初めに
前回はgrad-camやtsneを使用して学習状況の確認のための可視化を行いました。
今月は今までの手法とはちょっと趣向を変えて、教師なし学習をというものに手を出してみましょう。と言っても前回のtsneも教師なし学習ですが。
教師なし学習というのはその名の通りAIに教師となるラベルを与えずに学習させることです。ラベルも与えずに何ができるのかと言うと、次元削減・クラスタリングによく使われます。
機械学習でいわれる教師なし学習とは
教師なし学習でやることとしては異常検知が有名ですね。正解だけ学習させて、正解っぽくないものを異常とするというやり方です。
5ヶ月目でやること
- functionalでmodelを組めるようになる
- resnetを組んでみる
- vaeを実装する
くらいです。vaeを実運用で使用するのはかなり難しいですが、どれくらいのことができるかは知っておいたほうが良いと思います。
functionalについて
kerasにはmodelの組み方が2通りあり、それぞれSecentialとfunctional APIと言います。基本的に簡単に組めて初心者向けなのがSecentialで、ちょっと工夫したいと思った時に使うのがfunctionalです。かなり工夫したいと思ったらpytorch・chainerを使いましょう。研究部門でない限りそこまでの工夫はしないと思いますが。
イメージ的にはSecentialは乗せていく、functionalはつないでくという感じでしょうか。転移学習のときはfunctionalを使って実装するときが多いですね。
from keras.layers import Input, Conv2D, MaxPooling2D, GlobalAveragePooling2D, Dense, UpSampling2D, Reshape
from keras.models import Model
input_img = Input(shape=(28, 28, 1))
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = GlobalAveragePooling2D()(x)
x = Dense(256)(x)
output_img = Dense(7)(x)
model1 = Model(input_img, output_img)
model1.summary()
resnetを組んで見る
それではfunctionalでちょっと工夫したネットワークを組んでみましょう。やってみるのはresnetです。これは最近の中ではかなり革新的なアイディアで、skip connectionという層を飛ばすラインも持ちます。これにより、深い構造でも学習が進むというメリットがあります。
resnet以上の複雑なモデルは公開されてるのを使いますが、resnetくらいだったらこれを参考にちょっと小さいモデル作ったりするので、組めるようになっておいたほうが得です。
resnetの組み方は下記を使用させていただきました。ループで書くの良いですよね。上級者って感じがします。
あと、is_first_layer_but_not_first_block = j == 0 and i > 0でbool値を変数としてるのがかっこいいです。
新たなdata augmentation手法mixupを試してみた
def resnet_model(label_num):
num_filters = 64
num_blocks = 4
num_sub_blocks = 2
input_shape = (128, 128, 3)
# Start model definition.
inputs = Input(shape=input_shape)
x = Conv2D(num_filters, kernel_size=7, padding='same', strides=2, kernel_initializer='he_normal')(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# Instantiate convolutional base (stack of blocks).
for i in range(num_blocks):
for j in range(num_sub_blocks):
strides = 1
is_first_layer_but_not_first_block = j == 0 and i > 0
if is_first_layer_but_not_first_block:
strides = 2
y = Conv2D(num_filters, kernel_size=3, padding='same', strides=strides, kernel_initializer='he_normal')(x)
y = BatchNormalization()(y)
y = Activation('relu')(y)
y = Conv2D(num_filters, kernel_size=3, padding='same', kernel_initializer='he_normal')(y)
y = BatchNormalization()(y)
if is_first_layer_but_not_first_block:
x = Conv2D(num_filters, kernel_size=1, padding='same', strides=2, kernel_initializer='he_normal')(x)
x = keras.layers.add([x, y])
x = Activation('relu')(x)
num_filters = 2 * num_filters
# x = AveragePooling2D()(x)
# y = Flatten()(x)
y = GlobalAveragePooling2D()(x)
outputs = Dense(label_num, activation='softmax', kernel_initializer='he_normal')(y)
model = Model(inputs=inputs, outputs=outputs)
return model
res_model=resnet_model(2)
plot_model(res_model, to_file='model.png', show_shapes=True)
aeを実装する
お次はAuoEncoderです。これは普通のCNNはだんだん小さくしていってそのまま分類にかけますが、小さくしていったものを再度大きくすれば元の画像と同じ様な画像を作れるのではっていうものです。
元画像と同じの作って何が良いのかと言うと、一度少ない次元まで情報が落ちているので、この落ちたところは上手く特徴を抽出できているのではっていう考えができます。そして同じところまで画像を復元できている。
これを使えば画像の次元削減(マッピング)や画像の生成などができるのではとなります。また、このAEの学習はラベルを使用しない教師なし学習なので、取り出した特徴量の分布から異常検知にも使われたりしてます。
ネットワークはこんな感じです。
input_img = Input(shape=(28, 28, 1))
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same')(x)
encoded = GlobalAveragePooling2D()(x)
x = Dense(4*4*32, activation='relu')(encoded)
x = Reshape((4, 4, 32))(x)
x = Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
autoencoder.summary()
このネットワークでノイズ除去をやってみます。ノイズかけたのを入力、かけていないものを教師データとして、学習します。これでノイズが除去できるネットワークが作成できました。
from keras.datasets import mnist
import numpy as np
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
# ごま塩ノイズを追加
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0., scale=1., size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0., scale=1., size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
autoencoder.fit(x_train_noisy, x_train, epochs=30, batch_size=256,
shuffle=True, validation_data=(x_test_noisy, x_test))
# テスト画像を変換
decoded_imgs = autoencoder.predict(x_test_noisy)
# 何個表示するか
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# オリジナルのテスト画像を表示
ax = plt.subplot(2, n, i+1)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 変換された画像を表示
ax = plt.subplot(2, n, i+1+n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
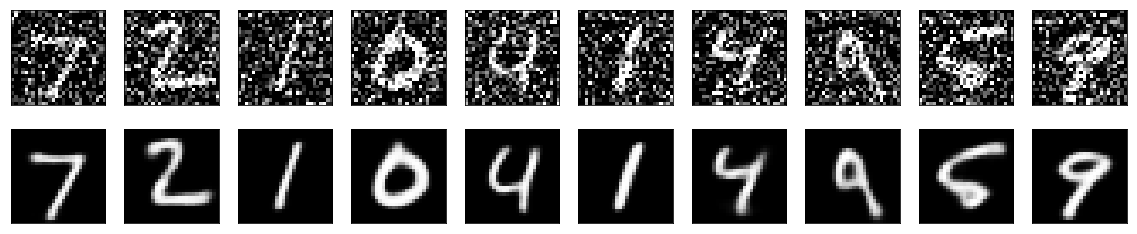
はい、ノイズを除去することができました。この流れの中でラベリング作業をやってないことが重要な点です。画像を得てそれを個別にラベリングしなくてもできるのが教師なし学習の良いところです。その分できることが限られますし、精度も良くない場合も多いですが。
まとめ
これで5ヶ月目は終わりです。NNでも教師なし学習ができるということを確認しました。時間ができたらVAEでのマッピング、異常検知も追加したいと思います。
今回の内容もgithubにあげてあります。モデルの可視化をやろうと思ったんだけれど。上手く来ませんでした。どうにもpydotがないと言われる・・・pydotplusとかpydotng奈良動くという記事もあったけれどどちらも動かず。残念。
教師なし学習といえば異常検知ですが、精度的に難しいところがあり、導入にはかなり工夫が必要だと思われます。この場合の工夫とはAI面ではなく、精度の低いAIを活用するための工程設計、周りへの周知という点です。
まあ教師ありの時も導入の仕方を工夫しないと上手くいかないのは共通ですが、より一層必要ということです。
次回はGANについてやってみたいと思います。正直実務的には前回分だけで十分で今回からはextraという感じです。