はじめに
前回の記事で少ない画像データを平行移動や回転などを行い増やす手段について記載しました。今回はその増やしたお酒の画像データをCNNに学習させ、ディープラーニングでどこまで正確に判断できるかについて試してみました。
お酒画像を学習させる
まずは、以下の8種類のお酒画像を各10枚ずつ準備し、前回の記事の方法を使ってデータ拡張してCNNで学習させてみました。
lagavulin
bowmore
caolila
kilchoman
bunnahabhain
bruichladdich
ardbeg
laphroaig
その結果は以下の通りとなりました。
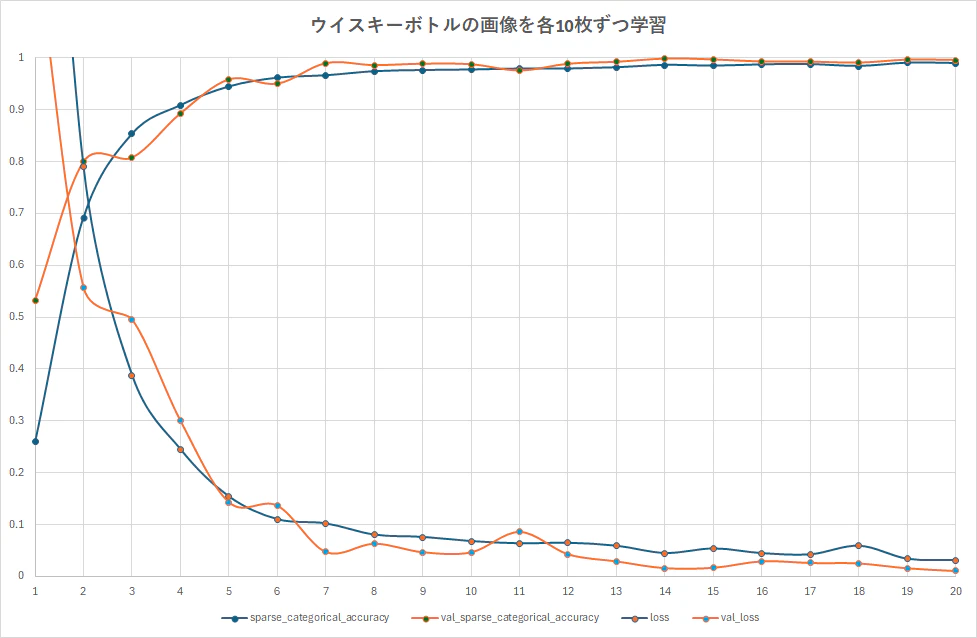
訓練データの学習が増えるに従い正解率も増加しており、学習が順調に進んでいるようです。
ここで作成されたモデルを使って、10枚の新しいお酒画像を正しく判別できるかについて試してみました。結果は以下の通りでした。
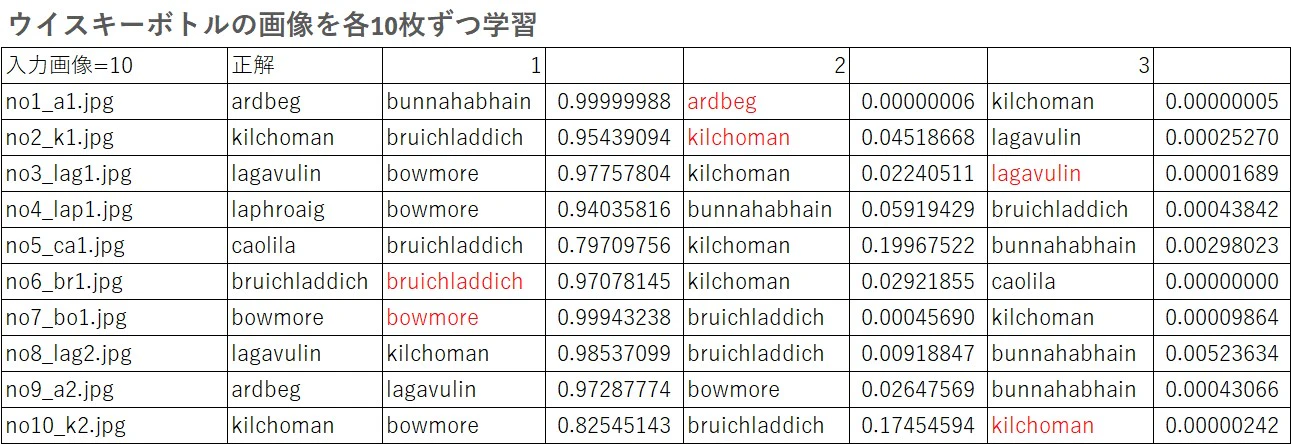
正しく判別できたのは、10枚中、no6_br1.jpgとno7_bo1.jpgの2枚だけ。4枚の画像データは上位3位以内にも判別されませんでした。
正解に近い画像データを追加学習させる
試しに正解データに近いお酒画像をWebから10枚ほど集めてきてそれを教師データとして追加学習させてみました。その結果は以下の通りとなりました。
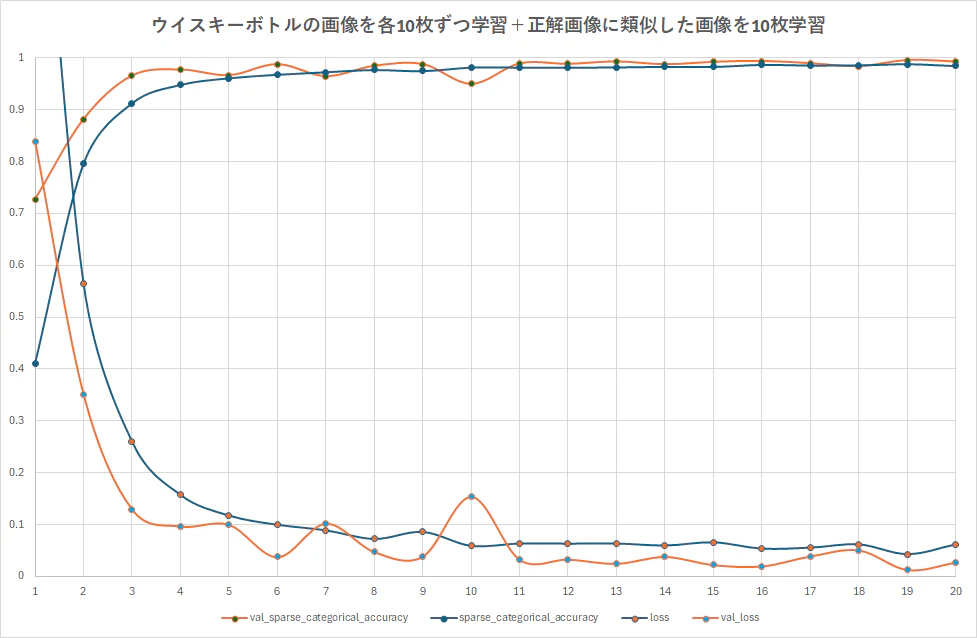
前回よりも教師データの枚数が増えているためか学習の正解率が早い段階で立ち上がっているようです。
このモデルを使って、先ほどと同じ10枚のお酒画像を判別させてみました。
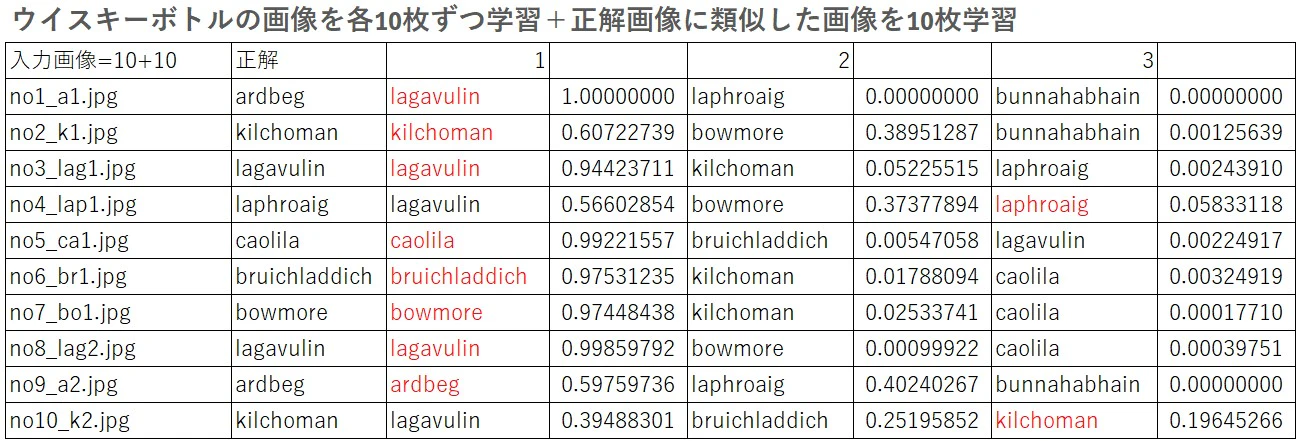
今度は10枚中8枚が正解と判別され、残りの2枚の画像も上位3位以内と判別されました。
この結果から、正解データに近い画像データが教師データに含まれている場合、たとえ画像データが少ない場合でも正解率はかなり上昇するようです。
再学習
先ほどの追加学習(正解データに近いお酒画像をWebから10枚ほど集めてきてそれを教師データとする)とまったく同じ条件で、再学習させ新しいモデルを作成しました。
前回と同じようにこのモデルを使って、先ほどと同じ10枚のお酒画像を判別させてみました。
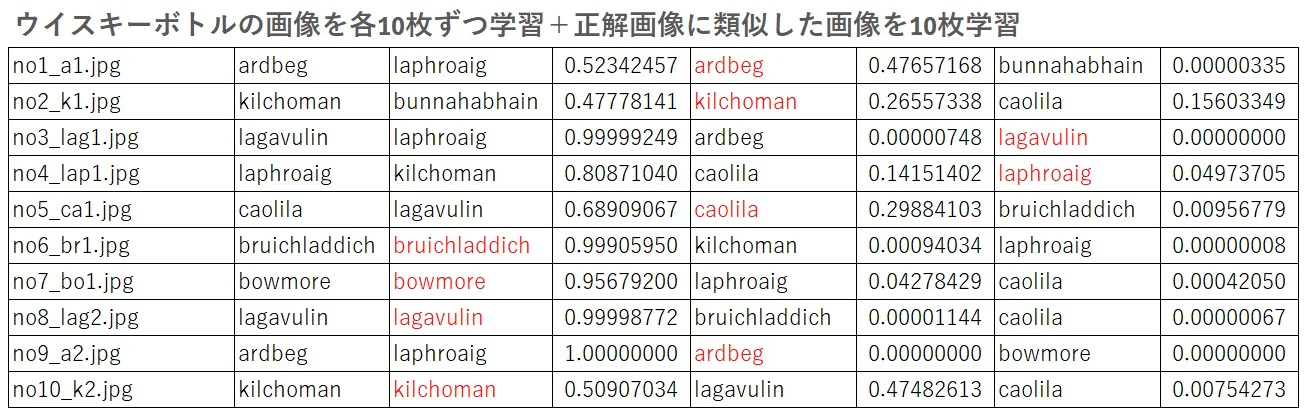
まったく同じ条件で学習させているにもかかわらず結果は前回とは全く異なりました。10枚中4枚が正解と判別され、それ以外の画像データは上位3位以内と判別されました。
おわりに
正解に近い画像データを追加学習させると再学習は、まったく同じ条件だったとしてもrand()によりランダムにミニバッチで選択される画像が異なってくるため、学習過程も異なるということだろう。今回は2回の追加学習での結果は異なるものが得られたが、いずれの結果も最初の学習お酒画像を学習させるの結果よりは正解率が高まっていることから、膨大な量の教師データを用いて学習させたモデルが比較的正解率も高まる傾向がありそうな気がする。