Azure Linux Data Science Virtual Machineの環境構築①-VM/OS編
Azure環境でデータ分析的なことをやろうとしていたところ、最初から色々なツールが入っているAzure Linux Data Science Virtual MachineというVMを発見したのでこれを使ってみることにしました。その際に行った設定等を纏めておきます。VMの詳細については以下のページに書いてあります。
Linux および Windows 用のクラウド ベースのデータ サイエンス仮想マシンの概要
VM作成
Azureのポータルから行います。SSD/HDD、インスタンスタイプの選択は適当なものを選択します。OSはCentOS7です。本当はUbuntuが良かったんですが。
ディスク容量はあらかじめ決まっていて、この段階では変更できないようです。デフォルトではdev/sda1の容量は約52GBでした。
固定IPの設定
再起動の度にIPが変わるのは面倒なので、固定IPの設定も行っておきます。
作った仮想マシンの概要でパブリックIPの部分をクリックすると、以下のように設定できます。

OSディスクの拡張
ディスクの拡張をする場合は、こちらの手順の通りに行うことができました。
Azure仮想マシンのOSディスク容量を拡張する(CentOS 7編)
ありがとうございます。
リモートデスクトップの導入
こちらの「X2Go クライアントのインストールと構成」の通りに設定を行います。
Linux データ サイエンス仮想マシンのプロビジョニング
日本語化
-
日本語関連のパッケージをインストールします。
sudo yum -y install ibus-kkc vlgothic-* -
システムの文字セットを変更します。
sudo localectl set-locale LANG=ja_JP.UTF-8
source /etc/locale.conf -
入力ツールをインストールをします。
sudo yum groupinstall -y "Input Methods" -
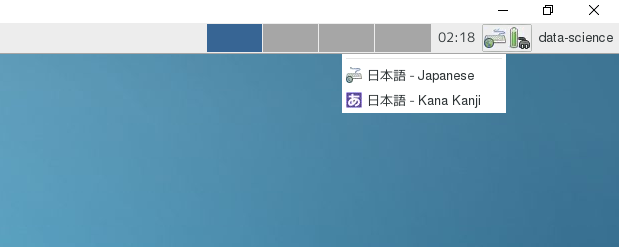
X2GOで日本語入力を行う場合は、ウィンドウ右上のキーボード設定で日本語-Kana Kanjiを選択します。
まとめ
以上で、GUIを使って日本語環境で作業をすることができるようになりました。
次回はPythonの設定まわりについて書きます。
参考ページ
Azure Virtual Machines 上にデプロイした OpenLogic CentOS 7.1 を日本語化、RDP 経由でアクセスする
CentOS 7 : 日本語環境にする
参考メモ/minimal installしたCentOS7にXfce4 + ibus-kkcで日本語入力可能にする