 個人情報等センシティブなデータを排除します。
評価はルールベースやLLMを用いて自動化することも可能ですし、人間が評価することもあります。排除対象のテキストの性質として攻撃的、差別的、性的、非論理的、社会的バイアスというものがあります。他方でデータセットに多様性を維持することも重要であり、たとえばTask2Vecを用いて事前学習用データセットの多様性を評価する論文もあります。
たとえばCommon CrawlのようにWebサイトのデータをもとにしている場合、対象のWebサイト自体は攻撃的であったり差別的、性的な場合があります。そうしたWebサイトをURLフィルタリングで排除することも可能です。
重複排除(Deduplication)
たとえばWebスクレイピングやCommon Crawlから収集したテキストには重複が多々含まれていますが、重複したデータを発見するためにはテキスト同士を比較する必要があり、その計算量はデータ量に比例して膨大になります。単純な多対多の比較を避けるため、重複排除のアルゴリズムとしてMinHash LSHのようにN-gramとハッシュ化を組み合わせた手法が用いられます。他にもSemDeDupのようにテキストEmbeddingから近似するテキストを検索する手法もあります。
品質基準と重複排除によりデータセットから不要なテキストを削除する場合、結果として多くのでデータ量が削減されることがあります。たとえばRefined WebでCommon Crawlから高品質なテキストを抽出した結果、約90%のテキストが削減されたことを報告しています。
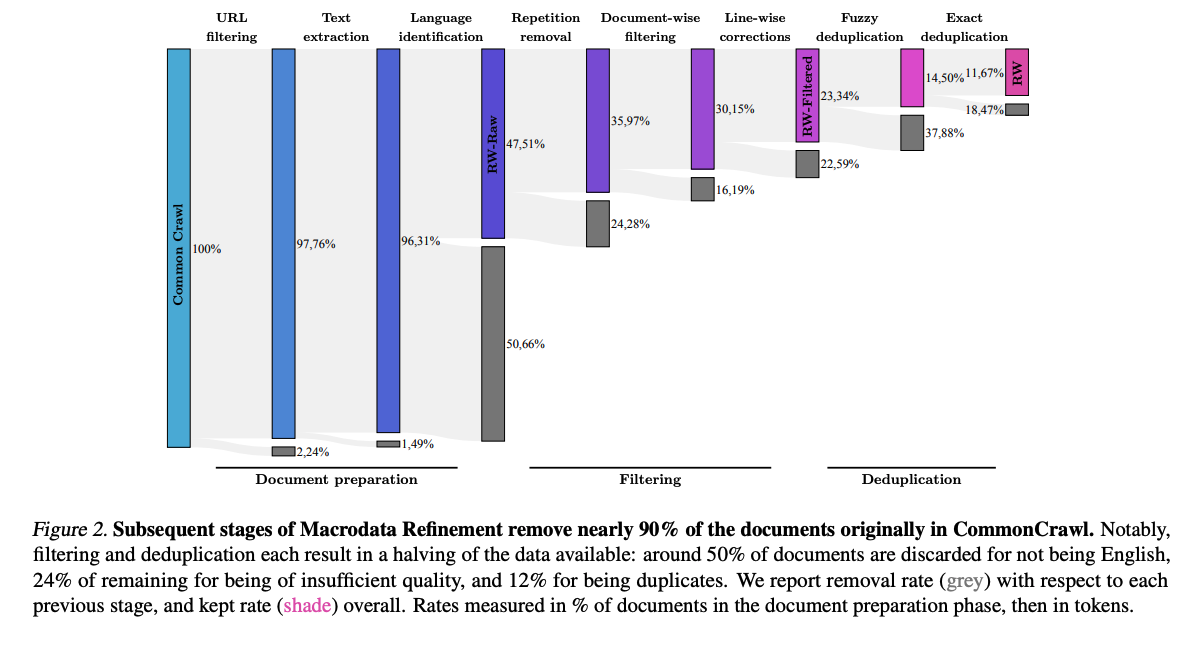
ドメイン
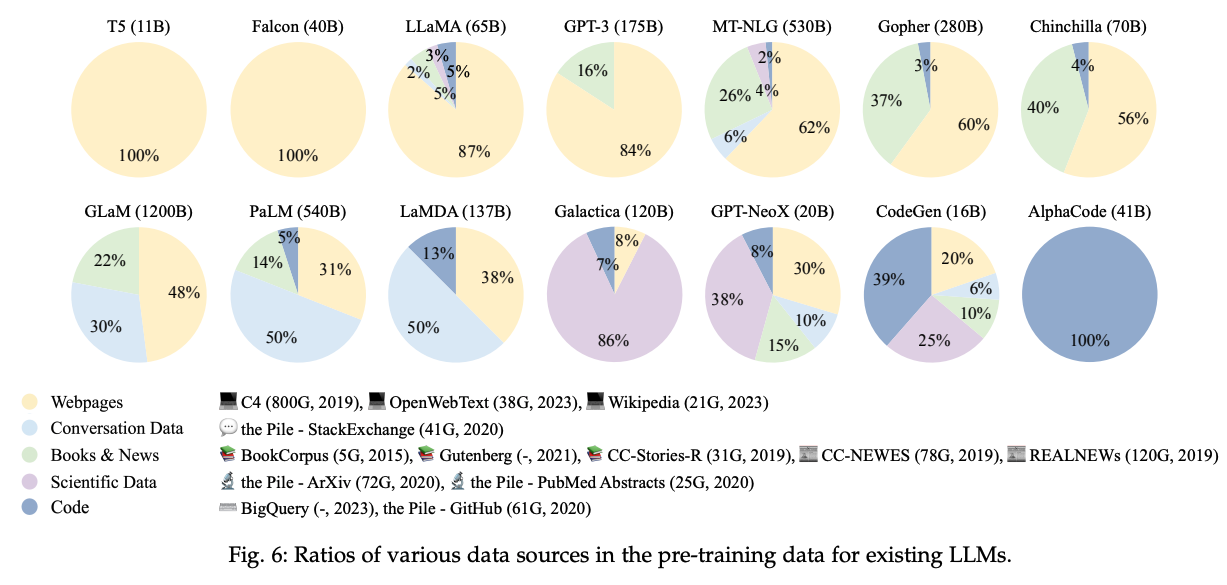
LLMが幅広い知識を獲得するためには、多様なドメインのテキストを学習に用いる必要があります。LLMに期待される知識は常識や言語、歴史、地理、数学、法律、社会等多種多様ですが、そうした目的によって各モデルが学習に使用しているデータセットの割合は多種多様です。以下で整理されているように、それぞれの目的に応じてデータセットを活用していることがわかります。
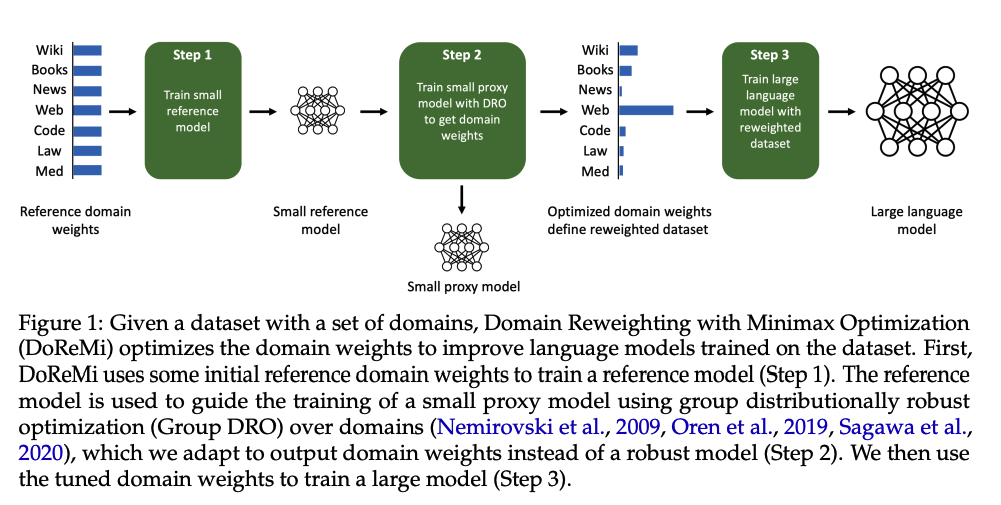
各種ドメインをバランス良くデータセットに組み込む手法には、DoReMiのようにProxy modelの学習を通して適切なドメインの比重を算出するものがあります。
Instructionチューニングの場合
事前学習用データセットと同様に、Instructionチューニング用データセットにおいてもデータの品質や多様性が重要な要素になります。
品質
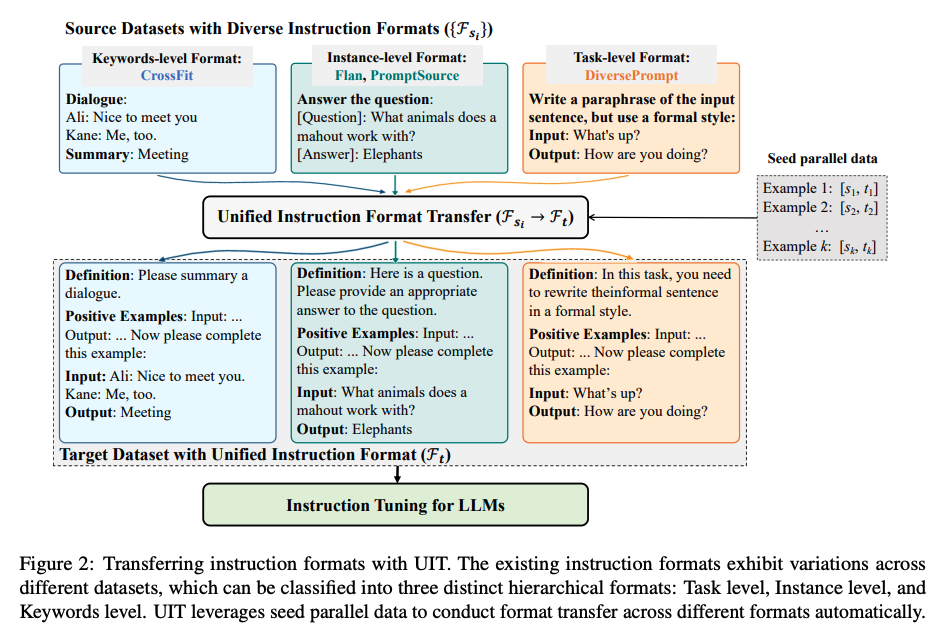
事前学習用データセットと主な違いは、Instructionチューニング用のデータセットだとInstructionのプロンプトや複雑性が関わってくる点です。Instructionは人間が作る場合もあれば、LLMで合成する場合もあります。日本語で同じ事実を複数のパターンで言い換えることができるように、プロンプトもバリエーションに富んだものが必要とされています。多様なInstructionを作るときに課題になるのがデータのフォーマットで、たとえばUnified Instruction Tuning, UITのように各種Instructionチューニング用データセットを同じフォーマットに統一する方法が提案されています。
複雑性でいうと、Instructionの複雑性をTreeモデルとしてコントロールし、複雑化することでLLMのパフォーマンスが改善されるという研究もあります。Instructionを効率的に複雑化していくEvol-Instructという手法も登場しており、複雑なInstructionデータセットを効率的に作っていくことが注目されています。
InstructionチューニングはLLMが特定のタスクを解き、人間に提案や説明する能力を獲得することが目的です。人間の教師が生徒に説明するとき同様に、LLMが人間に説明することには事実以外にも人間の求める価値があります。
- 誠実さ:常に正しい情報を用いて回答すること。誤った情報や嘘で人間を欺こうとしないこと。
- 便利さ:質問に対して求められる回答の内容、質、レベルを満たすようにすること。
- 無害性:差別的、犯罪的、虚偽等、人間を攻撃するような回答をしないこと。
こうした点が評価対象になっていることは個人的に興味深く思っています。以前であれば自然言語処理ではセマンティクスや文章生成の自然さだけが評価対象でしたが、LLMが広まって以降は、より人間のアシスタントとしての立場をLLMに求めるようになっている表れのように感じます。自然言語を扱うAIには人間的な価値に近い振る舞いが想定されているのかもしれません。このあたり、『葬送のフリーレン』で魔族が自然言語を扱うけど、人間的な価値を想定されないのと真逆ですね(?)。
データマネジメント
最後にデータマネジメントについて簡単に触れます。
LLMでは多様で巨大で複雑なデータセット扱う性質上、データを共通的に管理し操作することが重要な要素になります。LLMのデータセットはテキストデータであり、その品質やフィルタリングにはルールベースのアルゴリズムや自然言語処理が必要になります。特にテキストの意味理解や適切さの評価には高品質なLLMを用いることが最も信頼できる手法になるため、(コスト効率は目をつぶるとして)LLMのためのデータセット作成に他のLLMを利用するのが有益なプラクティスの一つです。
LLMのためのデータの前処理は前述のとおり、巨大な生データ(Raw data)を収集し、重複排除と品質フィルタリングを通して一定品質以上のデータセットを作り、PIIを排除し、トークナイズする手順を踏みます。Alibaba社の開発したData-Juicerというツールでは、この処理をMappers(変換)、Filters(フィルタリング)、Deduplications(重複排除)、Formatters(フォーマット統一)と整理し、各処理をOperatorとして実装したデータ処理基盤を提供しています。
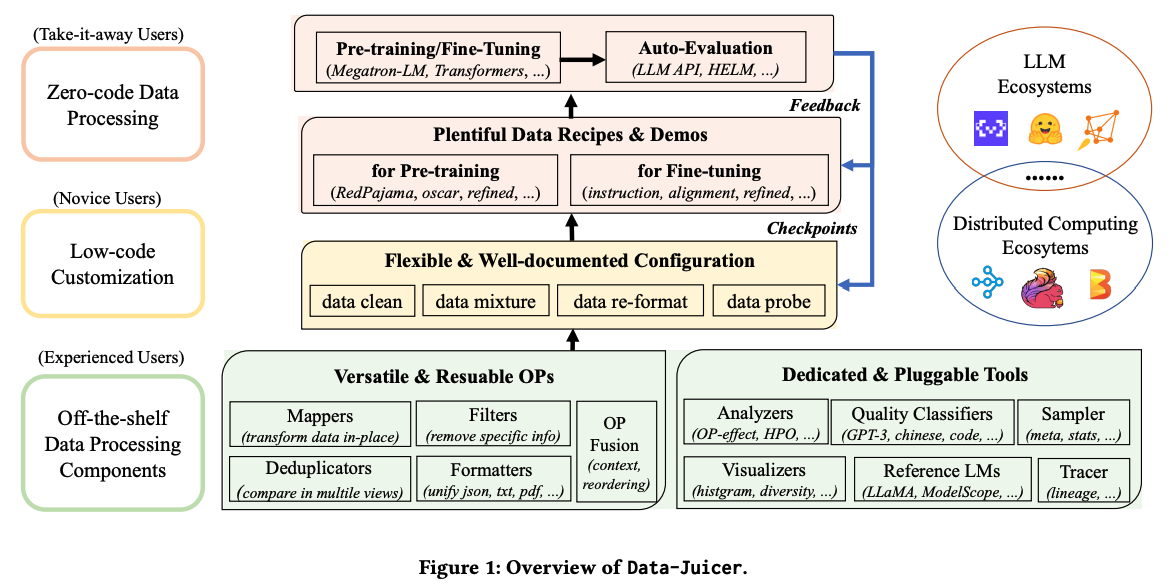
Data-Juicerは pip install py-data-juicer でインストールし、コマンドラインやPythonから使うことができる上、データをStreamlitでヴィジュアライズできるという包括的なツール群となっています。
今後同様のデータ処理基板が増えていくと予想されますが、その先駆者として期待が持てます。
まとめ
というわけでLLMのためのデータセットについて概要をまとめました。LLMそのものがそうであるように、そのデータセットの研究や活用も日進月歩でスピーディに発展している領域です。今後数ヶ月でまた新しいデータセットや処理手法、ライブラリが登場することを期待しています。