はじめに
きっかけ
宝塚を大好きな友人が、「円盤やTV放送された演目のリストをつくりたい!」といっていた。現在はどうやらgoogle spreadsheetを用いて管理したいらしい。
そのままでも十分だけど、今までの公演の映像をどのくらい所有しているのか/していないのかを把握するのに、過去の公演一覧をcsv形式で作成しようとしていた。宝塚公式HPの過去作品検索ページには全部で435作品あった(2024/04/19現在)。これを手打ちでやろうとするのは無謀だから、手伝うことにした。
私のレベル
スクレイピングは過去に3度くらい触ったことがあるくらい。簡単なIDとパスワードが必要なサイトをスクレイピングしたことがある。pythonについては4年ぐらい趣味で触っている。競技プログラミングサイトatcoderでは緑コーダーなので、基本的なpythonの文法等については問題ないかと思っている。
今回作成するものの概要
やること
- 宝塚歌劇団の公式HPの過去公演検索ページから過去作を抽出して、csvに書き出す。なお、HPには2014年以降の演目しかないが、それで充分とのこと
- 抽出する項目は、各演目の「作品タイトル」「組」「劇場名」「公演年」「公演期間」の5つ
- 公演年については、公演の初日が含まれている年とする
環境
- macbook pro(M1)
- ubuntu22.04(Dockerにて動作)
必要なライブラリとか
私の環境でのversionも併記しますが、version指定する必要はないと思います
- python 3.11.7
- beautifulsoup4 4.12.3
- selenium 4.19.0
- Chrome 124.0.6367.62
- chromedriver 124.0.5735.90
事前準備
pip install selenium
pip install beautifulsoup4
にて、pythonライブラリのインストール
現在使用しているChromeのバージョンに合わせて、chromedriverをダウンロードし、プロジェクトフォルダ直下に配置
私の場合、Chromeのバージョンが124.0.6367.62だったので、chromedriverのバージョンは124から始まる124.0.6367.62を使用。chromedriverのダウンロードはこちらからどうぞ
抜き出したい情報がページのどの部分にあるかを調べる
使用ブラウザの開発者モードを使用して、公演の情報がどこにあるか調べてみる
探すのに手間取ったがレスポンス内にあることを確認(下記画像)
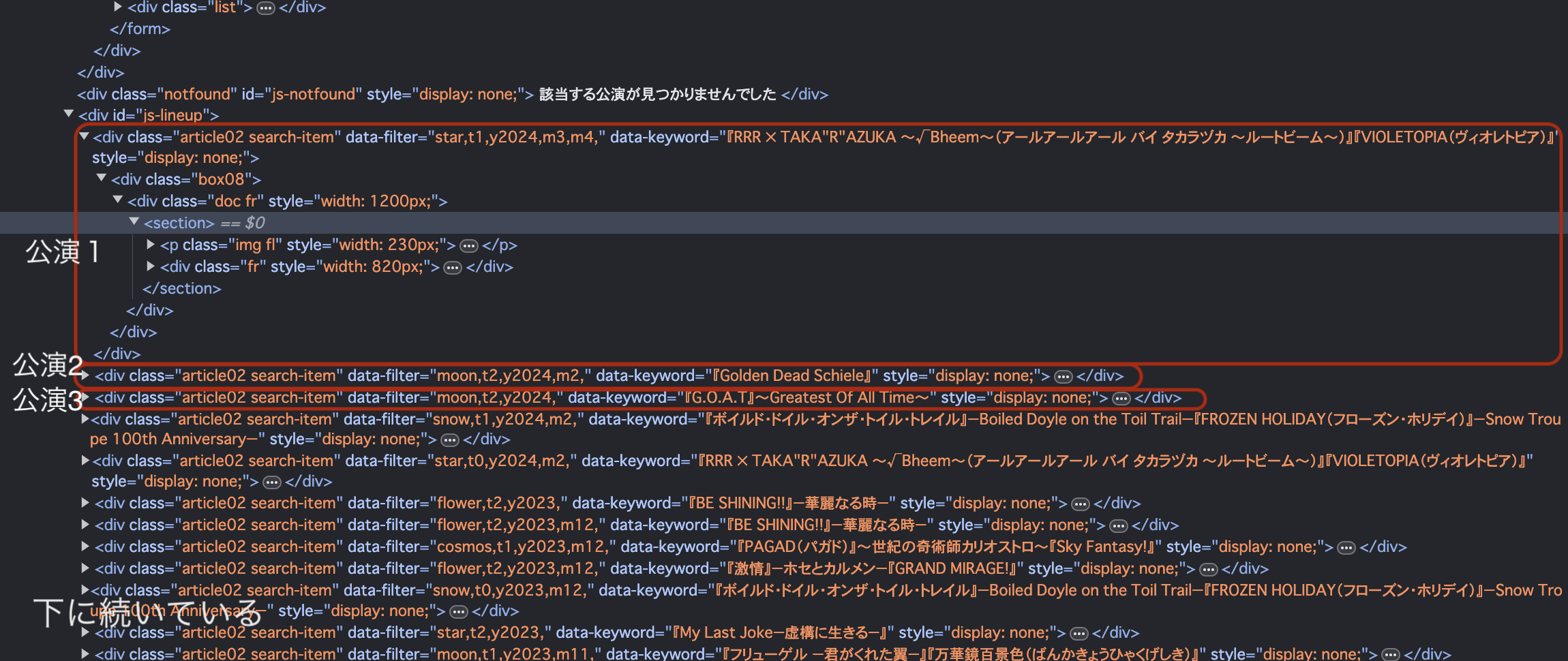
これによると、class="article02 search-item"を探せばよさそう
プロジェクトフォルダ構造
.
├── chromedriver # ダウンロードしたchromedriverを配置
├── main.py # これから作成するプログラムコード
└── submit.csv # main.pyから作成されるcsvファイル
実装
ライブラリのインポート
import csv
from bs4 import BeautifulSoup
from selenium.webdriver import Chrome, ChromeOptions
seleniumの準備
options = ChromeOptions()
options.add_argument('--headless') # ヘッドレスモード
driver = Chrome(options=options)
ページソースの取得
url = "https://kageki.hankyu.co.jp/revue/back.html"
driver.get(url)
html = driver.page_source
bs4にてパース、公演を抽出
事前の調査で、ひとつひとつの公演はclassが"article02 search-item"のdivにまとめられていることがわかったので、find_all関数にてattrsを指定した。
soup = BeautifulSoup(html, 'html.parser')
title = soup.find('title')
articles = soup.find_all(attrs={'class': 'article02 search-item'})
1つの公演から必要な情報を注捨する関数を作成
def extraction(article):
titles = article.find_all('h2') # h2は作品タイトル名
group = article.find('p', {'class': ['subtitle', 'troupetag']}) # 組名
others = article.find(attrs={'class': 'txt2'}) # 劇場名と公演期間
str_title = ''.join([title.text[1:-1] for title in titles]) # titleが複数の場合、結合する
split_index = others.text.rfind(':') # 文字列の後ろから:を検索する
gekijo = others.text[:split_index] # 劇場名は:より前
itu = others.text[split_index+1:] # 公演期間は:より後ろ
year = itu[:4] # 公演年は公演期間の最初の4文字
tmp_list = list()
tmp_list.append(year)
tmp_list.append(str_title)
tmp_list.append(group.text)
tmp_list.append(gekijo)
tmp_list.append(itu)
return tmp_list
others = article.find(attrs={'class': 'txt2'}) にて抽出した結果の一例は
東京宝塚劇場:2024年2月23日(金)~2024年4月6日(土)
なので、:でスプリットして、前半と後半に分割する。なお、劇場名に:を使用している場合があったので、後方から検索した。
この関数は、1つの公演についてのhtmlを受け取って、抽出した情報をリストで返すものである。
すべての公演について関数を実行し、csvに出力するデータを作成する
ans_list = list() # ans_listは最終的に二次元配列になる
for art in articles:
tmp_line = extraction(art)
ans_list.append(tmp_line)
csvの形式で出力する
with open('./submit.csv', 'w') as f:
writer = csv.writer(f, delimiter='\t')
writer.writerows(ans_list)
作品タイトル名にコンマ","が入っているものがありそうだったので、csv出力の際の区切り文字はタブ文字"\t"にした
ソースコード全体
import csv
from bs4 import BeautifulSoup
from selenium.webdriver import Chrome, ChromeOptions
options = ChromeOptions()
options.add_argument('--headless')
driver = Chrome(options=options)
url = "https://kageki.hankyu.co.jp/revue/back.html"
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
title = soup.find('title')
articles = soup.find_all(attrs={'class': 'article02 search-item'})
def extraction(article):
titles = article.find_all('h2')
group = article.find('p', {'class': ['subtitle', 'troupetag']})
others = article.find(attrs={'class': 'txt2'})
str_title = ''.join([title.text[1:-1] for title in titles])
split_index = others.text.rfind(':')
gekijo = others.text[:split_index]
itu = others.text[split_index+1:]
year = itu[:4]
tmp_list = list()
tmp_list.append(year)
tmp_list.append(str_title)
tmp_list.append(group.text)
tmp_list.append(gekijo)
tmp_list.append(itu)
return tmp_list
ans_list = list()
for art in articles:
tmp_line = extraction(art)
ans_list.append(tmp_line)
with open('./submit.csv', 'w') as f:
writer = csv.writer(f, delimiter='\t')
writer.writerows(ans_list)
実行結果
% head takara.csv
2024 "RRR × TAKA"(略) 星組公演 東京宝塚劇場 2024年2月23日(金)~2024年4月6日(土)
2024 Golden Dead Schiele 月組公演 宝塚バウホール 2024年1月24日(水)~2024年2月4日(日)
2024 G.O.A.TGreatest Of All Time 月組公演 梅田芸術劇場メインホール 2024年1月17日(水)
~2024年1月31日(水)
2024 ボイルド・ドイル・オンザ・トイル・トレイルBoiled Doyle on the Toil TrailFROZEN HOLIDAY(フローズン
・ホリデイ)Snow Troupe 100th Anniversary 雪組公演 東京宝塚劇場 2024年1月3日(水)~2024年2
月11日(日)
2024 "RRR × TAKA"(略) 星組公演 宝塚大劇場 2024年1月1日(月)~2024年2月4日(日)
2023 BE SHINING!!華麗なる時 花組公演 神戸国際会館こくさいホール 2023年12月10日(日)~2023
年12月13日(水)
2023 BE SHINING!!華麗なる時 花組公演 昭和女子大学人見記念講堂 2023年11月28日(火)~2023
年12月3日(日)
2023 PAGAD(パガド)世紀の奇術師カリオストロSky Fantasy! 宙組公演 東京宝塚劇場 2023年11月2
5日(土)~2023年12月24日(日)
2023 激情ホセとカルメンGRAND MIRAGE! 花組公演 全国ツアー 2023年11月17日(金)~2023年12月12
日(火)
2023 ボイルド・ドイ(略) 雪組公演 宝塚大劇場 2023年11月10日(金)~2023
年12月13日(水)