概要
深層強化学習による迷路探索 その1 の続きとなります。
準備
迷路探索では「パラメータ $\theta_0$」「スタート地点」「ゴール地点」の3つの情報から、移動経路(=エージェントの行動リスト)を求めます。ここでのパラメータとは、迷路内のある地点(=状態 $s_i$:State)においてエージェントがある方向への移動(=行動 $a_j$:Action)を「選択できるかどうか」を表したものです。目的は、少ない手数でゴールできる経路を求めることです。
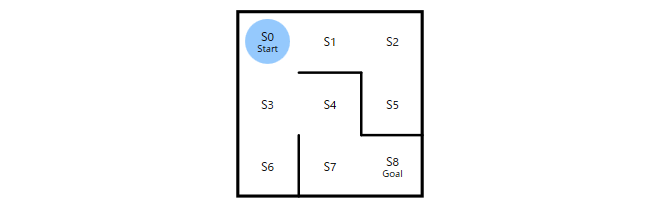
例えば、上記のようなS0をスタート、S8をゴールとする 3x3の迷路 では、パラメータ $\theta_0$ は、次のような行列として表現することができます。
\theta_{0}=\left( \begin{array}{cc}
0 & 1 & 1 & 0 \\
0 & 1 & 0 & 1 \\
0 & 0 & 1 & 1 \\
1 & 1 & 1 & 0 \\
0 & 0 & 1 & 1 \\
1 & 0 & 0 & 0 \\
1 & 0 & 1 & 1 \\
1 & 1 & 0 & 0 \\
0 & 0 & 0 & 1 \\
\end{array} \right)
行が状態 $s_i$、列が行動 $a_j$(上・右・下・左)に対応しており、値が1であれば「状態 $s_i$」で「行動 $a_j$」が選択可能、値が0であれば(その方向に壁があるため)選択不可能であること表しています。この $\theta_0$ は、ある状態におけるエージェントの行動選択可否をあらわしていますが、迷路の構造を表していると考えることもできます。
ランダム探索
ランダム探索では、$\theta_0$ から次式のように行動選択確率 $\pi_{s_{i},a_{j}}$ を計算して、それを方策 $\pi_0$(ポリシー)として探索を行ないます。
\pi_{s_{i},a_{j}}=\frac{\theta_{s_{i},a_{j}}}{\theta_{s_{i},a_{0}}+\theta_{s_{i},a_{1}}+\theta_{s_{i},a_{2}}+\theta_{s_{i},a_{3}}}
例えば、状態 $s_{0}$(=スタート地点)において行動 $a_{1}$(右方向に移動)を選択する確率 $\pi_{s_{0},a_{1}}$ は、$0.5$ となります。
\pi_{s_{0},a_{1}}=\frac{\theta_{s_{0},a_{1}}}{\theta_{s_{0},a_{0}}+\theta_{s_{0},a_{1}}+\theta_{s_{0},a_{2}}+\theta_{s_{0},a_{3}}}=\frac{1}{0+1+1+0}=\frac{1}{2}=0.5
これにより、ある状態において、移動可能な方向が2つであればそれぞれを50%の確率でランダムに選択、3つであればそれぞれを33.3%の確率でランダムに選択しながら迷路を探索するようになります。
先ほどの $\theta_0$ は、ランダム探索では次のような方策 $\pi_0$ に変換されます。
\pi_{0}=\left( \begin{array}{cc}
0 & 0.5 & 0.5 & 0 \\
0 & 0.5 & 0 & 0.5 \\
0 & 0 & 0.5 & 0.5 \\
0.33 & 0.33 & 0.33 & 0 \\
0 & 0 & 0.5 & 0.5 \\
1 & 0 & 0 & 0 \\
0.33 & 0 & 0.33 & 0.33 \\
0.5 & 0.5 & 0 & 0 \\
0 & 0 & 0 & 1 \\
\end{array} \right)
方策勾配法
方策勾配法では、1回目はランダムに迷路探索を行ないます。そして、その探索の行動履歴から、次式のようにパラメータ $\theta$ を更新し、それに基づく新たな方策 $\pi$ により2回目の探索をします。そして、その2回目の探索の結果から再び $\theta$ を更新して・・・を繰り返すことで最短経路でゴールに向かう方策(=強化学習された方策)を求めていきます。
\theta_{s_i,a_j} := \theta_{s_i,a_j}+\eta\cdot \Delta \theta_{s_i,a_j}
\begin{align}
\Delta\theta_{s_i,a_j} &:= \frac{N_1-N_0 \cdot \pi_{s_i,a_j}}{T}\\
& = \frac{N_1-(N_1 + N_2) \cdot \pi_{s_i,a_j}}{T}\\
& = \frac{N_1( 1-\pi_{s_i,a_j}) - N_2\cdot\pi_{s_i,a_j}}{T}
\end{align}
ここで、$T$、$N_{x}$ は探索結果(行動履歴)から得られる情報で、$T$ はステップ数(=スタートからゴールに到達するまでの移動回数)、$N_1$ は「(行動履歴のなかで)状態 $s_{i}$ のときに行動 $a_{j}$ をとった回数」、$N_2$ は「状態 $s_{i}$ のときに $a_{j}$ 以外の行動をとった回数」、$N_0$ は「状態 $s_{i}$ で $a_{j}$ を含め何らかの行動をとった回数(つまり、行動履歴のなかで状態 $s_{i}$ が出現した回数)」です。当然ながら $N_{0}=N_{1}+N_{2}$ という関係が成立します。
また、$\pi_{s_i,a_j}$ は、既に説明したように「状態 $s_{i}$ において行動 $a_{j}$ を選択する確率」であり、探索に用いた方策 $\pi$ から得ることができます。また、$\eta$ は、学習率といい、正の値で与えます。「その1 」で示した実装では $\eta=0.2$ としていました(大きすぎても、小さすぎても不都合な要調整な値となります)。
この更新式は、方策勾配定理ならびにREINFORCEアルゴリズム
というものから導出されるものらしいですが(数学的な導出はあきらめて)、ここでは更新式の持つ意味を定性的に考えていきたいと思います。
まず、$\Delta\theta_{s_i,a_j}$ が大きいと、それは以降の探索に対してどのように影響するのか?を考えていきます。
$\Delta\theta_{s_i,a_j}$ が大きいと方策決定のためのパラメータ $\theta_{s_i,a_j}$ が大きくなり、その $\theta_{s_i,a_j}$ が大きくなると $\pi_{s_i,a_j}$ が大きくなります。$\pi_{s_i,a_j}$ が大きいということは、探索時に状態 $s_i$ で 行動 $a_j$ を選択する確率が高くなるということです。つまり、$\Delta\theta_{s_i,a_j}$ が大きいと「(その大きさに応じて)以降の探索で、状態 $s_i$ で行動 $a_j$ が選択される可能性が高まる(=状態 $s_i$ で行動 $a_j$ を選択するように(少し)学習する)」ということになります。
では、どのようなときに、$\Delta\theta_{a_i,s_j}$ が大きな値となるのか?を考えていきます。
$\Delta\theta_{a_i,s_j}$に影響してくる要素は多数あります。
\Delta\theta_{s_i,a_j} = \frac{N_1( 1-\pi_{s_i,a_j}) - N_2\cdot\pi_{s_i,a_j}}{T}
まず、$N_{1}$(=行動履歴のなかで状態 $s_{i}$ で行動 $a_{j}$ をした回数)が多かったのならば$\Delta\theta_{a_i,s_j}$ は大きくなります。「迷路をゴールできた」という望ましい結果をもたらす一連の行動のなかに「状態 $s_{i}$ で行動 $a_{j}$ をした」が含まれていたのなら、それは「良い行動だった」と見なして学習しましょう(以降の探索では、その行動が選択されやすくなるようにしましょう)、ということです。例えば、先に示した 3x3 迷路において、ゴールに到達するためには「$s_{0}$ で行動 $a_{2}$(=スタート地点S0で下方向に移動)」「$s_{7}$ で行動 $a_{1}$(=ゴール手前のS7で右方向に移動)」という選択が絶対に必要であり、また、ゴールしたときの行動履歴にはそれが必ず含まれるので、そのことを学習しましょう、ということです。
ただし、この考え方だけで単純に $\Delta\theta_{a_i,s_j}:=N_1$ のように $\Delta\theta_{a_i,s_j}$ を決めると問題があります。例えば、S0 → S1 → S0 → S1 → S0 → S1 → S0 → S1 → S0 → S3 → S4 → S7 → S8 のように、スタート地点でウロウロしてからゴールしたときに「$s_{0}$ で行動 $a_{1}$(=スタート地点S0で右方向に移動)が多数おこなわれているので、それは良い選択だ」と学習してしまうという問題です。そこで、ステップ数 $T$(スタートからゴールまでに要した移動の合計数)で除するという要素が更新式に入ってきます。つまり、ステップ数が多いとき(無駄な行動があるとき)に、そこで多数の「$s_{i}$ で行動 $a_{j}$ をとった」が含まれていたとしても、そこは控えめに学習されるようになります。逆に言えば、少ないステップ数でゴールできたときに「$s_{i}$ で行動 $a_{j}$ をとった」が含まれていたら強めに学習する、ということを意味しています。
では、 上記の考え方を反映して $\Delta\theta_{s_i,a_j}:=N_1/T$ のように $\Delta\theta_{s_i,a_j}$ を決めればよいかというと、それでもまだ問題があります。その問題をあきらかにするために、極めて単純な迷路を考えます。状態はスタートS0 とゴールS1 のみです。状態$s_{0}$で選択可能な行動は $a_{0}$ か $a_{1}$ で、どちらを選択してもゴールに到達します。いま、なんらかのプロセスを経て、行動の選択確率(方策)が $\pi_{s_0,a_0}=0.3$、 $\pi_{s_0,a_1}=0.7$ になっていたとします。この方策を使って探索することを考えていきます。
探索のなかで、仮に $a_{0}$ を選択したとして $\Delta\theta_{s_i,a_j}:=N_1/T$ を計算すると、次のようになります。
\begin{align}
\Delta\theta_{s_0,a_0}&:=1/1=1\\
\Delta\theta_{s_0,a_1}&:=0/1=0
\end{align}
また、逆に $a_{1}$ を選択したとすれば、次のようになります。
\begin{align}
\Delta\theta_{s_0,a_0}&:=0/1=0\\
\Delta\theta_{s_0,a_1}&:=1/1=1
\end{align}
どちらの行動もステップ数1でゴールに到達するという同じ価値を持つ行動なので「$a_{0}$ を選択したときは $\Delta\theta_{s_0,a_0}=1$」「$a_{1}$ を選択したときも $\Delta\theta_{s_0,a_1}=1$」ということで問題はないように思えます。ただ、各行動の選択確率 $\pi_{s_i,a_j}$ は $\pi_{s_0,a_0}=0.3$、 $\pi_{s_0,a_1}=0.7$ であり、探索のなかで各行動が選択される確率も考慮して価値の期待値を考えると $E(\Delta\theta_{s_0,a_0})=1\times30%=0.3$、$E(\Delta\theta_{s_0,a_1})=1\times70%=0.7$ となります。同じ価値を持つ行動なのに $\Delta\theta$(期待値)が違うのが気になります。そこで、更新式を $\Delta\theta_{s_i,a_j}=N_1( 1-\pi_{s_i,a_j})/T$ のようにします。すると、次のように期待値で考えたときに両者の行動価値が同じと評価できるようになります。
\begin{align}
E(\Delta\theta_{s_0,a_0})&=0.7\times 30\%=2.1\\
E(\Delta\theta_{s_0,a_1})&=0.3\times 70\%=2.1\\
\end{align}
最後に、$\Delta\theta$ に含まれる「$-N_2\cdot\pi_{s_i,a_j}$」について考えていきます。先ほどと同じスタートとゴールしかない単純な迷路を考えていきます。この迷路では、行動 $a_0$ も行動 $a_1$ も価値は等しいので理想的な方策は $\pi_{s_0,a_0}=\pi_{s_0,a_1}=0.5$ に落ち着くべきできす。しかし、先の $\Delta\theta_{s_i,a_j}=N_1( 1-\pi_{s_i,a_j})/T$ という更新式では、$E(\Delta\theta_{s_0,a_0})=E(\Delta\theta_{s_0,a_1})=2.1$ となるので、ある時点における方策「$\pi_{s_0,a_0}=0.3$、 $\pi_{s_0,a_1}=0.7$」を、理想的方策「$\pi_{s_0,a_0}=\pi_{s_0,a_1}=0.5$」に修正していく力が働きません。そこで、更新式を次のようにします。
\Delta\theta_{s_i,a_j} := \frac{N_1( 1-\pi_{s_i,a_j}) - N_2\cdot\pi_{s_i,a_j}}{T}
探索なかで仮に $a_{0}$ を選択したとして上式により $\Delta\theta$ を計算すると次のようになります。
\begin{align}
\Delta\theta_{s_0,a_0}&:=\frac{1(1-0.3)-0\times0.7}{1}=0.7\\
\Delta\theta_{s_0,a_1}&:=\frac{0(1-0.7)-1\times0.3}{1}=-0.3
\end{align}
一方、$a_{1}$ を選択したとすると次のようになります。
\begin{align}
\Delta\theta_{s_0,a_0}&:=\frac{0(1-0.3)-1\times0.7}{1}=-0.7\\
\Delta\theta_{s_0,a_1}&:=\frac{1(1-0.7)-0\times0.3}{1}=0.3
\end{align}
これについても、期待値で考えていきます。$\Delta\theta_{s_0,a_0}$ の期待値は、30%の確率で行動 $a_{0}$ が選択、70%の確率で行動 $a_{1}$ が選択されるので、
\begin{align}
E(\Delta\theta_{s_0,a_0})&=( 0.7 \times 30\% )+ (-0.7\times 70\% ) = 2.1-0.49 = 1.61\\
\end{align}
また、$\Delta\theta_{s_0,a_1}$ の期待値は、
\begin{align}
E(\Delta\theta_{s_0,a_1})&=( -0.3 \times 30\% )+ (0.3\times 70\% ) = -0.
9+2.1 = 1.20 \\
\end{align}
となります。この結果、$E(\Delta\theta_{s_0,a_0}) > E(\Delta\theta_{s_0,a_1})$ となり、現状では $a_1$ の選択に偏っているものを「$\pi_{s_0,a_0}=\pi_{s_0,a_1}=0.5$」に収束させるような方向に力を働かせることができるようになります。
以上、更新式の意味を考えてみました。
方策勾配法における変換関数
方策勾配法においてパラメータ $\theta$ から方策 $\pi$ を求めるための変換関数について考えます。ランダム探索では、$\theta$ の単純な割合から次式により行動選択確率 $\pi_{s_{i},a_{j}}$ を求めました。
\pi_{s_{i},a_{j}}=\frac{\theta_{s_{i},a_{j}}}{\theta_{s_{i},a_{0}}+\theta_{s_{i},a_{1}}+\theta_{s_{i},a_{2}}+\theta_{s_{i},a_{3}}}
方策勾配法では、$\theta$ を $\Delta\theta$ により更新しますが、そのなかで $\theta$ がマイナスになることもあります。そのため、単純な割合ではなく、次のようなソフトマックス関数を利用して行動選択確率を求めます。
\begin{align}
\pi_{s_{i},a_{j}} &= \frac{\exp(\beta\cdot \theta_{s_{i},a_{j}})}{\exp(\beta\cdot \theta_{s_{i},a_{0}})+\exp(\beta\cdot \theta_{s_{i},a_{1}})+\exp(\beta\cdot \theta_{s_{i},a_{2}})+\exp(\beta\cdot \theta_{s_{i},a_{3}})}
\end{align}
$\exp(x)$ は、$x$ が負であっても、式全体としては非負となります。なお、$\beta$ は逆温度とよばれる係数になります。$\beta$ を小さくすると $\theta_{s_{i},a_{j}}$ の大きさに左右されずランダムに選択されるようになります($\beta=0$ であれば $\exp(\beta\cdot \theta_{s_{i},a_{j}})=\exp(0)=1$)。
参考資料
- 小川雄太郎 著「つくりながら学ぶ!深層強化学習」マイナビ出版
- 上記書籍のサポートリポジトリ@GitHub
- 大槻知史 著「最強囲碁AI アルファ碁 解体新書(増補改訂版)」翔泳社