概要
-「その1」のつづきとなります。Kaggleのタイタニック号のデータを使って、統計解析とデータの可視化をしていきます。
- 今回は、年齢の構成をヒストグラムによって把握していきます。また、生存/死亡と年齢の関係もみていきます。
準備
データを読み込みます。詳細については「その1」を参照してください。
from IPython.display import display
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
train = pd.read_csv('train.csv')
df = train
年齢に関する可視化
準備として、年齢に関する基本的な統計量と欠損値の数を求めます。describe() で平均や標準偏差などの基本統計量を一発で求めてくれます。また、isnull().sum() で欠損行の数を求めることができます。これは、isnull() により null値 のデータを True、それ以外 False に変換して、sum() によりその総和を求めることで行なっています( sum() の際、True は 1、False は 0 として計算に使われます)。
display(df['Age'].describe())
display(df['Age'].isnull().sum())
count 714.000000
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000
50% 28.000000
75% 38.000000
max 80.000000
Name: Age, dtype: float64
177
実行結果より、177名について年齢情報が欠けていることがわかりました。以降でヒストグラムなどを描く際に邪魔になるので、年齢について欠損がある行は削除しておきます。任意の列(たとえば Age)に null値 がある行を削除するためには dropna(subset=['Age']) を使用します。
df = df.dropna(subset=['Age'])
display(df['Age'].isnull().sum())
ここでの display(df['Age'].isnull().sum()) の結果は 0 となります(年齢の欠損値を含む行は存在しない)。なお、describe() は、欠損値を除外して統計量を計算するので、先に実行した結果と、削除後に実行した結果は変わりません。
つづいて、年齢情報が存在する全員を対象にヒストグラムを作成していきます。グラフのなかで日本語を使いたいので、IPAexフォントのサイトから「ipaexg.ttf(IPAexゴシック)」をダウンロードして、Jupyter にアップロードしておきます(作業中の xxxx.ipynb と 同じフォルダに ipaexg.ttf がアップされている想定とします)。なお、IPAexゴシックの最新版は Ver.004.01 なのですが、私の環境では日本語表示がうまくいかずリンク先の Ver.002.01 を使っています。
from matplotlib.font_manager import FontProperties
fp= FontProperties(fname='ipaexg.ttf', size=12);
df['Age'].plot.hist()
plt.ylabel('人数', fontproperties=fp)
plt.show()
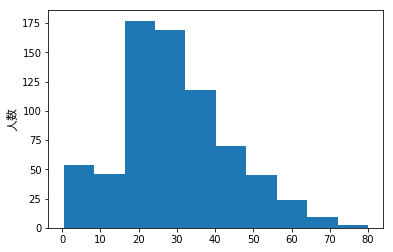
hist() に対して引数を指定しなければ、階級の幅、ビンの数は適当に決めてくれます。上記の実行結果ではビンの数は10になっています。引数を与えれば任意のビン数でヒストグラムを描いてくれます。
例えば、df['Age'].plot.hist(bins=8) とすると、次のようになります。

ビン数を変えると、ヒストグラムの形状がガラリと変化しました。こういったことは結構あるので、ヒストグラムの形状から分布を推定する場合などには注意が必要です。
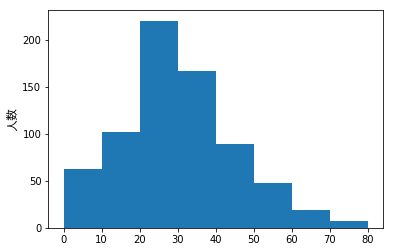
ところで、拡大表示しているように左端が気持ち悪いです。これは、最小値が 0.42 であるためです。ひったりと 0 からはじめるためには、df['Age'].plot.hist(bins=8, range=(0, 80)) のようにします。この結果、次のようなきれいなヒストグラムになります。
男女の年齢分布の違いを可視化
男女で年齢分布にどのような違いがあるのかを見ていきます。df[df['Sex']=='male']
により、男性だけのデータを取得できます。これらを利用して、次のようにすることで男女別の年齢分布をひとつのヒストグラムに表示することができます。
male = df[df['Sex']=='male']
female = df[df['Sex']=='female']
male ['Age'].plot.hist(bins=8, range=(0, 80), color='b', alpha = 0.5)
female['Age'].plot.hist(bins=8, range=(0, 80), color='r',alpha = 0.5)
plt.ylabel('人数', fontproperties=fp)
plt.show()
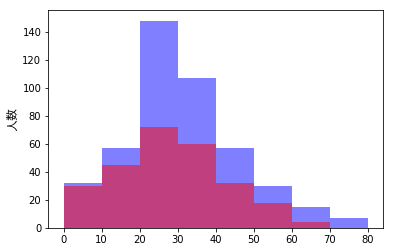
男女で重なる部分が隠れないように、alpha = 0.5 で透明度50%を指定しています。これでも見ずらい場合は、次のようにすることで重ねずに描くことができます。また、legend() により凡例をつけることができます。
male = df[df['Sex']=='male' ]
female = df[df['Sex']=='female']
d = [ male['Age'], female['Age'] ]
plt.hist(d, bins=8, range=(0, 80), alpha = 0.5, color=['b','r'])
plt.ylabel('人数', fontproperties=fp)
plt.legend(['男性','女性'], prop=fp)
plt.show()
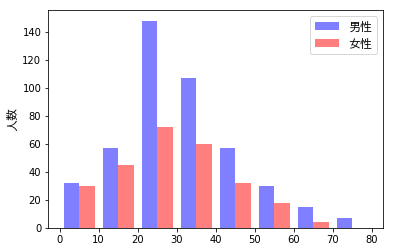
さきほどよりも、すっきりと表示することができました。
いずれの年代においても「男性数>女性数」であり、特に20~30歳の範囲では顕著になっていることが読み取れます。また、0~20歳の範囲では、男女の人数差はほとんどないことも読み取れます。
生存/死亡と年齢の関係を可視化
各年齢範囲における生存/死亡の割合を可視化していきたいと思います。ここでは、コードよりも先に結果を示したいと思います。各年齢範囲の生存/死亡の度数を、次の4つの異なるタイプのグラフで示します。
- 同じグラフ内に「左右に並べて」示したもの
- 同じグラフ内に「積み重ねて」示したもの(死亡を下段、生存を上段)
- 同じグラフ内に「積み重ねて」示したもの(生存を下段、死亡を上段)
- 左右に並べた2つのグラフに、それぞれ示したもの
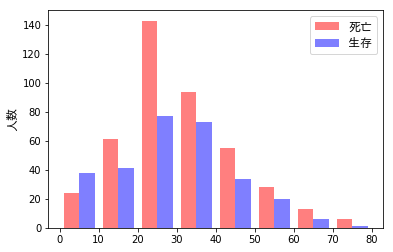
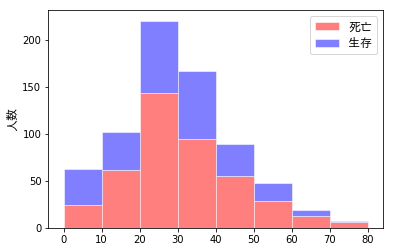
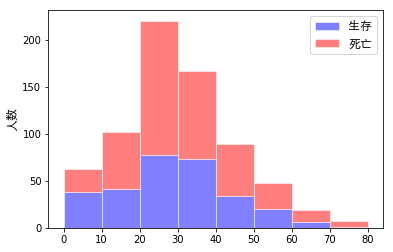
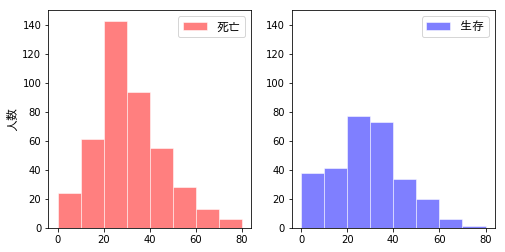
これらは、すべて同じデータから生成したものですが、どれだけ情報が読み取りやすいか・・・は、ずいぶん違ってきます。さらに、目の錯覚も手伝って、色々な誤解も生まれます。例えば、次の図において右側をみると、20-30歳において「生存者(青)の2倍以上の死亡者(赤)がいる」ように(私には)見えますが、、、左側を見てもらえれば分かるように、実際には「2倍」には至っていません。
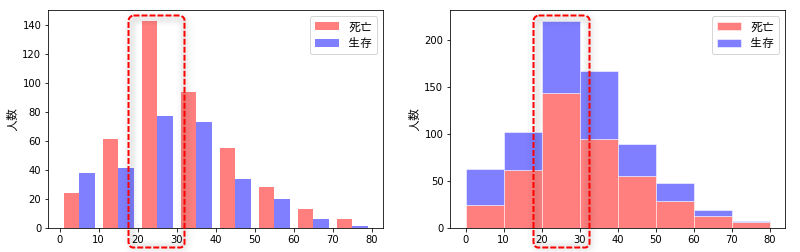
その他、次のようなことが読み取れます。
- 0~10歳では「生存者>死亡者」であるが、その他の年代では「生存者>死亡者」となっている。子どもを優先的に避難させた?
- 特に20代において、死亡者の割合が高く、絶対値としても多い。
- 60歳以上では、生存者の2倍以上の死亡者がでている。体力的に非難が厳しかった?
以下、各グラフを描画するためのコードとなります。
df0= df[df['Survived']==0]
df1= df[df['Survived']==1]
# 1
d = [ df0['Age'], df1['Age'] ]
plt.hist(d, bins=8, range=(0, 80), alpha = 0.5, color=['r','b'])
plt.ylabel('人数', fontproperties=fp)
plt.legend(['死亡','生存'], prop=fp)
plt.ylim(0,150)
plt.show()
# 2
plt.hist(d, bins=8, range=(0, 80), alpha = 0.5, color=['r','b'], ec='w' ,stacked=True)
plt.ylabel('人数', fontproperties=fp)
plt.legend(['死亡','生存'], prop=fp)
plt.show()
# 3
d = [ df1['Age'], df0['Age'] ]
plt.hist(d, bins=8, range=(0, 80), alpha = 0.5, color=['b','r'], ec='w' ,stacked=True)
plt.ylabel('人数', fontproperties=fp)
plt.legend(['生存','死亡'], prop=fp)
plt.show()
# 4
fig=plt.figure(figsize=(8, 4));
ax0 = fig.add_subplot(1,2,1);
ax0.hist(df0['Age'], bins=8, range=(0, 80), color='r', ec='w', alpha = 0.5)
ax0.set_ylim(0,150)
ax0.set_ylabel('人数', fontproperties=fp)
ax0.legend(['死亡'], prop=fp)
ax1 = fig.add_subplot(1,2,2);
ax1.hist(df1['Age'], bins=8, range=(0, 80), color='b', ec='w', alpha = 0.5)
ax1.set_ylim(0,150)
ax1.legend(['生存'], prop=fp)
plt.show()
補足:積み上げ順と凡例順を揃える
stacked=True を指定して積み上げ形式にしたとき、グラフの要素が「上段:生存、下段:死亡」なのに、凡例では「上段:死亡、下段:生存」と逆になってしまいます。
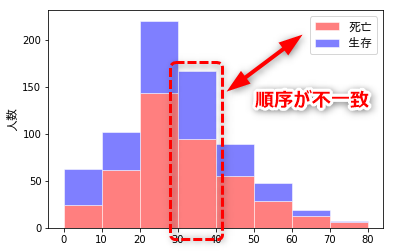
これは、次のように解決できました。
df0= df[df['Survived']==0]
df1= df[df['Survived']==1]
d = [ df0['Age'], df1['Age'] ]
fig = plt.figure()
ax0 = fig.add_subplot(1,1,1)
ax0.hist(d, bins=8, range=(0, 80), alpha = 0.5,
color=['r','b'], ec='w' ,stacked=True, label=['死亡','生存'])
ax0.set_ylabel('人数', fontproperties=fp)
handles, labels = ax0.get_legend_handles_labels()
ax0.legend(handles[::-1], labels[::-1], prop=fp)
plt.show()
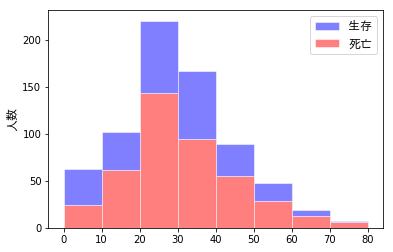
コードは少々複雑になりますが、こちらのほうが分かりやすいですね。
「その3」につづきます・・・