学生向けFixstars高速化コンテスト2026に参加しました.
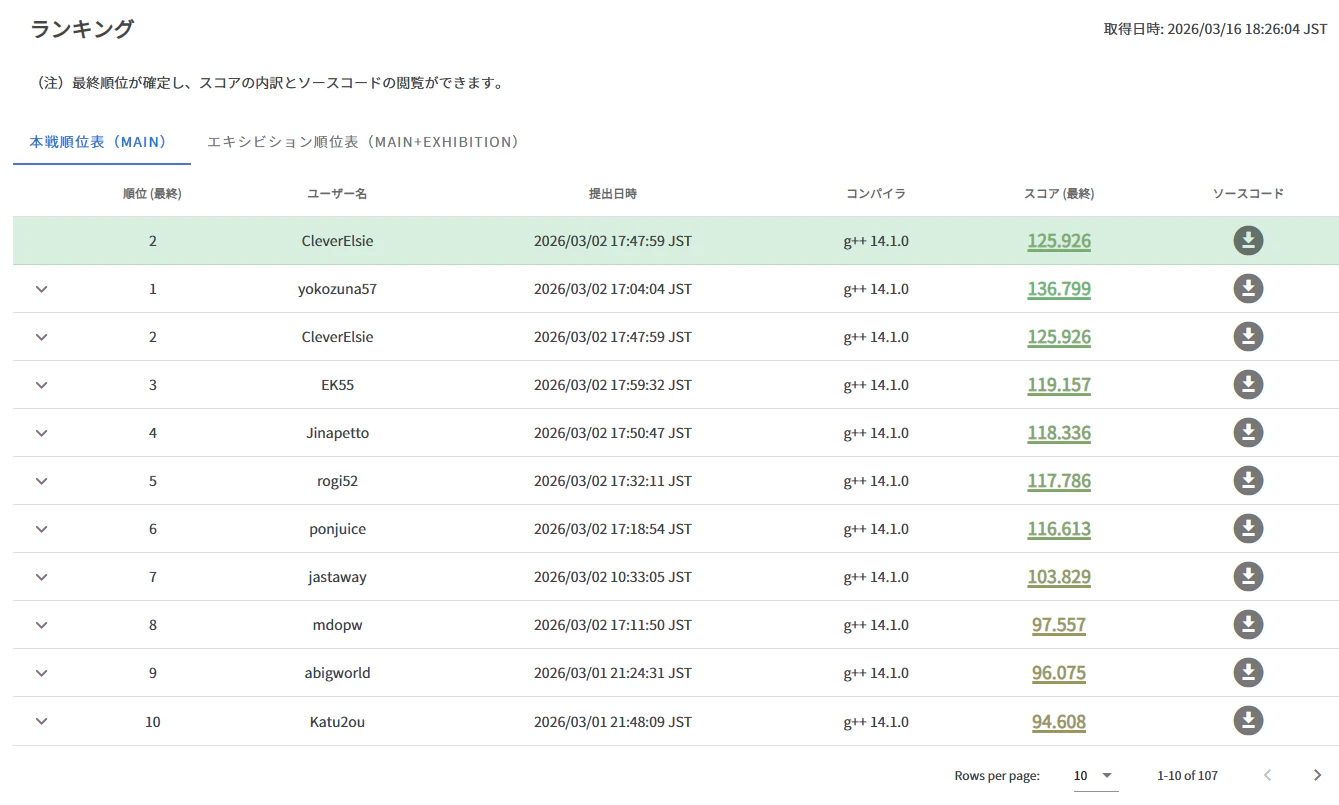
最終順位は2位でスコアは125.926でした.
1位のyokozuna57さんのスコアは136.799だったのでかなり差を付けられてしまいました.
3位から6位までは119.157から116.613とかなり団子で,私もコンテスト終了時の暫定順位は4位だったので,ほとんど差がつかないかなと思っていたんですが,なんとか2位をもぎ取ることができました.
ちなみに,賞金が出るので結構嬉しいです.

私は広島大学 情報科学部(計算機科学プログラム)3年(新4年) で AtCoder水色もう1年くらいコンテスト出てない なので競プロ強い大学のつよつよ競プロerというわけじゃないんですけど,こんなにいい順位につけられて結構びっくりです.
問題設定
$N=24,\ 64$ のグラフのクリークで,重みが最大の物を求める.
各頂点は128次元のパラメータベクトル(100,000以下)を持つ.
ただし,128次元のベクトルそれぞれの総和について,与えられる制約以上でなければならない.
実行環境
i7-11700 (コア数は4に制限)
L1データキャッシュ 48KB
L2 512KB/core
L3 16MB
AVX512
メモリ帯域幅Copy 19.8 GB/s, Scale 13.9 GB/s, Add 14.5 GB/s, Triad 14.8 GB/s
g++-14.1.0
実行時間制限3秒
コンテスト中のテストケースが30個,最終スコアのテストケースはそれとは別に150個.
スコアは各テストケースで全員の最速実行時間を自分の実行時間で割った値の総和で,125なら平均的に最速の83%くらいの実行速度なので,最速より1.2倍くらい時間がかかるという感じ.
全テストケースで最速のプログラムの実行時間は0.1から0.2ミリ秒くらいになっているので,スコアが30くらいの人でも実はかなり速い.
解法
詳しい解法は他の人がきっと出してくれると信じてざっくりと.
クリークに含める候補を$U$,含めることを決定した頂点を$K$とし,$U$をすべての頂点,$K$を空集合からスタートして,任意の頂点を含めるか含めないか選ぶDFSを行う.
能力値の各要素の上界が制約を満たさない場合や,到達可能な解の上界が暫定解より小さいなら枝狩り.
$U\cup K$ がクリークなら終端ノードとして,解の更新を行う.
暫定解は探索開始前に貪欲法で求める.
隣接行列は64bit整数をビットマップとして用いる.
制約のチェックにはAVX512のSIMD命令を用いる.
スレッドは起動コストが割に合わないので使わない.
smallケースとlargeケースで解法は変えない.
(私の解法はsmallケースに比較的有利で,largeはそうでもない)
small:large=1:2のテストケース比
前提知識
IntelのCPUには複数のデータに同じ命令(例えば足し算とか)を行う命令セットが用意されています.
それらはAVX, AVX2, AVX512と色々バージョンがありますが,今回はレジスタ幅が大きいAVX512を使います.
AVX512は512bit幅のレジスタ(ZMMレジスタ)があって,32bit整数なら16個同時に計算できます.
なので,今回の問題で128個のベクトルを全部ZMMレジスタに載せるなら8個必要になります.
ZMMレジスタは,プログラマが使える分は32本しかないです.
高速化テクニック
プリプロセッサ
まずはおまじないを書きます.
#pragma GCC optimize("O3,unroll-loops")
#pragma GCC target("avx2,avx512f,avx512dq,avx512vl,avx512bw,bmi,bmi2,lzcnt,popcnt")
例えコンパイルコマンドが-O2だったとしても関係ない!!
__builtin_ctzllや__builtin_popcountllを使うので,ターゲットにAVX以外も書きましょう.
バイナリサイズ削ったり_Exit()したり
実行環境では,計測プログラムは子プロセスを生成してその実行時間を計ります.
子プロセスを速く終わったように見せかけるテクニックとして_Exit(0)があります.
これを書くのと書かないので結構実行時間に差があるので,書き得です.
手元で計測すると,.soのロード時間が結構大きかったので,バイナリサイズを小さくすることが非常に有効になります.
動的リンクが遅いのはシンボル解決やページフォールトが起きるからなので,シンボルが少なければ少ないほどいいですし,バイナリサイズは小さければ小さいほどいいです.
そのために必要なことは,とりあえず関数を減らし,グローバル変数も減らし,何もincludeしないことです.
私のプログラムでincludeしたのはstddef.hとstdint.h,immintrin.hだけです.
immintrin.h以外は別にincludeしなくてもintやlong longと直接書けばいいのですが,私はint32_tやint64_tって書きたかったので,気分の問題です.
_Exit(0)はstdlib.hの関数なので,_Exit(0)を使うというのは大嘘です.
ところで_Exit(0)は単にプロセスを終わらせるシステムコールのラッパーライブラリ関数なので,インラインアセンブリでシステムコールを直接書けば同じことができます.
Linuxではexitのシステムコール番号は60なので,RAXに60を入れて,SystemV ABIではRDI, RSI, RDX, RCX, R8, R9の順番で引数を渡す(syscallではRCXではなくR10を使います)ので,EXIT_SUCCESSつまり0をRDIに書きます.
最後の"rax", "rdi"のところに"memory"も書いておいた方がいいです.
ここはこの命令で破壊されるレジスタのリストなので,"memory"を書くと書き込み順序を守ってくれるので,メモリバリアとして機能します.
私はその直前にメモリバリアを入れてるので書いてませんが,これが無い場合は答えの反映がされる前に子プロセスを殺してしまって,Wrong Answerになることがあります.
リターンアドレスがRCX,ステータスレジスタがR11に書き込まれて破壊されるので,本当はこれも書かないといけないです.私は書き忘れました.clobber警察の皆さまにおかれましてはまことにごめんなさい.noreturnだし別にいいかなって
__asm__ volatile(
"mov $60, %%rax\n\t"
"mov $0, %%rdi\n\t"
"syscall\n\t"
:
:
: "rax", "rdi"
);
__builtin_unreachable();
stdlib.hは他に使わないのでsolve(input_t&,output_t&)の最後にこう書くだけでOKです.
io_struct.hppで,問題の入出力に関する構造体などが定義されていますが,標準出力を使って入出力する部分も入っているので,構造体の定義の部分だけ拝借してソースコードにべた書きした方がいいです.
namespace io_struct{
constexpr size_t PARAMETER_COUNT = 128;
constexpr size_t MAX_N = 200;
struct input_t{
int N;
int A[MAX_N][MAX_N];
int v[MAX_N][PARAMETER_COUNT];
int r[PARAMETER_COUNT];
};
struct output_t{
int K_size;
long long T;
int members[MAX_N];
};
} // namespace io_struct
たったこれだけで結構サイズが小さくなるのでおすすめです.
ちなみに構造体の中身の順番は入れ替えてはいけません.
ちなみに当然algorithmなんかもincludeしてないので,ソートも手書きになります.
頂点の並び替えくらいしかやらないので,quick sortみたいな関数を書かず,バイナリサイズを小さくするために選択ソートやバブルソートをべた書きするのがおすすめです.
高々64要素の$O(n^2)$を定数回やるだけは大したことないです.
SIMDのループアンローリング
私のプログラムでは#pragma GCC unroll 8を使いまくってますが,バイナリサイズを減らすという話は何だったんだと思われそうです.
読者の皆さんはもちろんヘネパタを読んだことがあると思うので細かいことは省略しますがCPUは毎クロック複数の命令を発行して複数のロードストアを行えますから,分岐予測がない方がパフォーマンスがしばしばバイナリサイズを減らすより高速化に寄与するんですよね.
そんなわけで私のプログラムのSIMD命令はほぼすべてループアンローリングされているはずです.
ループアンローリングで制御命令と分岐予測ミスを減らし,ロードを飽和させてレイテンシを隠蔽しようというのがこの方法の目論見ですね.
こういうサイトがあって,immintrin.hの関数のスループットなどがわかります.
_mm512_load_epi32は0.5CPIなので,毎クロック2個ロードできるので,8クロックのレイテンシを埋めるにはループを4回展開すれば十分です.
なので,別に#pragma GCC unroll 8じゃなくて4でも良かったような気がします.
最近のCPUはTAGE予測器が使われているので,分岐ミスはほとんど発生しない気がしますし.
このとき,分岐は1度目がtake,2度目がuntakeになりますが,このパターンはTAGEじゃなくてもすぐに適応できそうなので,8回すべてをアンロールする必要は多分無いです.
再帰関数のループ展開
DFSが再帰関数ではなくループ展開されているのはZMMレジスタがアーキテクチャ的には32本しかないからです.
このループ展開は必ずしもバイナリサイズの低減に寄与しませんが,今回はたまたまループ展開したほうがバイナリサイズは小さくなりました.
このアプローチは毎回制約をロードしてるの無駄じゃね?と思ったから始めたんですけど,branch_include, branch_excludeなどで,うまく32本に収めれば再帰関数で復元しなくていいレジスタのロードを減らせるんじゃないかというのもありました.
グローバルに全部置いたら制約のロードしなくて済むし再帰関数でいいんじゃないかと思ったんですけど,そうすると初期解の構築とDFSであわせて32本以上使ってしまって,寿命解析でspillしないようなバイナリを吐いてくれる確証がなく確かめる気力も無かったので,ループ展開することにしました.
ループ展開とはすなわち,手動でDFSの中身を決定的有限オートマトン(DFA)概念的にはPDAに変換してループでエミュレートすることです.
DFSは一つのノードから続けて2回行われる可能性があり,つまり途中からの再開が必要なので当然元のDFSを再現するためにはスタック領域を別で確保する必要があります.
x86-64のL1キャッシュは64byteなので,alignas(64)とスタックのサイズを64byteにすることが多少は意味があるかなと思って,ちょっとStackItemの書き方に小細工をしています.
ZMMレジスタへのロードは_mm512_loadu_*ならアライメント不要ですが,_mm512_load_*を使うのでアライメントが必要で,512bit=64byteなので,alignas(64)はこれにちょうどぴったりです.
StackItemとSIMD用のundo_stackを分けたのは,構造体の中にalignas(64)を書きたくなかったからなので,別にひっつけても今回に関しては問題はないと思います.
スタック1個当たり $512+64=576\mathrm{byte}$ なので,64要素で36KBくらいあるので諸々考慮するとしばしばL1から落ちる可能性があるので,分けていればもしかしたらStackItemのほうだけでも生き残らないかなという目算はありますが,計測してないので知らないです.
ループ展開して__m512i[8]を4個solve()のローカル変数として保持するだけになって,こいつらがアーキテクチャ的なレジスタを全部占有してくれるだろうという目論見でこのプログラムは作られています.
もちろん実際に吐き出されるバイナリを確認するなんてことは大変なのでしてないですけど.
再帰関数のときは頂点を選ぶときと選ばないときのノードに好きな順序で直感的に行けましたが,ループ展開するとそうも行きません.
DFAと言いましたが,形式言語に詳しい皆さんはご存知の通り,上限の無い整数$N$について$0^N1^N$ という記号列をDFAは受理できません.
見ての通りスタックを使っているので,概念的にはプッシュダウンオートマトン(PDA)です.
なお,形式言語理論に詳しい皆さんはご存知の通り,上限のある整数$N$について$0^N1^N$という記号列を受理するDFAは存在しますので,これは等価なDFAが存在するPDA的な何かです.本当にDFAで実装したら状態数がバカみたいに増えるから仕方ないね!
つまり戻ってきたときに続きから始めるための情報が必要になるので,リターンアドレスを保持する代わりにスタックに書き込む必要があります.
ソースコードの以下の部分は再開処理についての記述です.
// branch_include/excludeのpre(cur_S==sumv)
// dfsのpre(undo_stack[depth-1]==cur_S)
#pragma GCC unroll 8
for(int k=0;k<8;++k){
_mm512_store_si512(&undo_stack[depth][k*16], cur_S[k]);
sumv[k] = cur_S[k];
}
const bool ei = s.T_exc > s.T_inc;
if(ei) goto exclude_path;
include_path:
if(s.T_inc > best_T_val && branch_include(s.non_edges_mask)){
// スタックに積む処理
continue;
}
if(ei) goto after_both;
exclude_path:
if(s.T_exc > best_T_val && branch_exclude(u)){
// スタックに積む処理
continue;
}
if(ei) goto include_path;
after_both:
stack_return;
}else{ // after_include_with_ieかafter_exclude_with_eiの場合
#pragma GCC unroll 8
for(int k=0;k<8;++k){
cur_S[k] = _mm512_load_si512(&undo_stack[depth][k*16]);
sumv[k] = cur_S[k];
}
StackItem& s = stack[depth];
if(s.control == Control::after_include_with_ie){
uint64_t chosen_mask = 1ULL << s.chosen_u;
if(s.T_exc > best_T_val && branch_exclude(s.chosen_u)){
// スタックに積む処理
continue;
}
}else{ // after_exclude_with_ei
if(s.T_inc > best_T_val && branch_include(s.non_edges_mask)){
// スタックに積む処理
continue;
}
}
stack_return;
}
以上のプログラムは以下の疑似プログラムをループ展開したものです.
if(s.T_inc<s.T_exc){
if(s.T_inc>best_T_val && branch_include(s.non_edges_mask))
dfs();
if(s.T_exc>best_T_val && branch_exclude(u))
dfs();
}else{
if(s.T_exc>best_T_val && branch_exclude(u))
dfs();
if(s.T_inc>best_T_val && branch_include(s.non_edges_mask))
dfs();
}
gotoを使っている部分は完全にこの部分だけを表しており,各分岐で一つ目のdfsに行かない時に二つ目の分岐を試せるようにしています.
eiがfalseの時は上から下に実行するだけですが,eiがtrueのときは,下行って上に戻って,一番下に行きます.
eiはexcludeしてからincludeという意味です.
これを使わず2回べた書きすると数千バイト大きくなるので,gotoを使っています.
elseの下側のほぼ同じ呼出しは,DFSから戻ってきたときの再開したときに実行する部分です.
これらの両方をあわせてincludeもexcludeも一回ずつしか書かないプログラムも最後に書いてたんですけど,間違えて出し忘れてました.
今のプログラムよりそっちのプログラムのほうが5000バイトくらい小さいバイナリになります.
SIMD命令はそこそこ長いので,片方のオペランドをメモリアクセスにしたり,演算結果を一時レジスタ使わずそのまま与えるように書くとコンパイラがいい感じに短い命令を使ってくれるようになるので,そういう書き換えも結構有効でした.
枝狩り
一番楽な枝狩りは,ある頂点を選ぶときにその頂点と隣接しないすべての頂点は取り除かなければならないという性質を利用して,スコアの上界を求める方法です.
$U$の頂点で,$U$の自分以外の一つ以上の頂点と隣接しない頂点の集合を$U'$とします.
このとき,任意の順序で以下の手続きを行って,$|U'|\le 1$になるまで繰り返します.
- $i\in U'$ を任意に選ぶ.
- $i$ と隣接しない頂点 $j\in U'$ を任意に選ぶ.
- 現在のスコアから$\min\left(\sum v_i, \sum v_j\right)$ を引く.
- $U'$ から $i,j$ を取り除く.
このとき,頂点の選び方は,$i$を並べ替え順で最も優先度が高いもの,$j$を$i$と接しない最も優先順位が低いものとしています.
こうすると,マッチングできるペアの中で差が最大になりやすいだろうという雰囲気でやってます.
辺が存在する確率が95%なので,辺が無い頂点の連結成分はサイズ2とかだといいなぁという希望的観測でやってます.
だいたい同じことを制約に対してもやりたいです.
ただ,頂点ごとにやっちゃうと特定の能力値は上界じゃなくなってしまうかもしれないので,能力値ごとに$\min$を取ります.
SIMDでやるだけです.
ソースコード全文(にコメントを大幅追加したもの)
コメント以外は提出したプログラムとまったく同じです.
提出したプログラムはランキングのところでダウンロードできます.
/*
* MIT License
*
* Copyright (c) 2026 CleverElsie
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
* SOFTWARE.
*/
#pragma GCC optimize("O3,unroll-loops")
#pragma GCC target("avx2,avx512f,avx512dq,avx512vl,avx512bw,bmi,bmi2,lzcnt,popcnt")
#define MIN(a,b) ((a)<(b)?(a):(b))
#include <stddef.h>
#include <stdint.h>
namespace io_struct{
constexpr size_t PARAMETER_COUNT = 128;
constexpr size_t MAX_N = 200;
struct input_t{
int N;
int A[MAX_N][MAX_N];
int v[MAX_N][PARAMETER_COUNT];
int r[PARAMETER_COUNT];
};
struct output_t{
int K_size;
long long T;
int members[MAX_N];
};
} // namespace io_struct
#include <immintrin.h>
using namespace io_struct;
enum class Control:uint32_t{
start=0,
after_include_exclude=1, // 両方終わったstack_return
after_include_with_ie=2, // current_S復元, call-exclude
after_exclude_with_ei=3, // current_S復元, call-include
};
// キャッシュラインに載せるために64byteに調整
struct StackItem{
uint64_t U, K; // 16byte
int64_t T_current; // 24byte
uint64_t dropped_mask; // 32byte
int64_t T_inc,T_exc; // 48byte
Control control; // 52byte
uint32_t chosen_u; // 56byte
uint64_t non_edges_mask; // 64byte
};
// DFSをループ展開するときにreturnの代わりに深さをエミュレートするシンタックスシュガー
#define stack_return { if (depth==0) break; else{--depth; continue;} }
__attribute__((noreturn))
void solve(input_t& input, output_t& output) {
alignas(64) uint64_t adj_mat[64]; // 隣接行列
alignas(64) uint64_t cmp_mat[64]; // 補グラフの隣接行列
alignas(64) int32_t T_arr[64]; // 各頂点の重みの総和
alignas(64) int32_t V_mat[64][128]; // 入力のvをアライメント
alignas(64) StackItem stack[66]; // スタック
alignas(64) int32_t undo_stack[66][128]; // cur_Sの復元用スタック
alignas(64) char original_idx[64]; // 頂点は並べ替えるので順序を保持する
const int N_v = input.N;
int depth = 0;
const uint64_t full_mask = (N_v==64) ? ~0ULL : 0xFFFFFF;
uint64_t mandatory_mask = 0, best_clique_mask = 0;
int64_t best_T_val = -1, init_T = 0;
[[no_unique_address]]__m512i req_v[8], cur_S[8], sumv[8], vmat[8]; // zmmレジスタに割り当てられるべき32個の名前付き変数
#pragma GCC unroll 8
for(int k=0;k<8;++k) req_v[k] = _mm512_loadu_si512(&input.r[k*16]); // reqはここでloadして以後不変
// dfsを再帰呼出しするならtrue
// 復元用データはcallerがsumvに積んでおく
auto branch_include = [&](const uint64_t non_edges_mask)__attribute__((always_inline))-> bool {
// non_edges_maskの頂点のVを減算してRを確認
for(uint64_t ex = non_edges_mask;ex;ex&=ex-1){
int idx = __builtin_ctzll(ex);
#pragma GCC unroll 8
for(int k=0;k<8;++k)
cur_S[k] = _mm512_sub_epi32(cur_S[k], _mm512_load_si512(&V_mat[idx][k*16]));
}
unsigned short violate=0xFFFF;
#pragma GCC unroll 8
for(int k=0;k<8;++k)
violate &= _mm512_cmpge_epi32_mask(cur_S[k], req_v[k]);
if(violate != 0xFFFF){ // 違反したら復元してfalse
#pragma GCC unroll 8
for(int k=0;k<8;++k) cur_S[k] = sumv[k];
return false;
}
return true;
};
auto branch_exclude = [&](const int u)__attribute__((always_inline))-> bool {
// 必須頂点は既にUには無いので,Uから選んだuでは必須頂点を除外する心配はない
#pragma GCC unroll 8
for(int k=0;k<8;++k)
cur_S[k] = _mm512_sub_epi32(cur_S[k], _mm512_load_si512(&V_mat[u][k*16]));
unsigned short violate=0xFFFF;
#pragma GCC unroll 8
for(int k=0;k<8;++k)
violate &= _mm512_cmpge_epi32_mask(cur_S[k], req_v[k]);
if(violate != 0xFFFF){
#pragma GCC unroll 8
for(int k=0;k<8;++k) cur_S[k] = sumv[k];
return false;
}
return true;
};
{ // グラフの構築
int32_t *Ts=undo_stack[0], *Hs=undo_stack[0]+64; // undo_stack[0]を並べ替えのために一時領域として活用
for(int i=0;i<N_v;++i){
original_idx[i] = i;
Ts[i] = 0, Hs[i] = 0;
for(int k=0;k<128;++k){
Ts[i] += input.v[i][k]; // 各頂点のvの総和
Hs[i] += MIN(input.v[i][k], input.r[k]); // 制約で飽和する並べ替えのためのキー
}
}
for(int i=0;i<N_v-1;++i) // 選択ソート
for(int j=i+1;j<N_v;++j)
if(int a=original_idx[i], b=original_idx[j]; // この記法便利だよね
Hs[a]!=Hs[b] ? Hs[a]<Hs[b] : Ts[a]<Ts[b]
){
original_idx[i] = b;
original_idx[j] = a;
}
#pragma GCC unroll 8
for(int k=0;k<8;++k) cur_S[k] = _mm512_setzero_si512();
for(int i=0;i<N_v;++i){
const int old = original_idx[i];
init_T +=(T_arr[i] = Ts[old]);
#pragma GCC unroll 8
for(int k=0;k<8;++k){
vmat[k] = _mm512_loadu_si512(&input.v[old][k*16]);
cur_S[k] = _mm512_add_epi32(cur_S[k], vmat[k]);
_mm512_store_si512(&V_mat[i][k*16], vmat[k]);
}
}
#pragma GCC unroll 8
for(int k=0;k<8;++k)
sumv[k] = cur_S[k]; // 初期解構築のcur_Sはsumvで代替
for(int i=0;i<N_v;++i){
adj_mat[i] = 0;
for(int j=0;j<N_v;++j) // 並べ替え済みの隣接行列ビットマップ
adj_mat[i] |= static_cast<uint64_t>(input.A[(int)original_idx[i]][(int)original_idx[j]])<<j;
cmp_mat[i] = ~adj_mat[i] ^ (1ULL << i); // 自己ループは取り除く
if(__builtin_popcountll(adj_mat[i])>=N_v-1) // 自分以外のすべてに辺があるとき,Kに最初から加えるリストに追加
mandatory_mask |= (1ULL << i);
}
}
if constexpr(true){ // 初期解の構築
uint64_t cur_U = full_mask;
int64_t temp_T = init_T;
while(cur_U){ // 貪欲に辺が少ない頂点から順番に取り除いていく
int worst_u = -1, max_non_edges = -1;
for(uint64_t temp_U = cur_U;temp_U;temp_U&=temp_U-1){
int i=__builtin_ctzll(temp_U);
int non_edges = __builtin_popcountll(cur_U & cmp_mat[i]);
if(non_edges>max_non_edges){
max_non_edges = non_edges;
worst_u = i;
}
}
if(max_non_edges<=0) break;
cur_U ^= 1ULL << worst_u;
temp_T -= T_arr[worst_u];
#pragma GCC unroll 8
for(int k=0;k<8;++k)
sumv[k] = _mm512_sub_epi32(sumv[k], _mm512_load_si512(&V_mat[worst_u][k*16]));
}
if(temp_T>best_T_val)[[likely]]{
unsigned short violate=0xFFFF;
#pragma GCC unroll 8
for(int k=0;k<8;++k)
violate &= _mm512_cmpge_epi32_mask(sumv[k], req_v[k]);
if(violate == 0xFFFF)
best_T_val = temp_T, best_clique_mask = cur_U;
}
}
stack[0].U = full_mask^mandatory_mask;
stack[0].K = mandatory_mask;
stack[0].T_current = init_T;
stack[0].dropped_mask = 0;
// T_inc, T_excはなんでもいい
stack[0].control = Control::start;
// chosen_u, non_edges_maskはなんでもいい
while(true){ // dfs
// startかafter_include_excludeの場合
if(static_cast<uint32_t>(stack[depth].control)<2)[[likely]]{
if(stack[depth].control == Control::after_include_exclude)[[unlikely]]
stack_return; // after_I/Eは早期return
// startの場合
StackItem& s=stack[depth];
int u=-1;
uint64_t mandatory_append=0;
{ // クリークかどうか.またそのときの最大非辺数の頂点を得る
int max_non_edges = -1;
for(uint64_t temp_U = s.U;temp_U;temp_U&=temp_U-1){
int i=__builtin_ctzll(temp_U);
int non_edges = __builtin_popcountll(s.U & cmp_mat[i]);
mandatory_append |= (static_cast<uint64_t>(non_edges==0)<<i);
if(non_edges>max_non_edges){
max_non_edges = non_edges;
u = i;
}
}
if(max_non_edges<=0 && s.T_current > best_T_val)[[unlikely]]{
best_T_val = s.T_current;
best_clique_mask = s.K|s.U;
stack_return;
}
}
s.U ^= mandatory_append;
s.K |= mandatory_append;
{ // クリークを壊す要素のマッチングにより,最も弱い制約違反を発見し枝狩りする
int64_t max_possible_T = s.T_current;
uint64_t temp_U_match = s.U; // 必須頂点を除外
// cur_S_k - L_k < req_k となると制約違反
// L_k はマッチング上の頂点u,vについてmin(V_u_k, V_v_k)
// これにより,制約を最も弱い条件で満たすかどうかを判定する
// cur_S_k < L_k + req_k なのでsumvにreqを積み,そこにL_kを加算する
#pragma GCC unroll 8
for(int k=0;k<8;++k) sumv[k] = req_v[k];
while(temp_U_match){
int u=__builtin_ctzll(temp_U_match);
temp_U_match&=temp_U_match-1;
uint64_t non_edges = temp_U_match&cmp_mat[u];
if(non_edges==0) continue;
int v=63-__builtin_clzll(non_edges); // vの選択は他にも方法がある
temp_U_match &= ~(1ULL << v);
max_possible_T -= MIN(T_arr[u], T_arr[v]);
#pragma GCC unroll 8
for(int k=0;k<8;++k){
vmat[k] = _mm512_load_si512(&V_mat[u][k*16]);
sumv[k] = _mm512_add_epi32(sumv[k], _mm512_min_epi32(vmat[k], _mm512_load_si512(&V_mat[v][k*16])));
}
}
if(max_possible_T <= best_T_val)[[unlikely]]{ stack_return; }
unsigned short violate = 0;
#pragma GCC unroll 8
for(int k=0;k<8;++k)
violate |= _mm512_cmplt_epi32_mask(cur_S[k], sumv[k]);
if(violate) stack_return;
}
s.chosen_u = u;
s.non_edges_mask = s.U & cmp_mat[u];
s.T_exc = s.T_current - T_arr[u];
s.T_inc = [&T_arr,&s](uint64_t ex)__attribute__((always_inline))-> int64_t {
int64_t acc = s.T_current;
for(;ex;ex&=ex-1) acc -= T_arr[__builtin_ctzll(ex)];
return acc;
}(s.non_edges_mask);
// branch_include/excludeのpre(cur_S==sumv)
// dfsのpre(undo_stack[depth-1]==cur_S)
#pragma GCC unroll 8
for(int k=0;k<8;++k){
_mm512_store_si512(&undo_stack[depth][k*16], cur_S[k]);
sumv[k] = cur_S[k];
}
const bool ei = s.T_exc > s.T_inc;
if(ei) goto exclude_path;
include_path:
if(s.T_inc > best_T_val && branch_include(s.non_edges_mask)){
// !ei == ie のとき,s.T_exc <= best_T_valならばexcludeを探索する意味はない
s.control = ei? (Control::after_exclude_with_ei)
: (s.T_exc <= best_T_val? Control::after_include_exclude : Control::after_include_with_ie);
StackItem& t = stack[++depth];
t.U = s.U & adj_mat[u];
t.K = s.K | (1ULL << u);
t.T_current = s.T_inc;
t.dropped_mask = s.dropped_mask | s.non_edges_mask;
t.control = Control::start;
continue;
}
if(ei) goto after_both;
exclude_path:
if(s.T_exc > best_T_val && branch_exclude(u)){
// eiのとき,s.T_inc <= best_T_valならばincludeを探索しなくていい
s.control = ei? (s.T_inc <= best_T_val? Control::after_include_exclude:Control::after_exclude_with_ei)
: Control::after_include_exclude;
StackItem& t = stack[++depth];
t.U = s.U ^ (1ULL << u);
t.K = s.K;
t.T_current = s.T_exc;
t.dropped_mask = s.dropped_mask | (1ULL << u);
t.control = Control::start;
continue;
}
if(ei) goto include_path;
after_both:
stack_return;
}else{ // after_include_with_ieかafter_exclude_with_eiの場合
#pragma GCC unroll 8
for(int k=0;k<8;++k){
cur_S[k] = _mm512_load_si512(&undo_stack[depth][k*16]);
sumv[k] = cur_S[k];
}
StackItem& s = stack[depth];
if(s.control == Control::after_include_with_ie){
uint64_t chosen_mask = 1ULL << s.chosen_u;
if(s.T_exc > best_T_val && branch_exclude(s.chosen_u)){
s.control = Control::after_include_exclude;
StackItem& t = stack[++depth];
t.U = s.U & ~chosen_mask;
t.K = s.K;
t.T_current = s.T_exc;
t.dropped_mask = s.dropped_mask | chosen_mask;
t.control = Control::start;
continue;
}
}else{ // after_exclude_with_ei
if(s.T_inc > best_T_val && branch_include(s.non_edges_mask)){
s.control = Control::after_include_exclude;
StackItem& t = stack[++depth];
t.U = s.U & adj_mat[s.chosen_u];
t.K = s.K | (1ULL << s.chosen_u);
t.T_current = s.T_inc;
t.dropped_mask = s.dropped_mask | s.non_edges_mask;
t.control = Control::start;
continue;
}
}
stack_return;
}
}
{ // 解の出力
output.T = best_T_val;
int k_size = 0;
for(uint64_t mask = best_clique_mask;mask;mask&=mask-1)
output.members[k_size++] = original_idx[__builtin_ctzll(mask)]+1;
for(int i=0;i<k_size-1;++i)
for(int j=i+1;j<k_size;++j)
if(output.members[i]>output.members[j]){
int t=output.members[i];
output.members[i] = output.members[j];
output.members[j] = t;
}
__asm__ volatile("":::"memory");
output.K_size=k_size;
__asm__ volatile("":::"memory");
}
__asm__ volatile(
"mov $60, %%rax\n\t"
"mov $0, %%rdi\n\t"
"syscall\n\t"
:
:
: "rax", "rdi"
);
__builtin_unreachable();
}