【Oracle】現場でよくあるSQLのバグ
この記事でわかる・できること
- バグを発生させやすいSQL
この記事の対象者
- OracleでSQLを書く人全般
動作環境・使用するツールや言語
- Windows 10 Pro 22H2
- Oracle 12cR2 Enterprise Edition
有効期間の終了日判定のバグ
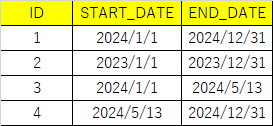
以下のようなテーブルがあったとします。
CREATE TABLE W_TEMP (
ID NUMBER,
START_DATE DATE,
END_DATE DATE
);
INSERT ALL
INTO W_TEMP VALUES(1,TO_DATE('20240101','YYYYMMDD'),TO_DATE('20241231','YYYYMMDD'))
INTO W_TEMP VALUES(2,TO_DATE('20230101','YYYYMMDD'),TO_DATE('20231231','YYYYMMDD'))
INTO W_TEMP VALUES(3,TO_DATE('20240101','YYYYMMDD'),TO_DATE('20240513','YYYYMMDD'))
INTO W_TEMP VALUES(4,TO_DATE('20240513','YYYYMMDD'),TO_DATE('20241231','YYYYMMDD'))
SELECT * FROM DUAL;
START_DATEとEND_DATEは有効期間を表す列です。
今日が2024/5/13だったとして、現時点で有効な行を抽出したい場合、直観的には以下のようなSQLになります。
SELECT * FROM W_TEMP WHERE SYSDATE BETWEEN START_DATE AND END_DATE;
しかしこの結果は以下のようになり、本来抽出したいID:3が抽出されません。

これはSYSDATEには時刻データが含まれていますが、START_DATEやEND_DATEは時刻データが含まれておらず、比較時は00:00:00になるためです。
つまりEND_DATEが2024/5/13 00:00:00なので、SYSDATEが2024/5/13 00:00:01~23:59:59の時は抽出対象外になります。
なおSTART_DATEは2024/5/13 00:00:00になった時から抽出対象になるので問題ありません。
これを回避するためにはTRUNC関数で時刻データを切り捨てましょう。
SELECT ID FROM W_TEMP WHERE TRUNC(SYSDATE) BETWEEN START_DATE AND END_DATE;
境界値テストをしていれば検出できますが、DATE型を扱う時は時刻データの有無にご注意ください。
DROP TABLE W_TEMP;
NULLとNOT IN
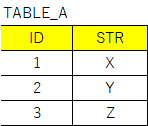
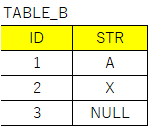
TABLE_BのSTRにないSTRをTABLE_Aから抽出したいとします。
CREATE TABLE TABLE_A (
ID NUMBER,
STR CHAR(1)
);
CREATE TABLE TABLE_B (
ID NUMBER,
STR CHAR(1)
);
INSERT ALL
INTO TABLE_A VALUES(1,'X')
INTO TABLE_A VALUES(2,'Y')
INTO TABLE_A VALUES(3,'Z')
INTO TABLE_B VALUES(1,'A')
INTO TABLE_B VALUES(2,'X')
INTO TABLE_B VALUES(3,NULL)
SELECT * FROM DUAL;
NOT EXISTSかNOT INを使うと思いますが、結果が異なります。
ここではNOT INを使うとバグになります。
SELECT STR FROM TABLE_A A
WHERE NOT EXISTS (
SELECT * FROM TABLE_B B
WHERE B.STR = A.STR
);
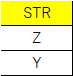
SELECT STR FROM TABLE_A
WHERE STR NOT IN (
SELECT STR FROM TABLE_B
);
NOT IN の場合は抽出対象がありません。
この理由は下記の通りです。(少々ややこしいので読み飛ばしてもいいです)
まず、SQLがOracleに解析されるとINはORで分解されます。
NOT(STR = 'A' OR STR = 'X' OR STR = NULL)
ド・モルガンの法則【NOT(A OR B) ⇒NOT A AND NOT B】で変形すると
STR <> 'A' AND STR <> 'X' AND STR <> NULL
となります。
NULLは何と比較してもTRUEでもFALSEでもなくUNKNOWNになります。(本来はIS NULLやIS NOT NULLで比較しますがNOT INでは使えません)
STR <> 'A' AND STR <> 'X' AND UNKNOWN
AND条件の場合、UNKNOWNはTRUEにならない(UNKNOWNかFALSE)ので条件を満たすレコードがありません。
優先順位は下記の通りです。
ANDの場合:FALSE > UNKNOWN > TRUE
ORの場合:TRUE > UNKNOWN > FALSE
NOT INの方が可読性が高いのですが、NOT NULL制約が無い限りはNOT EXISTSを使用した方がいいでしょう。
もしくはもっとシンプルにMINUSを使用してもいいです。
SELECT STR FROM TABLE_A
MINUS
SELECT STR FROM TABLE_B;
DROP TABLE TABLE_A;
DROP TABLE TABLE_B;
数値と文字列
0始まりの数値データ
0から始まる数値データを文字列のカラムに入れると先頭の0が削除されます。
CREATE TABLE W_TEMP (
ID VARCHAR2(5)
)
;
INSERT INTO W_TEMP VALUES(00001);
SELECT ID FROM W_TEMP;
結果は下記のようになります。

ここでは投入データを'00001'とすべきでしたが、シングルクォーテーションが抜けていたというバグです。
数値と文字列、日付などはある程度Oracleが自動的に修正してくれますが、お節介なこともあります。
投入したデータの型がカラムと合っているか確認しましょう。
また、0から始まるようなデータは扱いづらいので、できればコード設計の時点でそのようなデータが無いようにした方がいいでしょう。
数字の大小関係
INSERT ALL
INTO W_TEMP VALUES('5')
INTO W_TEMP VALUES('10')
SELECT * FROM DUAL;
SELECT * FROM W_TEMP ORDER BY ID;
直観的には1,5,10の順になりそうですが、実際には

になります。
これは文字列としてソートしているためです。MAX関数でも5が最大値になります。最初は1桁しかなかったが、途中から2桁になったことでバグが顕在化するということもあります。
'01','05','10'ならば問題ありませんが、できれば数値データを文字列(数字)として扱わない方がいいでしょう。
DROP TABLE W_TEMP;
JOINによる行の増加
あるデータに対して別のテーブルとJOINして列を追加したいということがよくあります。
例えばTABLE_Aのデータに対してTABLE_BのFLAG列を追加したいとします。
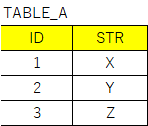
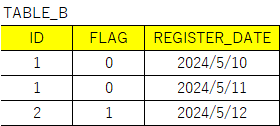
欲しい結果としては下記のような形になります。
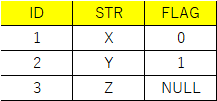
このような場合はLEFT(RIGHT) JOINを使用しますが、そのまま実行すると行数が増えます。
CREATE TABLE TABLE_A (
ID NUMBER,
STR CHAR(1)
);
CREATE TABLE TABLE_B (
ID NUMBER,
FLAG NUMBER,
REGISTER_DATE DATE
);
INSERT ALL
INTO TABLE_A VALUES(1,'X')
INTO TABLE_A VALUES(2,'Y')
INTO TABLE_A VALUES(3,'Z')
INTO TABLE_B VALUES(1,0,TO_DATE('20240510','YYYYMMDD'))
INTO TABLE_B VALUES(1,0,TO_DATE('20240511','YYYYMMDD'))
INTO TABLE_B VALUES(2,1,TO_DATE('20240512','YYYYMMDD'))
SELECT * FROM DUAL;
SELECT A.ID ID,A.STR,B.FLAG
FROM TABLE_A A
LEFT JOIN TABLE_B B
ON A.ID = B.ID;
結果は下記の通りになります。
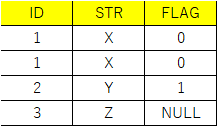
DISTINCTやGROUP BY で重複排除しましょう。
最終的な結果に対して重複排除してもいいし、TABLE_Bの時点で重複排除したものをJOINしてもいいです。
重複行が大量にある場合は早めに排除した方が高速になりやすいです。
SELECT DISTINCT A.ID ID,A.STR,B.FLAG
FROM TABLE_A A
LEFT JOIN TABLE_B B
ON A.ID = B.ID;
SELECT A.ID ID,A.STR,B.FLAG
FROM TABLE_A A
LEFT JOIN (
SELECT DISTINCT ID,FLAG
FROM TABLE_B
) B
ON A.ID = B.ID;
特にとりあえず列データを適当に大量に集めたビューやサブクエリ、あまり正規化していないテーブルを結合して使おうとすると重複データを多く含んでいるので注意が必要です。
JOINの前後で件数が変わっていないかは確認する必要があります。
DROP TABLE TABLE_A;
DROP TABLE TABLE_B;