概要
Martin Fowler氏によってDependency Injection (以下DI) と DIコンテナについての概念が2004年に発表されて約16年。
Java だけでなく JS や Swift、C# と言った様々な言語に実装されてきて基本的な設計概念として定着してきた。
だが、DIコンテナの利点、なぜDIコンテナを使うのかという話になってくると
テスト容易性をあげる、という話ばかりが多くそれ以外のメリットについて説明されることが少ないと感じてる。
Java開発を変える最新の設計思想「Dependency Injection(DI)」とは
DI (依存性注入) って何のためにするのかわからない人向けに頑張って説明してみる
そこでこの記事ではテスト容易性の向上以外のDIコンテナのメリットについて書いていきたいと思う。
まぁまぁ長いので面倒だったら結論を先に読むでいいと思う
当初、DI コンテナを直接モジュールのコンストラクタに渡す実装をしていました & 依存仕様の隠蔽という表現をしているところがありましたがコメントでの指摘を受け修正しました
前提 - DI と DIコンテナは違う-
まず、本題に入る前にDIとはなんのか、ということを軽く触れる。
依存性の注入とはある ModuleA の実行が違う ModuleB に依存していた時、
外部から ModuleA に ModuleB をセット(注入)できることをいう。
したがって以下のようなコンストラクトインジェクションも立派なDIである
public struct ServerSetting {}
public protocol APIClient { /*略*/}
public protocol UserRepository { /*略*/}
public class HTTPClient: APIClient {
public init(_ setting: ServerSetting) { /*略*/ }
}
public class UserRepoImpl: UserRepository {
public init(_ apiClient: APIClient) { /*略*/ }
}
public class Service {
public init(_ repository: UserRepository) { /*略*/ }
}
let setting: ServerSetting = ServerSetting()
let apiClient: APIClient = HTTPClient(setting) // ServerSettingを注入してる
let userRepository: UserRepository = UserRepoImpl(apiClient) // APIClient を注入してる
let service = Service(userRepository) // UserRepositoryを注入してる
service.execute()
そしてそのDIを効率的に行うための方法の一つがDIコンテナである。
DIを行う方法はDIコンテナだけではないのだが
そこにも触れると話が大きくなりすぎるのでここではDIコンテナを使ったDIについてのみ述べる。
また、DIコンテナの中にはアノテーションやリフレクションを使い記述量を減らすための DSL 的な書き方ができる物もあるが
今回はDIコンテナとは何かということを説明するために敢えてプリミティブなDIコンテナとしてSwift製のSwinjectを用いる。
(Swiftを使うのはここ最近で自分にとって一番手慣れた言語だから)
DIコンテナは何をしているのか
まず、DIコンテナが内部でどのようなことをしてるのか、というのを軽く説明する。
SwinjectでDIコンテナの設定と利用を行うと以下のようなコードになる。
(リフレクションやアノテーションを使っていないため若干冗長なコードになる)
let container = Container()
container.register(ServerSetting.self) { _ in
return ServerSetting()
}
container.register(APIClient.self) { r in
return HTTPClient(r.resolve(ServerSetting.self)!)
}
container.register(UserRepository.self) { _ in
return UserRepoImpl(r.resolve(APIClient.self)!)
}
func main() {
let repo = container.resolve(UserRepository.self)!
let service = Service(repo)
service.execute()
}
さて、やっていることを説明しよう。
- Interface と実際の実装モジュールの紐付けを設定する
- Interface が利用側から要求されると実装モジュールを組み立てる
- 組み立てられたモジュールを要求元に提供する
- 要求元は受け取った依存物を使い処理を行う
この中でDIコンテナがやっていることは仕様と実装の紐付けと解決である。
つまり語弊を恐れず乱暴に言ってしまえば
DIコンテナはクラスオブジェクトをキーとしたハッシュテーブルを拡張したものでしかなく、汎用的なものだ。
DIコンテナはテスト容易性をあげるのか
DIコンテナはテスト容易性をあげることに寄与する、とよく言われる。
しかし、正しくは依存モジュールを切り離すことができるようになるとクラスの責務が明確になり
その結果単体テストがしやすくなる、というのが本当のところだ。
ただ、依存を切り離せるようにつくるとどうしても以下のようなマトリョーシカ的なコードになってしまい、
インスタンス生成の実装コストがあがる。
let service = Service(
UserRepository(
HTTPClient(ServerSetting())
)
)
その実装コストの省力化にDIコンテナは有効である。
一度依存関係を設定してしまえば次からは以下のようにかけるし
let service = Service(container.resolve(UserRepository.self)!)
テスト側で以下のようにモックオブジェクトに切り替えることもできる
container.register(UserRepository.self) { _ in
return MockRepository()
}
let service = Service(container.resolve(UserRepository.self)!)
このような機能をもってDIコンテナはテスト容易性をあげるのに有効である、という説自体は別に間違えてはいない。
だが、DIコンテナはテストを容易にするためのものである、というところまで言ってしまうのはいささか言い過ぎである。
というのも依存モジュールの組み立て自体は Factory でもできるし、何よりDIコンテナの他の重要な利点を無視したものになるからである。
次の項で Factory を使った依存モジュール生成について述べよう。
Factory を使った依存物生成について
試しに Factory を使った生成を書いてみよう。
public class UserRepoFactory {
public static func make() -> UserRepository {
return UserRepository(
HTTPClient(ServerSetting())
)
}
}
なるほど、確かに毎回設定クラスや APIClient を生成してて冗長だ。
であるのであれば APIClient や Setting のFactoryを用意してしまおう。
そして、UserRepoFactory もクラスから関数にしてしまおう。
となると、以下のようになる。
func makeSetting() -> ServerSetting {
return ServerSetting()
}
func makeAPIClient(_ setting: ServerSetting = makeSetting()) -> APIClient {
return HTTPClient(setting)
}
func makeUserRepo(_ client: APIClient = makeAPIClient()) -> UserRepository {
return UserRepoImpl(client)
}
func main() {
let repo = makeUserRepo()
let service = Service(repo)
service.execute()
}
それぞれの関数のデフォルト引数にデフォルトインスタンスを生成するFactoryメソッドを設定することによって
基本的な利用に関してはデフォルトのインスタンスが注入され、
引数に渡ってるインスタンスを以下のようにモックインスタンスに変えてやればテストも可能である
let repo = makeUserRepo(MockAPIClient())
上記のFactoryがやっていることを整理すると以下のようになる
- Interface と実際の実装モジュールの紐付けを定義する
- Interface が利用側から要求されると実装モジュールを組み立てる
- 組み立てられたモジュールを要求元に提供する
- 要求元は受け取った依存物を使い処理を行う
そう、DIコンテナがやってることとほとんど変わらないのである。
つまり依存を切り離すことによるテスト容易性をあげるのにはFactoryでもいいということだ。
では DIコンテナとFactoryの違い、そしてDIコンテナを使う理由、すなわちメリットとはなんだろうか?
DIコンテナとFactoryの違い
前項でFactoryのやっていることを整理し、DIコンテナと比較しやっていることはほとんど変わらないと書いたが
実はというと微妙に違う。
DIコンテナは
「Interface と実際の実装モジュールの紐付けを設定する」なのに対し
Factoryは
「Interface と実際の実装モジュールの紐付けを定義する」になっている。
もったいぶった言い方になっているが簡単に言ってしまえば
Factoryの方はメソッド定義によって実装との紐付けが静的に行われているのに対し、DIコンテナは動的に行われている。
つまり、ある Interface の実装がリクエストされた時、Factoryはメソッドで定義されている以上
確実にインスタンスを返してくれるが
DIコンテナの方は設定が漏れている場合、何が返ってくるかはDIコンテナの実装仕様次第ということになる
(Google Guiceはよろしくインスタンスを生成して返してくれるが Swinjectはnil(null)を返す)
実際に Clean Architecture のケースをみてみよう。
(Clean Architecture についてはこの記事のスコープ外のため説明しない)
Clean Architecture ではDomainレイヤを実装レイヤが参照し、Domainレイヤに置かれたServiceの実行に必要なモジュールを実装レイヤが実装する、という構造になっている
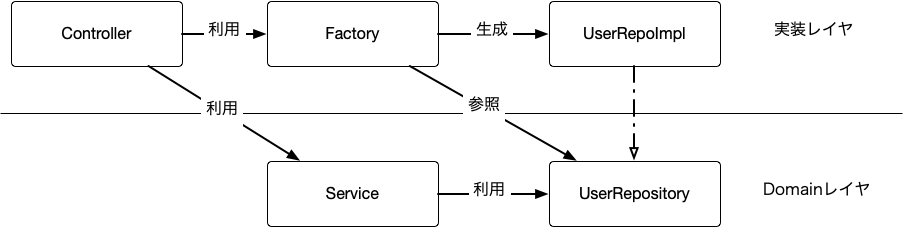
Factoryは UserRepoImpl を参照する必要があるため実装レイヤにおかれる。
故に Service を初期化するコードはFactoryを使った場合以下のようになる。
func makeService(repo: UserRepository = makeUserRepo()) -> Service {
return Service(repo)
}
let service = makeService()
service.execute()
一方、DIコンテナを使った場合は前述されたように以下のように書くことが可能である
container.register(Service.self) { r in
return Service(r.resolve(UserRepository.self)!)
}
let service = container.resolve(Service.self)!
service.execute()
あまり変わらないようだが、DIコンテナは依存関係を動的に解決できるため Container+Domain.swift を実装レイヤにも Domain レイヤにもおくことができる
一方、Factory は利用時には依存が全て解決されている必要があるため実装レイヤにしかおけない。
つまり、DIコンテナの方が Factory より依存解決の抽象度が高いと言える。
依存解決の抽象度が高いことの利点
では、依存解決の抽象度が高いことの利点はなんだろうか?
一旦 Factory を使って
Service を機能拡張し Google Analytics 等に利用状況を送ることになった例を書いてみよう。
Google Analyticsが呼ばれるかテストするために抽象化し以下のように Service にDIする手法をとるはずだ。
func makeAnalytics() -> Analytics {
return GoogleAnalytics()
}
func makeService(repo: UserRepository = makeUserRepo(),
analytics: Analytics = makeAnalytics()) -> Service {
return Service(repo, analytics)
}
let service = makeService()
service.execute()
なるほど、Factory を使えば Service の依存仕様の変更は隠蔽され controller 側の実装に影響を及ぼさないように見える。
ただ、内部的には Analytics を呼び出しているため、Factory の利用するタイミングで Analytics の実装が「定義」されている必要がある。
では次にリファクタリングによって internal なモジュールを切り離した場合を考えてみよう。
例えばこの Analytics を操作する際、タグの優先準備などやユーザーID等を紐付けるビジネスロジックを他のクラスからも使えるように Helper として切り出し
Analytics をラップしたとする。
class Helper {
init(_ analytics: Analytics) { /* 略 */}
}
依存関係は以下のような図になる
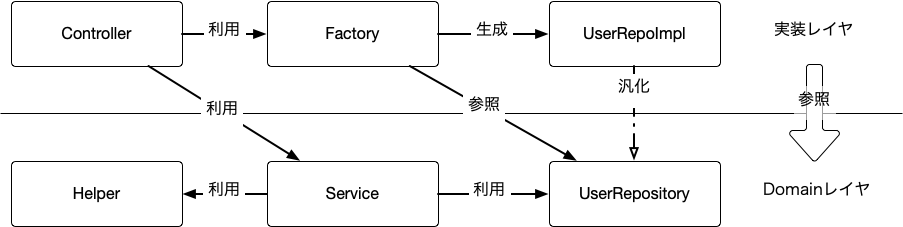
すると Factory は以下のようになるはずだ
func makeHelper(analytics: Analytics = makeAnalytics()) -> Helper {
return Helper(analytics)
}
func makeService(repo: UserRepository = makeUserRepo(),
helper: helper = makeHelper()) -> Service {
return Service(repo, helper)
}
良さそうに見えるが実は上記のコードには重大な欠陥がある。
Helper が Domainレイヤの internal なクラスであるのに対し、Factory は実装レイヤに置かざるえないため参照できずコンパイルが通らないのである。
つまり、 Factory を使って生成する場合は本来公開する必要のない Helper を public にする必要が出てくる。
微妙である。
一方、DI コンテナは実装との配線を後に回すことができるため、以下のように Domain レイヤ内の DI コンテナ設定に生成ロジックを書くことができる。
// Domain レイヤに DIコンテナの設定をおく
public func configDomainDI(with container: Container) -> Container {
container.register(Helper.self) { r in
return Helper(r.resolve(Analytics.self)!)
}
container.register(Service.self) { r in
return Service(r.resolve(UserRepository.self)!,
r.resolve(Helper.self)!)
}
return container
}
そして controller 側で依存関係の配線をつなげることができる
let combined = configDomainDI(with: container) // container は UserRepository等を実装と紐付けたDIコンテナ
let service = combined.resolve(Service.self)!
service.execute()
これこそがDIコンテナのメリットである。
configureDomainDI を定義した時点では UserRepository や Analytics の実装は決定していないが
生成ロジックを書くことができる。
つまり、Factory と比べより生成/依存解決のロジックを抽象化してると言える。
これはクリーンアーキテクチャーのように抽象が実装を参照してるような場合や
アプリケーションレイヤから動的にインフラレイヤに設定オブジェクトを後からセットする様な依存方向を逆転させるパターンの際非常に有効である。
Factory だと依存方向の関係で出来ないからだ。
(無理やりやればできなくはないが、外部からDIできるように private なパラメータを public にしたりなど歪な実装になるだろう)
また、先述した様に生成ロジックが抽象化することが可能であるため
Domain レイヤのオブジェクトの生成ロジックが変更されたとしてもその変更を吸収する
DI コンテナの設定にオブジェクトの生成ロジックを集中させてレイヤ間での生成ロジックに関する腐敗防止層を作ることができ、
変更に強くなるとも言える。
結論
以上、DIの方法についてFactoryを使ったやり方とDIコンテナを使ったやり方を比較し、それぞれのメリットとデメリットについて書いた。
まとめると
- Factory でも DI でも依存を切り離し疎結合に書くことができる
- Factory は静的に依存を解決するため依存方向が逆転するような場合、歪なコードになってしまうことがある
- DI は動的に依存を解決するため実装が決定していないモジュールに依存したとしても生成ロジックを記述することができる
- 生成ロジックが疎結合となり中間層を挟み込む余地ができ、取り回しが利くようになる(変更に強くなる)
- この生成ロジックの付け替えはテスト時のモッキングに有効
- 生成ロジックが疎結合となり中間層を挟み込む余地ができ、取り回しが利くようになる(変更に強くなる)
これでDIコンテナがテストに有効というだけで無く、依存関係を動的に切り替えられることのメリットを説明できたと思う。
DIコンテナはテストのために必要、や、DIコンテナは疎結合による生成の冗長さを解消するもの、という認識だと
生成が冗長でないものはDIコンテナを使わなくてもいいという事になってしまうが
実際は冗長でないものでもDIコンテナを使う意味はある。
ただ、DIコンテナは便利なものではあるが残念ながら万能ではない。
DIコンテナは動的に設定するため、設定を間違えた場合は実行時エラーになるしかないしそれをテストで防ぐのは難しい。
configDomainDI で UserRepository を呼んでいるが実装レイヤできちんと実装が紐付けされているかはコンパイル時にチェックできない。
(てか、DIコンテナの設定ってみなさんどのようにテストしてるんですかね。いい方法があれば教えて欲しい)
したがって依存方向が逆転しなかったり、下位レイヤの設定を上位レイヤが動的に実装を切り替える、ということがないのであれば無理に DI コンテナを使う必要はなく
むしろ静的に依存解決される Factory の方がコンパイルチェックが走る分安全ではあるだろう。
ちなみにDIコンテナ周りの記事はサーバサイドが多く、あまりDIコンテナをアプリケーションコード内で生成する記事はほとんどないが
(というかDIコンテナの設定をコロコロ切り替えるのはサーバサイドではアンチパターンである)
クライアントサイドにおいてはDIコンテナを動的に生成せざるえないことは多々ある。
それに関してはまたどこかで記事を書こうと思う。