この記事について
この記事は、AWSとGoogleCloudで、とりあえず簡単にRAGを構築してみたい!(API呼び出しもあるよ)のAWS編として、AWSでの構築手順をまとめたものになります。
GoogleCloud編や、AWSとGoogleCloudの比較を見たい方は親記事からどうぞ。
0. 使用するサービス
AWSではAmazon Bedrockのナレッジベースを使用します。(先日まではメニューが英語で「KnowledgeBase」と書かれていた気がするんですが、いつの間にかコンソールが変わってカタカナ表記になっていたので、この記事でもカタカナ表記にします)
ナレッジベースで外部から与える情報源と使いたいデータベースサービスを指定すると、RAGを構築できるようになっています。
1. S3にテキストファイルを配置する
Bedrockに触れる前に、まずは外部情報となるテキストファイルをS3に配置します。テキストファイルの作成については親記事で触れておりますので、そちらをどうぞ。
バケットの作成
S3の画面を開き、「バケットを作成」をクリックします。
次の画面で、リージョンを バージニア北部(us-east-1) にします。
バケット名に任意の値を入れたら、あとの項目はデフォルトでOK。画面一番下の「バケットを作成」をクリックしてバケット作成を実行します。
(▼リージョン指定を間違えるとナレッジベース作成時に上手くいかないので注意)

テキストファイルの配置
バケットが作成できたら、バケット一覧画面で作成したバケットをクリックします。
直下にテキストファイルを置いてしまってもいいんですが、それっぽくフォルダ分けもしてみましょう。
[バケット]
┣ ham_g
┃ ┗ ham_g.txt
┗ ham_j
┗ ham_j.txt
▼ ham_g.txtを配置した状態

2. BedrockでClaudeの使用を開始する
下準備もできたところで、Bedrockに触れていきたいと思います。
Bedrock画面を開いて、「使用を開始」をクリックしましょう。
初めてBedrockに触れる方は↓のようなようこそ画面が開くかと思いますが、いったんこれは閉じておきます。
Bedrockでは様々なモデルを使うことができますが、今回は日本語処理に強いと言われるClaudeを使ってみたいと思います。
Bedrockはリージョンによって使えるモデルが限定されており、東京では2024年4月10日時点で、最新のClaude3がまだ使えません。そのため、今回はバージニア北部で構築を進めます。
コンソール右上のドロップダウンで、リージョンをバージニア北部に変更します。
Bedrockでモデルを利用するためには利用開始の手続きが必要です。利用開始手続きをするために、画面左メニューの「モデルアクセス」をクリックしてベースモデル一覧画面に移行します。
(▼ 画面の左下、赤枠のところをクリック)

ベースモデル画面では、このリージョンで使えるモデル一覧とステータスを確認することができます。アクセスのステータス欄が「アクセスが付与されました」となっていればモデルが利用可能ですが、初回使用の場合は「リクエスト可能」となっているかと思います。これを利用可能にするために、画面右上の「モデルアクセスを管理」をクリックします。
「モデルアクセスを管理」の画面で、基本的には使いたいモデルにチェックを入れれば良いのですが、Claudeはもうひと手間、利用開始申請が必要になります。
私の手元の環境ではすでに利用開始申請が済んでしまっているので詳細が確認できないのですが、モデルを使う用途などを入力する必要があったかと思います。
↓こちらの記事に入力方法がありましたので、参考にどうぞ。(コンソールが日本語化されているので、画面が少し変わっているかもしれません)
https://qiita.com/icoxfog417/items/869e2093e672b2b8a139
Claudeの利用申請が完了したら、利用開始可能になるまで少し待ちます。(それほど待ち時間はなかったと思います。少し経ったら画面を更新してみてください。)
Claudeが使えるようになったら、モデルアクセス管理画面で以下のモデルにチェックを入れて「変更を保存」をクリックします。
・Titan Embeddings G1 - Text
・Claude
・Claude 3 Sonnet
・Claude 3 Haiku
モデル一覧画面でステータスが「進行中」から「アクセスが付与されました」に変われば準備完了です。
3. ナレッジベースの作成
モデルの準備が済んだら、ナレッジベースを作成していきます。
左メニューの「ナレッジベース」をクリックしてナレッジベース画面表示し、「ナレッジベースを作成」をクリックします。
ステップ1

ステップ1ではナレッジベースの名前、IAM、タグを入力します。
特にこだわりがなければデフォルトのままでOKです。
・ナレッジベース名 - 任意の名前。
・IAM - 基本的には新しいサービスロールを作成すればよいかと思います。(事前に作っているものがあればそちらを指定。)新規に作る場合は任意の名前を入れますが、「AmazonBedrockExecutionRoleForKnowledgeBase_」の文字列は必ず入れないといけないようなので注意。
・タグ - 任意。
上記を設定したら、「次へ」をクリック。ステップ2へ進みます。
ステップ2
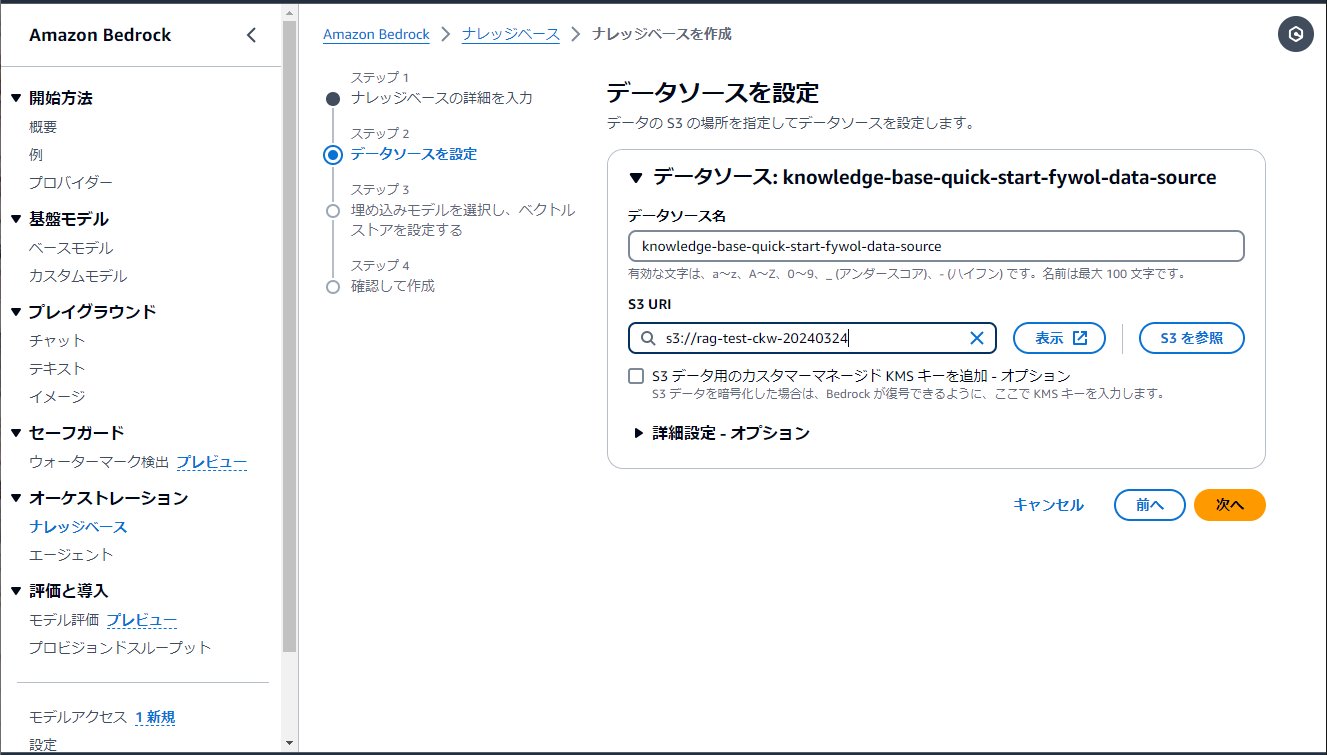
ステップ2ではデータソースの設定をします。
・データソース名 - 任意の名前。
・S3 URI - 「S3を参照」をクリックすると、現在のリージョンで作られているS3が表示されるので、先ほど作ったバケットを選んで「選択」をクリック。ここで目当てのS3バケットが表示されない場合は、作成したリージョンが間違っている可能性があります。
入力・選択が済んだら「次へ」をクリック。
ステップ3
ステップ3では、外部データベースを設定します。
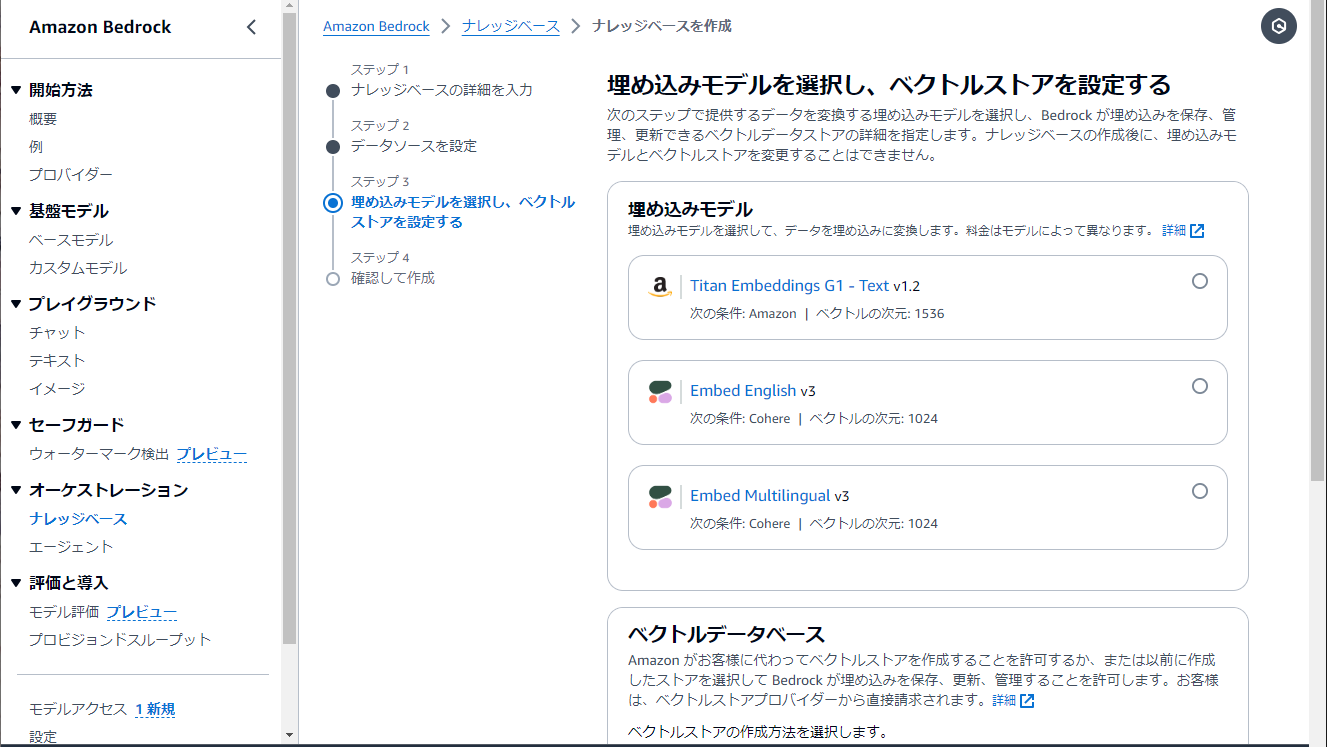
・埋め込みモデル - データ変換に使用するモデルを選択します。ここでは先ほどのモデル一覧画面で有効にしたTitan Embeddings G1 - Textを選びます。
・ベクトルデータベース - 事前に作ったデータベースを設定するか、ここで新規に作成するかを選びます。特に事前に作ったデータベースはないので「新しいベクトルストアをクイック作成」を選択します。
ここまで入力したら、「次へ」をクリック。
確認画面で入力項目を確認し、問題なければ「ナレッジベースを作成」をクリックします。
するとAmazon OpenSearch Serverlessのデータベース作成が始まるので、しばらく待ちます。(5分~8分ほどかかります)
4. ナレッジベースのテスト
ナレッジベースの作成が完了すると、以下のような画面が表示されます。ここでナレッジベースのテストができます。
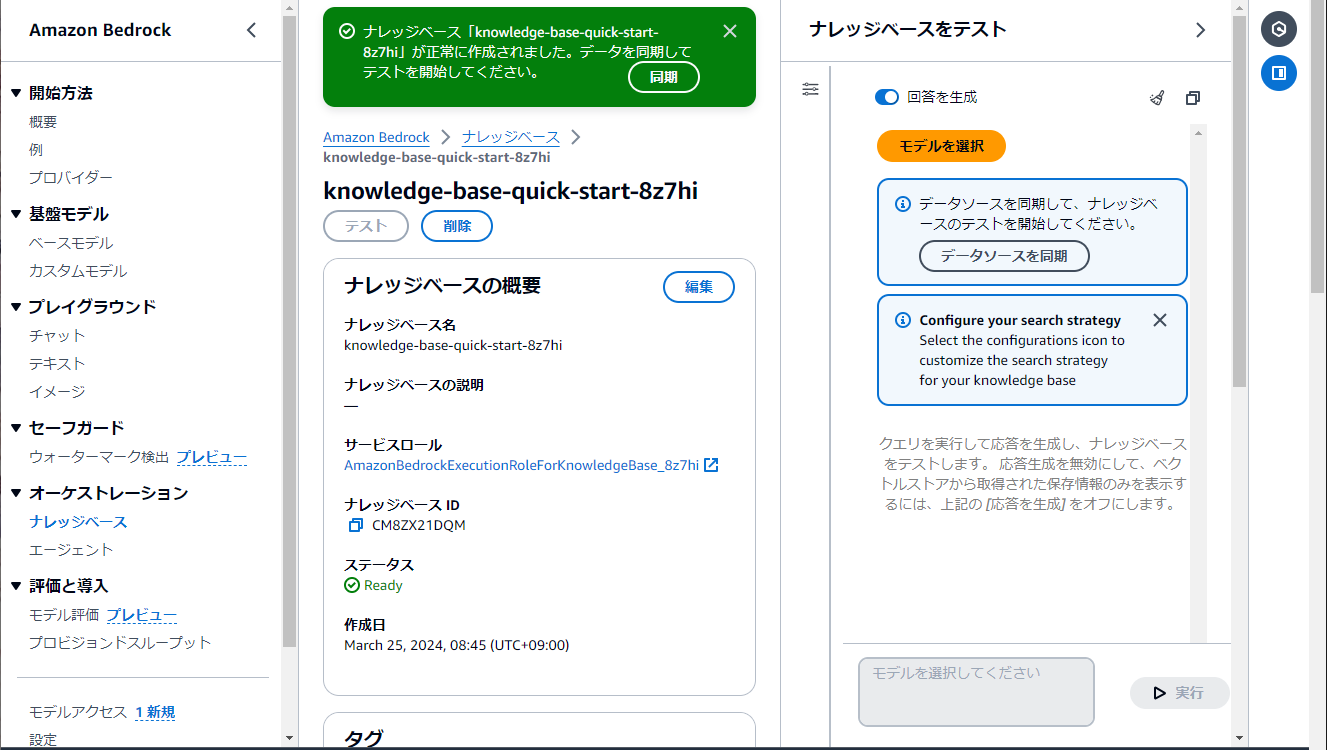
・「データソースの同期」をクリックします。数秒で同期が完了します。
・「モデルを選択」をクリックします。選択可能なモデル一覧が表示されるので、ここで先ほど利用開始を行ったClaude3を選択し、「適用」をクリックします。(選択肢にSonnetとHaikuが出るかと思います。モデルによって質問への回答も変わってくるので、比べてみたりすると良いと思います)
▼ 質問を入力して「実行」をクリックすると…

▼ 数秒で答えが表示されました!
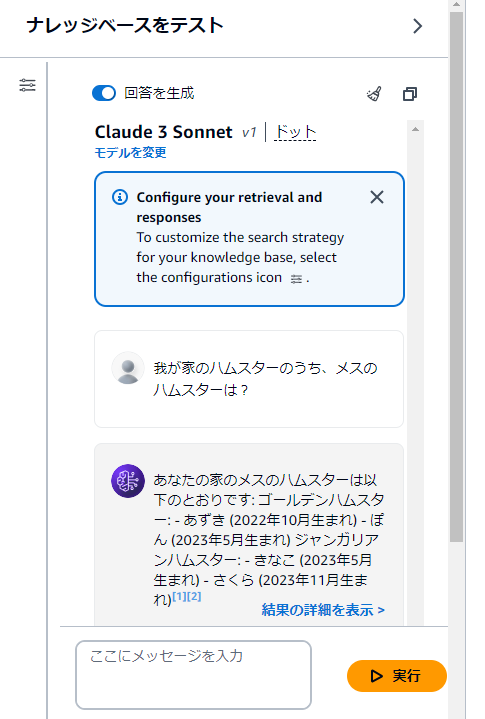
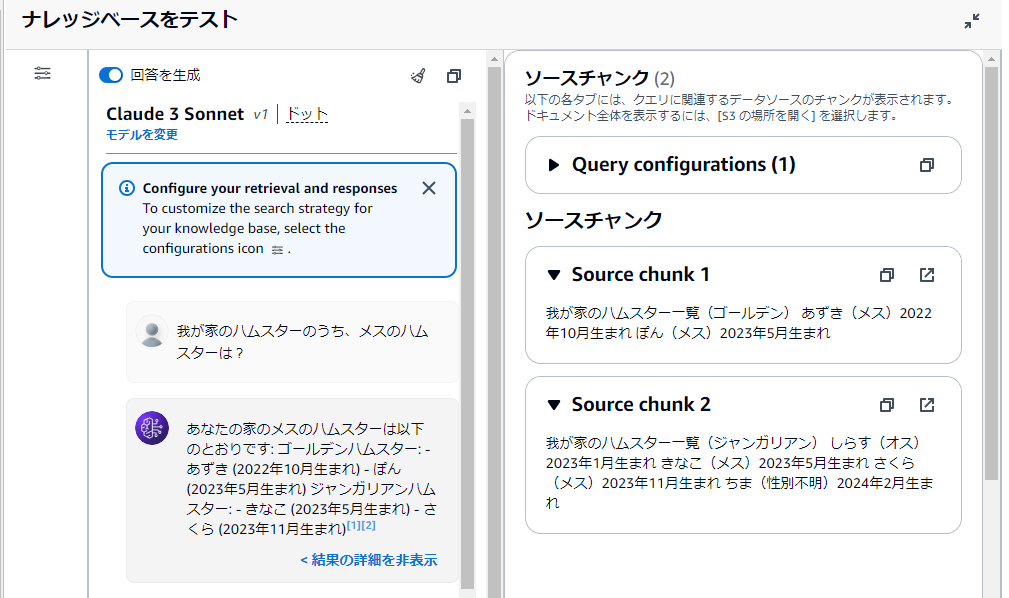
▼ 「結果の詳細を表示」をクリックすると、答えのソースとなったデータを表示することもできます。
5. エージェントの作成
今の状態では、せっかく作ったナレッジベースもこのコンソール上でしか使えません。
他からの呼び出しで使えるように、エージェントを作ります。
Bedrockの画面左メニューから「エージェント」を選択してエージェント画面を表示し、「エージェントを作成」をクリックします。
エージェント作成開始
(▼ 名前の入力)

「エージェントを作成」を選択すると、エージェント名を入力するポップアップが表示されるので、エージェント名と説明(任意)を入力して「作成」ボタンをクリックします。
Agent details

Agent builderの画面が表示されるので、上から順に必要な情報を入力していきます。
まずはAgent detailsで以下を設定します。
・IAM - ナレッジベースのIAMロールと同様、新しいサービスロールを作成すればOK。事前に作っているものがあればそちらを指定します。IAM名に「AmazonBedrockExecutionRoleForAgents_」の文字列を必ず入れないといけないようなので注意。
・モデルを選択 - 2024年4月10日時点ではClaude3を指定できないようなので、ここではClaude2.1を指定します。ここで有効なモデルが表示されない場合は、「2. BedrockでClaudeの使用を開始する」でClaude(「Claude3」ではなく「Claude」)を有効にしていないことが考えられるので、モデルアクセス画面で確認してください。
・エージェント向けの指示 - 日本語で指示を記入します。回答形式の指定などができます。思いつかない場合は「あなたは優秀なAIアシスタントです。ユーザーの指示に従って回答を作成してください。」等と入力しておけば良いと思います。
・Additional settings(ユーザー入力、アイドルセッションタイムアウト) - 基本的にデフォルトでOK。
ここまで入力したら、画面の上の方にある 「保存」を選択 します。
ここで保存を押さないと、他の項目設定が上手くいきません。
アクショングループ、ナレッジベース
アクショングループでは、ここから呼び出すLambdaなどの設定ができます。今回は使用しないので特に設定は必要ありません。
ナレッジベース設定で先ほど作成したナレッジベースとの関連付けが必要なので、ナレッジベース欄の「追加」をクリックします。
(▼ エージェント作成 ナレッジベースの追加)
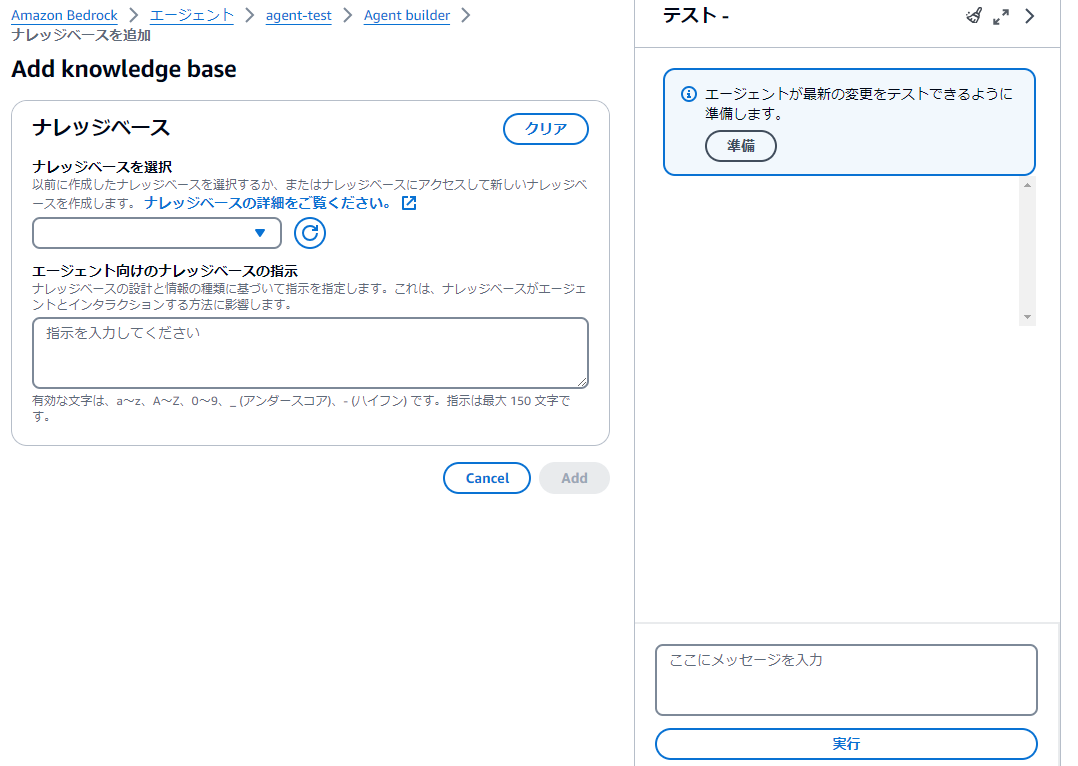
こちらの画面で関連付けるナレッジベースを指定します。
・ナレッジベースを選択 - 先ほど作成したナレッジベースを選択します。ナレッジベースが何も表示されない場合は、リージョンが間違っていないか確認してください。
・エージェント向けのナレッジベースの指示(任意) - ここでも指示を入力します。例として「ユーザーの指示に従って回答を作成してください。」と入力しました。
詳細プロンプト
最後に前処理等の詳細を指定できますが、今回はデフォルトのままでいきます。
ここまで入力したら、もう一度「保存」をクリックします。
エージェントのテスト

エージェントの保存が出来たら、右側のこの画面でエージェントのテストができます。
「準備」ボタンをクリックして、質問を入力します。

質問によっては、モデルが上手く回答を生成できない場合があります。その時は質問のしかたを変えてみてください。
エージェントのテストが完了したら、「保存して終了」をクリックします。
エージェント一覧画面で、作成したエージェントがPreparedになっていたらOKです。
6. エージェントのエイリアスを作る
ここまででナレッジベースとエージェントを作成することができました。
今回はここから更に、他サービスからAPI呼び出しをしたいと思います。
他サービスから呼び出す場合はエージェントと関連付けるのですが、そのためにエージェント側でもう1ステップ、エイリアスの作成が必要になります。
エイリアスの作成
(▼ エージェント一覧画面)

エージェント一覧画面を表示すると、先ほど作成したエージェントが表示されているので、エージェント名をクリックします。
(▼ エージェント詳細画面)

選択したエージェント名の詳細画面が表示されるので、画面上方の「エイリアスを作成」ボタンをクリックします。
(▼ エイリアス作成)

エイリアス名を入力するポップアップが表示されるので、設定したいエイリアス名を入力して「エイリアスを作成」ボタンをクリックします。
(▼ エイリアス作成完了)

エイリアスの作成完了後、画面を下の方にスクロールするとエイリアス情報が表示されています。
エージェントIDとエイリアスIDを覚えておく
この画面に表示されているエージェントIDとエイリアスID(↓画像の赤枠内のID)は後ほど使用しますので、メモしておくかこの画面を開いたままにしておきます。
(▼ エージェントID)

(▼ エイリアスID)

7. Lambdaから呼び出す
ここまで設定したら、Lambdaを作成してAPI呼び出しをしてみましょう。
Lambdaの画面を開き、「関数の作成」をクリックします。この時作成するリージョンを間違えないよう気をつけてください。Bedrockに合わせて バージニア北部 で作成します。
Lambdaの作成

Lambdaは「一から作成」を選択して、以下を設定します。
・関数名 - 設定したい関数名を入れます。
・ランタイム - Pythonを選択します。バージョンは最新で良いと思います。
・アーキテクチャ - おそらくどちらでも問題ないかと思います。今回はx86_64を選択しました。
・デフォルトの実行ロールの変更 - 「基本的な Lambda アクセス権限で新しいロールを作成」を選択。既存のロールを使用したい場合は選択します。
・詳細設定 - すべてチェックOFFでOK。
ここまで入力したら、「関数の作成」をクリックします。
(▼ Lambda画面)

関数が作成されたら、上のような画面が表示されます。
IAMの設定
コードを入力する前に、IAMの設定をしましょう。画面中ほどの「設定」タブを選択し、表示された設定タブで「アクセス権限」を選択します。
(▼ アクセス権限設定)

アクセス権限タブで、ロール名リンクをクリックしてIAMの画面を表示します。
(▼ IAM設定)

IAM画面に移動したら、許可ポリシー欄の「許可を追加」>「インラインポリシーを作成」をクリックします。
(▼ ポリシー編集)
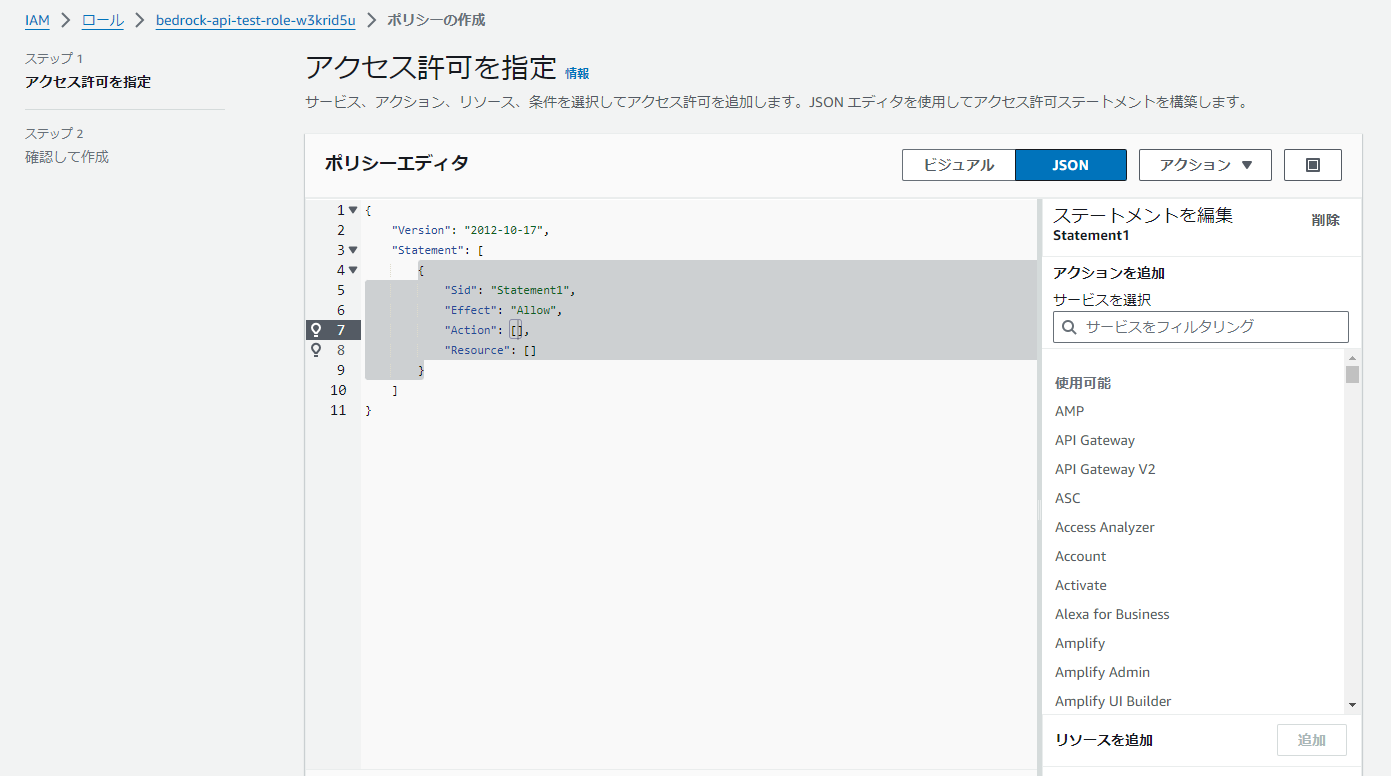
ポリシーエディタで、「JSON」を選択し、以下のポリシー情報をコピペします。
AWSアカウントIDは各自のものを入れてください。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "bedrock:InvokeAgent",
"Resource": "arn:aws:bedrock:us-east-1:[AWSアカウントID]:agent-alias/*/*"
}
]
}
ポリシー情報がコピペできたら、画面下の「次へ」をクリックします。
次の確認画面で、任意のポリシー名を入力して「ポリシーの作成」をクリックします。
(▼ Lambda画面でのポリシー確認)
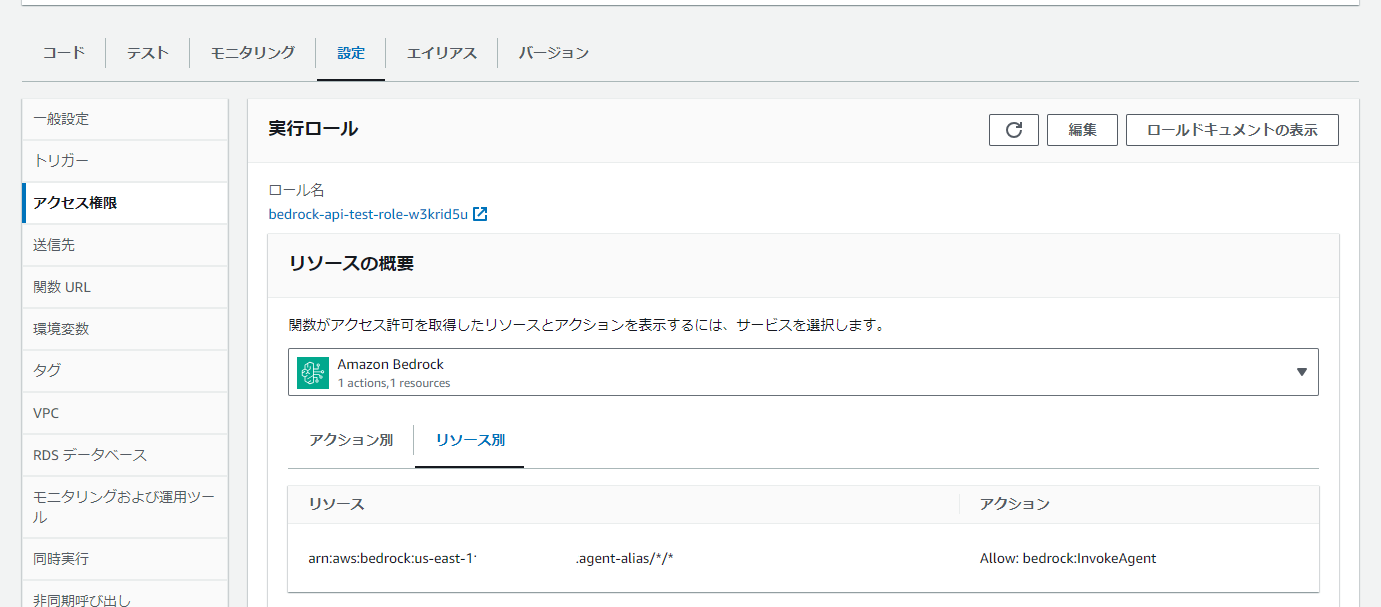
ポリシーが作成できたら、Lambda画面に戻って更新ボタンをクリックしてください。
正常に設定できていたら、実行ロールのリソースの概要にBedrockが追加されます。
タイムアウト値の設定
Bedrockの回答生成処理は3秒以上かかることがほとんどなので、Lambdaのデフォルトタイムアウトの3秒ではほぼ確実にエラーが起きます。そのため、タイムアウト値を変更します。
「設定」タブ > 「一般設定」を選択し、「編集」をクリックします。
(▼ 基本設定を編集)
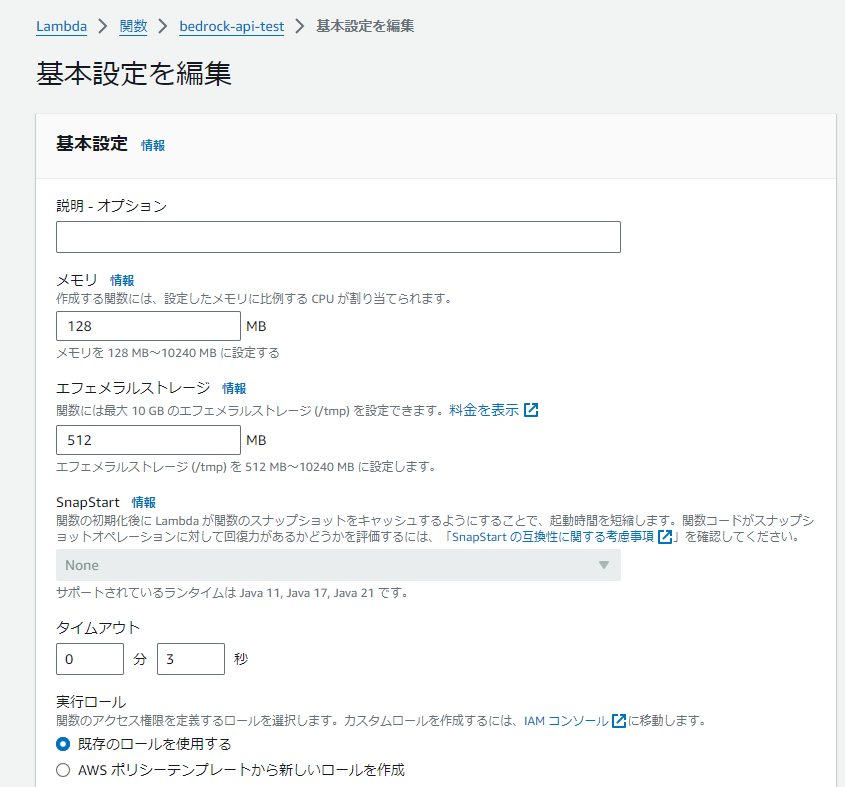
基本設定編集画面でタイムアウトを3分に設定し、「保存」をクリックします。
ソースコード
Lambdaの「コード」タブに戻って、ソースコードを設定します。
以下のソースコードに必要な情報を入れて、コードエディタにコピペしてください。
・[質問したい内容]:AIへの質問を入力する
・[エージェントID]:エージェント作成時にメモしたエージェントIDを入力する
・[エイリアスID]:エージェント作成時にメモしたエイリアスIDを入力する
import json
import uuid
import boto3
def lambda_handler(event, context):
try:
message = '[質問したい内容]'
agent_id:str = '[エージェントID]' # AgentのID
agent_alias_id:str = '[エイリアスID]' # AgentのAlias ID
session_id:str = str(uuid.uuid1()) # 乱数
# Clientの定義
client = boto3.client("bedrock-agent-runtime")
# Agentの実行
response = client.invoke_agent(
inputText=message,
agentId=agent_id,
agentAliasId=agent_alias_id,
sessionId=session_id,
enableTrace=False
)
# Agent実行結果の取得
event_stream = response['completion']
for event in event_stream:
if 'chunk' in event:
data = event['chunk']['bytes'].decode("utf-8")
# 結果を返す
return {
'statusCode' : 200,
'data' : {'answer' : data},
'completed' : 1
}
except:
import traceback
traceback.print_exc()
return {
'statusCode' : 200,
'completed' : 0
}
Lambdaの実行
ソースコードを入力したら、「Deploy」ボタンをクリックしデプロイします。
その後「Test」ボタンの横の▼を選択し、「Configure test event」をクリックします。
(▼ テストイベントを設定)
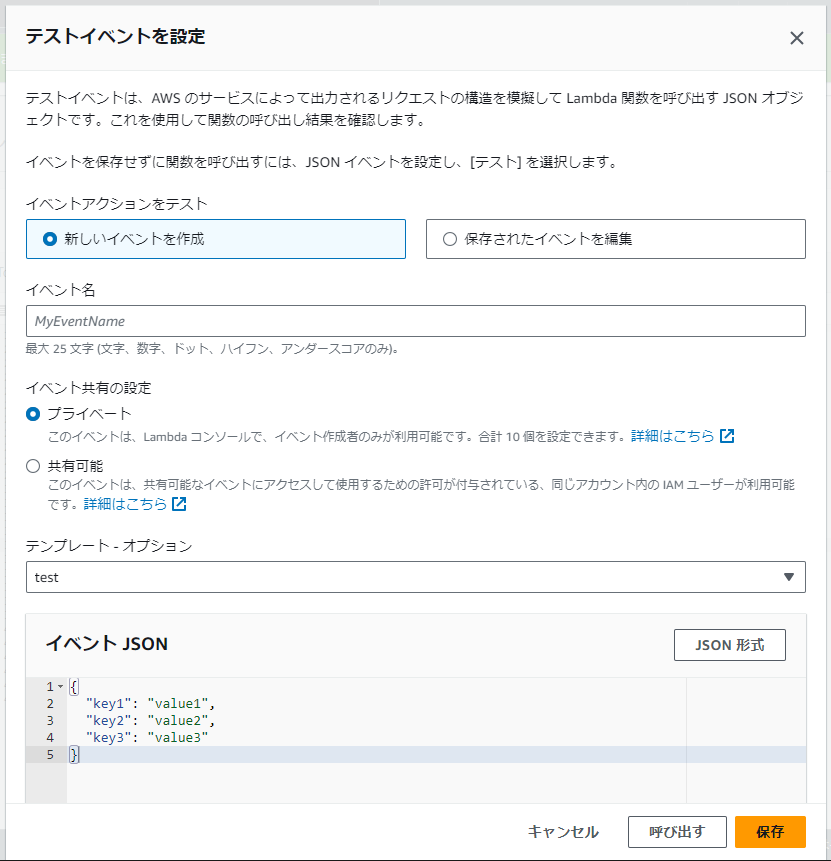
イベント名を入力して「保存」をクリックします。
イベント名は特にこだわりがなければtestでOK。
(▼ テスト実行)
テストイベントを保存したら、「Test」ボタンをクリックして実行完了を待ちます。
↓こんな感じで実行結果が表示されれば成功です!

これでBedrockでのRAG構築・API呼び出しをすることができました。
Lambdaから呼び出す際の質問を固定文字列で指定しましたが、ここをさらに外から指定するように変更すれば、外部アプリケーションからも呼び出せるようになります!
8.後片付け
作成したリソースの後片付けをします。
Lambdaなどは作成したままでも実行しなければ課金されないので問題ありませんが、Bedrockでナレッジベースを作成した際に裏でOpenSearch Serverlessのリソースが作成されています。 これが存在しているだけで1日5ドル以上の課金が発生する上にナレッジベース削除時に自動的に削除されない ので、今後使わない場合は忘れずに削除しておきましょう。
Lambdaの削除

関数の画面を表示して「アクション」>「関数の削除」で削除するか、Lambdaの関数一覧画面で該当の関数にチェックを入れ、「アクション」>「削除」で削除します。
Bedrockエージェントの削除

Bedrockのエージェント一覧画面で該当のエージェントのラジオボタンを選択し、「削除」ボタンをクリックします。確認画面が出るので"delete"を入力して削除実行します。エージェントのステータスが一旦Deletingになり、10秒ほどで削除されます。
Bedrockナレッジベースの削除

エージェントと同様、Bedrockのナレッジベース一覧画面で該当のナレッジベースのラジオボタンを選択して「削除」ボタンをクリックします。
(▼ ナレッジベース削除確認)
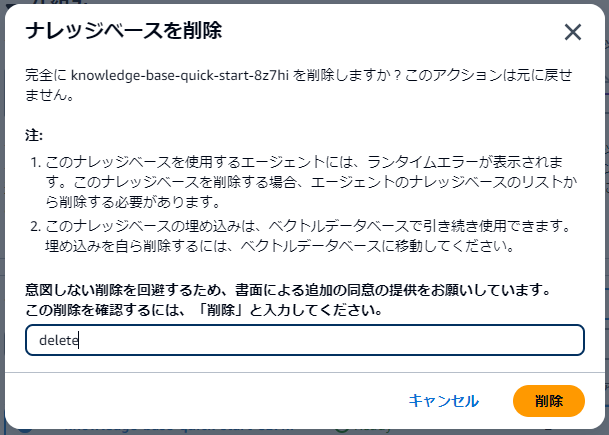
「削除」と入力してください。とあるのに、「delete」と入力しないと削除実行できません。こういうこともあります。。。
削除実行すると、数秒でナレッジベースが削除されます。
OpenSearch Serverlessの削除
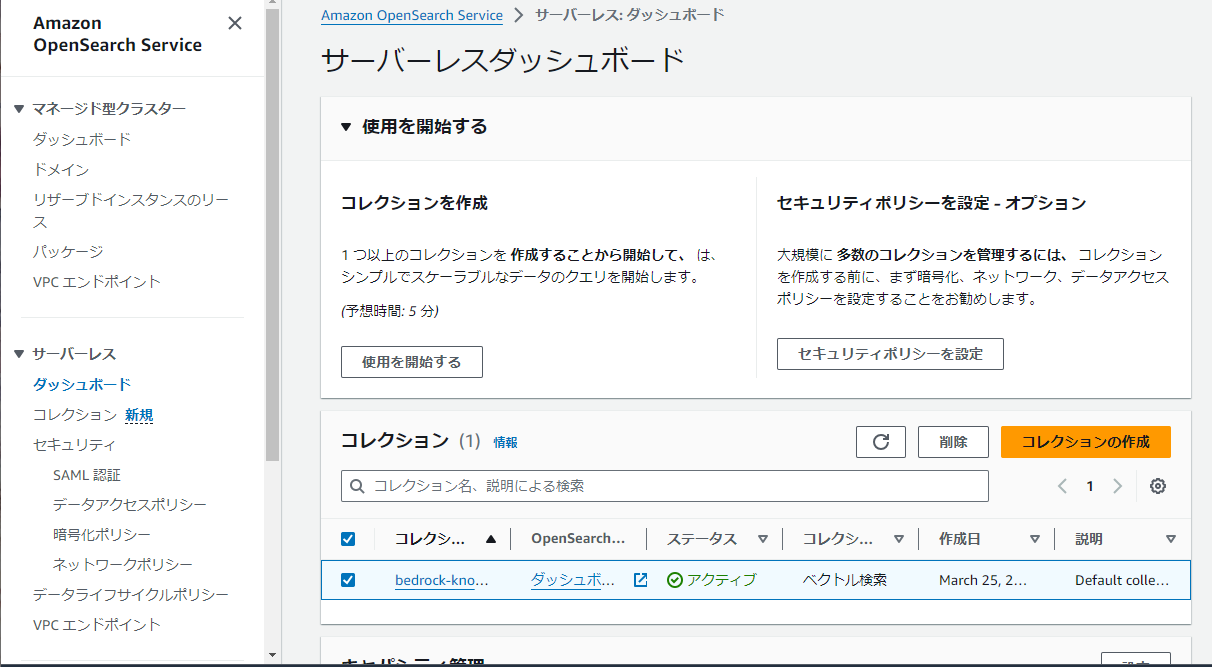
Amazon OpenSearch Serviceコンソールに移動し、サーバレスのダッシュボードもしくはコレクション画面を開きます。コレクション名が「bedrock-knowledge-base-[ランダム英字]」となっているコレクションにチェックを入れ、「削除」ボタンをクリックします。削除確認画面が表示されるので、「確認」と入力し削除実行します。
ステータスが「削除中」となるので、しばらく待って更新ボタンをクリックし、削除されていることを確認できればOKです。
IAMとCloudWatchロググループの削除
・LambdaのIAMロールはLambdaの関数名で検索して削除
・ナレッジベースののIAMロールは「AmazonBedrockExecutionRoleForKnowledgeBase_」で検索して削除
・エージェントのIAMロールは「AmazonBedrockExecutionRoleForAgents_」で検索して削除
・エージェントのIAMポリシーは「AmazonBedrockAgent」で検索して削除(2つあります)
・CloudWatchロググループはLambdaの関数名で検索して削除
ここまで完了すれば後片付けもOKです!