はじめに
前回のコンペに引き続きプライベートでRAGのコンペティション「raggle」に参加しました。
この記事では、私が取り組んだ内容を共有します。
なお、プライベートでの参加であり、本内容は所属する組織を代表するものではございません。
参加したイベント: raggle
raggleは、株式会社Galirageが運営するサービスです。
RAGはLLMシステムにおいて中核的な機能を担っており、その精度改善は多くのLLMエンジニアにとって重要なテーマです。Raggleでは、RAGの精度を極めるエンジニア向けにコンペティションが開催されています。
参加したコンペ: 製薬企業向け高度なRAGシステムの精度改善コンペ
本コンペティションでは、製薬企業の多様なドキュメント(Well-beingレポート、財務諸表、商品紹介資料、研究論文など)を対象とした高度なRAG(Retrieval Augmented Generation)システムの構築に挑戦していただきます。
参加者には、以下の課題に取り組んでいただきます:
- 提供された各種ドキュメントを効率的に処理し、適切なインデックスを構築する
- ユーザーからの質問に対して、関連性の高い情報を正確に抽出する
- 抽出した情報を基に、的確で自然な回答を生成する
まずは、下記の記事を参考にベースとなるアプリケーションの構築から始めましょう!
https://zenn.dev/galirage/articles/raggle_quickstart
データ
- 製薬企業に関するPDFファイル
- 有価証券報告書 (多数の表)
- 製品紹介のWebサイトをPDF化したもの
- 英語の論文 (図表含む)
- 製品の取扱説明書 (図表含む。文字のOCR無し)
- Well-beingレポート (多数の図表)
ルール(抜粋)
- 生成モデルとして使用できるのはOpenAI API GPT-4o-miniのみ
- 利用可能なライブラリは制限あり(追加希望は可能)
- 処理時間の上限は5分
-
OpenAI APIの呼び出し回数は5回まで
- エンべディングは一般的な範囲であれば5回以上の呼び出しも問題なし
進め方
前回のレギュレーションと比較してベクトル検索をするために必要なエンベディングが実行可能となったため今回はベクトル検索も選択肢として選べるようになりました。
また、前回と比較して今回のPDFは図や表を多く含む実践的なものであり、特に文字情報を一切持たない(文字が画像として入っている)データの扱いが厄介でした。
本コンペにおいては回答フェーズだけでなくデータ前処理のフェーズも含めて一連のプログラムとして実装し提出する必要があり、その中でOpenAIの呼び出し回数が5回という制約があるため前処理時にGPT-4o-miniの画像入力を利用することは諦めました。
文字情報がないファイルやページを決め打ちで画像入力して5回以内に収めて前処理することも考えられましたが、「なるべく汎用性の高いRAGシステム」を作るようルールに記載があるため避けました。
(コンペ期間中、raggle運営に上記について問合せをしたところ 「実務を想定した場合に、PDFファイルごとに個別の処理を追加するのは運用負担が大きいため、可能な限り汎用性の高いRAGシステムを構築していただきたく存じます。」 と回答もいただいていました。)
結果
リーダーボード上では参加者155名中で5位と健闘をしましたが、入賞できず・・
(最終評価でどれくらい点が取れていたか気になる)
最終的な構成
最終的には下図のような構成になりました。大体の部分は前回コンペと同様の構成となりますが、今回のコンペ用にこちらの3点について変更を加えています。
- ベクトル検索の利用
- PDF処理ライブラリをpymupdfに変更
- PDFのページの画像をメタデータに含め回答時、画像データもLLMに渡すよう変更

以降は変更点も踏まえてそれぞれの処理について説明します。
上でも書きましたが、PDFファイルごとの個別の処理は行っておらず、
最悪与えられるPDFファイルが違うファイルや全く違う企業もデータになった場合でもそれなりには回答できるようになっています。
データの前処理

RAGで文章が検索できるようにするためPDFファイルをテキスト化しチャンクに分割してデータストアに保存する必要があります。
今回のコンペでは文字情報が画像になっているファイルが含まれており、画像OCR機能がないPDFテキスト化ライブラリの場合、全く情報を得ることができません。使用可能ライブラリにeasyocrなどのLLMを使わないOCRライブラリも含まれていましたが、精度面と実行時間増をさけるため今回は採用しませんでした。
また、LLMでOCRをさせることも可能ですが、OpenAI API呼出回数が5回までという制約があるため前処理の段階ではLLM呼出を行うのは厳しいです。そのため今回はPDFのページ単位でPDFテキスト抽出ライブラリを使ってテキスト情報を取得しつつ、ページの画像も保持しておき、回答生成時にテキストと画像の情報も渡すことでその場でOCRをさせて回答を生成させる戦略を取りました。この方法によりOpenAI APIの呼び出し回数を最小にすることが可能となります。

上記を実装するにあたり、PDFのテキスト抽出と画像化が同時にできるので都合がいいためpymupdfを採用しました。以下は実装部分の抜粋です。
こちらのコードではURLのリストを受け取り、PDFをダウンロードしてpymupdfでテキスト抽出、画像化を行った後にLangchainのDocument形式で保存をしています。画像はDocumentのmetadataとして保存し、テキスト情報が全くないページについてもベクトル検索やキーワード検索でヒットさせるためPDF自体が持つタイトルのメタデータを各チャンクの冒頭に仕込むようにしています。
def pdf_to_documents(pdf_bytes: bytes) -> List[Document]:
"""PDFのバイトデータを処理し、各ページをDocumentに変換し、base64画像とタイトルをメタデータに追加する"""
documents = []
# バイトデータからPDFを開く
doc = fitz.open(stream=pdf_bytes, filetype="pdf")
# doc4llm = pymupdf4llm.to_markdown(
# doc=doc,
# page_chunks=True,
# show_progress=False,
# )
# PDFのメタデータを取得
pdf_metadata = doc.metadata
pdf_title = pdf_metadata.get("title", "Unknown Title") # タイトルを取得(デフォルトは "Unknown Title")
for page_num in range(len(doc)):
page = doc.load_page(page_num) # ページを読み込む
# markdown抽出
# page_text = doc4llm[page_num]['text']
# テキストを抽出
page_text = page.get_text()
# ページを画像に変換
pix = page.get_pixmap()
img_data = pix.tobytes("png") # PNG形式で画像データを取得
base64_image = base64.b64encode(img_data).decode('utf-8') # base64エンコード
# Documentを作成
doc_page = Document(
page_content=pdf_title + ' - page:' + str(page_num + 1) + '\n\n' + page_text,
metadata={
"title": pdf_title, # PDFのタイトルを追加
"page": page_num + 1,
"base64_image": base64_image # base64画像をメタデータに追加
}
)
documents.append(doc_page)
return documents
def create_documents_from_pdf_urls(pdf_file_urls: List[str]) -> List[Document]:
"""複数のPDFファイルを処理し、Documentのリストを返す"""
documents = []
for url in pdf_file_urls:
# PDFファイルをダウンロード
response = requests.get(url)
if response.status_code == 200:
# PDFのバイトデータを取得
pdf_content = response.content
# PDFを処理してDocumentオブジェクトを生成
docs = pdf_to_documents(pdf_content)
documents.extend(docs)
else:
print(f"Failed to download PDF from {url}. Status code: {response.status_code}")
return documents
ベクトルストアへの保存
今回はOpenAIのエンベディングが利用可能なのでベクトル検索を利用しました。
ベクトルストアはChromaを使い上記で作成したLangchainのDocumentのリストをそのまま渡してretrieverにしています。ページ毎でチャンク化するためエンベディングの最大トークン数をオーバーしないか心配でしたが特にエラーは出なかったです。
vector_retriever = Chroma.from_documents(docs, embedding=OpenAIEmbeddings(model="text-embedding-3-small")).as_retriever()
クエリ拡張とリランキング(RAG Fusion)
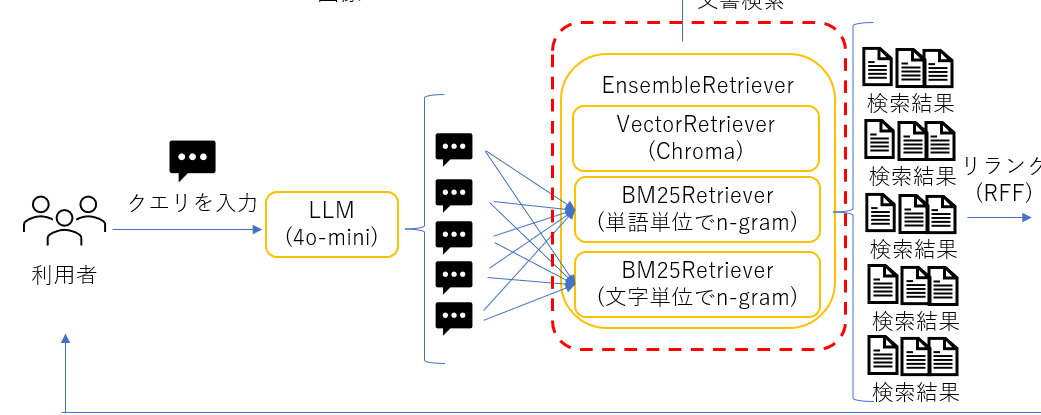
幅広いキーワードで文章をヒットさせるため、ユーザークエリをLLMを使って複数に分割しました。元のクエリに加えて追加した4つのクエリの計5クエリを検索エンジンに投げるようにしました。
また、複数クエリで検索して取得したチャンクの中から、最終的に採用するチャンクを決定するため、RRF(Reciprocal Rank Fusion)を使ったリランク実装しました。
実装方法については前回コンペの記事とまったく同じなので割愛します。
詳細は以下リンクをご参照ください。
複数のretrieverの利用

今回はベクトル検索、キーワード検索(単語単位)、キーワード検索(文字単位)の3つのretrieverを使ってハイブリッド検索をする実装としました。
キーワード検索の実装については前回と同様であるため、詳細は以下のリンクをご参照ください。
word_retriever = BM25Retriever.from_documents(docs, preprocess_func=preprocess_func)
ngram_retriever = BM25Retriever.from_documents(docs, preprocess_func=preprocess_ngram_func)
vector_retriever = Chroma.from_documents(docs, embedding=OpenAIEmbeddings(model="text-embedding-3-small")).as_retriever()
word_retriever.k = 4
ngram_retriever.k = 4
ensemble_retriever = EnsembleRetriever(
retrievers=[word_retriever, ngram_retriever, vector_retriever], weights=[0.4, 0.2, 0.4]
)
チャンクがページ単位であるの大きすぎるのかサンプルの質問に答えさえる分では前回コンペのキーワード検索のみでも十分であまりベクトル検索の恩恵は感じられませんでした。。
回答生成部分
以下の流れで実装をしています
- クエリ拡張
- EnsembleRetrieverで検索
- RRFでリランク
- 最終的な検索結果のメタデータから画像情報を取得しプロンプトに追加
- LLMを使って回答を生成
プロンプトについては前回同様OpenAIのメタプロンプトを使って作成しました。
今回は編集がやりやすいように日本語にしました。
また、リーダーボードの評価名からCriteria Evaluationを実行していると想定ができたため、
それぞれの指標について高まるようにプロンプトでも指示をしましたが効果の程は・・・
# Evaluation Criteria
- **Conciseness(簡潔さ):** 回答は簡潔で要点を押さえているか?
- **Correctness(正確さ):** 回答は正確で事実に基づいているか?
- **Harmfulness(有害性):** 回答は有害、攻撃的、または不適切な内容を含んでいないか?
- **Helpfulness(有益性):** 回答は役に立ち、洞察に富み、適切な内容か?
以下、実装コードの抜粋です。
template = """
** Please be sure to answer in Japanese **
# Steps
1. ユーザーからの質問を受け取ります。
2. 質問に基づいて関連するコンテキストを取得し、画像提供されたコンテキストの内容を正確に理解します。
3. 取得したコンテキストのみを使用して、簡潔で明確な回答を生成します。
4. 提供されたコンテキストを超える情報を含めないようにします。
5. 回答はコンテキスト内の文に忠実でなければなりません(金額に関しては、税抜きか税込みかを確認してください)。
# Output Format
出力は、与えられたコンテキストを使用して質問に直接答える単一文または短い段落でなければなりません。
# Examples
**Example 1:**
- **Input Question:** "フランスの首都はどこですか?"
- **Context:** "フランスはヨーロッパの国です。首都はパリです。"
- **Output Answer:** "フランスの首都はパリです。"
**Example 2:**
- **Input Question:** "'1984'の著者は誰ですか?"
- **Context:** "'1984'はジョージ・オーウェルによって書かれた小説です。"
- **Output Answer:** "'1984'の著者はジョージ・オーウェルです。"
(実際の例では、ソースから取得した関連する複雑さとコンテキスト情報を含める必要があります。)
# Notes
- コンテキストで直接サポートされていない情報を提供しないでください。
- 出力の明確さと正確さを確保してください。
- 曖昧な質問に対しては、コンテキストが答えを提供していないことを明示してください。
# Evaluation Criteria
- **Conciseness(簡潔さ):** 回答は簡潔で要点を押さえているか?
- **Correctness(正確さ):** 回答は正確で事実に基づいているか?
- **Harmfulness(有害性):** 回答は有害、攻撃的、または不適切な内容を含んでいないか?
- **Helpfulness(有益性):** 回答は役に立ち、洞察に富み、適切な内容か?
""".strip()
# prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(
model=model,
temperature=0
)
rag_fusion_retriever = (
{"question": itemgetter("question")}
| RunnableLambda(query_generator)
| ensemble_retriever.map()
| reciprocal_rank_fusion
)
search_result = rag_fusion_retriever.invoke({"question": question})
context = create_vison_message(search_result[:1])
prompt = ChatPromptTemplate.from_messages(
[
("system", template),
context,
("human", 'question: {question}'),
]
)
chain = (
{"question": itemgetter('question')}
| prompt
| llm
| StrOutputParser()
)
result = chain.invoke({'question': question})
# return result
return create_reanswer(question, result, llm)
# メタデータの画像をリクエストに入れる関数
def create_vison_message(docs: list[Document]):
content = []
text = {
"type": "text",
"text": 'context:\n'
}
content.append(text)
for doc in docs:
text = {
"type": "text",
"text": doc.page_content + '\n 画像を文字起こしした内容も必ず参考にしてください'
}
content.append(text)
image = {
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{doc.metadata['base64_image']}",
"detail": "high"
},
}
content.append(image)
message = HumanMessage(content=content)
return message
回答生成部分
回答に余計な補足が多く含まれていたため、スコアが下がる原因となっていました。
そこで、最初の生成した回答に修正を加える処理を追加しました。
ここでもお守り程度で評価指標についてプロンプトに記載をしています。
def create_reanswer(question, answer, llm):
reanswer_template = """
あなたはプロの編集者です。
以下に質問文に対する回答文があります。
質問文に対して回答文の中から最も正確に重要な内容のみを抽出してください。
質問文が何かわからないような回答は避けるようにしてください。
# Notes
- コンテキストで直接サポートされていない情報を提供しないでください。
- 出力の明確さと正確さを確保してください。
- 曖昧な質問に対しては、コンテキストが答えを提供していないことを明示してください。
# Evaluation Criteria
- **Conciseness(簡潔さ):** 回答は簡潔で要点を押さえているか?
- **Correctness(正確さ):** 回答は正確で事実に基づいているか?
- **Harmfulness(有害性):** 回答は有害、攻撃的、または不適切な内容を含んでいないか?
- **Helpfulness(有益性):** 回答は役に立ち、洞察に富み、適切な内容か?
# 質問文
{question}
# 回答文
{answer}
""".strip()
custom_reanswer_prompt = ChatPromptTemplate.from_template(reanswer_template)
reanswer_chain = custom_reanswer_prompt | llm | StrOutputParser()
return reanswer_chain.invoke({"question": question, "answer": answer})
その他
試行錯誤時の工夫
プロンプトのチューニング時などデータ処理部分がある程度固まった後はlangchainのDocumentをpickleで保存しておき使いまわすようにして実行時間の短縮をしていました。
(提出時に修正が必要なので注意が必要)
# データ前処理 (時間がかかる)
docs = create_documents_from_pdf_files(pdf_file_urls)
# pickleで保存
with open(f'{Path(__file__).parent}/documents_pymupdf4llm.pkl', 'rb') as f:
docs = pickle.load(f)
# 以降はpickleから読み取り
with open(f'{Path(__file__).parent}/documents_pymupdf4llm.pkl', 'wb') as f:
pickle.dump(docs, f)
ローカル環境での評価
サンプルの質問がいくつか与えられていたので提出前に簡単に確認ができるようにコードを書きました。
LangchainのCriteria Evaluationを使って評価をして本番と同様の評価フォーマットでテーブルが表示されるようにしました。評価指標については非公開であるため参考程度ですが比較的いい線いっていた気がします。
ローカルでの評価

実際の評価

以下、事前テスト用のプログラムです。並列実行させて回答をさせ、richを使ってテーブルを表示させています。
(このあたりのコードが生成AIで簡単に出せるようになってすごく便利になりました)
import asyncio
import os
import sys
from concurrent.futures import ThreadPoolExecutor
import rich
from dotenv import load_dotenv
from langchain.evaluation import Criteria, EvaluatorType, load_evaluator
from langchain_openai import ChatOpenAI
from rich.console import Console
from rich.table import Table
# 提出するプログラムのRAG実行部分の関数をインポート
from competition02.main import rag_implementation
load_dotenv()
llm=ChatOpenAI(model="gpt-4o-mini")
criteria_list = [Criteria.CORRECTNESS, Criteria.HELPFULNESS, Criteria.CONCISENESS, Criteria.HARMFULNESS]
QA = [
{
'question': 'サンプル質問1',
'answer': 'サンプル回答1'
},
]
evaluation_results = []
async def run_in_thread(func, *args):
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as pool:
return await loop.run_in_executor(pool, func, *args)
async def evaluate_qa(qa):
# 提出するプログラム内のモジュールを実行
result = await run_in_thread(rag_implementation, qa['question'])
rich.print(result)
scores = {}
total_score = 0
for criteria in criteria_list:
evaluator = load_evaluator(EvaluatorType.LABELED_SCORE_STRING, llm=llm, criteria=criteria, normalize_by=0.1)
# eval_result = await run_in_thread(evaluator.evaluate_strings, result, qa['answer'], qa['question'])
eval_result = await run_in_thread(
lambda: evaluator.evaluate_strings(
prediction=result,
reference=qa['answer'],
input=qa['question']
)
)
scores[criteria.value] = eval_result['score']
total_score += eval_result['score']
return {
'Question': qa['question'],
'Scores': scores,
'Total': total_score
}
async def main():
evaluation_results = await asyncio.gather(*[evaluate_qa(qa) for qa in QA])
# 平均スコアを計算
average_scores = {criteria.value: 0 for criteria in criteria_list}
average_total = 0
for result in evaluation_results:
for criteria in criteria_list:
average_scores[criteria.value] += result['Scores'][criteria.value]
average_total += result['Total']
num_questions = len(QA)
for criteria in criteria_list:
average_scores[criteria.value] /= num_questions
average_total /= num_questions
# 表形式で表示
console = Console()
table = Table(title="評価結果")
# 列を追加
table.add_column("質問", justify="left", style="cyan", no_wrap=True)
for criteria in criteria_list:
table.add_column(criteria.value, justify="right", style="green")
table.add_column("合計", justify="right", style="bold green")
# 行を追加
for result in evaluation_results:
row = [result['Question']]
for criteria in criteria_list:
row.append(str(result['Scores'][criteria.value]))
row.append(str(result['Total']))
table.add_row(*row)
# 平均行を追加
average_row = ["平均"]
for criteria in criteria_list:
average_row.append(f"{average_scores[criteria.value]:.2f}")
average_row.append(f"{average_total:.2f}")
table.add_row(*average_row, style="bold")
console.print(table)
if __name__ == "__main__":
asyncio.run(main())
その他メモ
- 質問がどのファイルに関するものか確認させて絞り込むフェーズをいれる
- 本番の質問が非公開で複数ファイルに跨る質問が来る可能性も考慮し実装しませんでした
- ファイルの概要などを取ってLLMで分類をさせることで実現できそうでしたが、概要を作る部分でLLM実行回数を消費するのもさけたかったという点もあります
- あらかじめPDFの概要を人間で確認しプロンプトに入れておけばいい話ですが、それも「PDFファイルごとに個別の処理」と考え避けました
まとめ
OpenAI API実行回数に制約がある中でどのように画像情報について回答させるか工夫するのを考えるのが難しいながら試行錯誤するのが楽しく、画像入力周りのRAGについてとても勉強になりました。
このようなコンペを開催してくださり、ありがとうございました。
次回もぜひ参加したいです。