tensorboardX
普段業務や趣味で画像データを取り扱うことが多いのですが、とりあえず特徴空間上に可視化、ってときによく使う手法が PCA なり t-SNE なりでの Embedding でして。
画像データ自体から得られる何らかの特徴量もしくはそれに付随するメタデータを 2, 3 次元の特徴空間にマッピングしてあげることで、どんな画像が似た者同士なのかを眺めながら様々な想いを馳せるのが大好きです。
そんな Embedding 、これまでは Python の素晴らしい画像処理ライブラリであらせられる PIL もとい Pillow におんぶにだっこさせてもらいながら頑張って作図してたわけなのですが、何やら TensorFlow 標準のビジュアライズツールである TensorBoard が結構使えるとの噂を耳にしたので使ってみることにしました。
TensorflowのEmbedding Visualizationでカッコよく可視化したい
とはいえ自分がこれまでに利用したことのある主要な DeepLearning フレームワークは PyTorch のみ。PyTorch 自体にもまだそこまで熟れていないくせに TensorFlow に片足突っ込むのもなんとなく気が引けていた1ところに見つけたのがこの tensorboardX 。
なんと PyTorch の torch.Tensor 型のデータをそのまま TensorBoard 用に書き出してくれるというスグレモノです。もちろん Embedding Projection にもしっかり対応。
PyTorchで学習の過程を確認したいときはtensorboardXを使うのが良かったです
さらに本家 TensorFlow から書き出す際にはプロット用の画像を格子状に 1 ファイルにまとめた所謂スプライト画像を自作する必要があるっぽいんですが、 tensorboardX はこの割とめんどそうな作業も自動化してくれて、何ともいたせりつくせりなライブラリとなっています。
正直このアドバンテージだけでも PyTorch から書き出す意味結構あるんじゃないですかね。
インストール
PyTorch、TensorFlow、tensorboardX あたりをインストールします。
Linux 向けに pip でインストールしていますが、環境に合わせて適切な方法で行ってください。
$ pip3 install http://download.pytorch.org/whl/cu80/torch-0.3.0.post4-cp35-cp35m-linux_x86_64.whl
$ pip3 install torchvision tensorflow tensorboardX
データ
features.csv という CSV ファイルに下記のように「特徴値 20 次元・ラベル・プロット用の画像パス」がカラムごとに格納されて 10000 データ分存在しているとします。
feature1,...,feature20,label,image_path
コード
上記のファイルから特徴値を読み込んで TensorBoard 向けに吐き出すスクリプトを記述します。
ファイルを1行ずつ読み込み特徴値とプロット画像をそれぞれ Tensor 、ラベルはリストとして連結していく形で行いました。
プロット画像に関しては Tensor 化する際に 50x50 へリサイズしておきます。このサイズですが、スプライト画像が読み込まれる際に Width, Height 共に 8192px までしかサポートされていないようですのでデータ数に応じて考慮してあげてください。
https://www.tensorflow.org/versions/r1.2/get_started/embedding_viz#images
最後に特徴値とプロット画像の Tensor を 10000 データ分として view で体裁を整えた後、ラベルリストと共に add_embedding してあげましょう。
import torch
import torchvision
import csv
import numpy as np
import PIL
import tensorboardX as tbx
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((50, 50)),
torchvision.transforms.ToTensor(),
])
features = torch.zeros(0)
labels = []
label_imgs = torch.zeros(0)
with open('features.csv') as f_csv:
for data in csv.reader(f_csv):
feature = torch.Tensor(np.array(data[:20]).astype(float))
features = torch.cat((features, feature))
label = data[20]
labels.append(label)
label_img = transform(PIL.Image.open(data[21]).convert('RGB'))
label_imgs = torch.cat((label_imgs, label_img))
features = features.view(10000, 20)
label_imgs = label_imgs.view(10000, 3, 50, 50)
writer = tbx.SummaryWriter()
writer.add_embedding(features, metadata=labels, label_img=label_imgs)
writer.close()
これを実行すると runs というディレクトリが作成されその中に TensorBoard 用のデータが格納されます。
もう既に torch.utils.data.Dataset を拡張して独自クラスを作成しており簡単にデータローダーが取り扱える状態になっているって方はファイル読み込みのあたりは読み替えてもらって構いません。
TensorBoard 起動
あとは runs ディレクトリを logdir にオプション指定してあげる形で TensorBoard を起動するだけです。
以下のように叩いてあげると TensorBoard が localhost の 6006 ポートで起動するのでブラウザへ。
$ tensorboard --logdir=runs
可視化画面
ブラウザ上でこんな画面が出力されれば成功です。
最初は 3D PCA が表示されました。グリグリ動かせます。
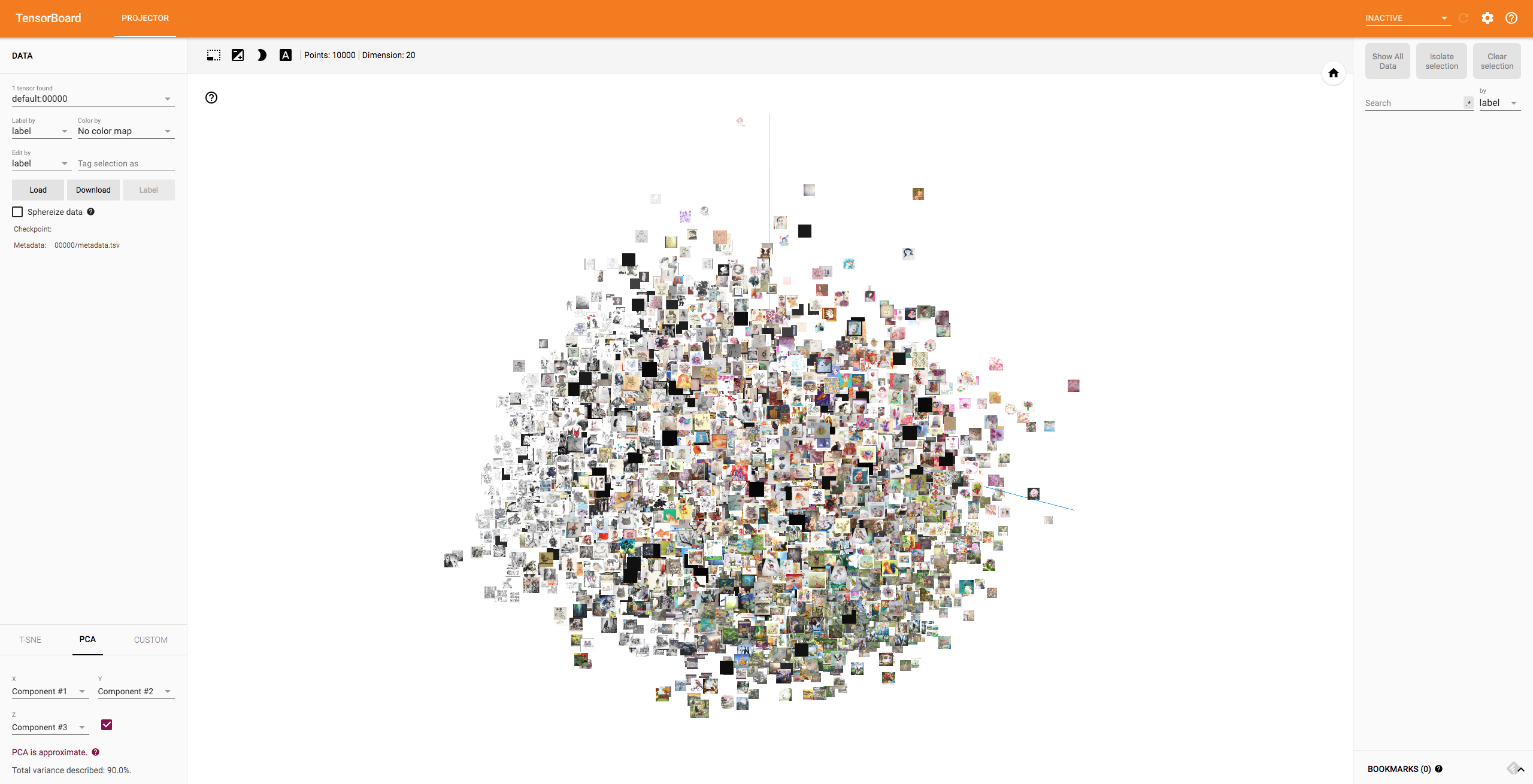
さらにクラスタ形成具合を詳しく見たりしたい場合は、左上のプルダウンをいじってあげることでラベルごとに色分けもされますね。
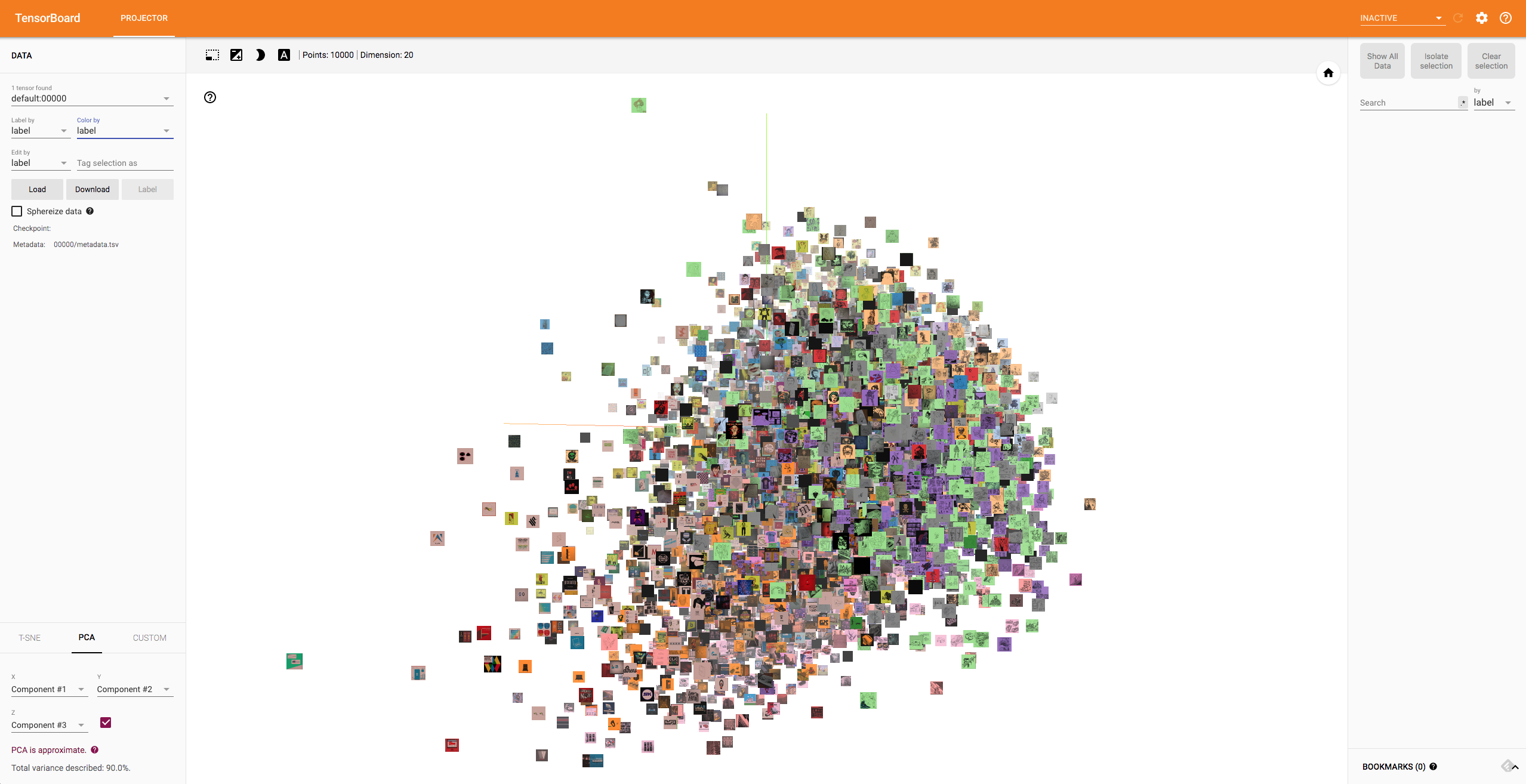
こんな感じで PCA の他に t-SNE も選択できますし、プロットされている画像をクリックすることで距離計算による Nearest Neighbor も簡単に確認できます。
まとめ
今回 PyTorch から吐き出せるとのことで tensorboardX にたまたま手を出してみたんですが TensorBoard の機能ほとんど(全部か?)に対応しているので重宝しています。
これまでチマチマ自分で作図して Embedding プロットしていたのがアホらしくなってきますね。
-
そもそも Define-By-Run 系以外あまりいじりたくない・・・ ↩