はじめに
PythonやR等のプログラミング言語では、統計解析のライブラリが豊富に存在しますが、プログラミングによる解析は面倒です。
Power BI+Pythonで主成分分析では、Power BIのクエリー処理でPythonによる分析を行い、PowerBIで可視化を行いました。今回は、アンケートのデータを例に、主成分分析で2軸に要約し、クラスター分析によるグルーピングを試みます。
サンプルデータ
以下のような、サンタ帽のカラーイメージを評価するアンケートを扱います。
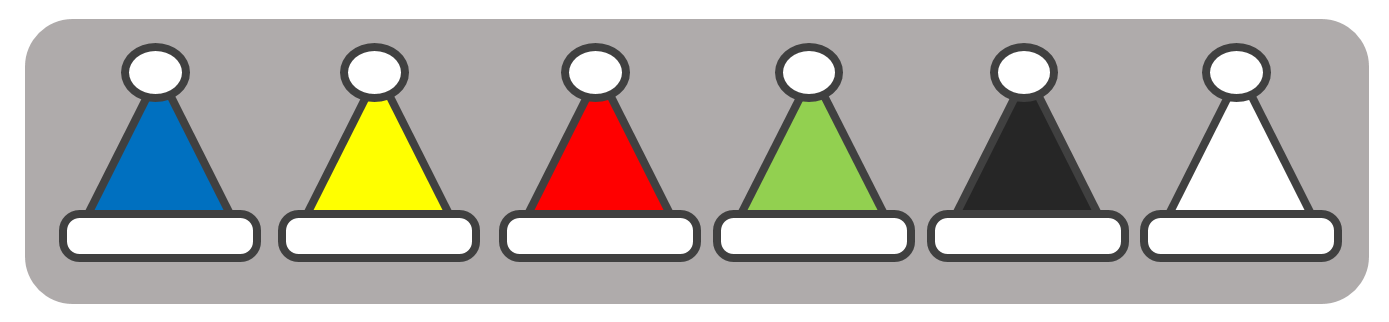
アンケートの設問(一部)
ここでは、SD法という、対となる形容詞でイメージを探るアンケートでデータを収集します。
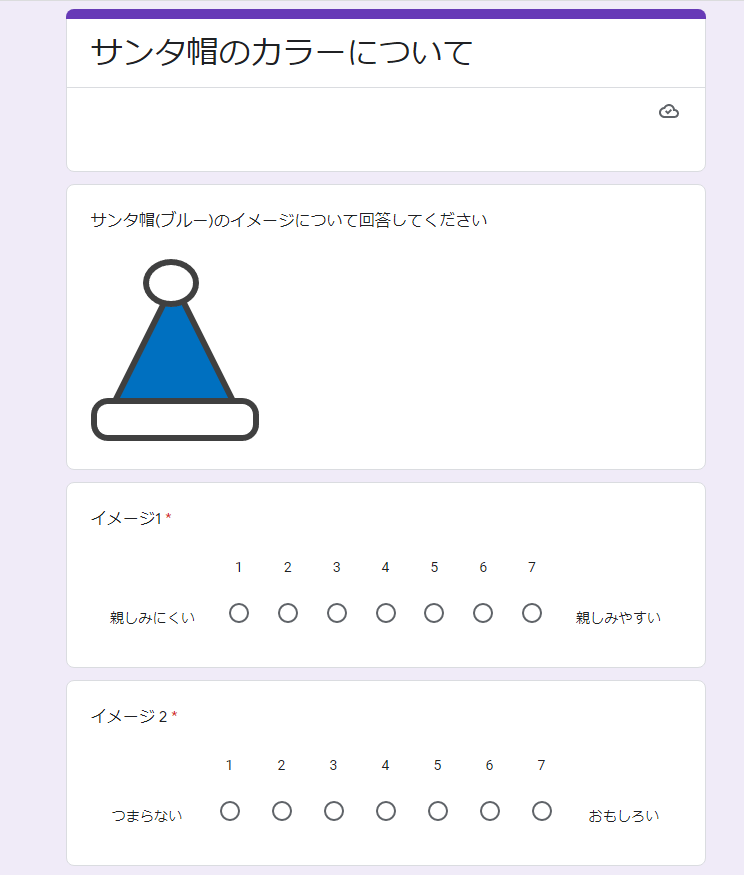
回答データ(サンプル)
アンケート結果から、以下のようなExcelデータを用意します。
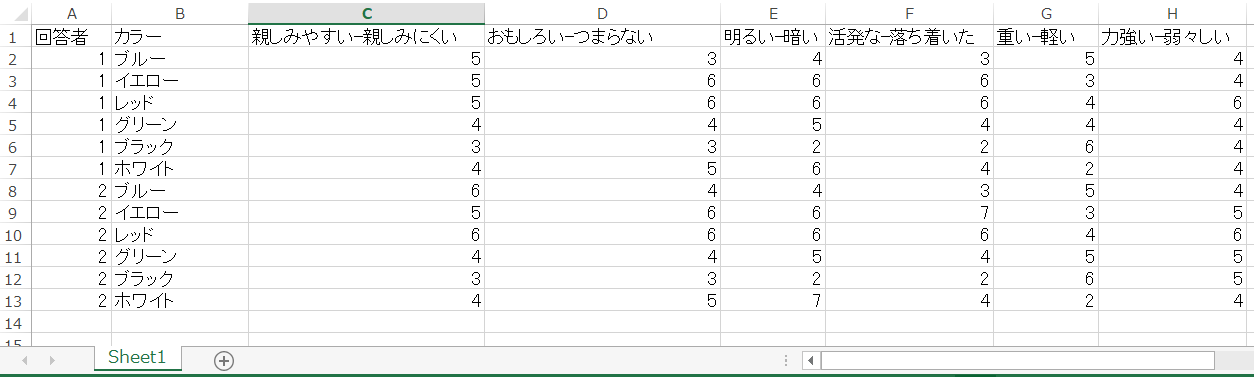
| 回答者 | カラー | 親しみやすい-親しみにくい | おもしろい-つまらない | 明るい-暗い | 活発な-落ち着いた | 重い-軽い | 力強い-弱々しい |
|---|---|---|---|---|---|---|---|
| 1 | ブルー | 5 | 3 | 4 | 3 | 5 | 4 |
| 1 | イエロー | 5 | 6 | 6 | 6 | 3 | 4 |
| 1 | レッド | 5 | 6 | 6 | 6 | 4 | 6 |
| 1 | グリーン | 4 | 4 | 5 | 4 | 4 | 4 |
| 1 | ブラック | 3 | 3 | 2 | 2 | 6 | 4 |
| 1 | ホワイト | 4 | 5 | 6 | 4 | 2 | 4 |
| 2 | ブルー | 6 | 4 | 4 | 3 | 5 | 4 |
| 2 | イエロー | 5 | 6 | 6 | 7 | 3 | 5 |
| 2 | レッド | 6 | 6 | 6 | 6 | 4 | 6 |
| 2 | グリーン | 4 | 4 | 5 | 4 | 5 | 5 |
| 2 | ブラック | 3 | 3 | 2 | 2 | 6 | 5 |
| 2 | ホワイト | 4 | 5 | 7 | 4 | 2 | 4 |
データ読み込み
データを取得より、アンケートのExcelデータを読み込みます。
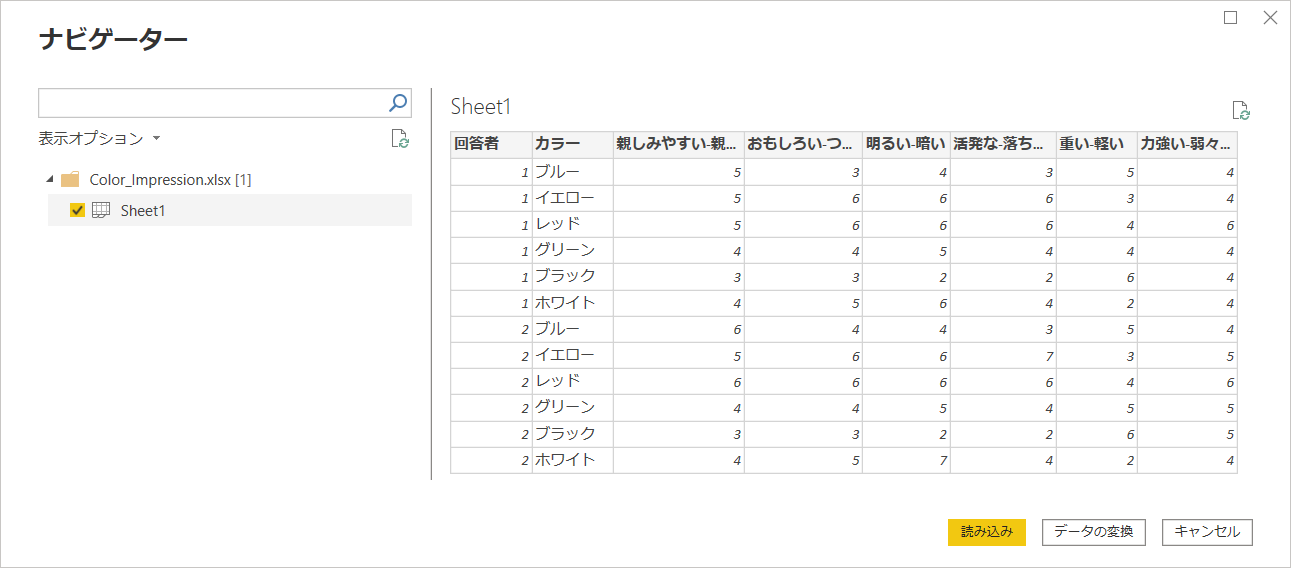
クエリーの編集
-
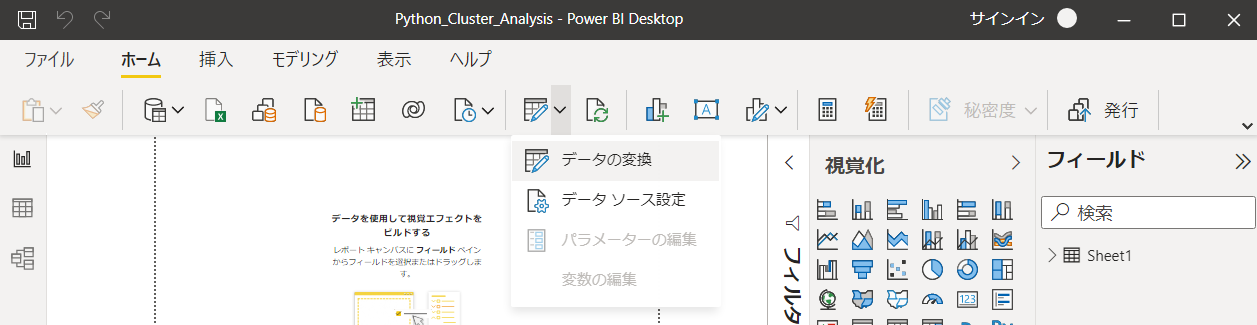
データの変換をクリックし、Power Queryエディタを起動します。
-
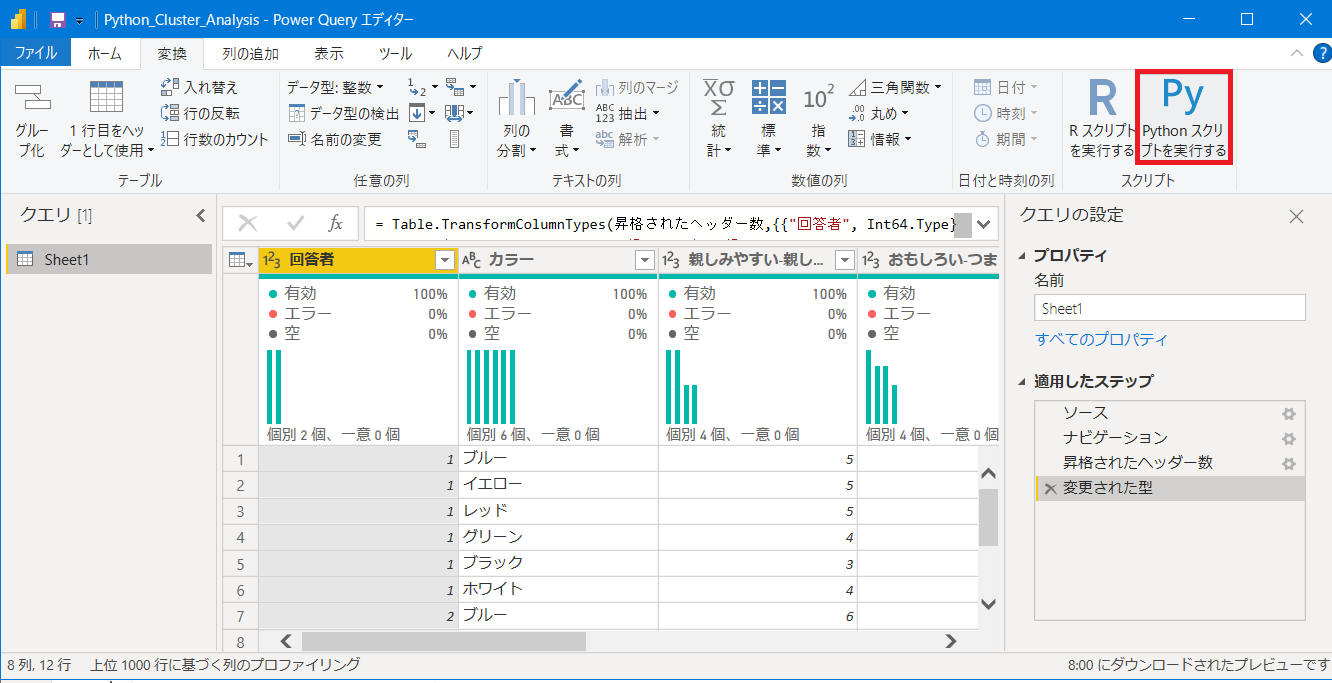
メニューの変換>Pythonスクリプトを実行するをクリック
-
Pythonスクリプトを記述します。(pythonライブラリのsklearn,pandasを使用しています)
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
dataset2=dataset.drop(dataset.columns[[0,1]],axis=1)
X=dataset2.values
pca = PCA()
pca.fit(X)
pca_point = pca.transform(X)
dataset['PC1']=pca_point[:,0]
dataset['PC2']=pca_point[:,1]
evr=pd.DataFrame(data=pca.explained_variance_ratio_, columns={'explained_variance_ratio'}, dtype='float')
evr['PC No.']=evr.index+1
components=pd.DataFrame(data=pca.components_, columns=dataset2.columns, dtype='float')
components['PC No.']=components.index+1
km = KMeans(n_clusters=2, # クラスターの個数
init='random', # セントロイドの初期値をランダムに設定 default: 'k-means++'
n_init=10, # 異なるセントロイドの初期値を用いたk-meansの実行回数 default: '10'
max_iter=300, # k-meansアルゴリズムの内部の最大イテレーション回数 default: '300'
tol=1e-04, # 収束と判定するための相対的な許容誤差 default: '1e-04'
random_state=0) # セントロイドの初期化に用いる乱数発生器の状態
y_km = km.fit_predict(pca_point)
dataset['Cluster']=y_km
del dataset2
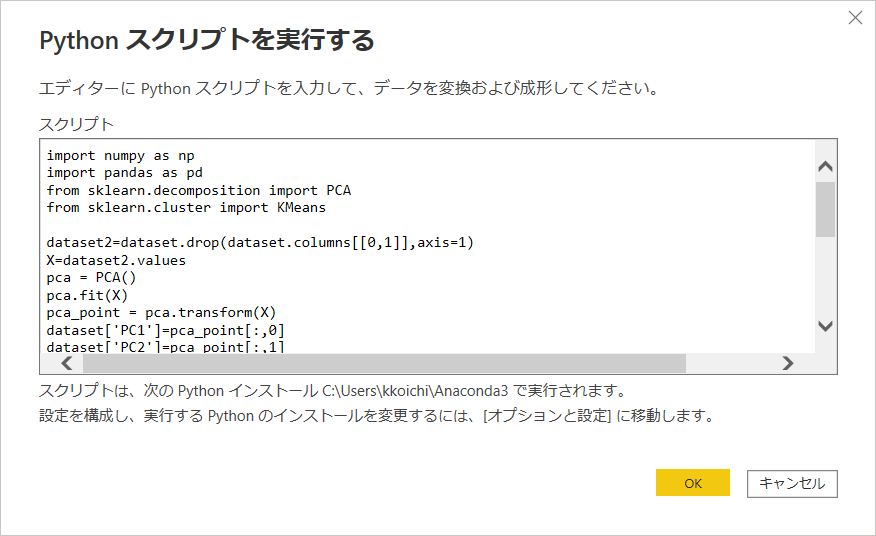
4. evrには各成分ごとの寄与率がセットされており、値を確認します。(各成分の影響力を示しています)
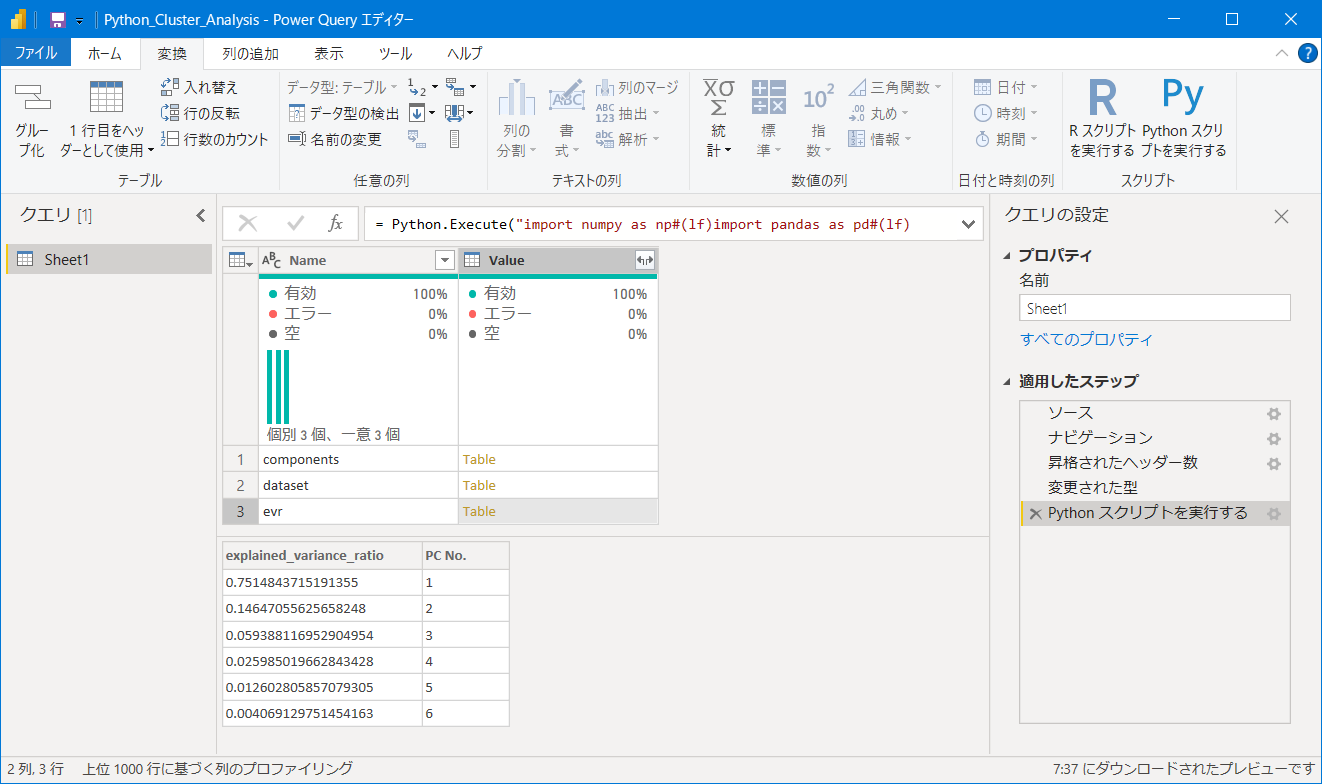
5. datasetのTableをクリックし、Pythonで解析したデータを読み込みます。(主成分1、主成分2、クラスタ番号の列が追加されています。)
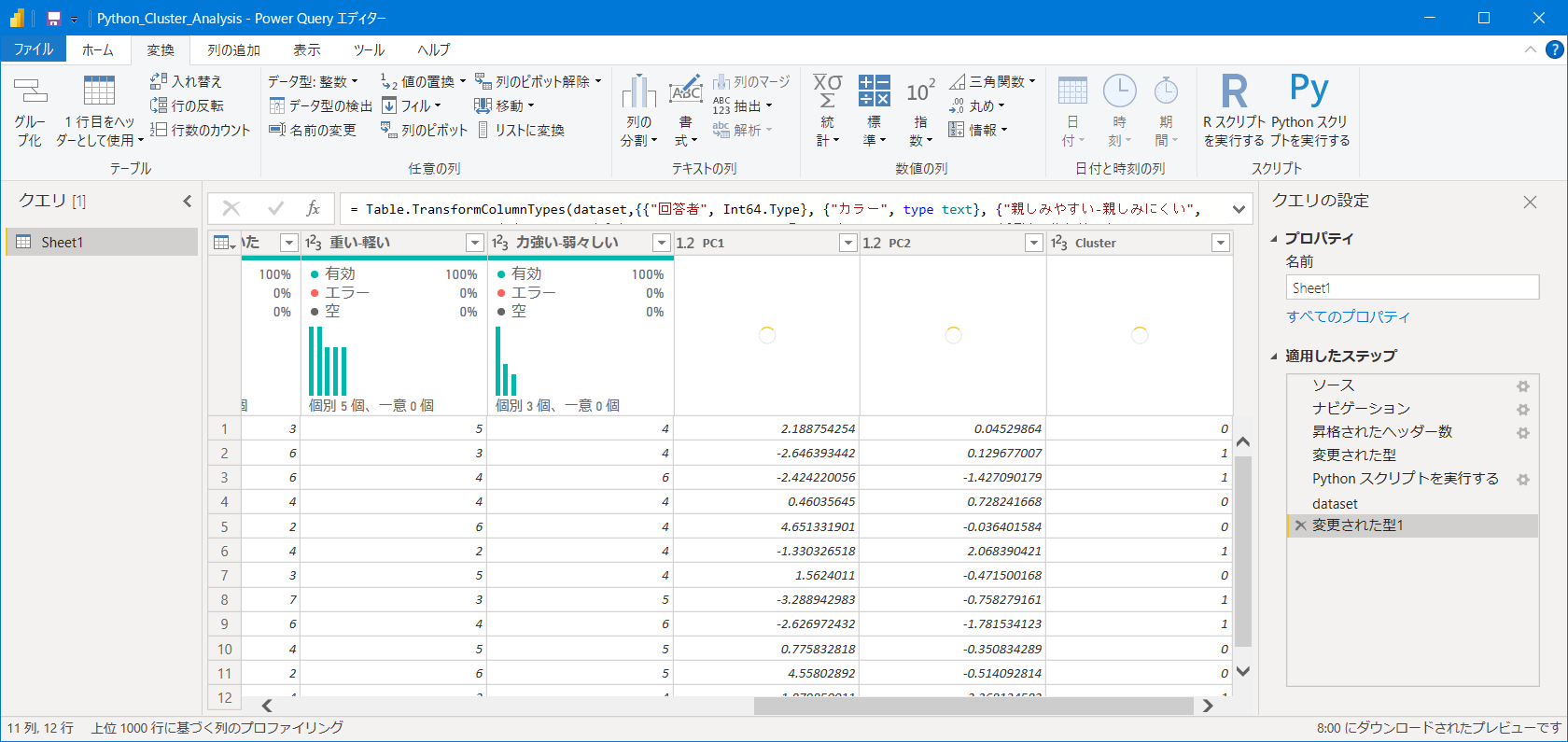
6. ホーム>閉じて適用をクリック
レポートの作成
- 散布図のアイコンをクリックし、ダッシュボードに置きます。
- X軸にPC1の平均、Y軸にPC2の平均を設定します。
- 凡例をCluster、詳細をカラーに設定します。
- 視覚化>書式>カテゴリを有効に設定し、データラベルを表示します。
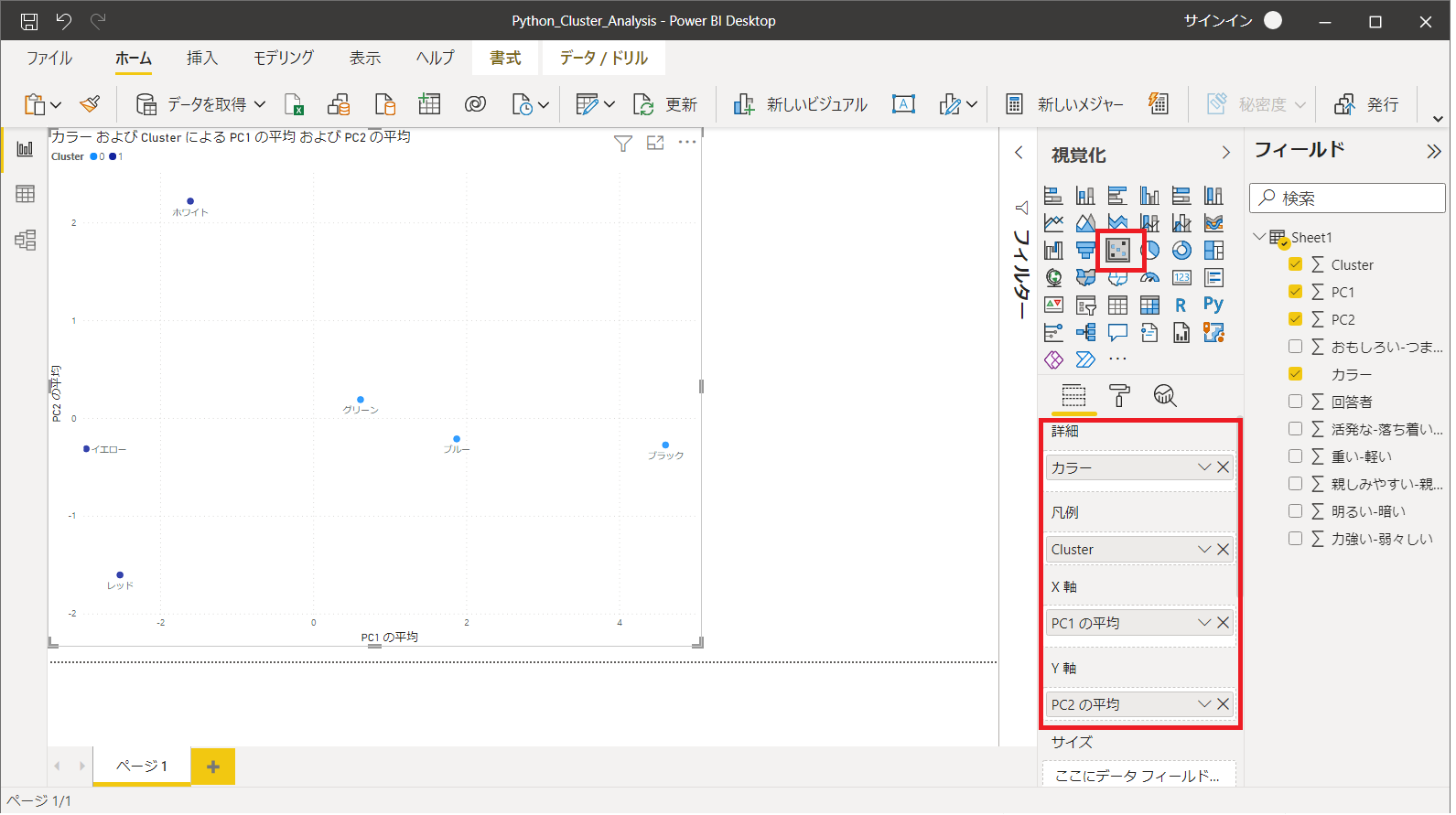
分析結果
クラスタ数を2に設定した場合、このようにグルーピングされました。
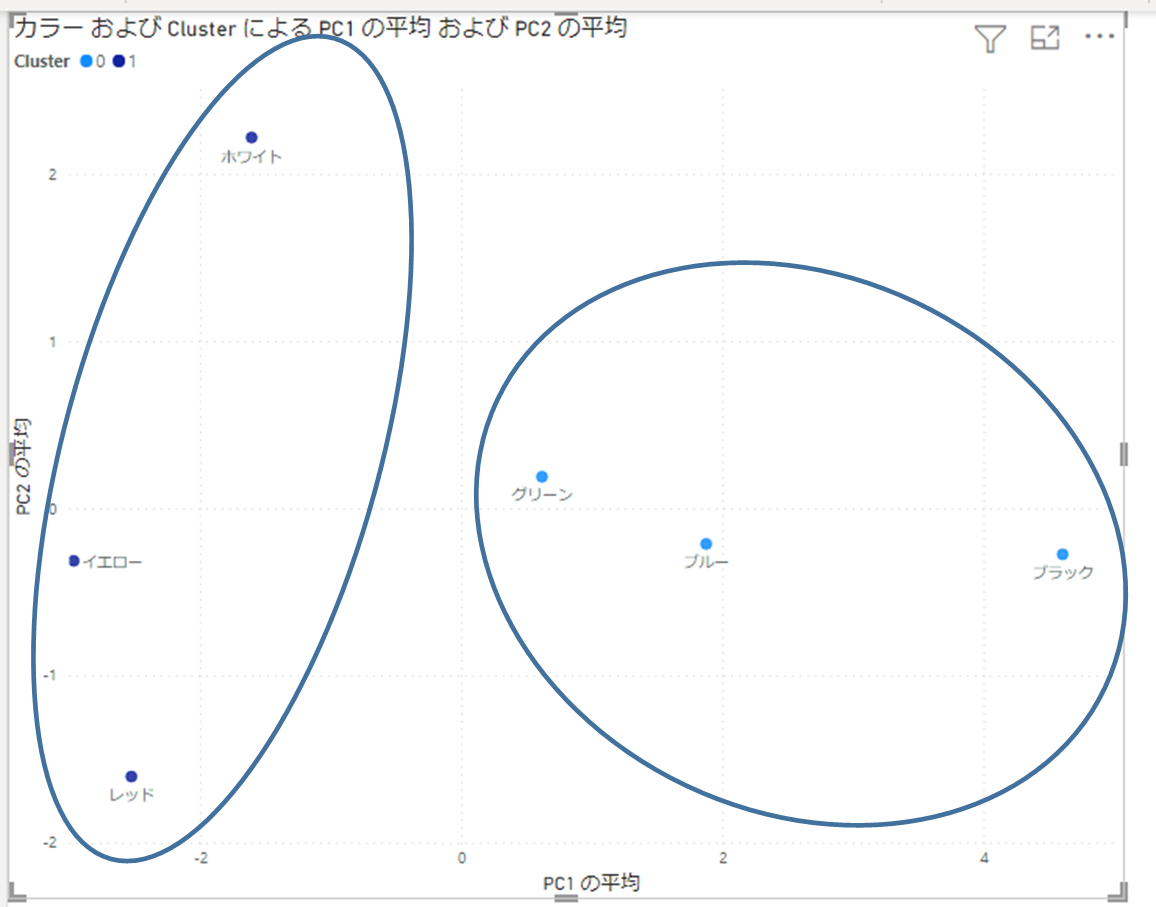
要約されたX軸(第1主成分)、Y軸(第2主成分)は、分析結果をもとに何らかの意味づけをすると分かりやすくなります。
まとめ
Power BIとPythonを用いて、アンケートデータから主成分分析とクラスタ分析を行ってみました。