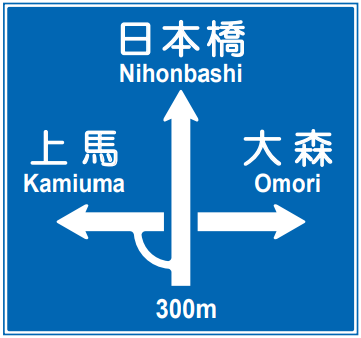
Amazon SageMaker は機械学習のワークフロー全体をカバーする AWS の完全マネージド型サービスであるが、実際に何ができてどのように使えばいいのか分からなかったため、今回は Amazon SageMaker の オブジェクト検出アルゴリズム を使用して、画像から下図のような日本の道路に広く見られる道路標識(方面及び方向の予告)を検出してみた。
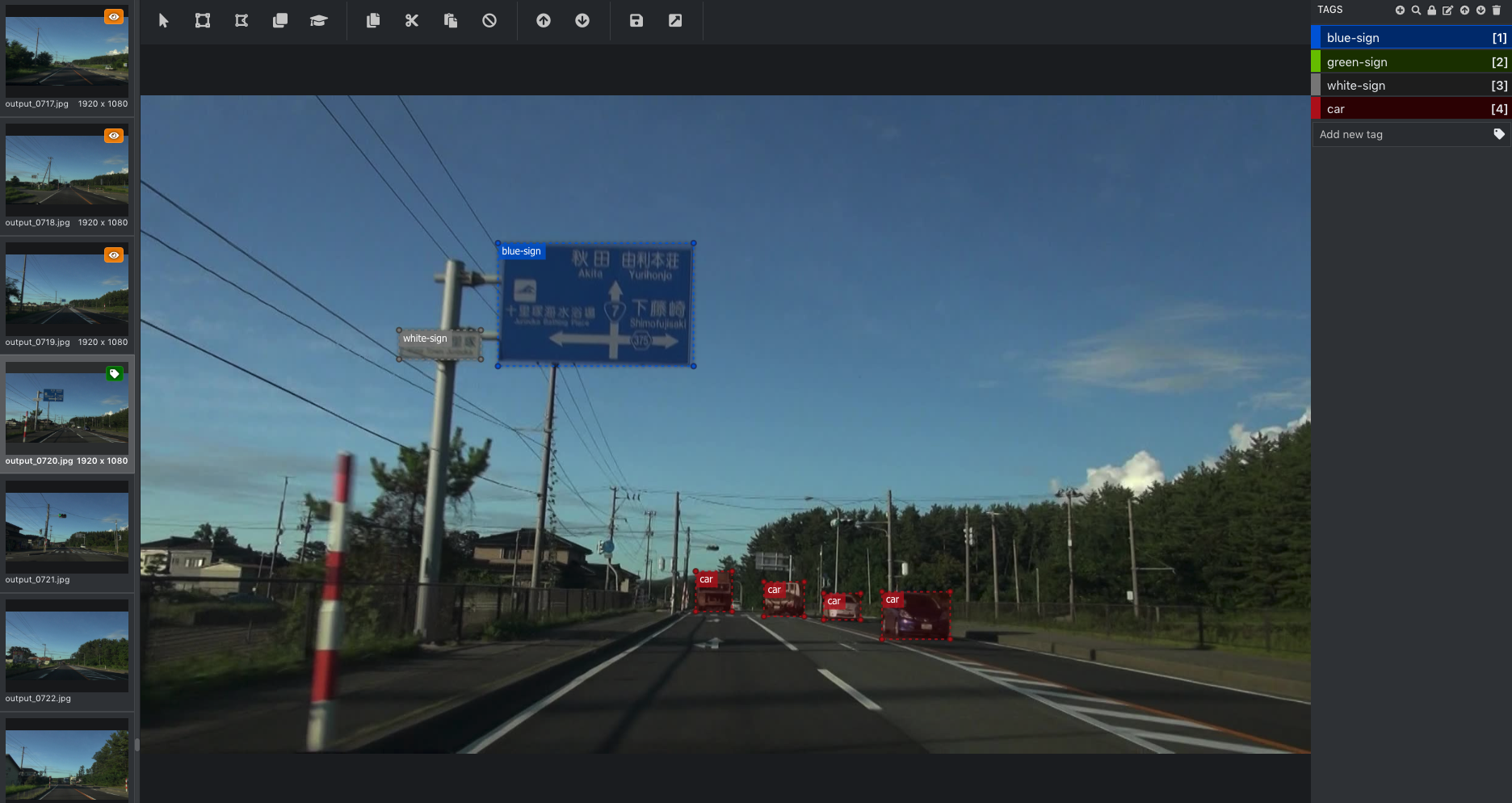
教師データの作成
映像からスクリーンショットを抽出
まずは、学習用に道路標識を含む大量の画像を用意する必要がある。そこで、走行中の車内から前方を撮影した映像を用意し、FFmpeg により 4 秒おきにスクリーンショットを取得することで、大量の画像を得た(以下のコマンドでは yadif フィルターによるインターレース解除処理を同時に行っている)。
ffmpeg -loglevel warning -i input.mp4 -vf yadif=0:-1:1 -r 0.25 output_%04d.jpg
画像のアノテーション(タグ付け)
抽出した大量の画像をもとに教師データを作成する。すなわち、画像内の道路標識の部分を手作業で指定してやる必要がある。Amazon SageMaker Ground Truth というサービスを利用して、この作業を外部のパブリックチームや社内のプライベートチームなどに委託することもできるが、今回は小規模のため自力で行うこととする。
このような、画像のタグ付け(アノテーション)を少しでもラクにするためにさまざまなツールが存在しているが、今回は Microsoft が開発している VoTT (Visual Object Tagging Tool) を使用した。VoTT によるアノテーションについては こちら の別記事を参照されたい。
RecordIO 形式のファイルを作成
Amazon SageMaker のオブジェクト検出アルゴリズムでは入力ファイル形式として Apache MXNet RecordIO 形式が推奨されているため、VoTT により作成したアノテーションデータ(JSON 形式)を RecordIO 形式に変換する必要がある。変換の手順については こちら の別記事を参照されたい。
Amazon S3 に教師データをアップロード
RecordIO 形式のファイルを下記の通り Amazon S3 にアップロードした。なお、機械学習においては一般的に、過学習を防ぐ目的で、学習用データと検定用データを別々に用意することが多い。今回は、タグ付けした 240 枚の画像から無作為に抽出した 160 枚の画像を学習用データ、残りの 80 枚を検定用データとして、それぞれ RecordIO 形式のファイルを作成した。
| S3 URI | 説明 |
|---|---|
| s3://example-bucket/train/train.rec | 学習用データ (RecordIO 形式) |
| s3://example-bucket/validation/validation.rec | 検定用データ (RecordIO 形式) |
ノートブックインスタンスの作成
機械学習を始めるにあたり、データの前処理や可視化、アルゴリズムの検討などを行うために Jupyter Notebook というツールを使う。これはブラウザ上で Python のコードを対話的に実行できるようなもので、機械学習やデータ分析の分野では一般的に使われている。
通常は Jupyter Notebook をローカル PC にインストールしたり Docker コンテナとして入手して使用したりするが、Amazon SageMaker ノートブックインスタンスは、いわば AWS のマネージド Jupyter Notebook のようなもので、インスタンスを作成するとすぐに Jupyter Notebook が使用できるようになる。
ノートブックインスタンスは Amazon SageMaker マネジメントコンソールから簡単に作成できる。
参考: https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/gs-setup-working-env.html
トレーニングジョブの作成
ここからはノートブックインスタンスで稼働する Jupyter Notebook 上で Python コードを実行していく。Jupyter Notebook の使い方についてここでは説明しないが、基本的には「セル」と呼ばれるエリアにコードを記述し、Shift + Enter キーを押してコードを実行するという作業の繰り返しになる。
以下では https://github.com/awslabs/amazon-sagemaker-examples/blob/master/introduction_to_amazon_algorithms/object_detection_pascalvoc_coco/object_detection_recordio_format.ipynb を参考にトレーニングジョブの作成を行う。
import sagemaker
from sagemaker import get_execution_role
role = get_execution_role()
print(role)
sess = sagemaker.Session()
Amazon SageMaker の組み込みアルゴリズムの中から「オブジェクト検出アルゴリズム」の最新のイメージを読み込む。
from sagemaker.amazon.amazon_estimator import get_image_uri
training_image = get_image_uri(sess.boto_region_name, 'object-detection', repo_version='latest')
print(training_image)
トレーニングを行うインスタンスを設定する。第 1 引数にアルゴリズムのイメージ、第 2 引数に IAM ロールを指定する。train_instance_count はインスタンスの台数、train_instance_type はインスタンスタイプを表す。なお、オブジェクト検出アルゴリズムでは GPU を搭載した P2 または P3 インスタンスファミリーを選択する必要があることに注意。また、GPU インスタンスは高額なので使いすぎには十分注意したい。train_volume_size はインスタンスに与える追加のボリュームサイズ(GB 単位)。train_max_run はトレーニングの最大実行時間(秒)で、最初は短めに設定しておくことを推奨する。output_path にはトレーニング済みのモデルを出力する Amazon S3 の URI を指定する。
参考: https://sagemaker.readthedocs.io/en/stable/estimators.html
od_model = sagemaker.estimator.Estimator(training_image,
role,
train_instance_count=1,
train_instance_type='ml.p2.xlarge',
train_volume_size=8,
train_max_run=600,
input_mode='File',
output_path='s3://example-bucket/sagemaker/output',
sagemaker_session=sess)
続いてハイパーパラメータと呼ばれるトレーニングに関連する各種パラメータを調整する。num_classes には教師データに何種類のタグが含まれるかを指定する。num_training_samples は教師データに含まれる画像の枚数を指定する。トレーニング中にメモリ不足が発生した場合は mini_batch_size を小さくする(ml.p2.xlarge インスタンスで mini_batch_size = 32 の場合、メモリ不足が発生した)。その他の項目は基本的にデフォルト値のままとしている。
参考: https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/object-detection-api-config.html
od_model.set_hyperparameters(base_network='vgg-16',
use_pretrained_model=1,
num_classes=4,
mini_batch_size=8,
epochs=30,
learning_rate=0.001,
lr_scheduler_factor=0.1,
optimizer='sgd',
momentum=0.9,
weight_decay=0.0005,
overlap_threshold=0.5,
nms_threshold=0.45,
image_shape=512,
label_width=350,
num_training_samples=240)
Amazon S3 にアップロードした教師データ(学習用と検定用)の情報を指定する。第 1 引数の S3 URI は RecordIO 形式のファイルへのフルパス、または同ファイルが格納されているディレクトリ名を指定する。ディレクトリ名を指定する場合は、ディレクトリ内に RecordIO 形式のファイルが複数存在してはならないことに注意。
train_data = sagemaker.session.s3_input('s3://example-bucket/train',
distribution='FullyReplicated',
content_type='application/x-recordio',
s3_data_type='S3Prefix')
validation_data = sagemaker.session.s3_input('s3://example-bucket/validation',
distribution='FullyReplicated',
content_type='application/x-recordio',
s3_data_type='S3Prefix')
data_channels = {'train': train_data, 'validation': validation_data}
次のコードを実行すると、トレーニングジョブが開始される。トレーニングが終了するか、train_max_run で指定した最大実行時間が経過すると、Amazon S3 の指定した場所にモデルが .tar.gz 形式で出力される。
od_model.fit(inputs=data_channels, logs=True)
なお、トレーニングインスタンスの料金については、実際にトレーニングを行っていた時間に対してのみ秒単位で課金される。すなわち、トレーニングインスタンスが起動しても、教師データの不備や設定ミスによって実際にトレーニングが始まる前にジョブが終了した場合は、課金されないということになる。
エンドポイントの作成
トレーニングにより出力されたモデルを使用して実際に未知データの推論を行うため、エンドポイントを作成する。エンドポイントのインスタンスは、トレーニングインスタンスとは異なるインスタンスタイプを選択することができる。
object_detector = od_model.deploy(initial_instance_count=1, instance_type='ml.m5.large')
未知データの推論
Jupyter Notebook に画像ファイルをアップロードし、作成したエンドポイントで道路標識の検出を試みた。
import json
file_name = 'test01.jpg'
with open(file_name, 'rb') as image:
f = image.read()
b = bytearray(f)
ne = open('n.txt', 'wb')
ne.write(b)
object_detector.content_type = 'image/jpeg'
results = object_detector.predict(b)
detections = json.loads(results)
print(detections)
検出結果を画像に重ね合わせて可視化するための関数 visualize_detection を用意する。
def visualize_detection(img_file, dets, classes=[], thresh=0.6):
"""
visualize detections in one image
Parameters:
----------
img : numpy.array
image, in bgr format
dets : numpy.array
ssd detections, numpy.array([[id, score, x1, y1, x2, y2]...])
each row is one object
classes : tuple or list of str
class names
thresh : float
score threshold
"""
import random
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img=mpimg.imread(img_file)
plt.imshow(img)
height = img.shape[0]
width = img.shape[1]
colors = dict()
for det in dets:
(klass, score, x0, y0, x1, y1) = det
if score < thresh:
continue
cls_id = int(klass)
if cls_id not in colors:
colors[cls_id] = (random.random(), random.random(), random.random())
xmin = int(x0 * width)
ymin = int(y0 * height)
xmax = int(x1 * width)
ymax = int(y1 * height)
rect = plt.Rectangle((xmin, ymin), xmax - xmin,
ymax - ymin, fill=False,
edgecolor=colors[cls_id],
linewidth=3.5)
plt.gca().add_patch(rect)
class_name = str(cls_id)
if classes and len(classes) > cls_id:
class_name = classes[cls_id]
plt.gca().text(xmin, ymin - 2,
'{:s} {:.3f}'.format(class_name, score),
bbox=dict(facecolor=colors[cls_id], alpha=0.5),
fontsize=12, color='white')
plt.show()
最後に結果を出力する。visualize_detection の第 3 引数に渡す配列は、教師データをタグ付けする際に、検知したい各物体に割り当てた番号との対応関係を表すものである(今回は青色の標識を 0 , 緑色の標識を 1 , 白色の標識を 2 としてタグ付けを行なっている)。
object_categories = ['blue-sign', 'green-sign', 'white-sign']
threshold = 0.20
visualize_detection(file_name, detections['prediction'], object_categories, threshold)
実行結果
教師データの量が少なくトレーニングの時間も不十分だったため確度は低いものの、道路標識の検出には成功した。教師データを増やしたり、トレーニングの時間を十分に確保したりすることで、さらに検出精度が向上することが期待できる。



エンドポイントの削除
エンドポイントはデプロイされている時間に応じて課金されるため、不要になったら必ず削除する。
sagemaker.Session().delete_endpoint(object_detector.endpoint)