記事を書いたきっかけ
kaggleをはじめとするデータ解析コンペに参加する中で、実験管理の煩雑さに悩まされていました。
機械学習プロジェクトでは、モデルのアーキテクチャ検討やハイパーパラメータ探索のために、複数回の実験を行うことが一般的です。
実験の数が少ないうちはGitとTensorBoardと表計算ソフトぐらいがあれば管理は事足りるのですが、実験条件のバリエーションが増えてくると、どんどん見通しが悪くなってきます。
私はズボラなので、油断していると実験時の条件がわからなくなり、ベストスコアが再現できなくなったりしました。これは非常に困ります。

何かうまい方法はないかと調査したところ、Sacredという良い感じのOSSを発見したのですが、日本語の情報が殆ど見当たらなかったため、紹介のために記事を書くことにしました。
実験管理ツールの必要性
機械学習に限った話ではありませんが、実験の記録で重要なのは以下の2点だと考えています。
-
実験条件と結果を俯瞰・比較できるようにする
-
実験結果の再現に必要な情報をすべて残す
これらを両立して記録を取るのは、なかなかに面倒な作業です。
一口に実験結果といっても、学習時のメトリクス推移や、標準出力を含むログ、学習済のモデルなど、残したい情報は色々あります。
また、機械学習の再現性を確保するためには、最低限以下の情報の保全が必要です。
- 環境の構成情報(依存パッケージなど)
- プログラムコード(Define by Runの場合は特に)
- 乱数シード
- ハイパーパラメータ
- データセット(前処理等でバリエーションがある場合)
- その他依存関係のあるリソース(pre-trained modelなど)
環境のスナップショットだけならばGitでもなんとかなりますが、commitを実験の記録と確実に紐つけて管理しようと思うと、ちょっと大変です。
コンペに限らず、機械学習プロジェクトでは実験のスピード=試行回数が成果に直結する面があります。
記録に極力時間をかけず、かつ正確・確実に行うために、何らかのツールによる支援が欲しいところです。
Sacred
本記事では、実験管理を支援するツールとしてSacredを紹介します。
Sacredは、スイスの人工知能研究所IDSIAによって開発されているOSSで、実験の再現性を確保しつつ、効率的に記録を取ることを目的としています。
実験用のコードに、わずかなトラッキングコードを埋め込むことで、実験の記録を「自動で」データベースに保存し、比較・取り出しできるようにしてくれます。
類似の機能を提供するものとしては、neptune.mlやCometMLといったクラウドサービスがあります。これらは扱いやすく高機能ですが、無償または安価なプランでは、使える機能に制限があります。(プライベート・プロジェクトの数やストレージ、記録できる実験の数など)
OSSかつオンプレミスで稼働できるSacredには、
- 無償でもプライベート・プロジェクトが作り放題・実験し放題
- 学習済モデルや推論結果など、サイズの大きなリソースも気兼ねなく投げ込める
- リポジトリをローカルに置けるのでアクセスが高速
という、前述のクラウドサービスにはないメリットがあります。
使い方
公式ドキュメントが充実しているので、詳しくはそちらを参照頂くとして、ここでは理解を助けるための大雑把な解説・使い始めるまでの手順・簡単なサンプルを紹介します。
なお、以下の手順はUbuntu 18.04LTSの環境で確認していますが、Python+NodeJS+Dockerが使える環境であれば、他の環境でも大きくは変わらないと思います。
構成
Sacredを使用する際の基本的な構成は、下図のようなものです。

Sacred自身は実験記録を収集するトラッカーの機能のみを提供します。
実行記録を参照するためのフロントエンドは、外部プロジェクトとして複数開発されており、それらと組み合わせて使用するのが基本的な使用方法のようです。今回はOmniBoardを使ってみます。
ログの保存方法には、単なるファイルシステムへのダンプを含む複数のオプションがありますが、フロントエンドの対応状況を踏まえるとMongoDB一択と思って良さそうです。
環境構築
Sacredのインストールはpipで一発です。
pip install sacred
フロントエンドのOmniBoardはNode.jsで実装されており、npmでインストールできます。
npm install -g omniboard
あとは、実験ログを保存するためのMongoDBのインスタンスがあればOKです。
今回はdockerでサクっと立ち上げます。
# Docker ManagedなVolumeの作成
docker volume create mongo-volume
# MongoDB起動(port: 27017)
docker run -d --name mongo --restart=always --mount source=mongo-volume,target=/data/db -p 27017:27017 mongo:latest
# 管理ツール(mongo-express)を同時に起動しておくと便利
docker run -d --name mongo-express --restart=always --link mongo:mongo -p 8081:8081 mongo-express:latest
これで環境の準備はOKです。
実験コードの書き方
Sacredでは、実験をExperimentという単位で構成します。
実験用のコードをExperimentの持つデコレータで修飾することで、実験コードをExperimentに取り込むことができます。
文章だとちょっと分かりにくいので、サンプルコードを載せます。
import numpy as np
from sacred import Experiment
from sacred.observers import MongoObserver
ex = Experiment("hello_sacred")
ex.observers.append(MongoObserver.create("localhost:27017"))
@ex.config
def default_config():
message = "Sacred"
@ex.main
def main(_run, message, seed):
print(f"Hello, {message}.")
print(f"seed = {seed}")
rand_state = np.random.RandomState(seed)
for epoch in range(1, 101):
loss = 1 / (epoch + rand_state.uniform()) # dummy
acc = 1 - loss # dummy
_run.log_scalar("loss", loss, epoch)
_run.log_scalar("acc", acc, epoch)
return acc
if __name__ == "__main__":
ex.run()
順を追って説明していくと、
ex = Experiment("hello_sacred")
初めに生成しているExperimentというのが、Sacredの最も主要なコンポーネントです。
このExperimentに実験コードとパラメータを紐付けて実行することで、実験記録が自動保存されます。
複数の実験を区別するために名前を付けることができます。(ここでは"hello_sacred"を指定)
ex.observers.append(MongoObserver.create("localhost:27017"))
次に登場するObserver とは、実験ログを書き出すためのコンポーネントです。
サンプルコードではMongoDBにログを保存するためのMongoObserverをExperimentに追加しています。
Observerにはさまざまなバリエーションがあります。(詳細は公式ドキュメントを参照。)
@ex.config
def default_config():
message = "Sacred"
Experiment.configは、実験のパラメータを指定するデコレータです。
デコレータを付与したfunctionのプライベート変数は、実験パラメータとしてExperimentに取り込まれます。
(個人的には「functionのプライベート変数を取り込む」という挙動が珍しいので少し戸惑いました。)
configは複数作成して実行時に選択することや、実行時に一部のパラメータを差し替える事もできます。
サンプルコードでは、messageというキーで"Sacred"という文字列を持つパラメータを定義していますが、もちろん様々な型(数値やlistやdict)をパラメータとして管理できます。
@ex.main
def main(_run, message, seed):
print(f"Hello, {message}.")
print(f"seed = {seed}")
rand_state = np.random.RandomState(seed)
for epoch in range(1, 101):
loss = 1 / (epoch + rand_state.uniform()) # dummy
acc = 1 - loss # dummy
_run.log_scalar("loss", loss, epoch)
_run.log_scalar("acc", acc, epoch)
return pseudo_acc
Experiment.mainは、実験コードのエントリポイントを指定するデコレータです。
このデコレータを付与されたfunctionは、実験を実行すると最初に呼び出されます。
また、functionの戻り値は、実験結果(result)としてキャプチャされます。
上記サンプルコードでは、main内部で機械学習をイメージしたダミー処理を回しています。
Experiment.run()を呼ぶことで、Experiment.mainで修飾したfunctionが実行されます。
この際、引数にはExperiment.configで指定された具体的な値が与えられます。(inject)
mainの引数に注目すると、configに存在しない_runとseedという2つのパラメータを取っていることがわかります。
_runはSacredの予約語になっていて、この名前の引数がある場合、実行時コンテキストを示すオブジェクト(sacred.run.Run)を受け取る事ができます。実行中に任意のデータを記録する場合(epoch毎の精度の推移など)は、この_run経由でSacredのAPIにアクセスすることで、ログの記録が可能です。上記のサンプルコードでは、_run.log_scalar("loss", loss, epoch) の所でepoch毎のloss(のダミー値)を記録しています。
seedは、乱数シードとして利用するための値で、Sacredが発行して暗黙的にconfigに追加します。
ユーザが明示的にconfigにseedを指定した場合は、そちらの値が優先されます。
Sacredは、実験の開始前に、自動でrandomおよびnumpy.randomのglobal seedに、configのseedの値を設定します。
これによって、実験コード側であまり意識をしなくても疑似乱数の再現性が確保されるようになっています。
※注:非同期処理などの影響で乱数の発行順序が非決定的である場合は再現困難です。
なお、numpy以外にランダム性を持つライブラリを使用する場合(PyTorchなど)は、別途実験コードでseed値の設定が必要です。
他にも、いくつかのデコレータが存在し、例えば任意のfunctionをExperiment.captureデコレータで修飾することで、エントリポイント以外のfunctionにもconfigの値をinjectすることができます。(簡易的なDIのようなイメージです。)
上記のサンプルコードを実行した結果が以下になります。
$ python hello_sacred.py
INFO - hello_sacred - Running command 'main'
INFO - hello_sacred - Started run with ID "1"
Hello, Sacred.
seed = 889569123
INFO - hello_sacred - Result: 0.9900083033466508
INFO - hello_sacred - Completed after 0:00:00
実験コードの標準出力に加えて、実験の名称やSacredによって発番されたID、実験結果のメトリクス、実行時間などが表示されています。
実験ログの参照
実験コードを実行できたので、OmniBoardを開いて、実験ログを見てみます。
まず、OmniBoardを起動します。
# OmniBoardの起動
omniboard -m localhost:27017:sacred
引数-mには、ログの保存先となっているMongoDBのデータベースを指定します。
なお、Sacredのログ保存先のデータベース名は標準で「sacred」です。(変更可)
この状態でブラウザからlocalhost:9000にアクセスすると、OmniboardのUIが表示されます。
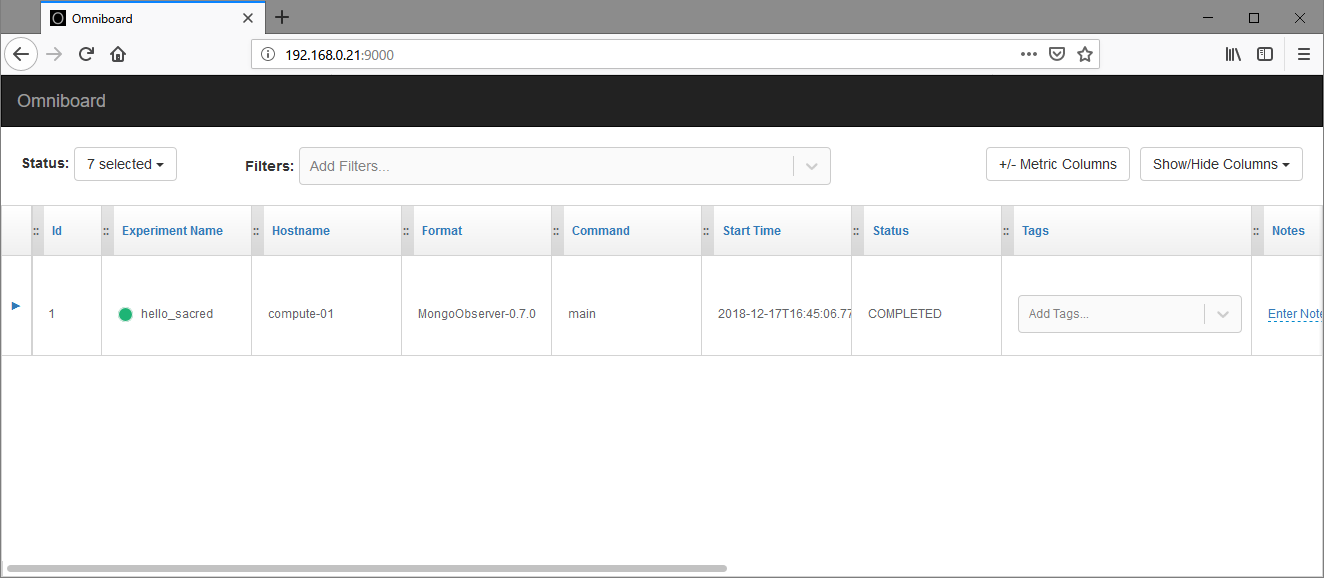
先ほど実行した実験のログが保存されているのがわかります。
このビューでは、複数の実験をリスト形式で俯瞰できます。
それぞれの実験に対して後からタグやメモを付けたり、タグで実験を絞り込むこともできます。
実験ログは実験コードの実行中に随時更新されているため、簡易的な実行状況の監視にも使えます。
実験の詳細を確認したい場合は、行頭の三角マークをクリックすることでドリルダウンできます。
参照できる情報から代表的なものをピックアップして紹介します。
-
メトリクスの推移
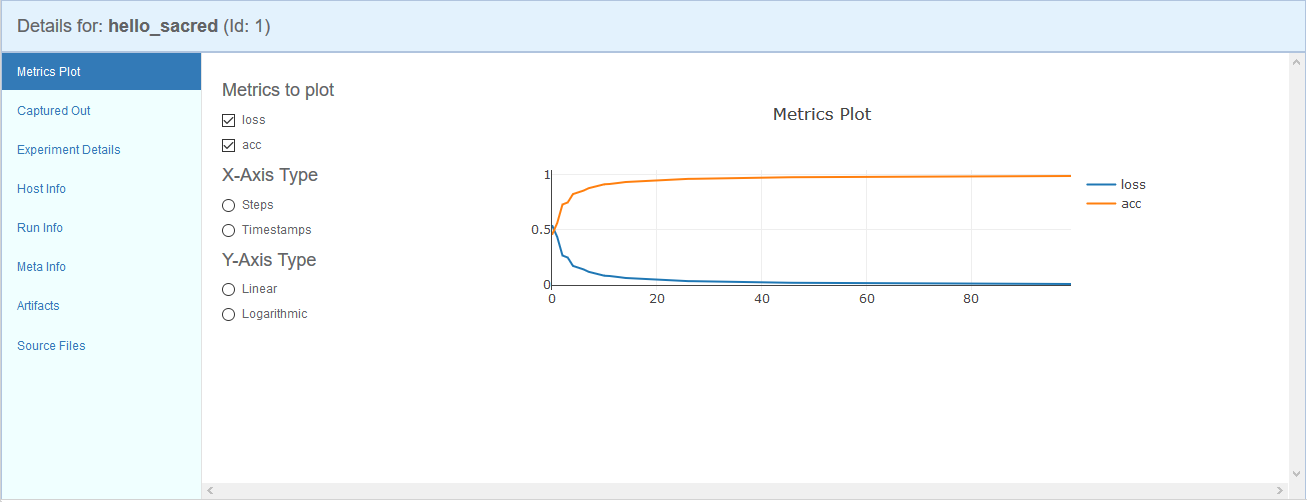
-
標準出力のキャプチャ
-
実験の詳細情報(依存パッケージのバージョンなど)
-
実行環境の情報(OS、ホスト名、CPU/GPUの情報、環境変数など)
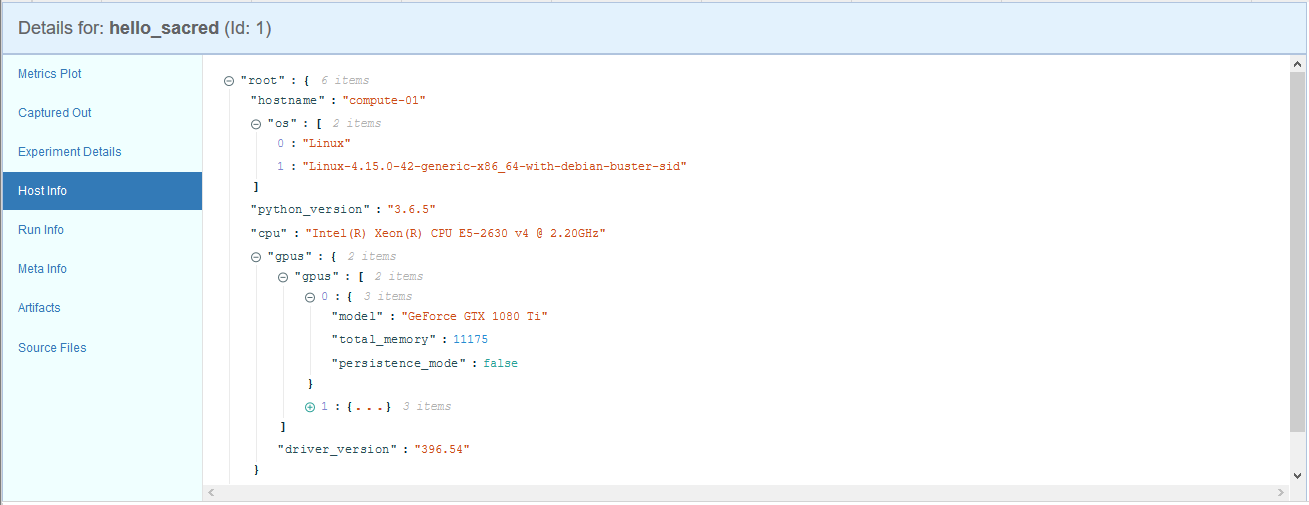
-
ソースコードのスナップショット
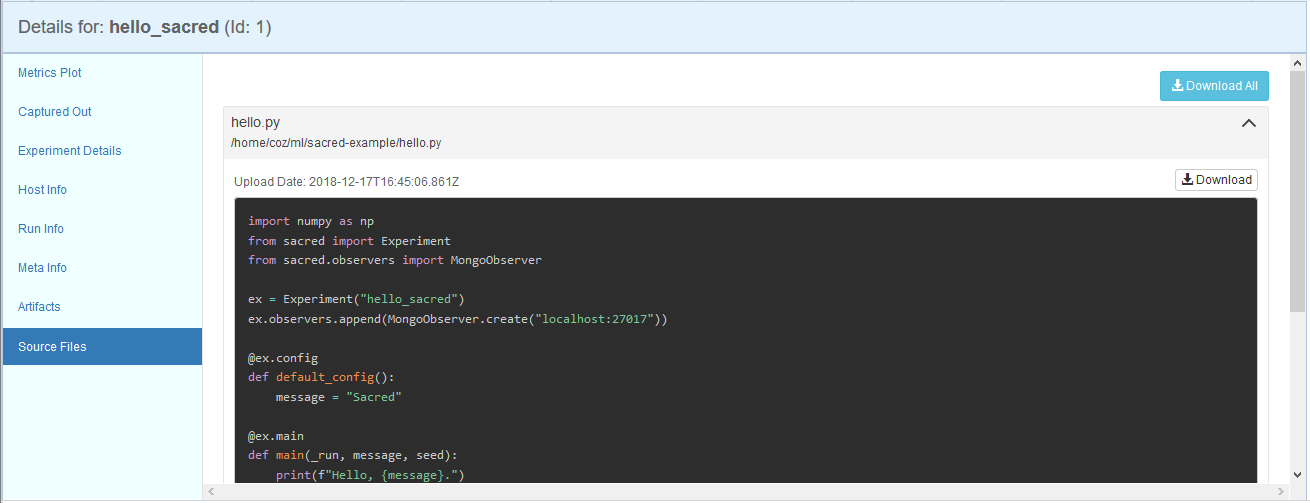
他にも、実験に任意のバイナリデータを添付しておいて、後からダウンロードする事もできるので、
例えば学習に使ったデータセットや、学習済モデルのダンプを保存しておくことも可能です。
(バイナリデータはハッシュ管理されており、同じデータが重複して保存されることはないようです。)
使ってみた感想など
率直に言って良くできているなー、という印象です。(小並感)
実は比較対象となるクラウドサービスを殆ど使っておらず、あくまでSacredだけを触った感想なのですが、
よいところ
- 手間をかけず、ある程度自動で環境情報やコードを保存してくれる
- オンプレ環境にもサクっと建てられる
もうちょいなところ
- お作法がちょっと独特で慣れが要る(デコレータを使った記述や引数の予約語など)
- メトリクスの推移を実験同士で比較しづらい(OmniBoard)
- グラフの表示が小さい(OmniBoard)
慣れの問題もあるとは思いますが、メトリクスの詳細表示に関しては、普段使いのTensorboardと比べると使いづらさがあるので、現状では併用したい感じです。
その他雑感
optunaのような便利な最適化ツールも出てきているので、人間が試行錯誤で数値パラメータを調整する機会は減っていくのかも知れませんが、モデルの構造を変更して実験を繰り返すケースなど、実験そのものは当分無くならないと思われるので、活躍の場は多そうです。
個人的には今後のコンペで積極的に使用していきたいと思います。(余裕があればcontributeしたい。)
もし「もっと良い方法/ツールがあるぞー」みたいな方がいれば、情報頂けるとハッピーです。