この記事は GLOBIS Advent Calendar 2023 の21日目の記事です。
計測はとっても大事ですね。Rob Pike先生もそう言っています。ということで、この記事ではGLOBIS SREチームの1年間を数字で振り返ってみたいと思います。
SREへの依頼を数える
私たちSREチームは、特定のプロダクトに属しているわけではなく、組織横断的にすべてのプロダクトを見ています。そのため、何か不定型な運用作業や、システムの不具合があった場合、様々なチームからSlackの @sre グループメンションで声を掛けられる場合があります。
もらったグループメンションはすべて、Zapierを活用してNotionのデータベースに連携、記録しています。記録されたメンションは毎日の夕会で見直し、漏れがあった場合はチケットを切ったり、メンションが不具合対応依頼なのか、何か作業の依頼なのかなど、分類作業を行っています。
さて、NotionデータベースはCSV形式でエクスポートできます。これをExcelに取り込んでグラフ化することを以前は実施していたのですが、 Excel操作がなかなか面倒で 手動作業の手間があり、なかなか滞っていました。そこで今回は、Googleが提供しているデータ分析ツール、Looker Studioを使ってみました。Looker Studioでは、CSVを取り込んで簡単に表やグラフを作成することができます。
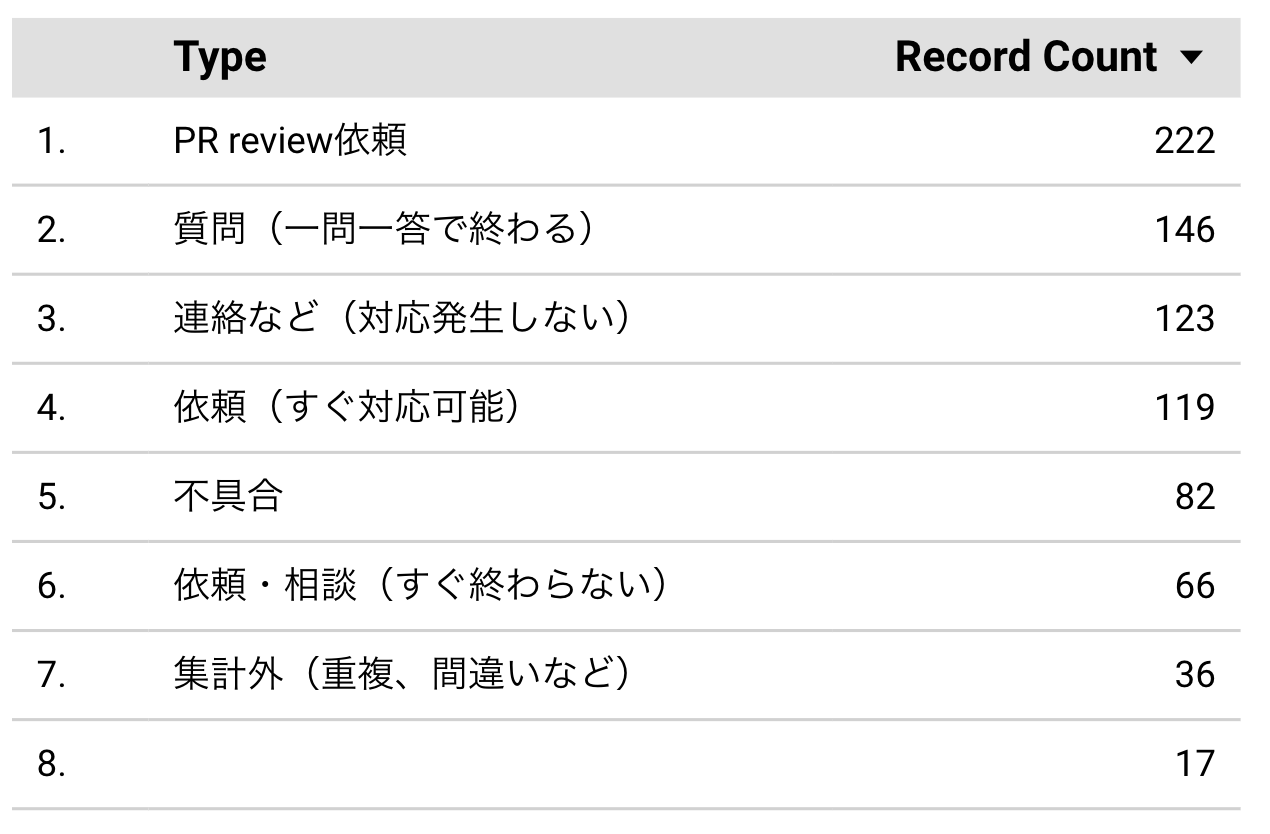
まず年内のメンションを種別ごとに数え上げて表にしてみました。「集計外」を含めて分類は7つを用意しており、迷いなく分類できるよう、それぞれ表現はかなり口語的にしています。ポイントとしては、「依頼」は手作業の依頼、すなわちトイルに該当するものであり、これをなるべく減らしてPull Requestに置き換えることを目指しているということです。
結果としては「依頼」が「すぐ対応可能(単発作業を想定)」「すぐ終わらない(丸1日以上かかるようなものや検討が必要なもの)」を足し合わせても185件であり、「PR Review依頼」の222件を下回りました。ただ、不具合対応も「依頼」と合わせてトイルとして換算すると、合計で300件を超えてきます。手作業の運用は、まだまだ減らす余地があるのかもしれません。
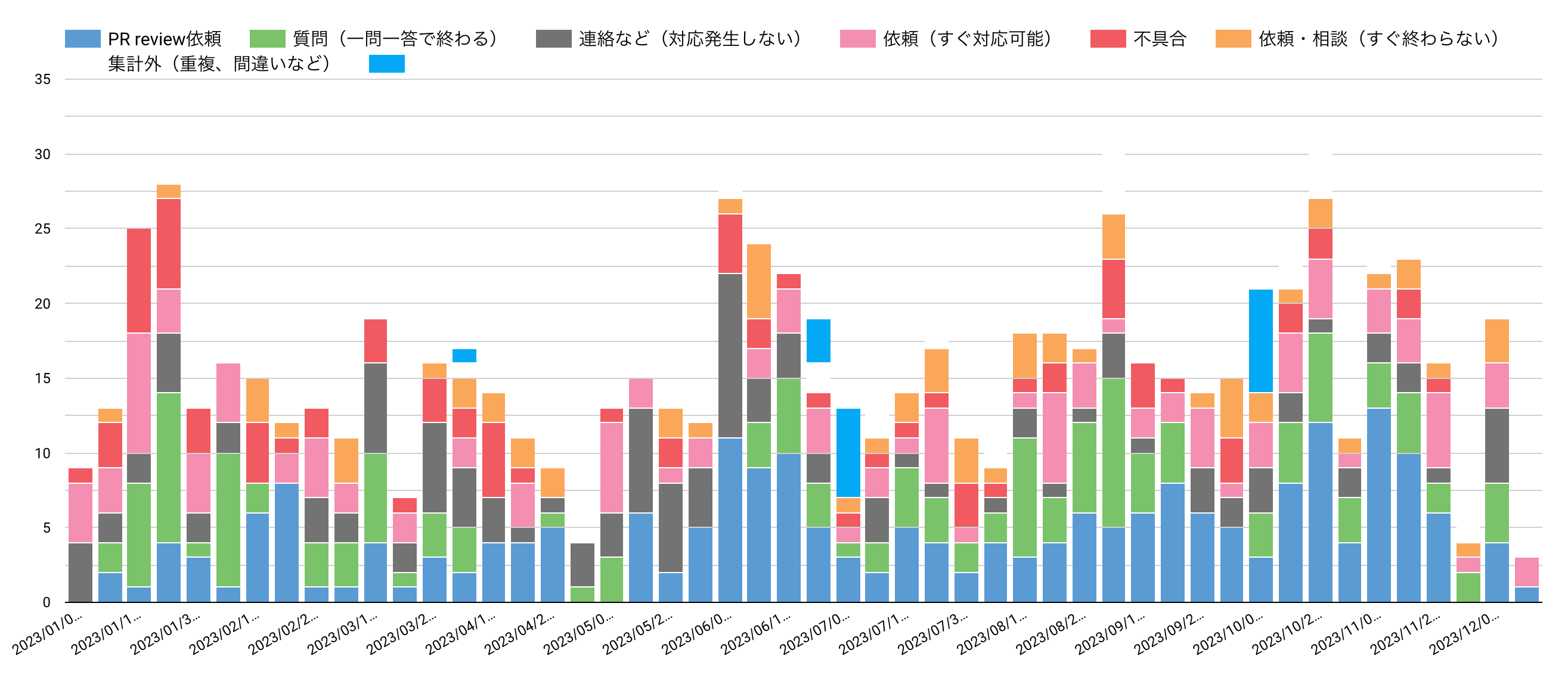
変わってこちらは年間の傾向です。1週間ごとに積み上げグラフの形にしました。こういったグラフもLooker Studioでは簡単に作れます。ただ、このグラフからだとなかなか劇的な変化のようなものは読み取りにくいですね。多少PR Review依頼が増えてきたようにも見えるのですが。
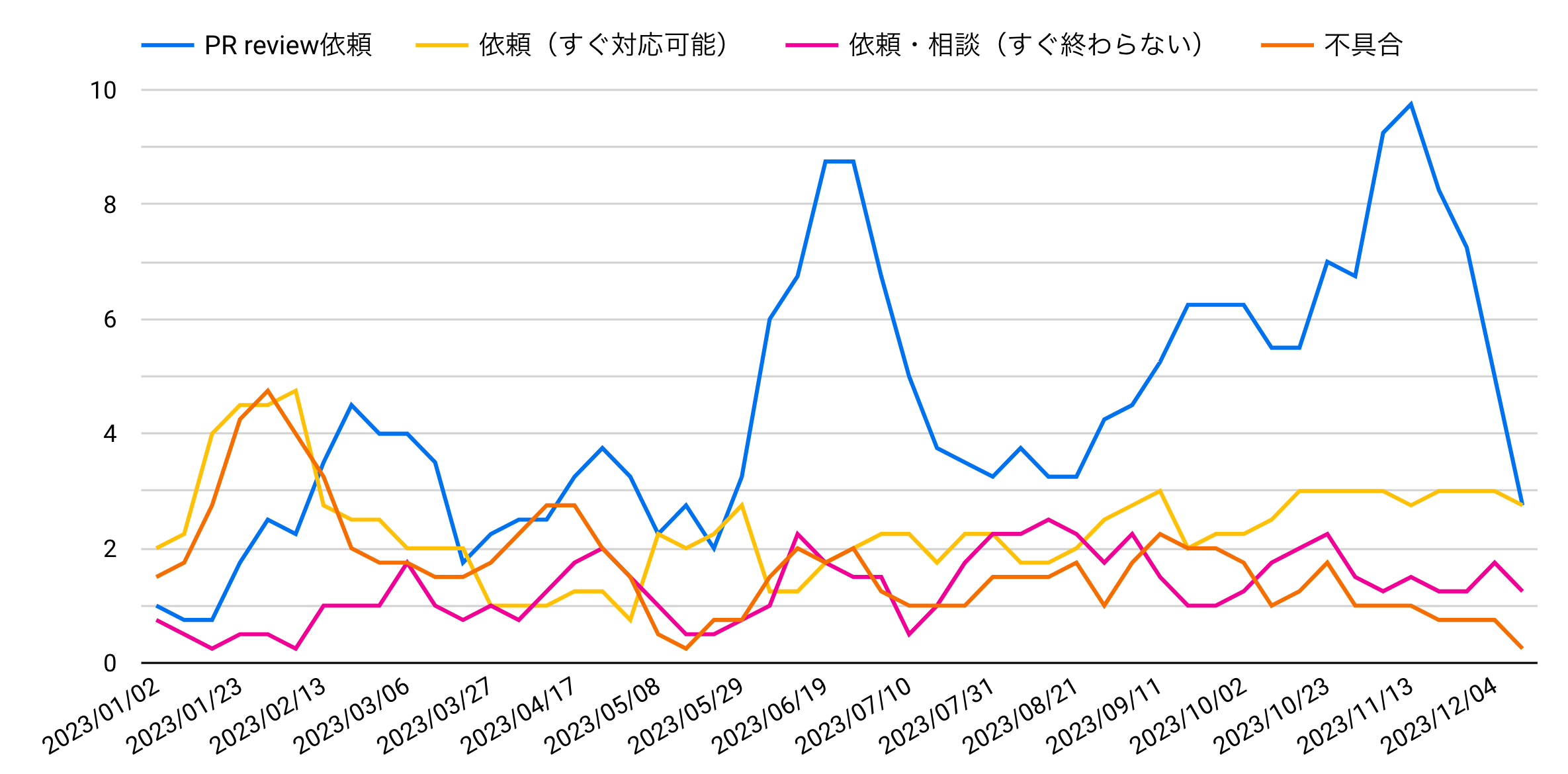
変化を見るには移動平均を使いたいところですが、残念ながらLooker Studioには移動平均を計算する機能がありません。そこで今回は、Excelの AVERAGE 関数を愚直に対象セル範囲をずらしながら適用して、4週移動平均のデータを作成してからLooker Studioへ取り込んでみました。これだと、年間を通じてPR Review依頼が徐々に増えているのがよくわかりますね。
トイルの比率を数える
次はSRE定量化あるあるの1つである、トイルの比率を見てみます。よく言われる理想的割合は、全作業量に対して50%ですね。
私たちのチームではタスク管理にGitHub Projectsを用いており、トイルの集計にもこれを用いています。issueには「Task type」というカスタムフィールドを作成し、Toil、Engineering、OKR(チームOKRに寄与する作業をこの分類としています)の3つから選択しています。集計には単純なissueの件数ではなく、見積もり時のポイントを用いることで、より負荷の可視化として実感に近づけようとしています。
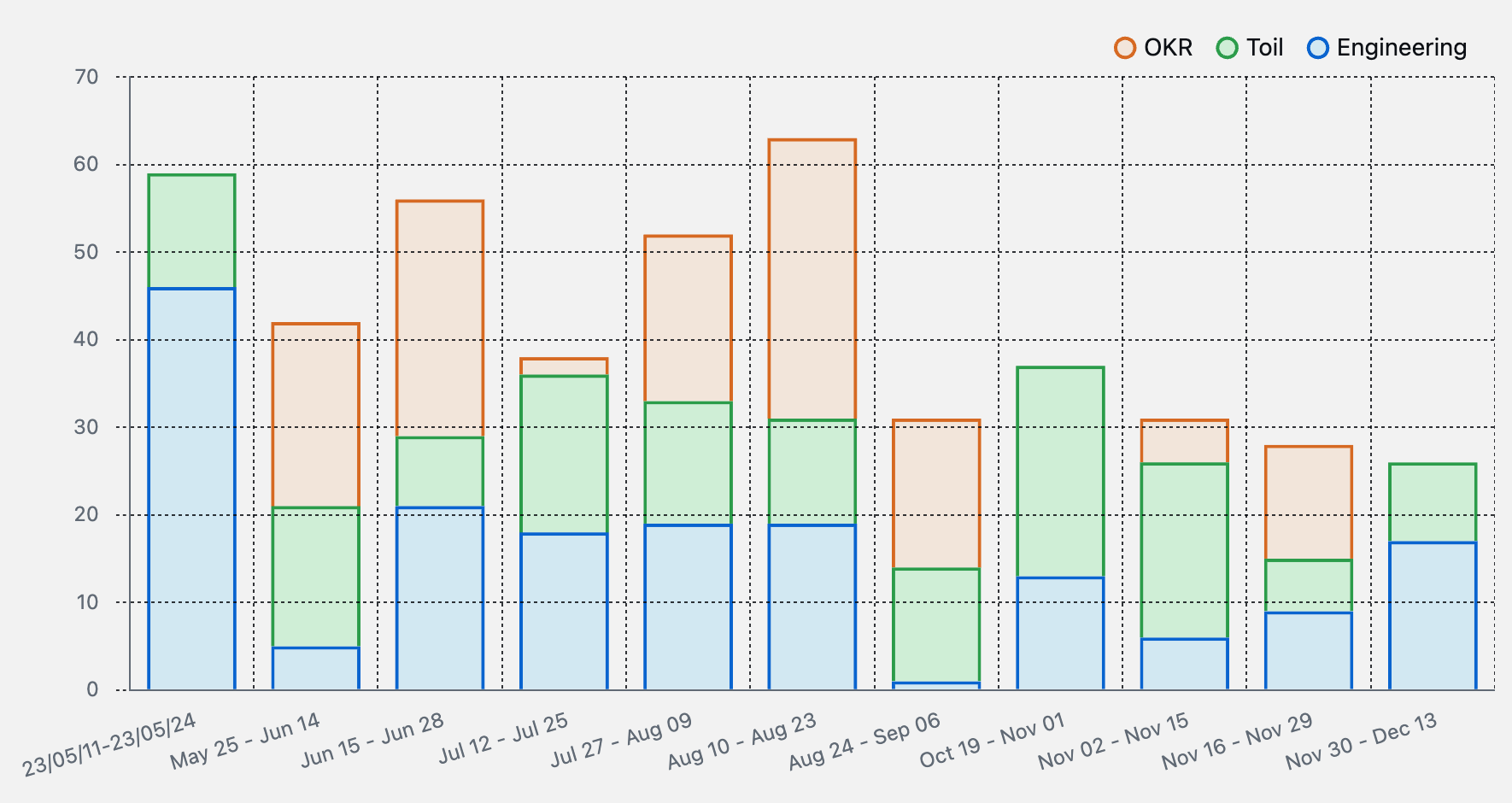
通常時は、このようにスプリントごとの集計を行っています。今年の上半期はそれなりに良い割合に見えますが、特に10月あたりから全体の消化ポイント数の減少と、Toilの割合の増加が見えます。
原因として、10〜12月のクォーターは何件かインシデントがあり、その根本対応に追われていたほか、各種EOLの対応を行っていたことが挙げられます。特にEOL対応は組織横断的なタスクであり、ついチケットを大きく切りがちになり、結果としてスプリント内に消化しきれず、ベロシティが上がらないスプリントが少なくありませんでした。横断的タスクでも、スプリント内で消化できるサイズまで分割し、しっかりフローを流していくことを意識したほうが良さそうです。
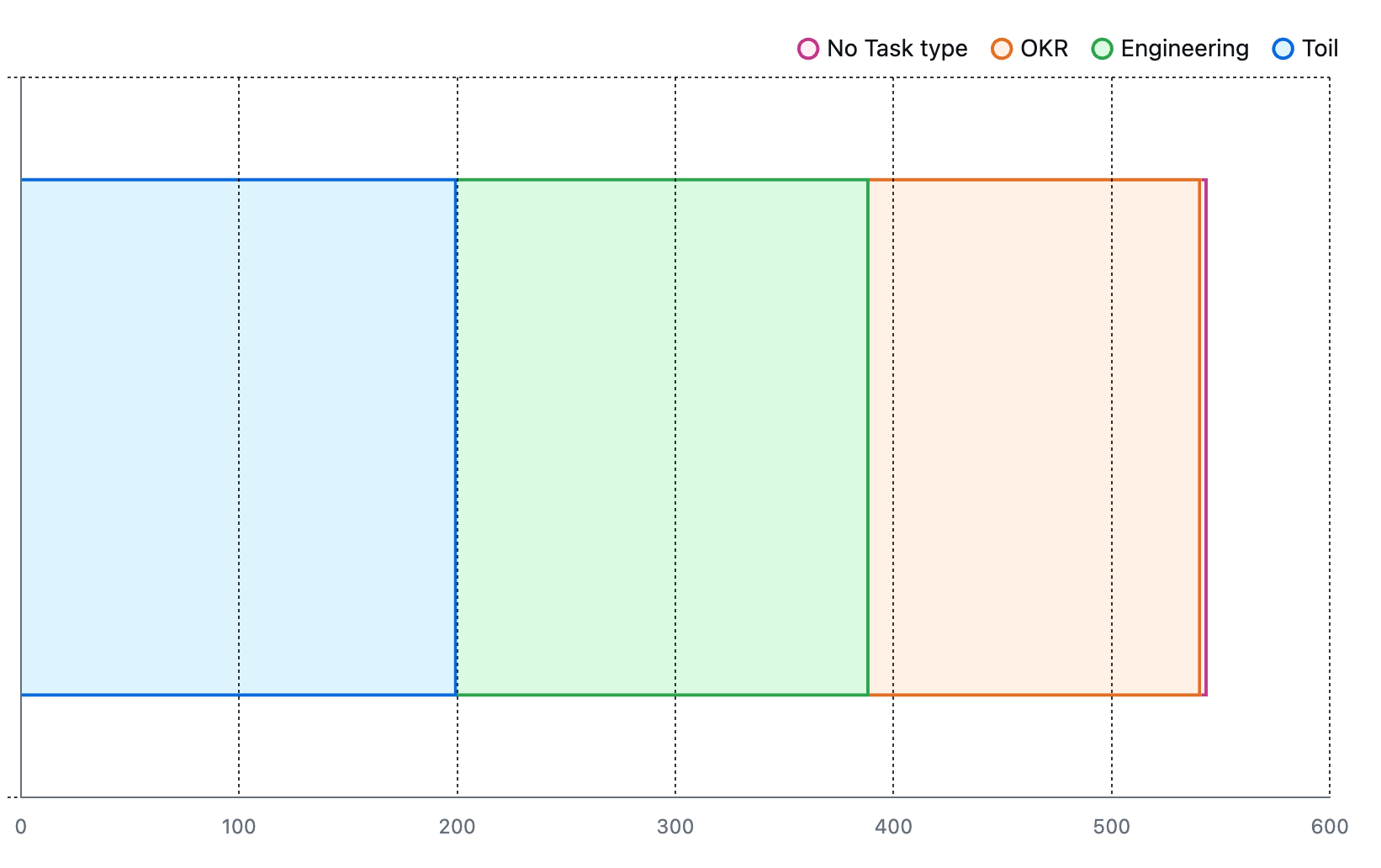
今回の記事にあわせて、年間の集計も行ってみました。GitHub Projectでは closed にした日付などでのフィルタリングはできないため、ざっくりと「直近340日間に更新があった、すでにクローズ済みのチケット( -last-updated:340days )」でフィルタしています。Toilの比率は年間合計で見ても50%を少し下回るような形になりました。
アラートを数える
最後に、SREと言えば信頼性、ということで、アラートの数を見てみます。
緊急コールを数える
監視にはDatadogを用いているのですが、Datadogのアラート履歴はEvents Explorerで一覧化できます。もちろん、通知先やアラートのタイプなど、様々なメタ情報でフィルタリングも可能です。今回は、Twilio webhookを通じて、SREに緊急電話コールが行われたアラートだけを抽出してみました。なお、弊社ではDatadogを複数のOrganizationに分けて運用しているのですが、今回はそのうち最大のOrganizationのみを対象としています。

11月前後にピークがありますが、それ以外のところだと0件の期間も多く見えます。実際のところ、弊社のシステムは今年1年、あまり大きなトラブルに苛まれることはありませんでした。11月のコール多発の原因ですが、
- 10月末にあるサービスのクローズがあったが、クローズ後も一部監視が残存していた(作業漏れ)
- あるシステムのKubernetesへの移行後、コンテナ上で予期せぬ挙動が発生し、不安定になっていた(バグ)
という2点があったようです。後者に関しては、nginxに関する罠のような挙動にハマったのですが、これだけで1記事書けそうなので、ここでは詳細は省きます。
アラートの増加は必ずしもネガティブではない?

一方で、コールではなくSlack通知のみにとどめた軽微なアラートの件数をグラフにしてみると、また少し違う傾向が見えます。
特に9〜10月以降、かなりアラート数が増えているのがわかります。この理由を探ると、新たに設定されたmonitorによるものでした。もともとDatadogで監視を組むのは、ほぼSREの専門業務として行っていましたが、SREからプロダクト開発チームに対して、Datadogの使い方を浸透させる活動を行っており、その結果開発チームが自らAPMやRUMを設定したり、必要なアラートを追加することが増えているのです。この9月以降の上昇は、 Core Web Vitals の計測を、一部のチームが始めたことによるものでした。
もちろん、アラートが出ていること自体は見直しも必要ではありますが、Datadogの活用の幅が広がっていることも、このような可視化からは読み取ることができます。
SREは何を定量的に測っていくのか
今回触れた以外にも、SREチームでは様々なものを計測したり、可視化したりしています。ただ、あまりに指標が多すぎても、すべてを追い切れるわけではありません。そこでちょうど最近の取り組みとして、SREが追うべき指標の再考と、優先順位の付け直しを行っています。SREは直接的に売上を上げるような役割を担うのは難しいですが、間接的に寄与したり、あるいは利益貢献のためのコスト削減を行ったりすることはできます。そのような視点で模索しているところです。
また、指標の目標値をどのように置くのかも重要です。『97 Things Every SRE Should Know』には以下のように書かれています。
Why is the toil-to-project work ratio 50:50? Is that the right number, rather than 20:80, or indeed having no fixed ratio but a flexible approach?
(Google翻訳:トイルとプロジェクトの作業比率が 50:50 なのはなぜですか? 20:80 ではなく、この数字が正しいのでしょうか、それとも固定比率ではなく柔軟なアプローチを採用しているのでしょうか?)
(Niall Murphy "93. SRE in Crisis" より)