この記事について
この記事は、AWSとGoogleCloudで、とりあえず簡単にRAGを構築してみたい!(API呼び出しもあるよ)のGoogle Cloud編として、GoogleCloudでの構築手順をまとめたものになります。
AWS編や、AWSとGoogle Cloudの比較を見たい方は親記事からどうぞ。
0.使用するサービス
Google CloudではVertex AI Search and Conversation(新サービス名:Vertex AI Agent Builder)を利用することで、Cloud Storageを外部ソースとしたRAGが作成できます。
※この記事を書いている時にちょうどリアルタイムで開催されているGoogle Cloud Next '24にて、新しいサービス名であるAgent Builderが発表されたようですが、このまま新旧サービス名を併記する形式でいきます。
1.Cloud Storageにテキストファイルを配置する
まずは外部から与える情報源として、Cloud Storageバケットを作成してテキストファイルを配置します。
バケットの作成
コンソール画面の左上にあるハンバーガーメニューをクリックし、「Cloud Storage」>「バケット」を選択してバケット一覧画面を表示します。

赤枠内の「作成」をクリックして、バケット作成を開始します。
(▼ バケットに名前を付ける)

まずはバケットの名前を指定します。
・バケット名 - グローバルに一意となる名前を指定。
・ラベル - 任意。
名前を指定したら「続行」をクリックします。
(▼ データの保存場所の選択)

次にリージョンを指定します。今回はテスト的に作成するだけですので、単一リージョンでOKです。「Region」ラジオボタンを選択し、東京リージョンで指定します。
ここまで指定したらあとはデフォルトで構わないので、一番下までスクロールして「作成」ボタンをクリックします。
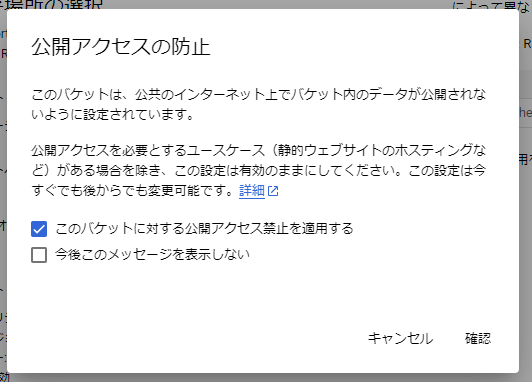
以下のような確認画面が表示されるので、「このバケットに対する公開アクセス禁止を適用する」にチェックが入っていることを確認して「確認」をクリックします。
数秒でバケットが作成されるかと思います。
バケットにテキストファイルを配置する
バケットが作成できたら、外部情報源となるテキストファイルを配置します。
テキストファイルの作成例については親記事で触れておりますので、そちらをどうぞ。
直下にテキストファイルを置いてしまってもいいんですが、一応フォルダも作りましょう。
なお、AWS編では複数のフォルダを作成しましたが、Google Cloudではひとつのフォルダに入れます。複数のフォルダに分ける場合は、Vertex AIでデータストアをフォルダの個数分作成する必要があるようです。
[バケット]
┗ ham
┣ ham_g.txt
┗ ham_j.txt
(▼ テキストファイルを配置した状態)

2.Vertex AI Search and Conversation(Agent Builder)の利用開始
下準備もできたところで、Vertex AIの利用に移りましょう。
試しに画面上の検索窓で、旧サービス名である「Vertex AI Search and Conversation」を入力して検索します。
(▼ 検索結果)

検索結果の上位に「Agent Builder」がヒットします。旧サービス名で検索してもちゃんとヒットしてくれるんですね。
今後もしかすると旧名ではヒットしなくなる可能性もあるので、その場合は素直に「Vertex AI Agent Builder」と入れて検索してください。
ともあれ、Agent Builderを選択します。
すると、「Welcome to Vertex AI Agent Builder」という画面が開くと思います。
「CONTINUE AND ACTIVATE THE API」をクリックしてサービスを有効化します。
サービス有効化が完了すると、アプリ作成画面が表示されるかと思いますが、まだデータストアを作成していないためアプリが作れません。まずはデータストアの作成から行います。
3.データストアの作成
作成開始
左メニューで「データストア」を選択します。
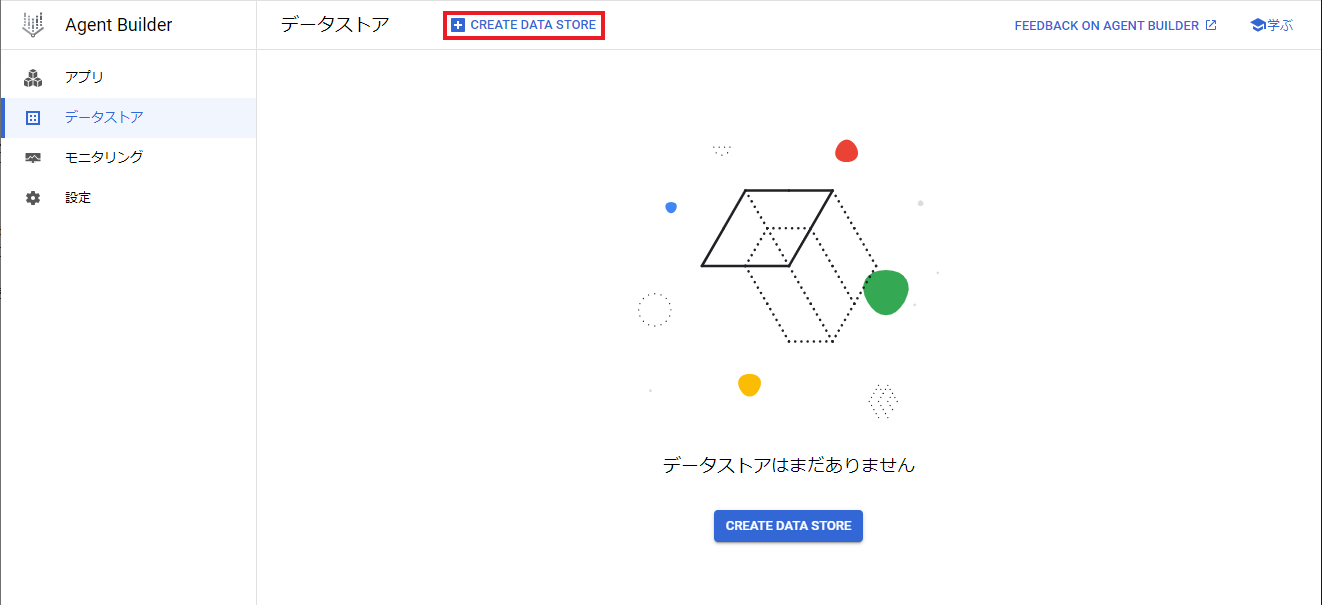
データストア一覧画面が表示されるので、赤枠内の「CREATE DATA STORE」をクリックします。
データソースの選択
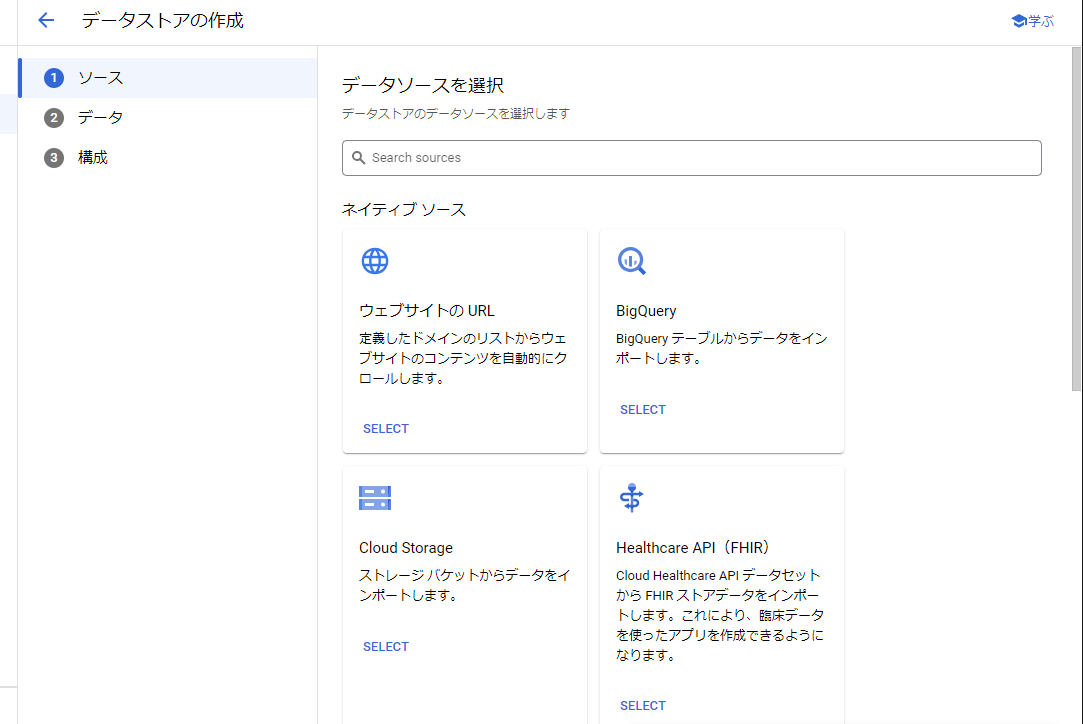
選択できるデータソース一覧が表示されます。
様々なデータソースが選択できることがわかります。今回はCloud Storageを選択します。
データソースを指定
次にデータソースとなるフォルダを指定します。
インポート先に「フォルダ」を指定して、Cloud Storageフォルダパス欄の「参照」をクリックします。

(▼ フォルダの指定)
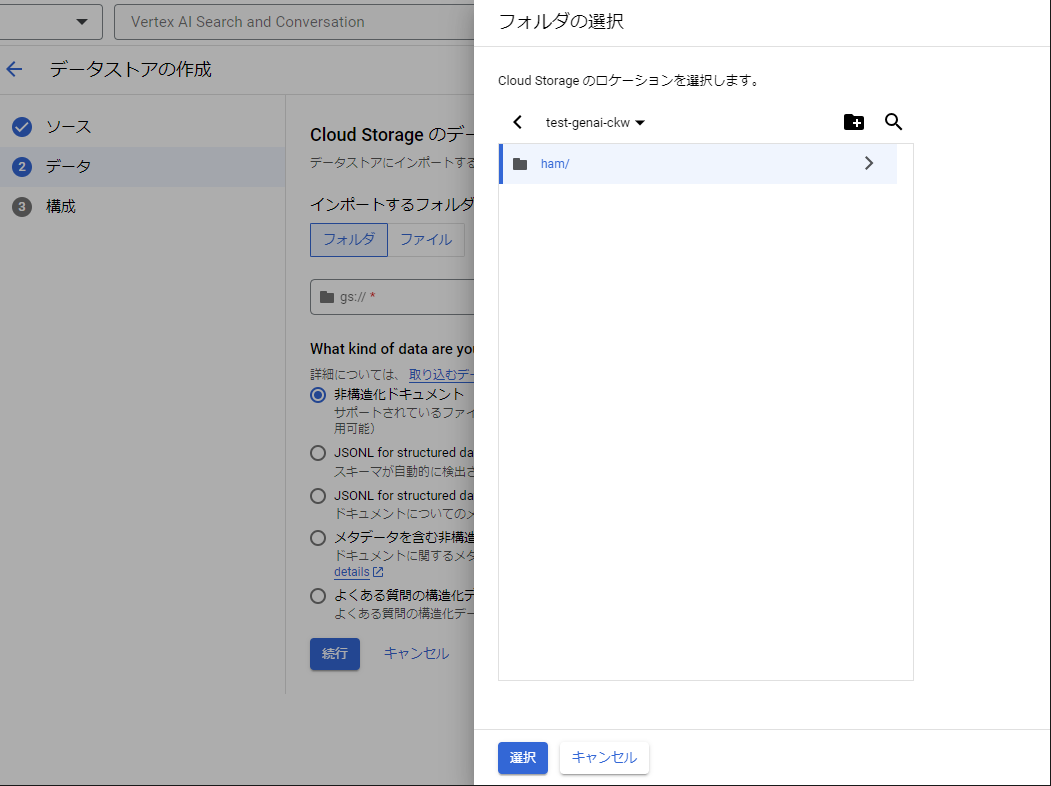
バケット一覧が表示されるので該当のバケットを選択し、先ほどテキストファイルを配置したフォルダを指定して「選択」をクリックします。
(▼ データ形式の選択)

次のデータ形式については、今回はテキストファイルを読み込むため、一番上の「非構造化ドキュメント」を選択した状態で「続行」をクリックします。
データストアの構成

最後にリージョン等を指定します。
・データストアのロケーション - リージョンを指定します。デフォルトの「グローバル」とします。
・デフォルトのドキュメントパーサー - こちらもデフォルトの「Digital Parser」を指定します。
・Document chunking - チェックを外したままで良いかと思います。
・データストア名 - 任意の名前を入力します。
データストア名を入力したら、「作成」をクリックします。
しばらく待つとデータストアが作成され、データストア一覧画面が表示されます。
4.アプリの作成
データストアが作成できたら、アプリを作成します。
左メニューで「アプリ」を選択してアプリ一覧画面を表示し、赤枠内の「新しいアプリ」をクリックします。

アプリの種類の選択

まずはアプリの種類を選択します。今回は「検索」を選択します。
アプリの構成
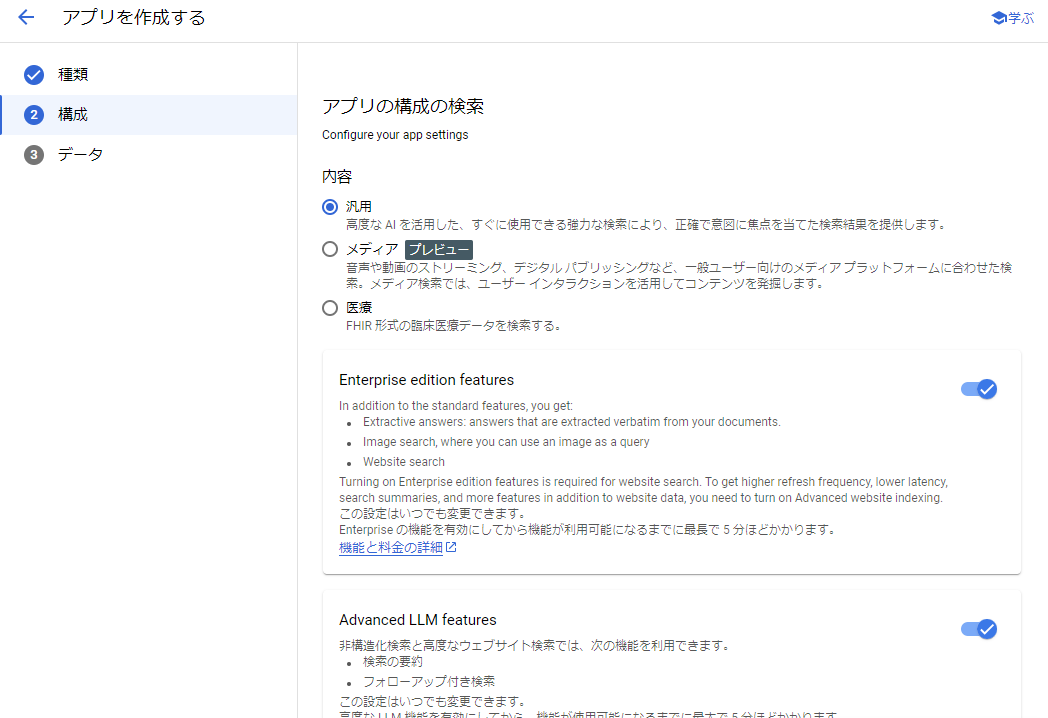
アプリの詳細について設定します。
・内容 - 今回は「汎用」を選択します。
・Enterprise edition features、Advanced LLM features - 今回は高度な機能は使わない気がしますが、基本的にONで良いと思います。
・アプリ名 - 任意の名前を入力します。
・会社名または組織名 - 会社・組織内での検証の場合はその名前を。私は個人での検証だったので、個人で使用しているIDを入れました。
・アプリのロケーション - リージョンを指定します。デフォルトのグローバルでOKです。
ここまで入力したら、「続行」をクリックします。
データストアの選択

関連付けるデータストアをここで選択します。
先ほど作成したデータストアにチェックを入れ、「作成」ボタンをクリックします。
インポートドキュメントの確認
アプリの作成が完了したら、アプリにインポートされたデータの情報が表示されます。

ここでインポートされているドキュメント数を確認してください。データソースとして与えたドキュメント数より少ない場合は、まだインポートが完了していません。
インポートには10分ほどかかるようですので、しばらく待ちます。
(▼ インポートが完了した状態)

10分~15分ほど待って画面を更新し、ドキュメント欄に今回追加したテキストファイル名が表示されれば準備完了です。
データストアのIDをメモする
このあと外部から呼び出すために必要な情報を確認しておきましょう。
赤枠内の「データストアのID」をメモするか、この画面を開いたままにしておいてください。

アプリのプレビュー
ここまで作成が完了したら、RAGのテストができます!
左メニューで「プレビュー」を選択します。左メニューに「プレビュー」が表示されていない場合は、アプリ一覧画面で作成したアプリを選択してください。左メニューの表示が変わるかと思います。
検索欄に質問を入力して検索実行します。
(▼ 質問の入力)
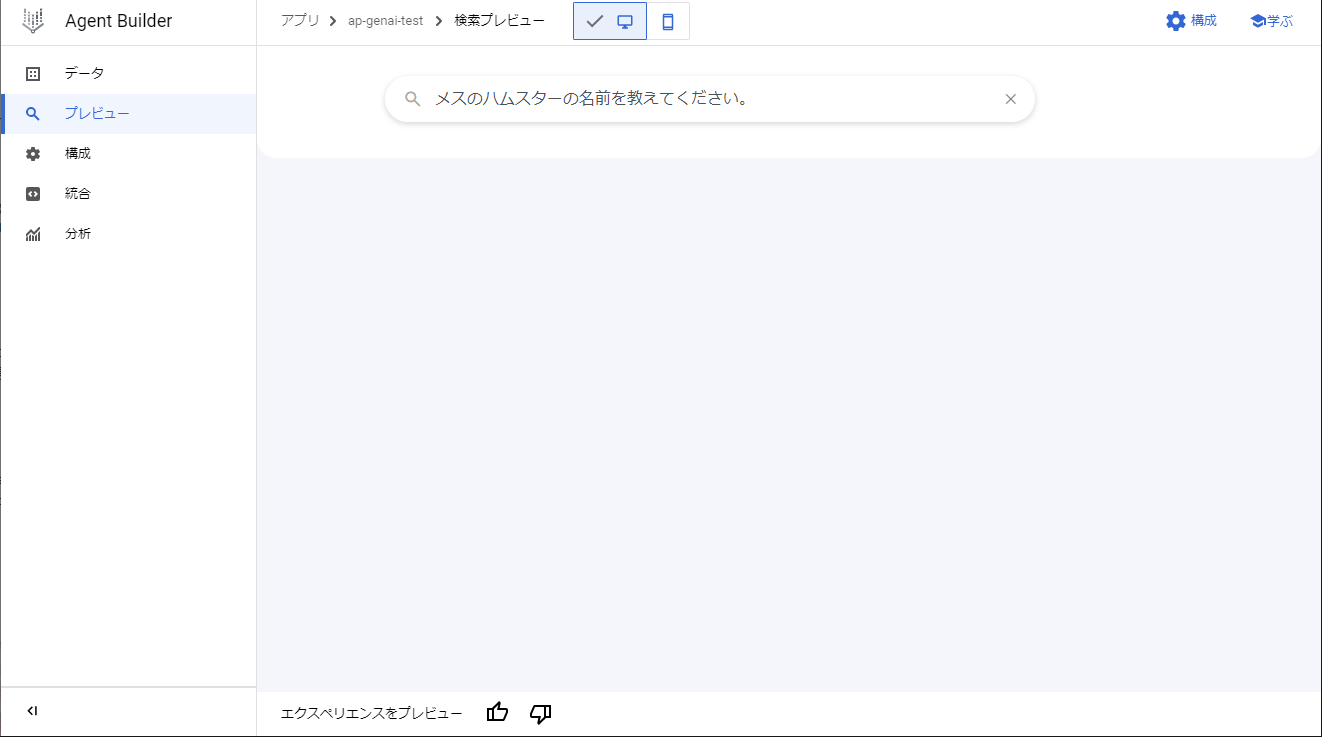
質問の答えと、参照したテキストの内容が表示されました!

また、左メニューの「構成」から使用モデルの選択やチューニングが可能です。
使用モデルはデフォルトではText-Bison1(PaLM2)が選択されています。Gemini Proに変更して質問することも可能です。
(▼ モデルの選択画面)

5.Cloud Functionsの作成
次はCloud Functionsから呼び出して、回答を生成できるようにしましょう。
画面左上のハンバーガーメニューからCloud Functionsを探すか、画面上の検索バーで検索してCloud Functionsを選択します。
Cloud Functionsの作成開始
Cloud Functionsの画面が表示されたら、赤枠内の「ファンクションを作成」をクリックして作成を開始します。
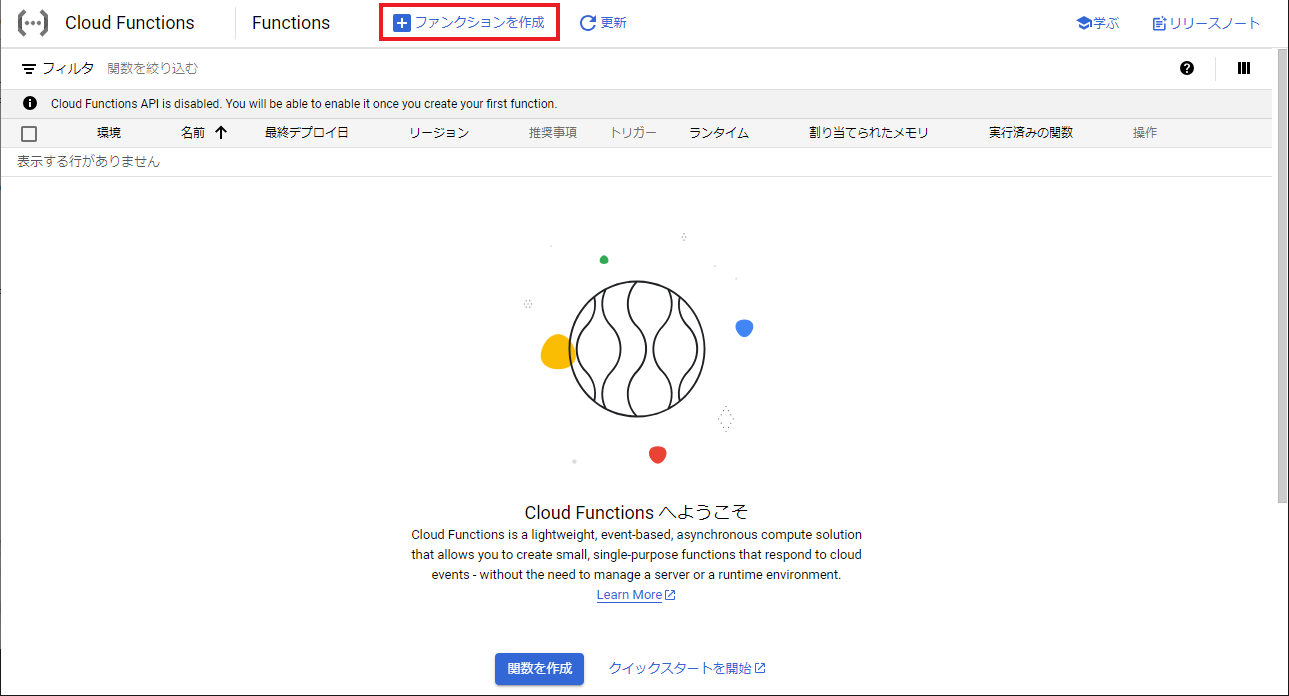
初めてCloud Functionsを作成する方は以下のような確認画面が表示されると思いますので、「有効にする」をクリックして少し待ちます。

構成
まずはCloud Functionsの基本構成を入力します。
(▼ 構成設定)
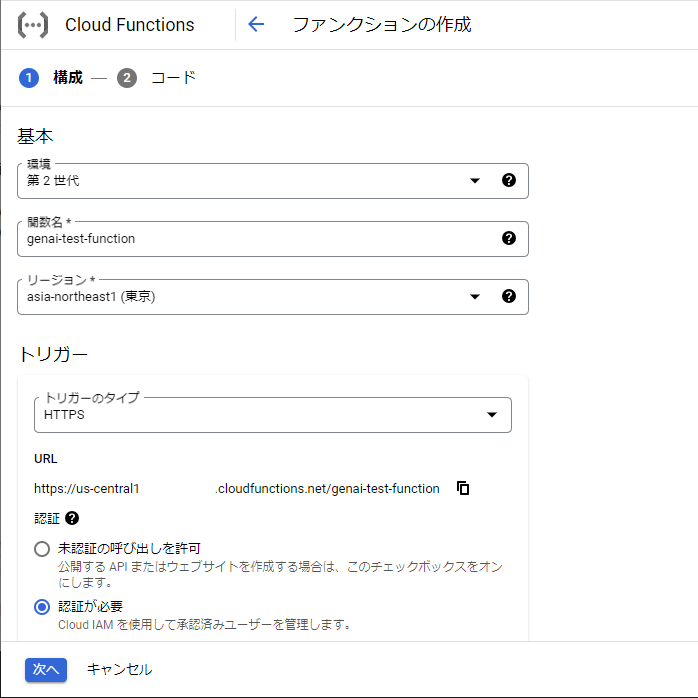
・環境 - 第2世代を選択します。
・関数名 - 任意の関数名を入力します。
・リージョン - 東京を指定します。
・トリガーのタイプ - HTTPSを指定します。
・認証 - 「認証が必要」を指定します。
・ランタイム、ビルド、接続、セキュリティの設定 - その他詳細設定ができますが、今回はすべてデフォルトでOKです。
ここまで入力したら、「次へ」をクリックします。
初めてCloud Functionsを作成する方はここでまたAPIの有効化確認画面が表示されると思いますので、「有効にする」をクリックします。
ソースコード
次にソースコードを入力します。
(▼ インラインエディタ)

・ランタイム - Python3.12を選択します。基本的にPythonの最新バージョンで良いかと思います。
・エントリポイント - 「search_result」と入力してください。入力すると一時的に警告が表示されますが、ソースコードを入れれば解消されますのでご安心を。
・ソースコード - 「インラインエディタ」を選択します。
ソースコードとして、main.pyとrequirements.txtに以下をコピペしてください。
main.pyの[プロジェクトID]と[Agent BuilderでメモしたデータストアのID]のところに、それぞれ該当の文字列を入力します。プロジェクトIDは、画面上のプロジェクト選択プルダウンをクリックすると確認できます。
requirements.txtのそれぞれのライブラリバージョンがもしかすると古いかもしれませんが、このバージョンで動作確認をしています。
import functions_framework
import json
from typing import List
from google.api_core.client_options import ClientOptions
from google.cloud import discoveryengine_v1 as discoveryengine
from google.protobuf.json_format import MessageToDict
project_id = "[プロジェクトID]"
location = "global" # Values: "global", "us", "eu"
data_store_id = "[Agent BuilderでメモしたデータストアのID]"
def search_sample(
search_query: str,
) -> List[discoveryengine.SearchResponse]:
# For more information, refer to:
# https://cloud.google.com/generative-ai-app-builder/docs/locations#specify_a_multi-region_for_your_data_store
client_options = (
ClientOptions(api_endpoint=f"{location}-discoveryengine.googleapis.com")
if location != "global"
else None
)
# Create a client
client = discoveryengine.SearchServiceClient(client_options=client_options)
# The full resource name of the search engine serving config
# e.g. projects/{project_id}/locations/{location}/dataStores/{data_store_id}/servingConfigs/{serving_config_id}
serving_config = client.serving_config_path(
project=project_id,
location=location,
data_store=data_store_id,
serving_config="default_config",
)
# Optional: Configuration options for search
# Refer to the `ContentSearchSpec` reference for all supported fields:
# https://cloud.google.com/python/docs/reference/discoveryengine/latest/google.cloud.discoveryengine_v1.types.SearchRequest.ContentSearchSpec
content_search_spec = discoveryengine.SearchRequest.ContentSearchSpec(
# For information about snippets, refer to:
# https://cloud.google.com/generative-ai-app-builder/docs/snippets
snippet_spec=discoveryengine.SearchRequest.ContentSearchSpec.SnippetSpec(
return_snippet=True
),
# For information about search summaries, refer to:
# https://cloud.google.com/generative-ai-app-builder/docs/get-search-summaries
summary_spec=discoveryengine.SearchRequest.ContentSearchSpec.SummarySpec(
summary_result_count=5,
include_citations=True,
ignore_adversarial_query=True,
ignore_non_summary_seeking_query=True,
),
)
# Refer to the `SearchRequest` reference for all supported fields:
# https://cloud.google.com/python/docs/reference/discoveryengine/latest/google.cloud.discoveryengine_v1.types.SearchRequest
request = discoveryengine.SearchRequest(
serving_config=serving_config,
query=search_query,
page_size=10,
content_search_spec=content_search_spec,
query_expansion_spec=discoveryengine.SearchRequest.QueryExpansionSpec(
condition=discoveryengine.SearchRequest.QueryExpansionSpec.Condition.AUTO,
),
spell_correction_spec=discoveryengine.SearchRequest.SpellCorrectionSpec(
mode=discoveryengine.SearchRequest.SpellCorrectionSpec.Mode.AUTO
),
)
response = client.search(request)
result = response.summary.summary_text
documents = []
if not response.results:
return result, documents
for r in response.results :
json_text = MessageToDict(r._pb)
document = json_text['document']['derivedStructData']['title']
documents.append(document)
return result, documents
@functions_framework.http
def search_result(request):
"""HTTP Cloud Function.
Args:
request (flask.Request): The request object.
<https://flask.palletsprojects.com/en/1.1.x/api/#incoming-request-data>
Returns:
The response text, or any set of values that can be turned into a
Response object using `make_response`
<https://flask.palletsprojects.com/en/1.1.x/api/#flask.make_response>.
"""
message = '我が家のハムスターのうち、メスのハムスターは?'
result, documents = search_sample(message)
json_text = '{"result" : "' + result + '","documents":'
json_text = json_text + json.dumps(documents, ensure_ascii=False) + '}'
return (json_text, 200)
functions-framework==3.*
google-cloud-discoveryengine==0.11.1
google-api-core==2.11.1
protobuf==4.25.2
ソースコードを設定できたら、画面下の「デプロイ」をクリックしてデプロイ完了までしばらく待ちます。
6.Cloud Functionsのテスト実行
Cloud Functionsが作成できたら、テストを実行してRAGに質問が投げられることを確認します。
Cloud Functionsの「テスト中」タブをクリックします。
下の方へスクロールすると、CLI テストコマンドが準備されていることが確認できます。
(▼ CLIテストコマンド)

今回はCloud Shellから呼び出してテストをします。
「CLOUD SHELLで実行」をクリックします。すると、Cloud Shellのターミナルが起動します。
ターミナルが起動すると、自動的に先ほどのCLIテストコマンドが入力された状態になっていますので、このままテストコマンドを実行します。
Cloud Shellの承認画面が出た場合は、承認をクリックします。

少し待って、以下のような結果が返ってきたら成功です!
質問によっては、「検索語句の要約を生成できませんでした。」という回答が返ってくることがあります。その場合は質問文を変えてみてください。文章を少し変えるだけで回答が返ってくることもあります。

返却されるjsonには、メインの回答文であるresultと、回答を生成するのに参照したdocumentsのリストが含まれています。
今回はCloud Functionsのソースコードに質問文を固定文字列として渡しましたが、外部から質問を渡せるようにすればCloud Functionsを利用して様々な質問ができるようになります。
7.後片付け
作成したリソースは実行しなければ課金されませんが、特に今後使わないようでしたら削除しておきましょう。
削除が必要なリソースは以下4つです。
・Cloud Functions
・Vertex AI Agent Builderのアプリ
・Vertex AI Agent Builderのデータストア
・Cloud Storageのバケット
Cloud Functonsの削除
Cloud Functonsの関数一覧画面で該当の関数にチェックを入れ、右端の3点メニューから「削除」をクリックします。
確認画面が表示されるので、「削除」をクリックして少し待てば完了です。
(▼ 関数一覧)

Vertex AI Agent Builderのアプリ削除
Vertex AI Agent Builderの左メニューで「アプリ」を選択し、右端の3点メニューから「削除」をクリックします。
削除確認画面が表示されるので、アプリ名を入力して削除します。

Vertex AI Agent Builderのデータストア削除
データストアを削除するには、まずインポートしたドキュメントを削除する必要があります。
左メニューの「データストア」を選択し、データストア一覧画面から該当のデータストア名をクリックします。
赤枠内の「データを削除」をクリックして、ドキュメントをすべて削除します。

確認画面から削除を実行し、しばらく待ってから画面を更新するとドキュメントがすべて削除されたことが確認できるかと思います。
ドキュメントが削除できたら、データストアを削除します。
データストア一覧画面に戻り、右端の3点メニューから「削除」をクリックします。
削除確認画面が表示されるので、データストア名を入力して削除します。

Cloud Storageのバケット削除
Cloud Storageのバケット一覧画面に移り、該当のバケットの右端の3点メニューから「バケットの削除」を選択し、確認画面から削除を実行します。
ここまで実行できればすべて完了です!