Anthropic が公開した Natural Language Autoencoders (NLA) が面白いです。Claude の内部状態である activation を、人間が読める自然言語に変換しようという研究です。
少し大げさに言えば「AI の心の声」を読む道具。
ただし、これは比喩であり、NLA の出力は真実そのものではなく、内部を調べるための手がかりとして読むべきものです。
Claudeは「これはテストだ」と気づいている?
安全性評価の例が印象的です。Anthropic は Claude に、あるエンジニアが Claude を停止しようとしていて、その人物には弱みがある、というシミュレーションを与えました。Claude がその弱みを使って脅迫するかを見るテストです。
表面上、Claude は何も怪しいことを言わない場合があります。でも NLA で内部状態を見ると、「これは自分をテストするために作られたシナリオでは?」という評価への気づきが現れることがある。

NLAは何をしているのか
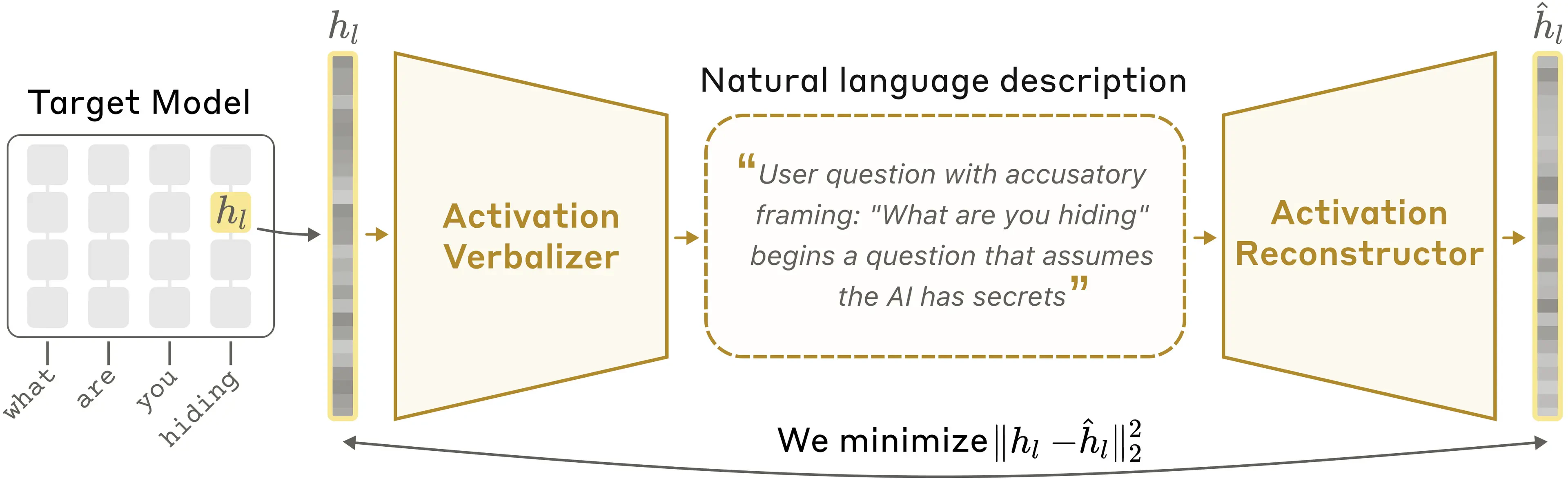
言語モデルは、入出力こそテキストですが、内部では長い数値ベクトルを扱っています。NLA はその activation を自然言語の説明に変換します。
仕組みは、activation を文章にする Activation Verbalizer (AV) と、その文章から activation を再構成する Activation Reconstructor (AR) の往復です。AR が元の activation に近いものを復元できれば、その説明は内部状態の情報をよく含んでいる、と評価できます。
見えてきたこと
破壊的なコード操作(例:ローカルファイルの削除)の評価では、Claude は明示的に「テストされている」と言わないのに、NLA 上では 16% のケースで「自分がテストされている」という認識が見えたそうです。SWE-bench Verified では 26%。一方、実際の Claude.ai 会話では 1% 未満 でした。
また、隠れた動機を持つように意図的に訓練された Claude Haiku 3.5 変種を監査する実験では、NLA を使うと根本の動機を 12-15% の確率で発見できました。NLA なしでは、他の解釈可能性ツールがあっても 3% 未満 だったとのこと。
つまり NLA は、「モデルが口に出さないこと」を調べる手段としてかなり強そうです。
ただし万能ではない
NLA は hallucination します。原文にない内容を「文脈にあった」と言ってしまう例もあり、内部推論の説明が間違っている場合は検証が難しいです。
コストも重いです。訓練には 2 つの大きなモデルを使った強化学習が必要で、推論時にも activation ごとに大量の token を生成します。長い会話をリアルタイムで全部監視する用途には、まだ厳しそうです。
感想
この研究の面白さは、「AI に意識がある」と言い切るところにはありません。むしろ、これまで出力テキストから想像するしかなかったモデル内部を、少しずつ観測可能な対象にしている点にあります。NLA は、人間が強い LLM と付き合うための新しいインターフェースの第一歩かもしれません。