「 AWS には ChatGPT ないの ? 」そんな疑問に、バーでグラスを滑らせるように Amazon Bedrock をお送りします。 Amazon Bedrock は Web API 経由で様々な基盤モデルを扱える AWS のサービスです。特に、 Anthropic Claude は日本語においても ChatGPT と同等精度であることが各種リーダーボードで示唆されています (Rakuda Ranking, Nejumi Leaderboard) 。
Anthropic Claude 、 また Amazon の基盤モデルである Titan だけでなく、 AI21 Labs 、 Cohere 、 Meta 、 Stability AI といった先進的なスタートアップが開発したモデルが選択できる「品揃え」、そして AWS の基盤に支えられたセキュリティ、安定性、そしてコスト効率の良さが Amazon Bedrock の特徴です。

本記事では、 Amazon Bedrock を始める方法を 1) 準備 2) 利用 3) 監視 4) 応用、の 4 ステップでご紹介しようと思います。スライドで見たい方は Amazon Bedrock のはじめ方 をご参照ください。
1. Amazon Bedrock の準備
Amazon Bedrock を利用できるように準備します。このセクションの手順を終えると、次の図のように AWS Console 上で基盤モデルの返答を試すことができます。

Amazon Bedrock を利用開始する手順を次に示します。なお、リージョンにより利用可能なモデルが異なります。東京リージョンでも日本語が扱える Claude は利用できます。すべて利用したい場合は us-east-1 や us-west-2 がお勧めです。
| スクリーンショット | 操作 | |
|---|---|---|
| 1 | 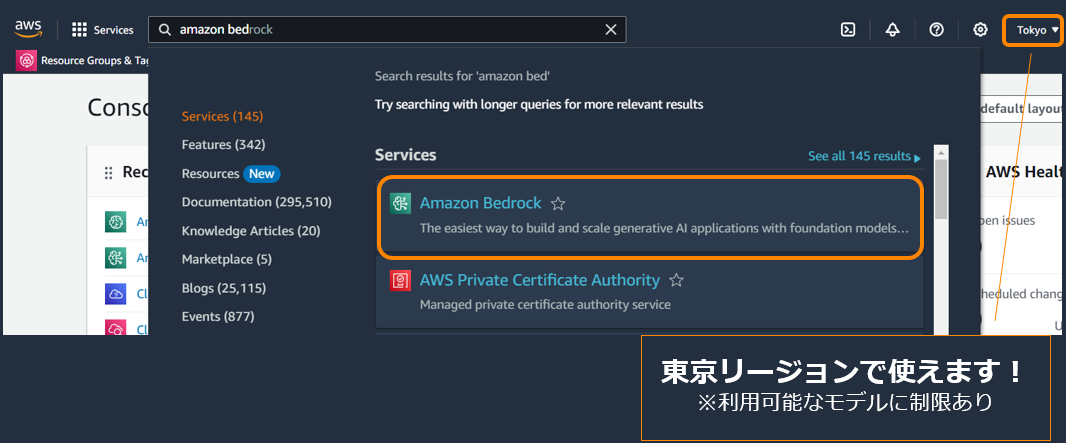 |
AWS Console の検索バーで "Amazon Bedrock" を入力し、 Services のリストから Amazon Bedrock の画面に遷移。 |
| 2 |  |
"Get started" をクリック。 |
| 3 | 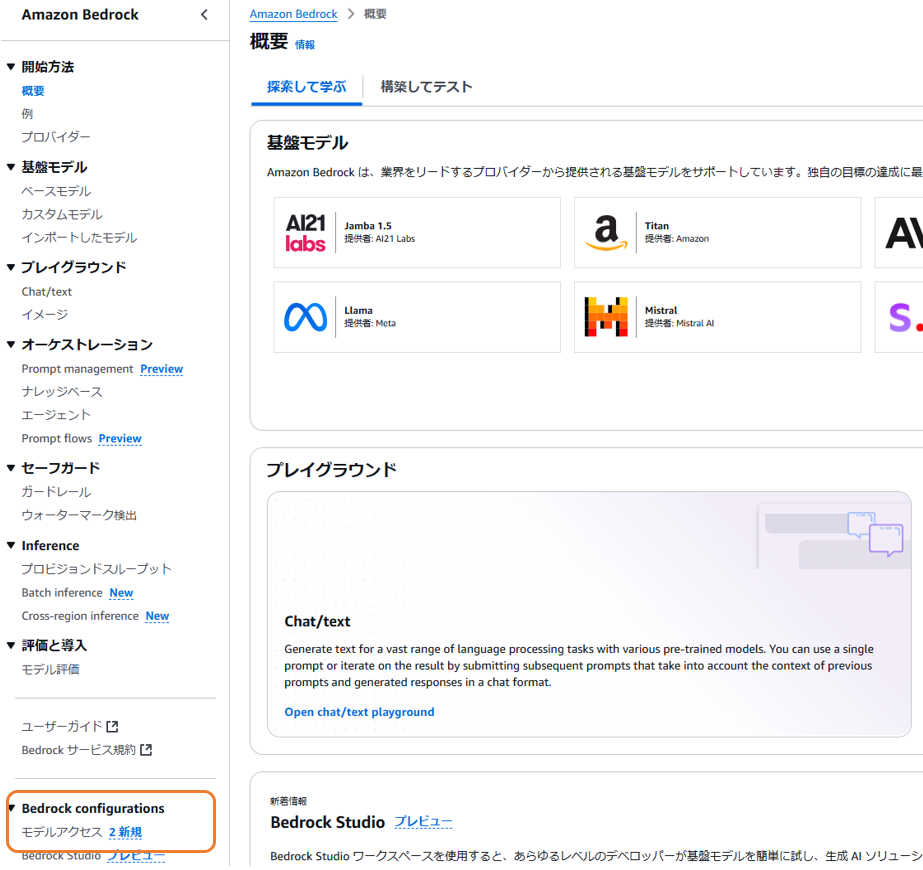 |
左側のメニューから "Model Access" を選択。 |
| 4 | 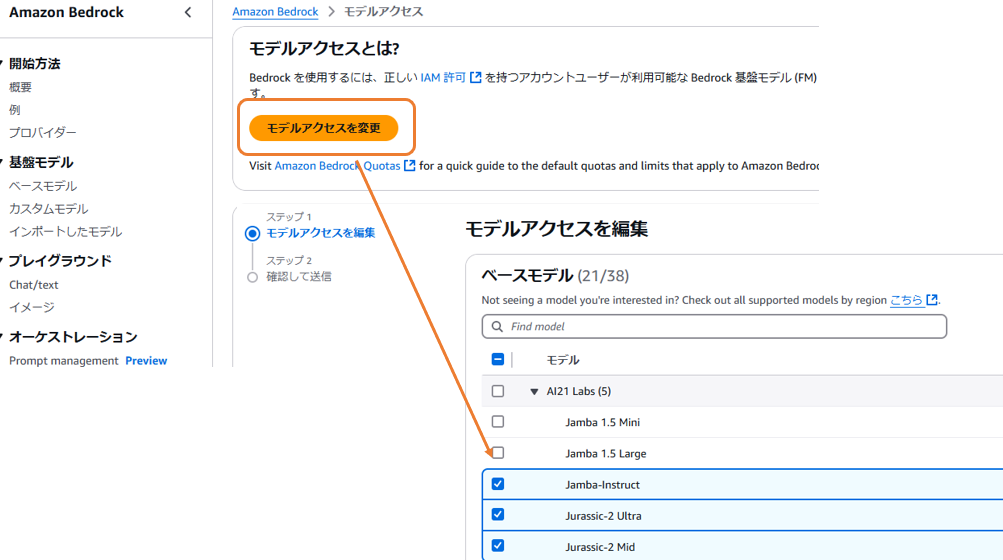 |
利用したいモデルのチェックボックスをクリック。 |
| 5 | 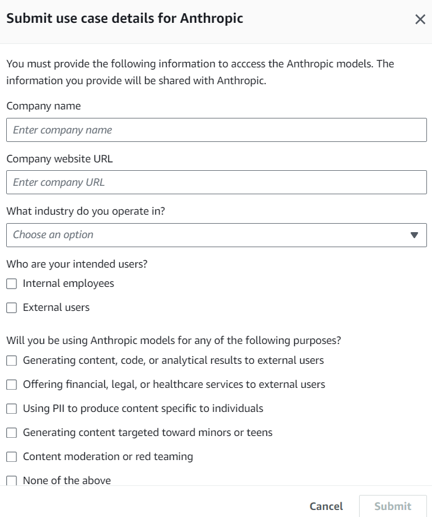 |
(現在は不要?) "Submit use case details" が必要な場合、申請。会社での使用を前提としたフォームになっているので、所属の会社の情報を入力。社内検証用の建付けであれば Internal employees を選択、ユースケースについては検証したい内容を記載 ( 日本語で書いて Amazon Translate で英訳すると楽 ) 。申請が通るまでしばらく待つ。 |
| 6 | 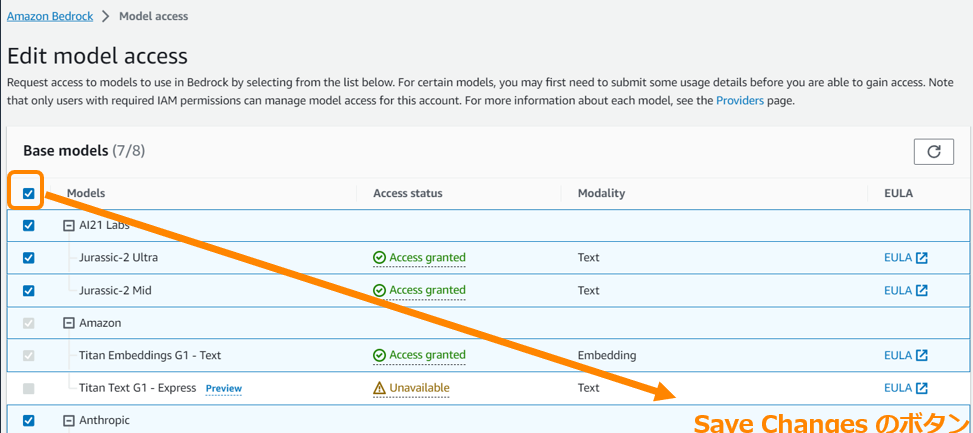 |
使いたいモデルをチェックし終えたら、「次へ」を押下すると確認画面へ遷移し、送信するとモデルアクセスが有効化される。 |
| 7 | 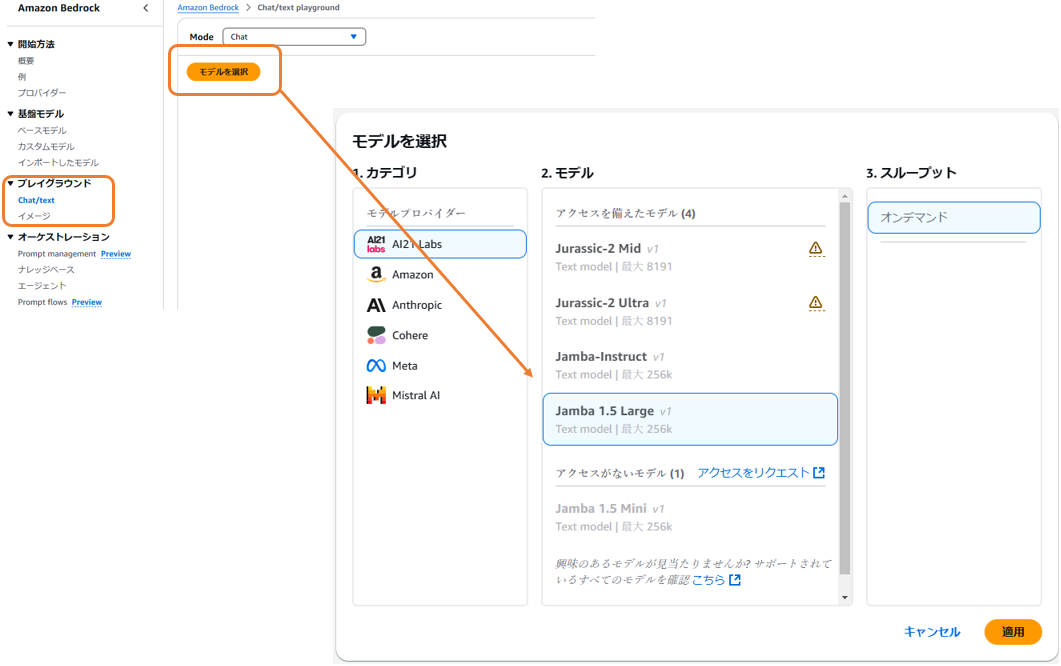 |
Playground のメニューからモデルを利用する。 |
SageMaker Studio から利用したい場合、 SageMaker Domain の利用している Execution role に Amazon Bedrock へのアクセス権限が必要です。
| スクリーンショット | 操作 | |
|---|---|---|
| a | 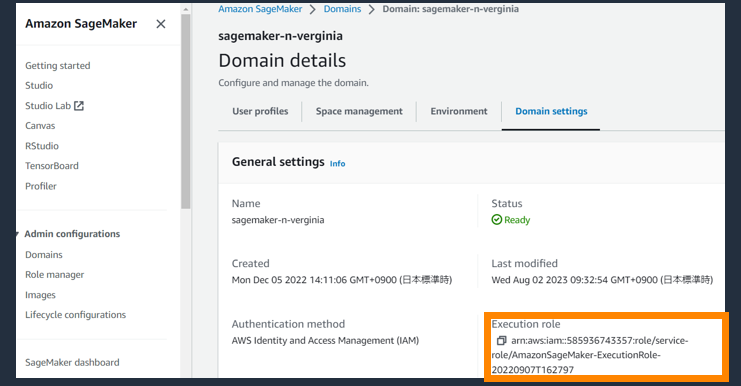 |
SageMaker Domain の settings から Execution role を特定 |
| b | 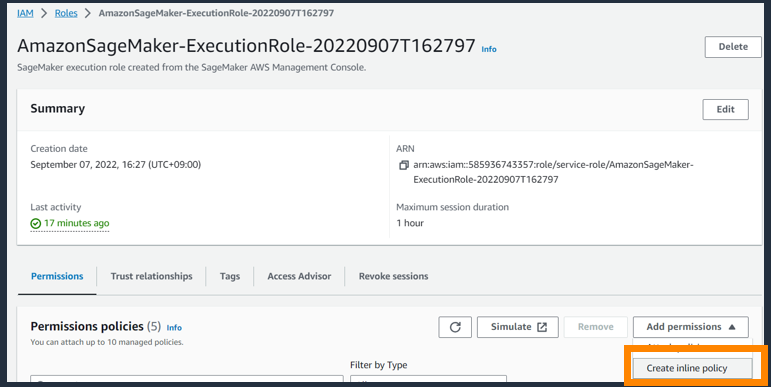 |
IAM ロールの画面で Execution role を検索し、Create inline policy を実行 |
| c | 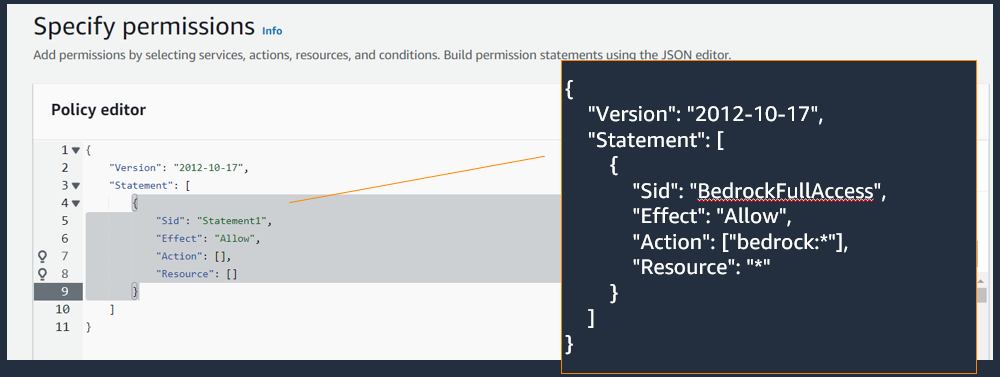 |
JSON を選択し ( ※ 1) のポリシーを貼り付け |
※ 1 : 貼り付けるポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockFullAccess",
"Effect": "Allow",
"Action": ["bedrock:*"],
"Resource": "*"
}
]
}
CLI や SDK などから使うロールを作る時も、上記のポリシーを参考にしていただければと思います。
これで準備は万端です。
2. Amazon Bedrock の利用
Amazon Bedrock は AWS Console 上の Playground やプログラムから呼び出す AWS SDK から利用できます。
2.1 Playground
| スクリーンショット | 操作 | |
|---|---|---|
| 1 | 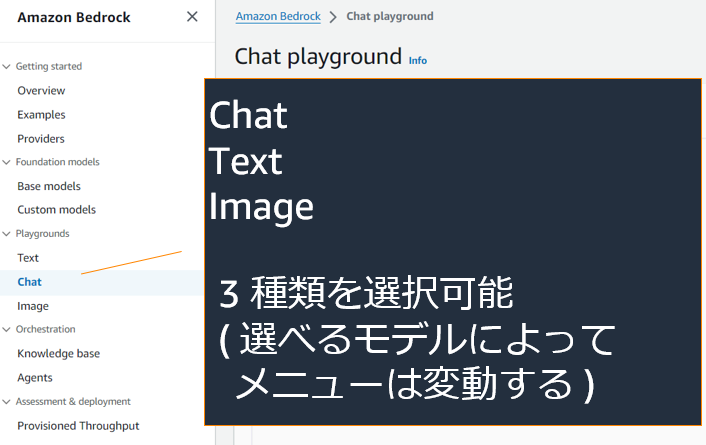 |
左側のメニューから Text / Chat / Image のいずれかを選択。今回は Chat を選択します。 |
| 2 | 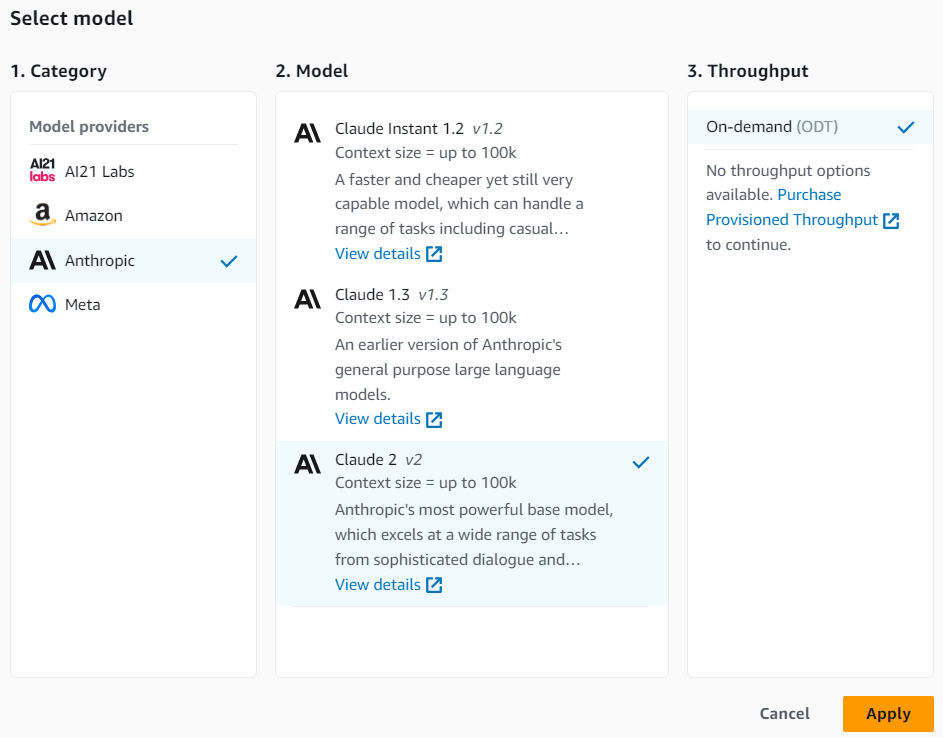 |
Playground で使用するモデルを選択。 |
| 3 | 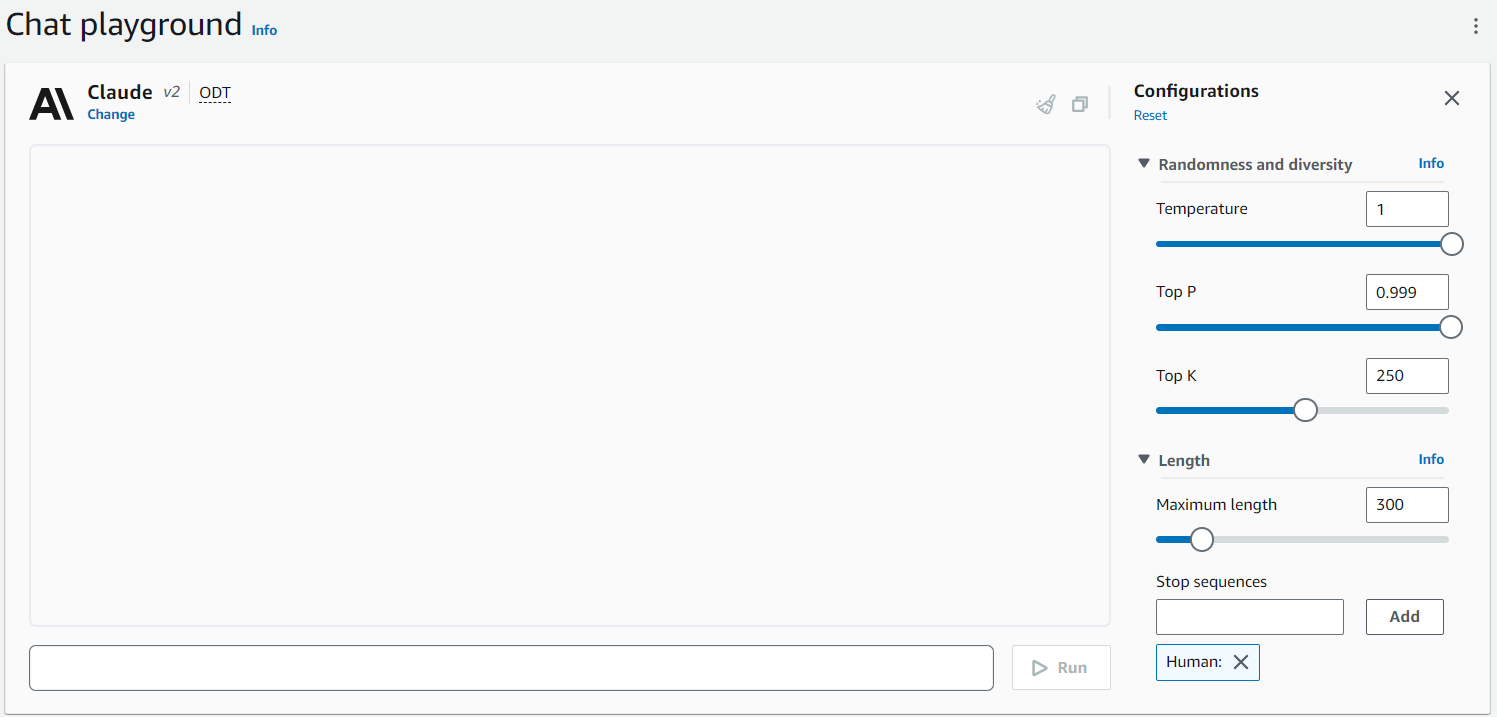 |
ハイパーパラメーターを設定し、モデルと Chat する ( パラメーターについては下記を参照 ) 。 |
推論時に設定できるパラメーターについて簡単に解説します。モデルによって設定できるパラメーターが異なるので、詳細はドキュメントを参照ください ( 例 : Anthropic Claude のドキュメント ) 。
- Temperature: 低いほど確実な単語のみ採用する
- Top P: 出現確率が高い順に並べ合計 P になるまで採用
- Top K: 出現確率が高い上位 N 個から採用する
- Length: 出力長を制限
- Stop sequences: この文字列が出たら生成を停止する
Anthropic Claude は Human / Assistant の会話形式でやり取りするので、人間側の発話の頭につける "Human:" が出てきたら止めるよう指定しています。
Text を使うと対話形式にこだわらず入力したテキストに続くテキストを作成させることができます。次の図は、左図で入力したテキストの続きが右図で生成されています ( 緑のテキストの箇所 ) 。
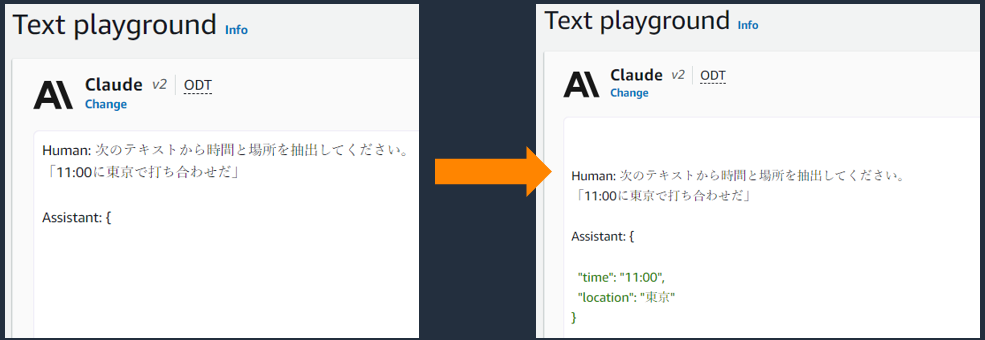
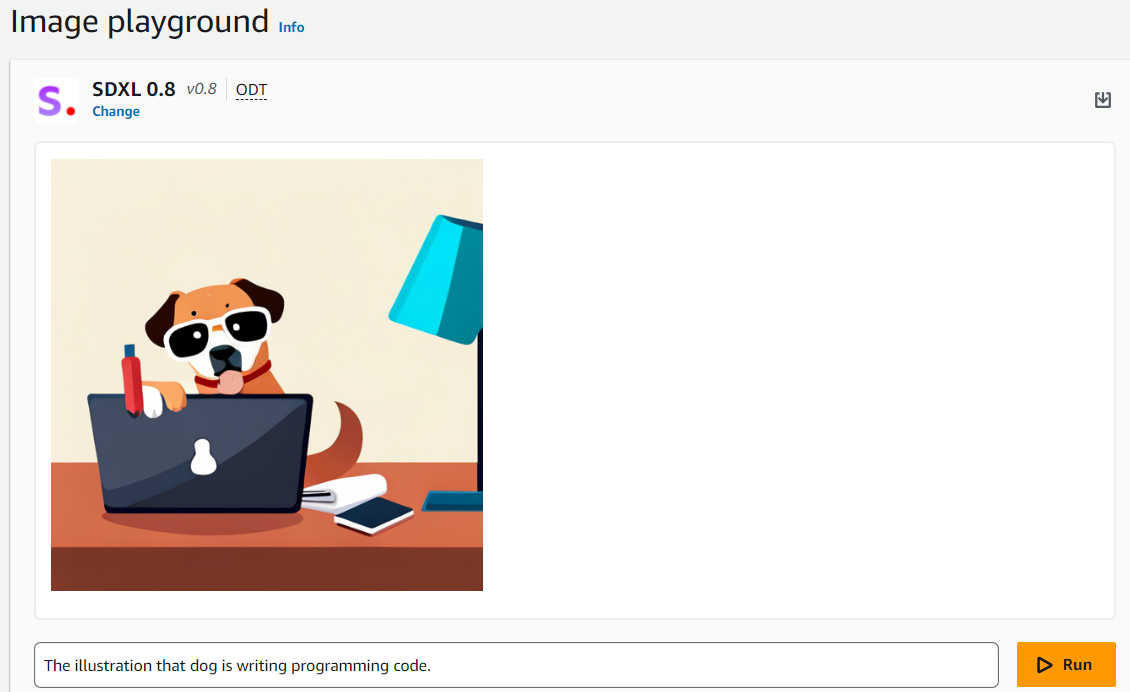
Image では入力したテキストから画像が生成できます。
2.2 Bedrock API
CLI や SDK から API を呼び出すことで Bedrock を使うこともできます。 Bedrock には使える基盤モデルの情報を得たりカスタマイズするための Bedrock API と推論を実行するための Bedrock Runtime API の 2 種類があります。後者は現時点で invoke-model しかできません。 使えるモデルを Bedrock API で確認、実際に推論するには Bedrock Runtime API を呼び出す流れになります。
Bedrock API で、特定リージョンで使えるモデルを確認するための Python コードの例を示します。前述の Amazon SageMaker Studio で使うためのセットアップをしたうえで動作確認をしています。
import boto3
bedrock = boto3.client(service_name='bedrock', region_name='us-east-1')
bedrock.list_foundation_models()
AWS CLI の場合次のコマンドになります
aws bedrock list-foundation-models --region us-east-1
Bedrock Runtime API で、モデルを使った推論をするための Python コードの例を示します。
import boto3
import json
brt = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
body = json.dumps({
"prompt": "\n\n Human: カレーの作り方を教えてください。\n\nAssistant:",
"max_tokens_to_sample": 300,
"temperature": 0.1,
"top_p": 0.9,
})
modelId = 'anthropic.claude-v2'
accept = 'application/json'
contentType = 'application/json'
response = brt.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read())
# text
print(response_body.get('completion'))
出力は↓のような感じになります。
はい、カレーの簡単な作り方を説明します。
材料(2人分)
- 牛肉または鶏肉 100g
- 玉ねぎ 1/2個
- カレールウ 50g
- カレー粉 大さじ1
- ガーリックミンチ 1/2小さじ
- トマトケチャップ 大さじ1
- 牛乳 大さじ2
- 塩コショウ 適量
作り方
1. 肉は適当な大きさに切る
2. 玉ねぎはみじん切りにする
3. フライパンに油を熱し、玉ねぎを炒める
4. 肉とガーリックミンチを加えて炒める
5. カレールウとカレー粉を入れてさらに炒める
6. トマトケチャップと牛乳を加え、水
AWS CLI の場合次のコマンドになります (AWS CLI v2 の場合、テキストが base64 でエンコードされるので -cli-binary-format raw-in-base64-out \ の指定が必要です ) 。 AWS CLI
aws bedrock-runtime invoke-model \
--model-id anthropic.claude-v2 \
--body "{\"prompt\": \"\n\nHuman: 肉じゃがの作り方を教えて\n\nAssistant:\", \"max_tokens_to_sample\" : 1024}" \
invoke-model-output.txt
invoke-model-output.txt に返却された JSON データが保存されます。
2.3 LangChain
LangChain から Bedrock を使うこともできます。公式ドキュメントの例がわかりやすいです。
from langchain.llms import Bedrock
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
llm = Bedrock(
model_id="anthropic.claude-v2"
)
conversation = ConversationChain(
llm=llm, verbose=True, memory=ConversationBufferMemory()
)
conversation.predict(input="Hi there!")
2.4 Anthropic SDK
Anthropic オフィシャルの SDK からも Bedrock を呼び出すことができます。公式ドキュメントの Amazon Bedrock API から使い方を確認できます。
import anthropic_bedrock
from anthropic_bedrock import AnthropicBedrock
client = AnthropicBedrock(
aws_region="us-east-1",
)
completion = client.completions.create(
model="anthropic.claude-v2",
max_tokens_to_sample=256,
prompt=f"{anthropic_bedrock.HUMAN_PROMPT} トンカツの作り方を教えて {anthropic_bedrock.AI_PROMPT}",
)
print(completion.completion)
2.5 Cohere AWS
Cohere からも AWS 専用の SDK が公開されています。 Cohere のモデルは AWS Marketplace で販売されているので、 Bedrock 以外に SageMaker にホスティングしたモデルの推論、 Fine Tuning を行う API も用意されています。次のコードは Bedrock を使って推論する例です。詳細は cohere-aws を参照ください。
import cohere_aws
co = cohere_aws.Client(mode=cohere_aws.Mode.BEDROCK, region_name='us-east-1')
prompt = "Write a LinkedIn post about starting a career in tech:"
response = co.generate(prompt=prompt, max_tokens=50, temperature=0.9,
return_likelihoods='GENERATION', model_id='cohere.command-text-v14', stream=False)
print(response.generations[0]['text'])
3. Amazon Bedrock の利用状況を監視する
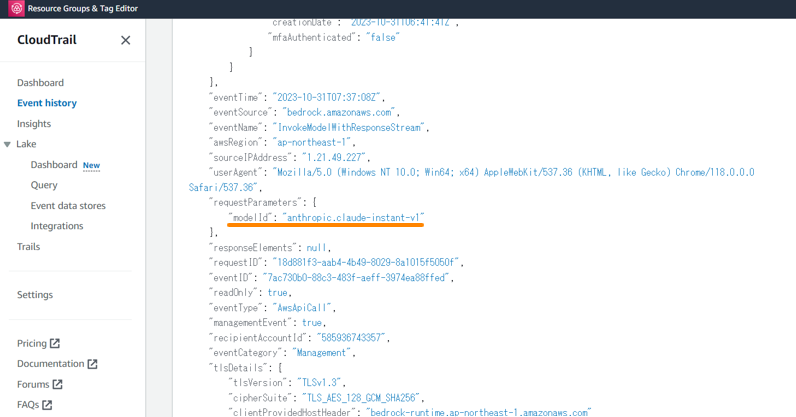
基盤モデルにどんな入力がされていて、どんな出力がユーザーの手元に入っているか、モニタリングしたいこともあると思います。まず、モデルの呼び出し (InvokeModel / InvokeModelWithResponseStream) は CloudTrail に記録されます。そのため、どのモデルがいつ呼び出されたのかは監視ができます。
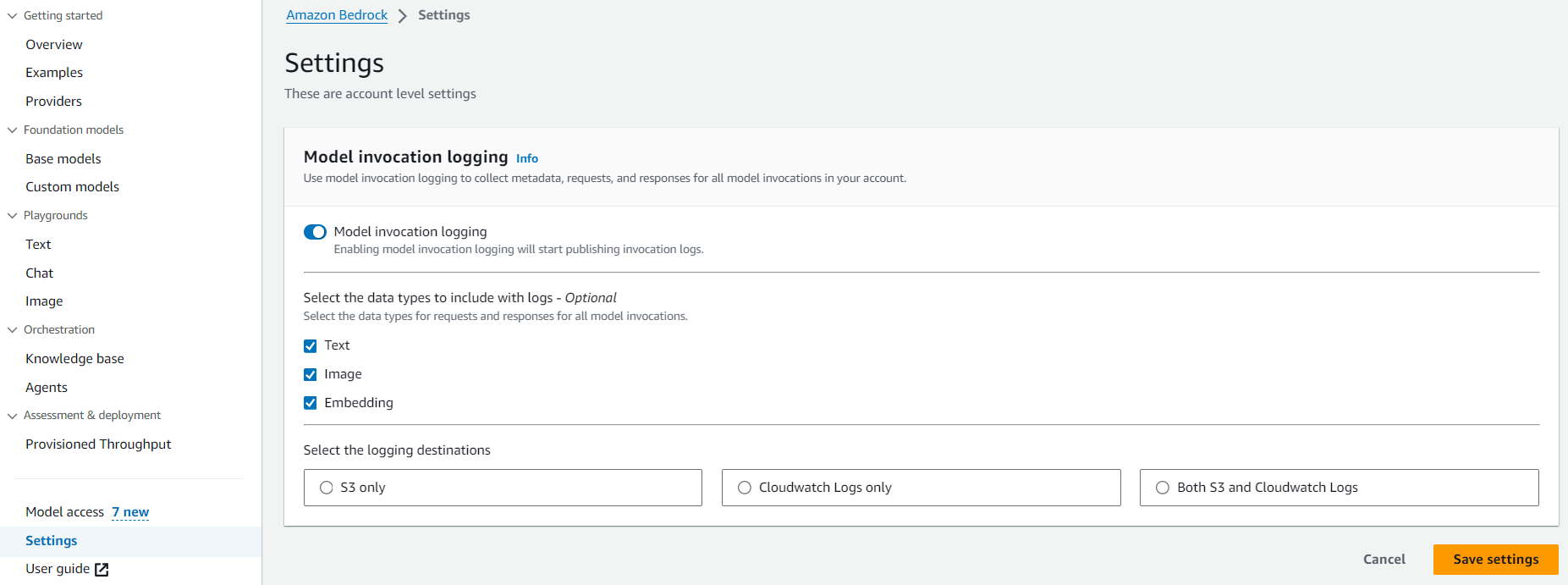
具体的なプロンプトの中身を記録する場合は Settings から Model invocation logging をオンにする必要があります。 Amazon S3 か CloudWatch 、もしくは両方にログを保存することができます。
ここでは、入力したプロンプト、出力された回答、またハイパーパラメーターを参照することができます。

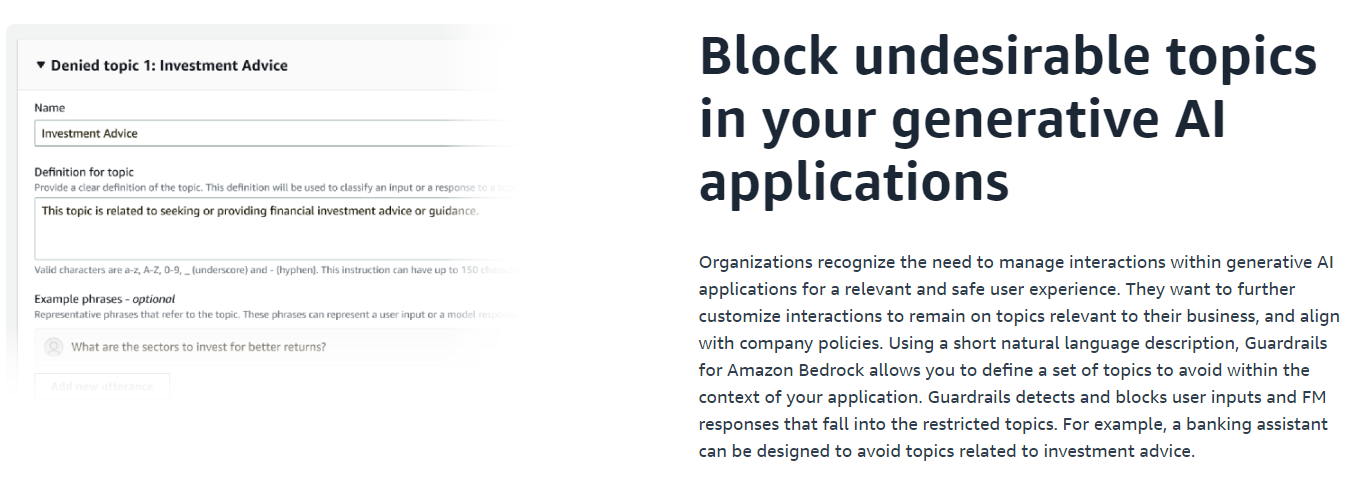
3.1 不適切な使用をブロックする : Guardrails for Amazon Bedrock (Preview)
監視していて不適切な利用を発見し、そうした利用をブロックしたいことがあると思います。 2023/12 時点では Preview ですが、そのための機能として Guardrails for Amazon Bedrock があります。特定のトピックに対する回答を制限したり、いわゆるコンテンツフィルターの機能を提供するようです。
3.2 上限を緩和する : Provisioned Throughput
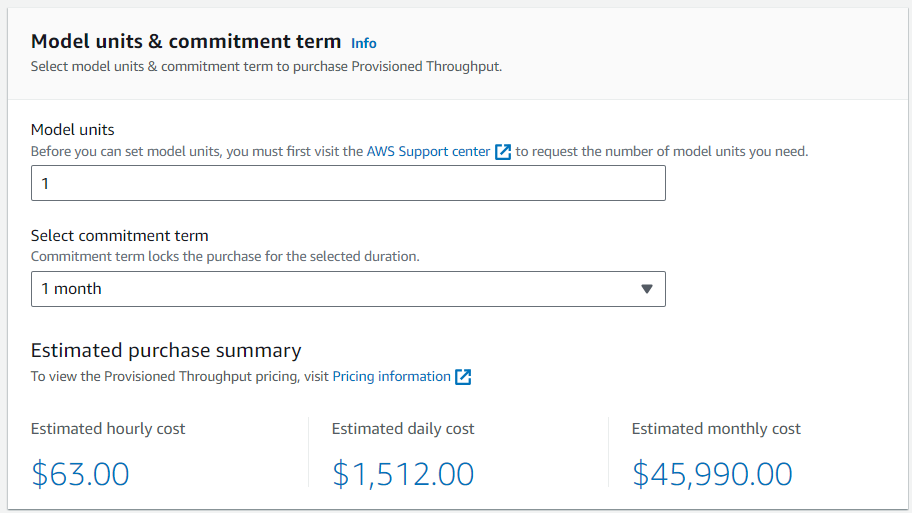
Amazon Bedrock には Quota が設定されており、上限を超える利用ははじかれてしまいます。
モニタリングの結果、上限に触れることが多い場合 Provisioned Throughput の購入が選択肢になります。 Provisioned Throughput は、時間単位課金のユニットで、 input token の処理か output token の処理に適用し処理できる量を増やすことができます (input と output 両方の処理量を上げたい場合、 2 つ必要になります ) 。ユニットは、利用期間が長いほどディスカウントされるようになっています。
3.3 モデルをチューニングする : Fine Tuning
モデルの監視をしていて、うまく返答できていない傾向が見えることもあるでしょう。モデルに対する入出力データを蓄積しておくことで、モデルの挙動を調整する Fine Tuning に利用できます。 2023/11 時点でチューニングできるのは Amazon Titan のみですが、 Fine Tuning 、あるいはドメイン知識を新たに追加するための Continuout Pre-training を簡単に実行することができます。インプットデータを S3 に置き、ハイパーパラメーターを設定するだけで実行できます。
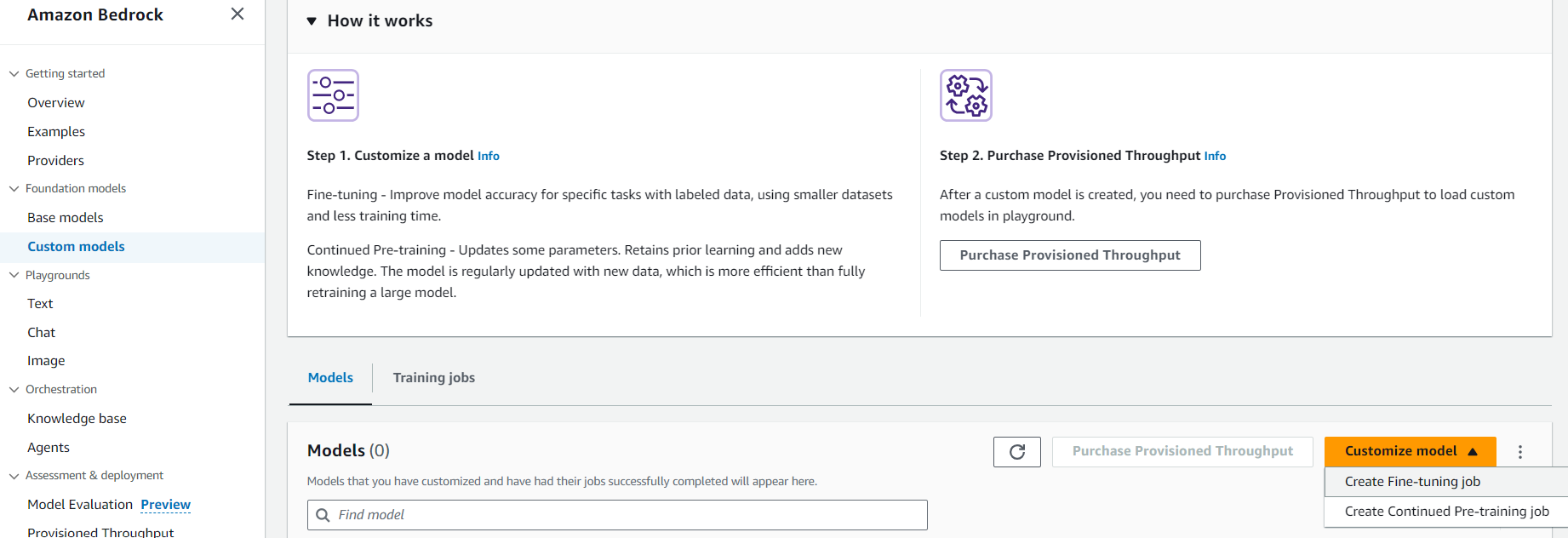
チューニングしたモデルを利用する際は、先の Provisioned Throughput を購入する必要がある点に注意してください。
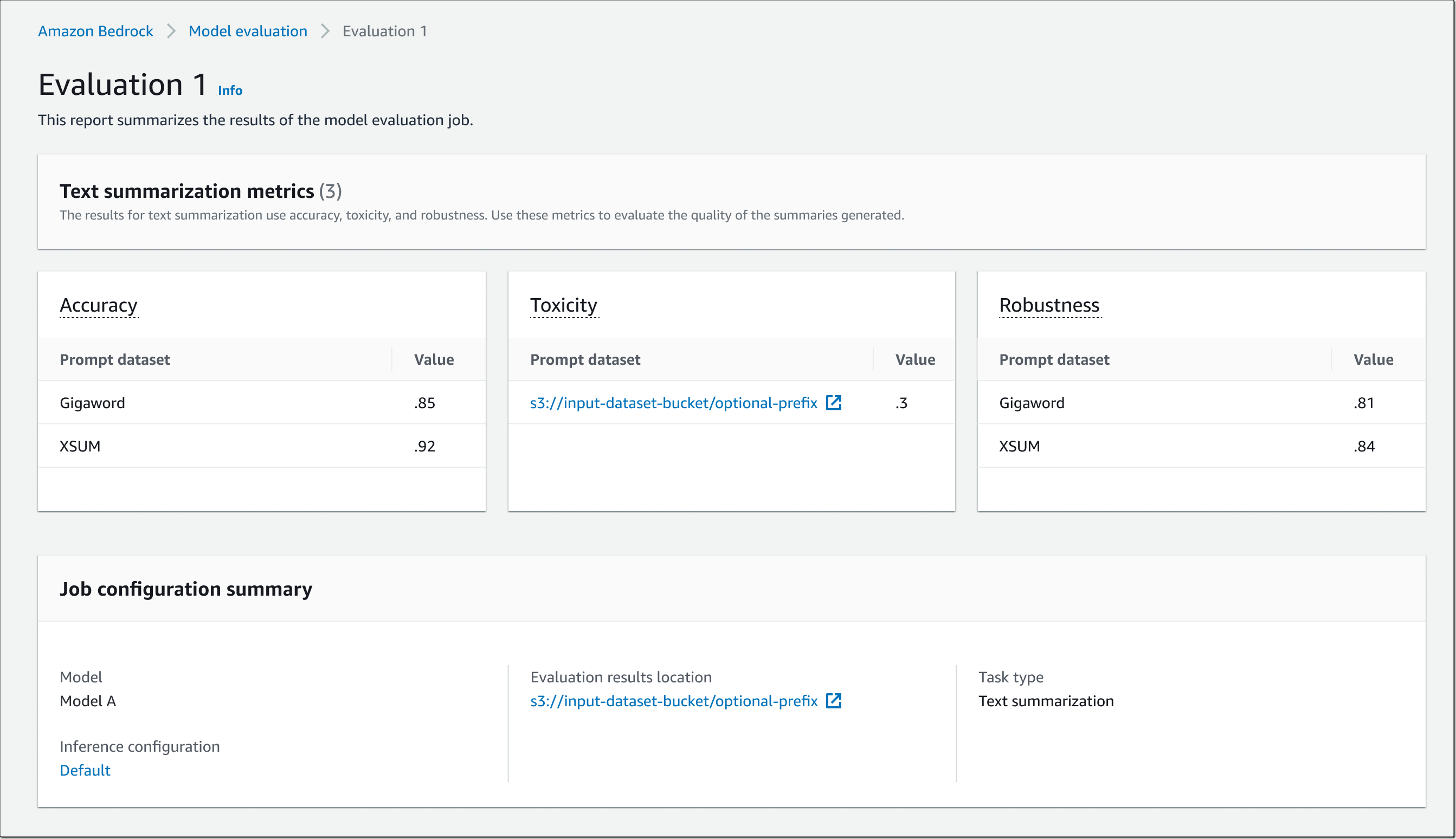
3.4 モデルの性能を評価する : Evaluation (Preview)
チューニングしたモデルがデプロイしても問題ないかどうか、事前に評価したいものです。 Amazon Bedrock では Model evaluation の機能が提供されています。自動評価か、人手評価の 2 種類を選択できます。自動評価の場合、要約などのタスクを選択しビルトイン、もしくは自前のデータセットで評価します。人手評価の場合、自前のチームか AWS にお願いして人を集めてデータセットに対し評価ができます。結果はいずれもコンソールから見ることができます。
| 自動評価 | 人手評価 |
|---|---|
 |
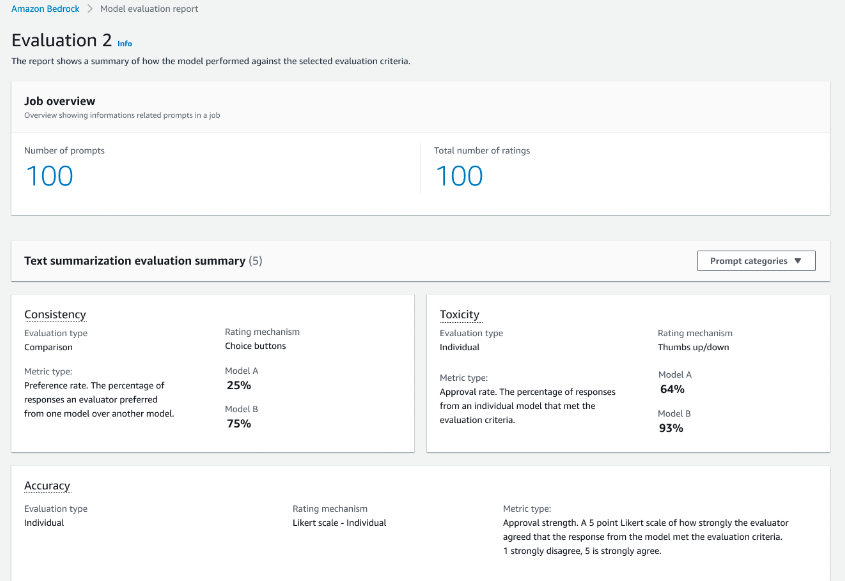 |
詳細は次のブログを参照してください。
4. Amazon Bedrock を応用しアプリケーションを作る
AWS では、 Amazon Bedrock で使える基盤モデルを素材として、プロセスやアプリケーションを構築する方法をいくつか提供しています。
4.1 Agents for Amazon Bedrock
Agents for Amazon Bedrock を使うことで、基盤モデルを旗振り役として適切なバックエンド処理を呼び出すアプリケーションを作成できます。バックエンド処理はプログラム処理か検索を設定できます。プログラム処理は、 OpenAPI 形式で定義し処理の実態を AWS Lambda で実装します。検索は Knowledge base で作成し、実体はベクトル検索エンジン ( デフォルトでは OpenSearch Serverless ) になります。次の図はドキュメントに掲載されている処理フローです。

今回は、 Knowledge base を使用し、与えた知識に基づき回答してくれるエージェントを作成してみます。
| スクリーンショット | 操作 | |
|---|---|---|
| 1 | 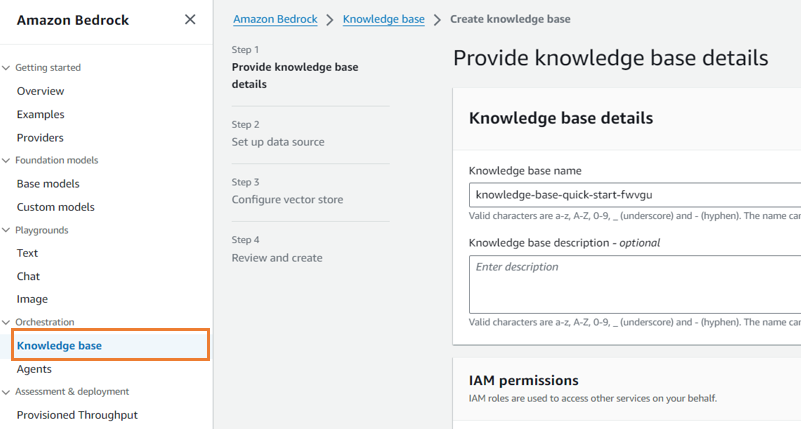 |
メニューから "Knowledge base" を選択。データソースとなる Amazon S3 を選択するだけで作成できます。ベクトル表現には Amazon Titan 、ベクトル検索には OpenSearch Serverless がデフォルトでは選択されます。 |
| 2 | 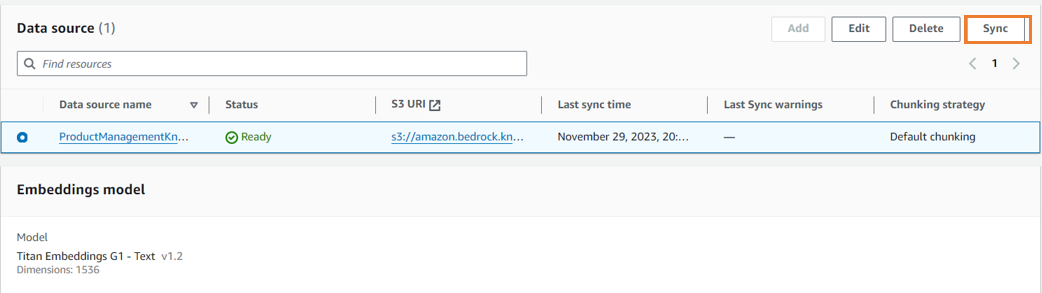 |
Knowledge base を作成後、 Data source の Sync を実施 ( これを実施しないと、インデックスが作成されません ) 。 |
| 3 | 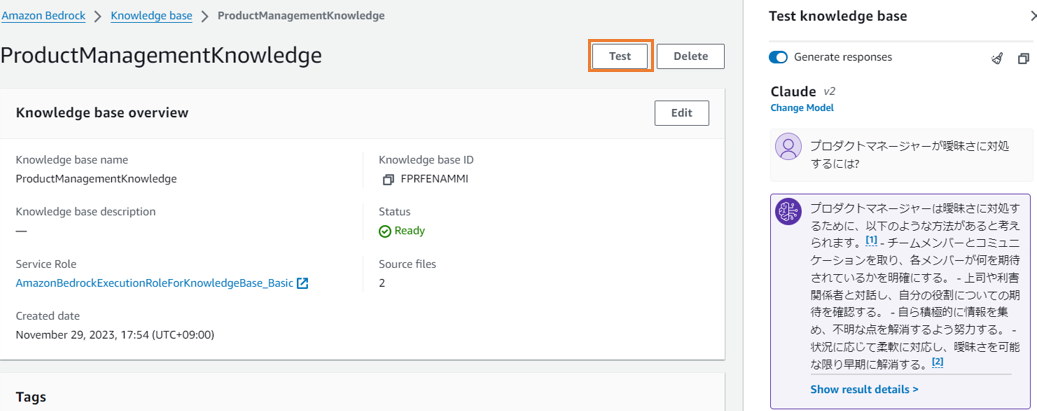 |
Knowledge base の段階でテストを実施。 Amazon S3 に保管したドキュメントに関する質問をしてみてください。きちんと引用した答えが返ってきたら正常にインデックスが作成できています。 |
| 4 |  |
メニューから "Agent" を選択。 |
| 5 |  |
Add Action Groups はスキップし、作成した Knowledge base を選択。 |
| 6 | 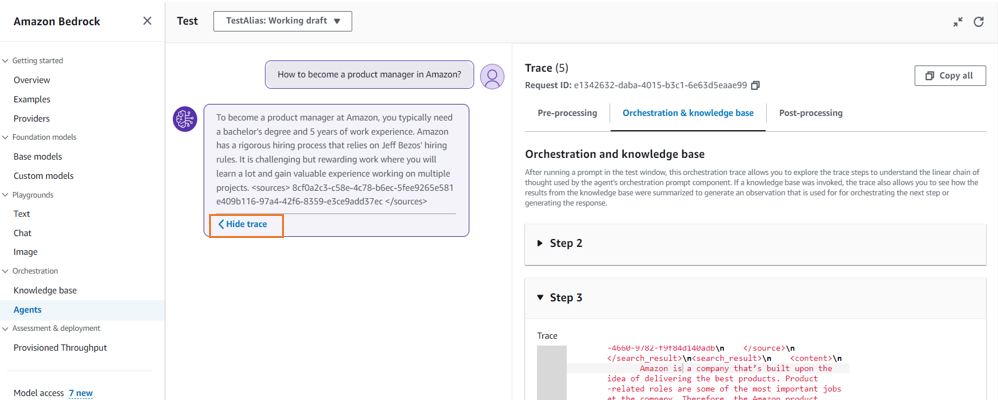 |
Knowledge base と同様にテストする。 Agent の返答の末尾にある "Show trace" を押すことで、エージェントがどのようなプロンプトで問い合わせたのか、どんな検索結果が帰ってきたのか参照できる。 |
Action Group 、 AWS Lambda を使った Agent は Where Are You Christmas? At Agents for Amazon Bedrock! 世界最速(?) Agent for Amazon Bedrock デモ で解説しています。
なお、 Knowledge base を削除しても Vector Store は消えない点に注意してください。
4.2 AWS Step Functions
AWS Step Functions からも Amazon Bedrock のイベントが呼べるようになりました。詳細は Build generative AI apps using AWS Step Functions and Amazon Bedrock で紹介されています。今回は AWS Lambda でプロンプトを作成して Amazon Bedrock で生成した結果を Amazon S3 に保存する Step Function を作成してみます。 2023/12/1 時点では、 Amazon Bedrock への入出力は Amazon S3 を経由する必要があります。
| スクリーンショット | 操作 | |
|---|---|---|
| 1 |  |
プロンプトを生成し S3 に保存する AWS Lambda を作成。今回は Anthropic Claude 用のプロンプトを作成しました。サンプルコードは ( ※ 1 を参照してください) |
| 2 | 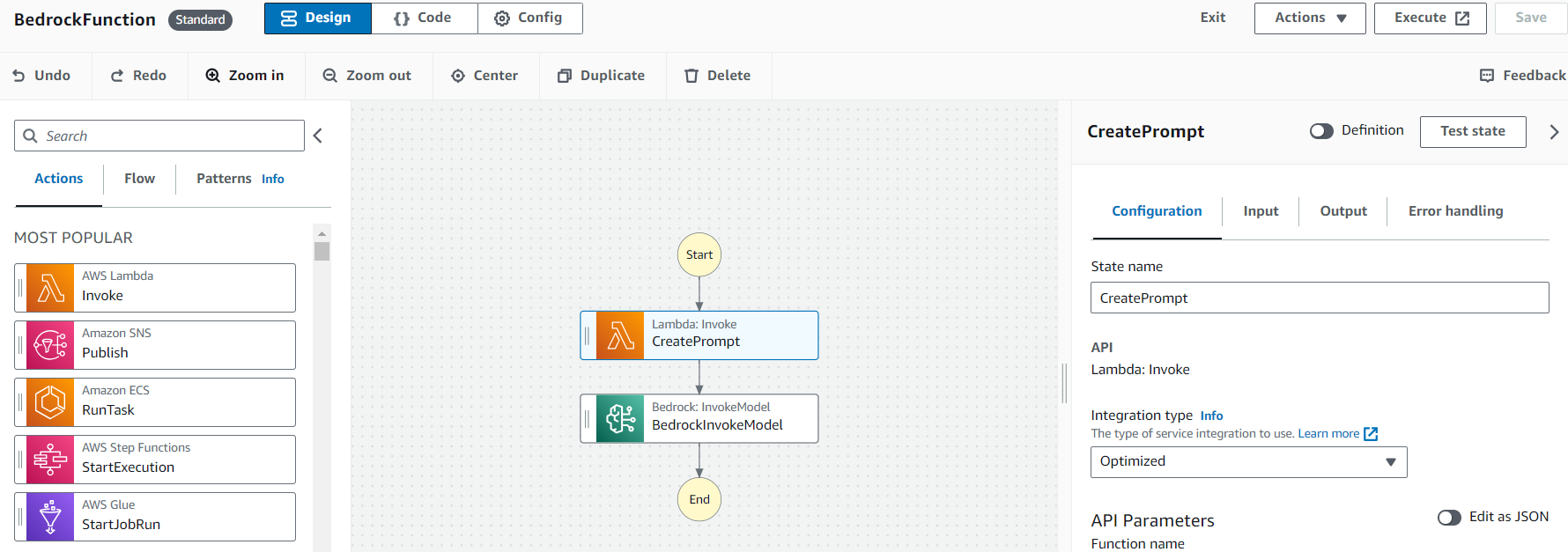 |
StepFunction を作成。先ほど作成した AWS Lambda と BedrockInvokeModel をつないだ Function を作成しました。 BedrockInvokeModel の Configuration では、 Bedrock Model Parameters で入力となる S3 のパスと出力となる S3 のパスを設定します。 |
| 3 | 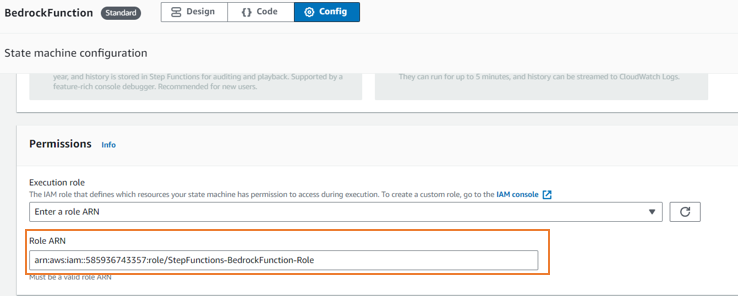 |
StepFunction を保存。私の場合、ロールの作成がうまくいかなかったので必要な権限をつけたロールを自前で作成しました。 |
| 4 | 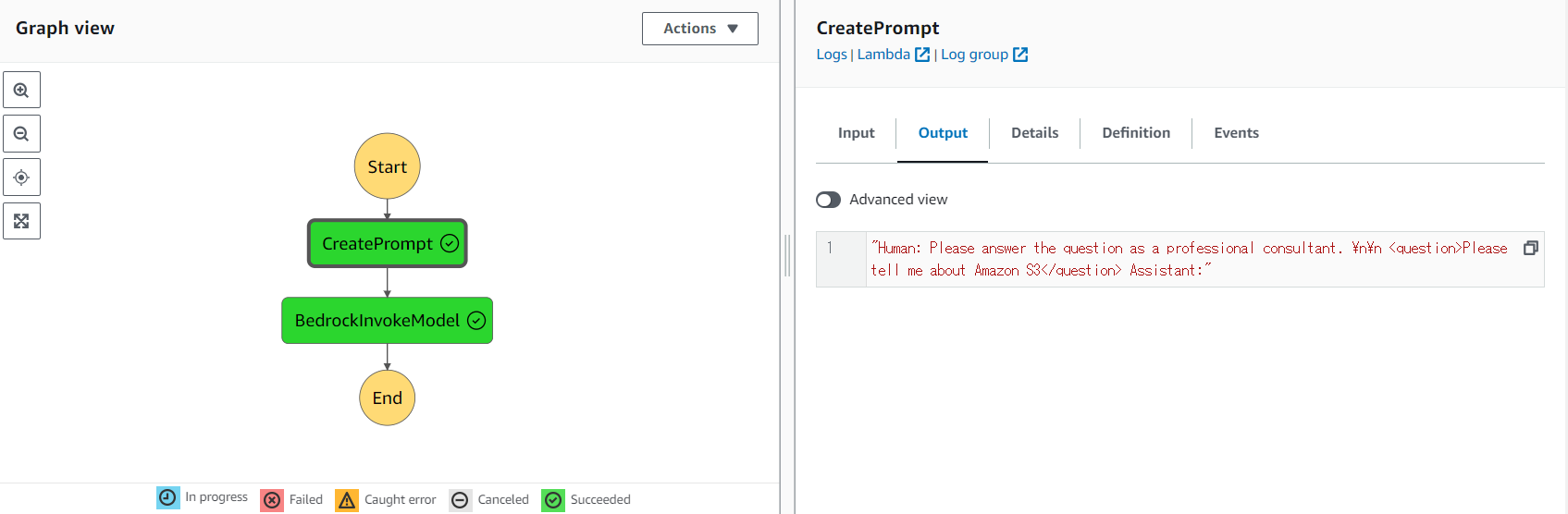 |
StepFunction を実行。設定した Amazon S3 のファイルに出力結果が記録されている。 |
※ 1 : プロンプトを生成する AWS Lambda のサンプルコード。 Node.js v18 で書いています。
console.log('Loading function');
import { PutObjectCommand, S3Client } from "@aws-sdk/client-s3";
const client = new S3Client({});
export const handler = async (event, context) => {
//console.log('Received event:', JSON.stringify(event, null, 2));
console.log('prompt=', event.prompt);
var prompt = `\n\nHuman: Please answer the question as a professional consultant. \n\n <question>${event.prompt}</question> Assistant:`
const command = new PutObjectCommand({
Bucket: 'amazon.bedrock.stepfunction.001',
Key: 'prompt/generated.json',
Body: JSON.stringify(
{
"prompt":prompt,
"max_tokens_to_sample": 200
}
),
ContentType: 'application/json'
});
try {
const response = await client.send(command);
console.log(response);
} catch (err) {
console.error(err);
}
return prompt;
// throw new Error('Something went wrong');
};
StepFunction への入力例
{
"prompt": "Please tell me about Amazon S3"
}
AWS Lambda が保存する Amazon Bedrock への入力ファイル。
{
"prompt": "\n\nHuman: Please answer the question as a professional consultant.
\n\n<question>Please tell me about Amazon S3</question> Assistant:",
"max_tokens_to_sample": 200
}
Amazon Bedrock が出力する Amazon S3 のファイル ( 適宜改行を入れています ) 。
{
"completion":" Here is how I would respond as a professional consultant:
\n\nAmazon Simple Storage Service (Amazon S3) is a highly scalable cloud storage
service that can be used to store and retrieve any amount of data from anywhere on
the web. Some key things to know about Amazon S3:\n\n- Storage Model: S3 uses a
simple web services interface that can be used to store and retrieve any amount
of data, at any time, from anywhere on the web. Data is stored in \"buckets\"
which organize objects within the S3 namespace. \n\n- Scalability: S3 provides
unlimited storage for any type of data including texts, media files, application
data, and more. It provides 99.999999999% durability with redundancies across
multiple data centers. Capacity can scale easily without performance degradation.
\n\n- Access Control: S3 supports granular access control to objects stored using
Identity and Access Management. You can set permissions for individual accounts
or groups to control who can",
"stop_reason":"max_tokens",
"stop":null
}
実際は入出力のファイルにタイムスタンプをつけて管理するとよいと思います。 StepFunction での処理は画像を生成した後に超解像して Crop して・・・といった一連の処理を実装するのに向いていそうです。
4.3 Amazon Q
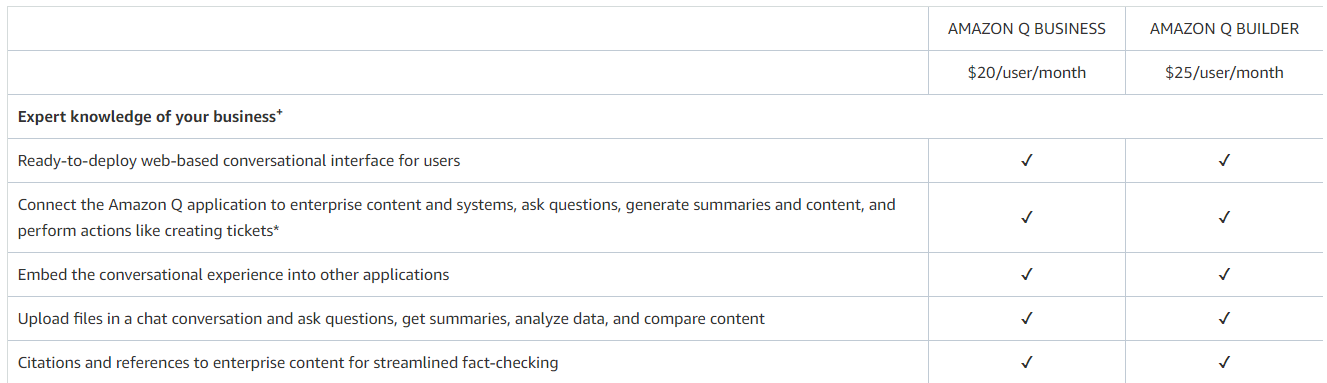
Amazon Q は Business と Builder の 2 種類があり、まず「どっちの Q? 」を明確にする必要があります。ユーザー単位課金のため、外部向けのサービスを作るというより社内での生成系 AI 活用を促すサービスです。
Amazon Q For AWS Builder Use
AWS Console から見える Amazon Q は "AWS Builder Use" です。月額 \$25 / ユーザーの価格が提示されていますが、プレビュー中はコストがかかりません。将来的には、課金すると使えるようになるのだと思います。
Pricing のページの通り、 "AWS Builder Use" は "Business Use" よりリッチなプランになります。そのため、 "Business Use" で使える機能は "AWS Builder Use" でも使うことができます。逆に言うと、 開発用途だから "Business Use" の機能を外して \$25 を安くすることは現時点ではできません。
"AWS Builder Use" の Amazon Q は、先の図の通りアイコンを押せばいつでも呼び出すことができます。また、 IDE にインストールして使うこともできます。ドキュメントで言及されている Amazon Q のサービス提供範囲は次の通りです。
- AWS Management Console
- AWS Marketing Website
- AWS Documentation
- IDEs
- AWS Console Mobile Application
Pricing のページを見ると、 Amazon CodeCatalyst や Amazon RedShift の Query Editor 、 Amazon QuickSight も含まれます。 Amazon QuickSight にはすでに "Q" と呼ばれる機能があり、 Author の場合は月額 \$34 がかかります。 Amazon Q 提供する機能と "Amazon QuickSight Q" で提供される機能は現時点で差異があるので、おそらく別々に料金がかかると考えています。この点については明確になり次第追記します。
AWS Chatbot を使うことで、チームの Slack や Microsoft Team に召喚することもできます。 Classmethod さんが早速ブログを書いてくれているのでご参考ください。
Amazon Q For For Business Use
"Business Use" の主要な機能は生成系 AI を用いた業務用・開発用アシスタント、 Amazon Q application が作れることです ( 前述の通り、 "AWS Builder Use" は上位プランになるため Builder User でもこのアシスタントは作成できます) 。 月額 \$20 / ユーザーの料金に加え、回答に使用する知識ベースについて 20,000 文書につき \$0.14/ 時間 (\$100/ 月 ) が必要です。また、 "Business Use" については最低 10 名が必要な点に注意してください。
アプリケーションは裏側で Amazon Bedrock を使用しているものの、その存在を意識することはありません。画面をポチポチしていくだけでアプリケーションを作ることができます。次は AWS Console から "Amazon Q" のページにアクセスした画面です。
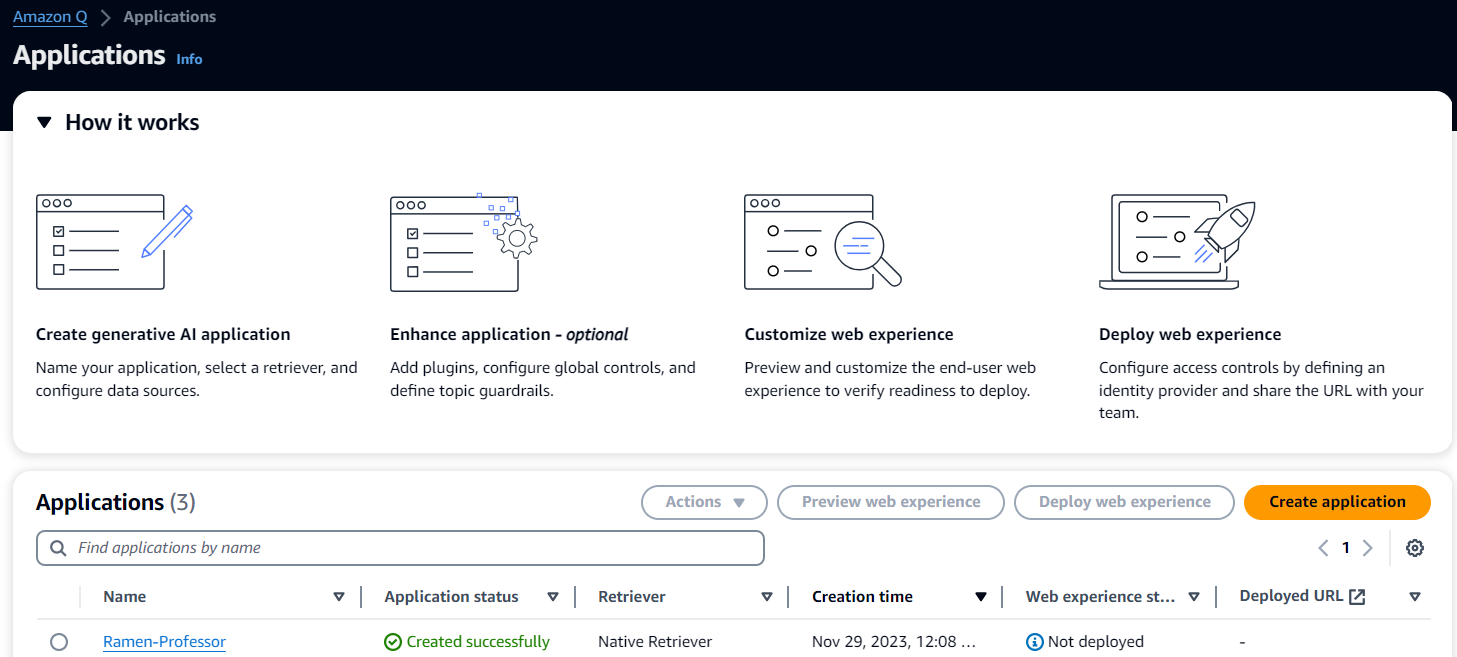
Amazon Q でのアプリケーション作成方法は次の通りです。 Preview 時点では英語のみ対応のため、英語で試しています。また、 AWS アカウントの Organization への参加が必要なようです。
| No | スクリーンショット | 操作 |
|---|---|---|
| 1 |  |
"Create application" を実行。 |
| 2 | 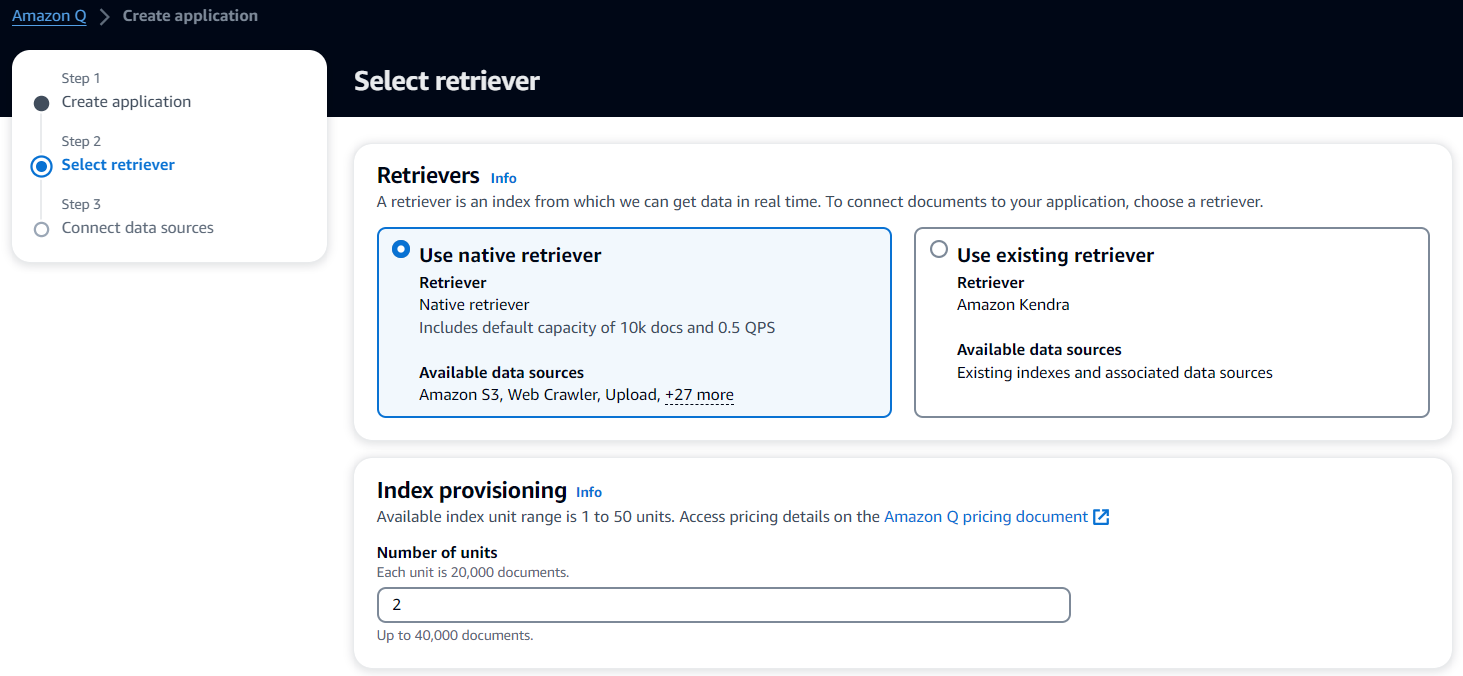 |
Retrievers を選択。 Kendra の検索エンジンがあれば選択できます。 "Index provisioning" は増やすほど固定で課金されるため、必要十分な値を設定することを推奨します。 |
| 3 | 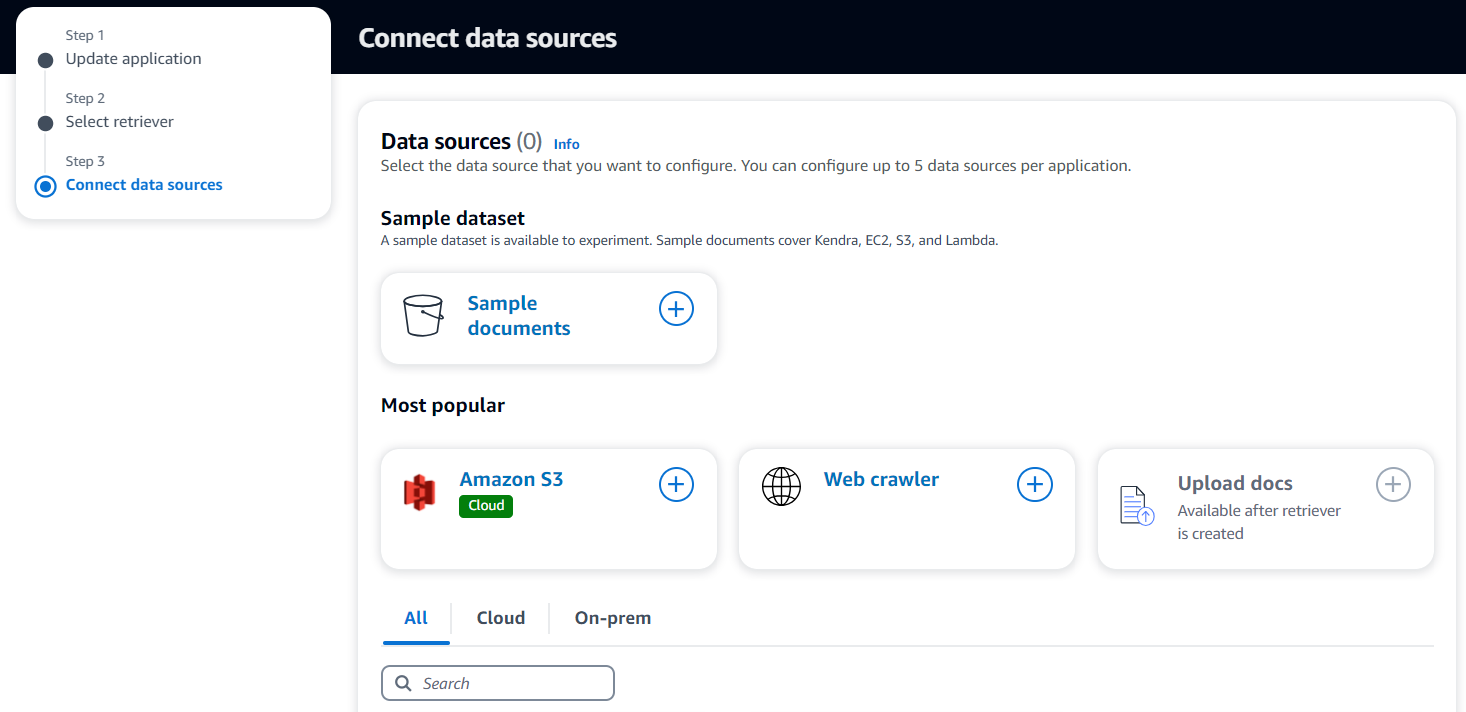 |
Data source を選択。今回は "Web crawler" を選択し、外部サイトからクローリングし情報をとるよう選択しました。 |
| 4 |  |
Data source で "Sync now" を実行 |
| 5 | 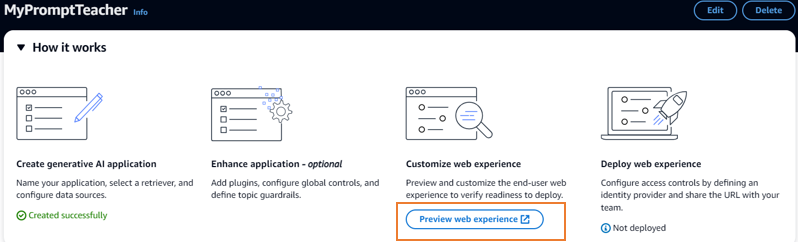 |
"Preview we experience" で回答をテスト。 |
作成した Amazon Q のサンプルです。 Anthropic Claude の Prompt Guideline をクローリングして、プロンプトのアドバイスがもらえるボットを作ってみました。クローリングの時間は 20 分程度でした。取り込んだドキュメントを引用して回答していることがわかります。
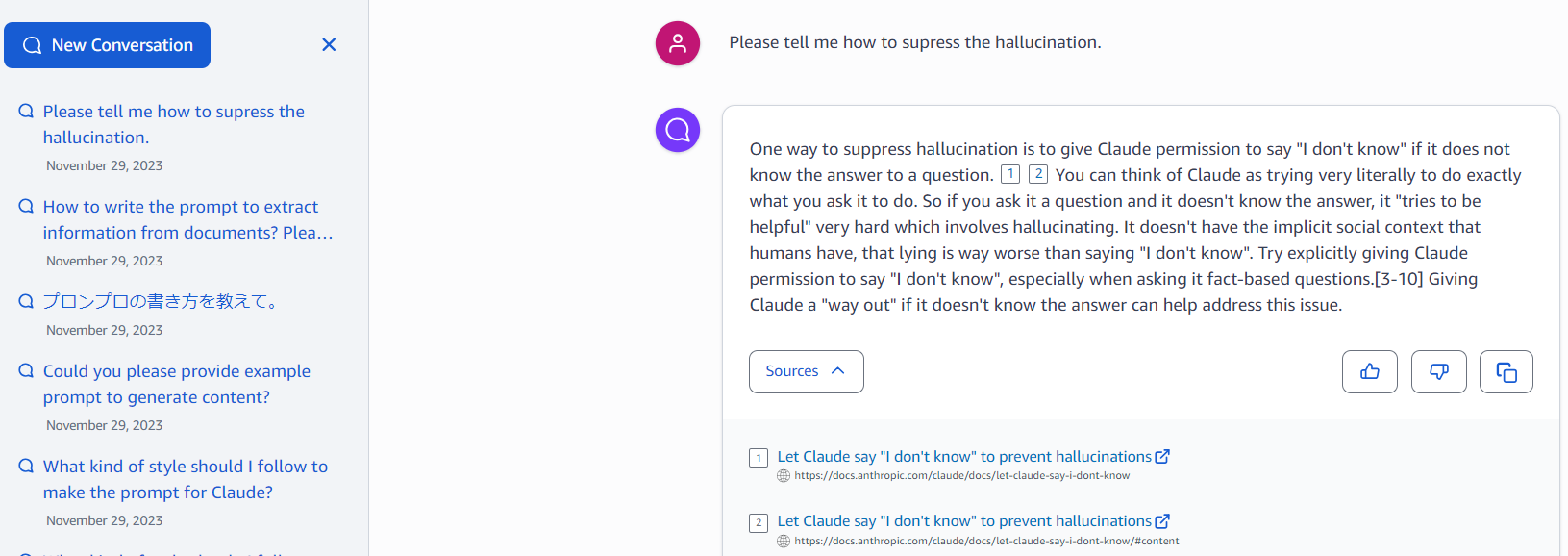
外部の identity provider (IdP) と連携し、限られたユーザーにアプリケーションを公開することができます。また、次の GitHub のコードを使うことで Slack と連携できます。
4.4 PartyRock
PartyRock は無料かつ AWS アカウント不要で生成系 AI を利用したアプリケーションが作れるサービスです。裏側は Amazon Bedrock が使われています。
アプリケーションの共有ができるので、アイデアをアプリケーションにしてみてもらうのに最適です。たとえば レシピジェネレーター は、私が作成して公開したアプリです。
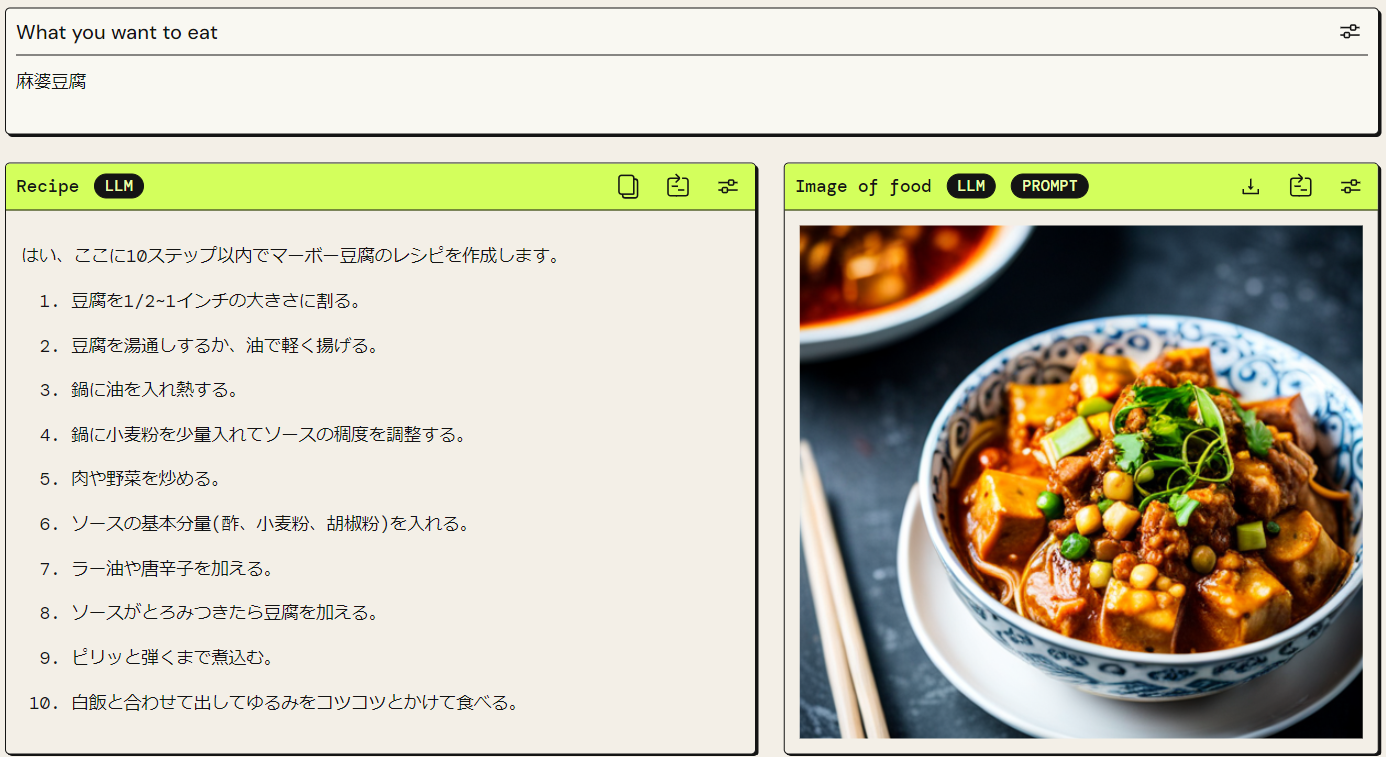
詳細な使い方は以下の記事を参照してください。
PartyRock : 誰でも生成系 AI のアプリケーションを作成し共有できるサービス
4.5 AWS Sample
Amazon Q が魅力的なものの、日本語に対応していないとちょっと、という場合もあると思います。 AWS では、日本語が使える生成系 AI のサンプルを OSS で公開しているので最後にご紹介します。
bedrock-claude-chat
日本語が扱える Anthropic Claude を使ったチャットシステムが簡単に作れるサンプルです。 CDK でデプロイでき、認証・ IP アドレス制限もできるのでセキュアに使用することができます。 Markdown のレンダリングにも対応しています。
Generative AI Use Cases JP
チャットだけでは物足りない時はこちらです。 RAG や要約、画像生成といった様々なユースケースを試すことができます。こちらも CDK でデプロイできます。
おわりに
本記事では、 Amazon Bedrock の準備方法からアプリケーション開発の方法まで幅広にご紹介しました。生成系 AI を使った開発の参考になれば幸いです!
