はじめに
株式会社クリエイスのモトキです。
前回、pandasでグラフを表示しました。
Anaconda環境でPyTorch 〜株価予想〜 #01 環境構築編
Anaconda環境でPyTorch 〜株価予想〜 #02 基礎知識・学習編
Anaconda環境でPyTorch 〜株価予想〜 #03 予測編
Anaconda環境でPyTorch 〜株価予想〜 #04 予測(リベンジ)編
Anaconda環境でPyTorch 〜株価予想〜 #05 表示編 (今回)
やったこと
1.環境を再構築
VScode上でJupyterが使える環境をおすすめされたので構築しました。
それに伴い、PyenvからAnacondaを落としてきて動かせるようにしました。
環境構築はこちらを参照
Anaconda3 on pyenvとVSCodeでJupyterプラグインを使った環境構築
2.いくつかのコードを参考に、データ取得・整形・学習・保存・予測・グラフに出力を実装
# %%単位で区切れるとはいえ、読みにくかったのでファイルを分割しています。
データ取得(CSVに保存)
分割の都合で、CSVに一旦保存しています。
# %%
import quandl
if __name__ == '__main__':
print('***** start save *****')
data = quandl.get('WIKI/AAPL', start_date='2003/01/01', end_date='2018/01/01',
authtoken='token')
data.to_csv('apple_stock.csv')
print('***** end save *****')
apple_stock.csvはこんな感じ。今回はHighというカラムを使います。
Date,Open,High,Low,Close,Volume,Ex-Dividend,Split Ratio,Adj. Open,Adj. High,Adj. Low,Adj. Close,Adj. Volume
2003-01-02,14.36,14.92,14.35,14.8,3239800.0,0.0,1.0,0.92273007233099,0.95871397487315,0.92208750264274,0.95100313861411,45357200.0
...
取得したデータを整形・学習とモデル保存
ここから長いです。
CSVを読み込み、学習を行います。
# %% https://github.com/smallflyingpig/lstm_stock_pred_pytorch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
import tqdm
from torch.autograd import Variable
print('****** start setting ******')
# 乱数を固定する
torch.random.manual_seed(0)
np.random.seed(0)
# データ取得クラス
class StockDataSet(Dataset):
def __init__(self, file_path: str, t: int = 10, train_flag: bool = True):
"""
Constructor
:param file_path:
:param t:
:param train_flag:
"""
# read data
with open(file_path, 'r', encoding='utf-8') as fp:
data_pd = pd.read_csv(fp)
self.train_flag = train_flag
# データの分割サイズ(学習データ:予想されるデータ)
self.data_train_ratio = 0.8
self.T = t # use 10 data to pred
key = 'High' # 'max_price'
if train_flag:
self.data_len = int(self.data_train_ratio * len(data_pd))
data_all = np.array(data_pd[key])[::-1]
data_all = (data_all - np.mean(data_all)) / np.std(data_all)
self.data = data_all[:self.data_len]
else:
self.data_len = int((1 - self.data_train_ratio) * len(data_pd))
data_all = np.array(data_pd[key])[::-1]
data_all = (data_all - np.mean(data_all)) / np.std(data_all)
self.data = data_all[-self.data_len:]
print("data len:{}".format(self.data_len))
def __len__(self) -> int:
"""
マジックメソッド
:return:
"""
return self.data_len - self.T
def __getitem__(self, idx: int):
"""
マジックメソッド
:param idx:
:return:
"""
return self.data[idx:idx + self.T], self.data[idx + self.T]
# LSTMモデルクラス
class LstmModel(nn.Module):
def __init__(self, input_dim: int, rnn_unit: int):
"""
Constructor
:param input_dim:
入力次元
:param rnn_unit:
隠れ層
"""
super(LstmModel, self).__init__()
self.dim = input_dim
self.rnn_unit = rnn_unit
self.emb_layer = nn.Linear(input_dim, rnn_unit)
self.out_layer = nn.Linear(rnn_unit, input_dim)
self.rnn_layer = 2
self.lstm = nn.LSTM(input_size=rnn_unit, hidden_size=rnn_unit, num_layers=self.rnn_layer, batch_first=True)
def init_hidden(self, x):
"""
hiddenを初期化する
:param x:
:return:
"""
return (torch.zeros(self.rnn_layer, x.shape[0], self.rnn_unit, device=x.device).requires_grad_(),
torch.zeros(self.rnn_layer, x.shape[0], self.rnn_unit, device=x.device).requires_grad_())
def forward(self, input_data, h0=None):
"""
forward
nn.RNNは系列をまとめて処理できる
outputは系列の各要素を入れたときの出力
hiddenは最後の隠れ状態(=最後の出力) output[-1] == hidden
:param input_data:
:param h0:
:return:
"""
# batch x time x dim
h0 = h0 if h0 else self.init_hidden(input_data)
x = self.emb_layer(input_data)
output, hidden = self.lstm(x, h0)
out = self.out_layer(output[:, -1, :].squeeze()).squeeze()
return out, hidden
def l2_loss(pred, label):
"""
損失関数
:param pred:
:param label:
:return:
"""
return torch.nn.functional.mse_loss(pred, label, size_average=True)
def train_once(model: LstmModel, data_loader: DataLoader, optimizer) -> int:
"""
1回学習処理
:param model:
:param data_loader:
:param optimizer:
:return:
"""
model.train()
loader = tqdm.tqdm(data_loader)
loss_epoch = 0
for idx, (data, label) in enumerate(loader):
# data: batch, time
data = data.unsqueeze(2)
data, label = Variable(data.float()), Variable(label.float())
output, _ = model(data)
optimizer.zero_grad()
loss = l2_loss(output, label)
loss.backward()
optimizer.step()
loss_epoch += loss.detach().item()
return loss_epoch / len(loader)
def eval_once(model: LstmModel, data_loader: DataLoader) -> int:
"""
評価
:param model:
:param data_loader:
:return:
"""
model.eval()
loader = tqdm.tqdm(data_loader)
loss_epoch = 0
for idx, (data, label) in enumerate(loader):
# data: batch, time x 1
data = data.unsqueeze(2)
data, label = data.float(), label.float()
output, _ = model(data)
loss = l2_loss(output, label)
loss_epoch += loss.detach().item()
return loss_epoch / len(loader)
print('****** end setting ******')
if __name__ == '__main__':
print('***** start main *****')
file_path = 'apple_stock.csv'
dataset_train = StockDataSet(file_path=file_path)
dataset_val = StockDataSet(file_path=file_path, train_flag=False)
train_loader = DataLoader(dataset_train, batch_size=64, shuffle=True)
val_loader = DataLoader(dataset_val, batch_size=64, shuffle=True)
model = LstmModel(input_dim=1, rnn_unit=8)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
total_epoch = 100
for epoch_idx in range(total_epoch):
train_loss = train_once(model, train_loader, optimizer)
print('stage: train, epoch:{:5d}, loss:{:6.3f}'.format(epoch_idx, train_loss))
if epoch_idx % 10 == 0:
eval_loss = eval_once(model, val_loader)
# print('stage: test, epoch:{:5d}, loss:{:6.3f}'.format(epoch_idx, eval_loss))
# モデルを保存
torch.save(model.state_dict(), 'model_high.pth')
予測とグラフ出力
StockDataSetとLstmModelは同じなので中略します。
pytorch_learn.pyで保存したmodel_high.pthを読み込みます。
# %%
import pandas as pd
import numpy as np
import torch.nn as nn
import matplotlib.pyplot as plt
import torch
from torch.utils.data import DataLoader, Dataset
import tqdm
# データ取得クラス
class StockDataSet(Dataset):
# 中略
# LSTMモデルクラス
class LstmModel(nn.Module):
# 中略
def eval_plot(model, data_loader: DataLoader):
"""
反映する
:param model:
:param data_loader:
:return:
"""
data_loader.shuffle = False
preds = []
labels = []
model.eval()
loader = tqdm.tqdm(data_loader)
for idx, (data, label) in enumerate(loader):
# data: batch, time x 1
data, label = data.float().unsqueeze(2), label.float()
output, _ = model(data)
preds += (output.detach().tolist())
labels += (label.detach().tolist())
# plot
fig, ax = plt.subplots()
data_x = list(range(len(preds)))
ax.plot(data_x, preds, **{'label': 'predict', 'color': 'blue', 'linestyle': '-.', 'marker': ','})
ax.plot(data_x, labels, **{'label': 'label', 'color': 'red', 'linestyle': ':', 'marker': ','})
plt.legend()
plt.show()
if __name__ == '__main__':
file_path = 'model_high.pth'
dataset_val = StockDataSet(file_path='apple_stock.csv', train_flag=False)
val_loader = DataLoader(dataset_val, batch_size=64, shuffle=True)
model = LstmModel(input_dim=1, rnn_unit=8)
model.load_state_dict(torch.load(file_path))
eval_plot(model, val_loader)
結果と雑感
同じ区間を予想しています。
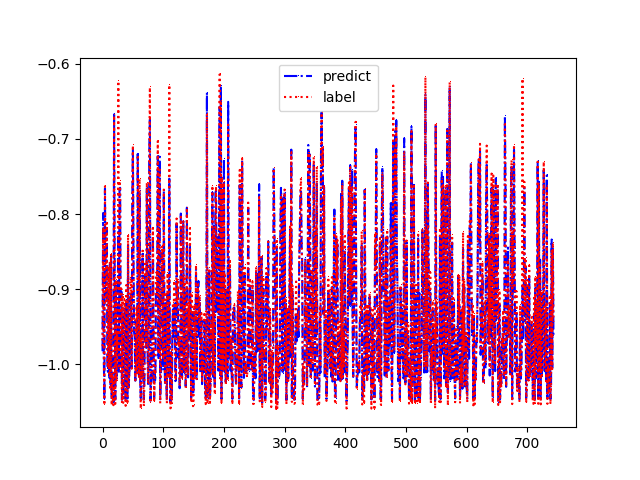
今回Pytorchでググっても出てこないものはTensorFlowのソースコードなど他のライブラリのコードを参考にしました。
(記述することもそんなに変わらないので、ドキュメントが多いライブラリ・材料で入門した方が良いのでは)
個人的にザクザクとコメントされてるだけではわからないので今回は型を意識できるように関数を宣言しています。
別チーム
別チームでもPyTorchの記事を書いています。
Docker環境でPyTorch 〜画像解析〜 #05 最終回 セクシー女優判定編