※ 2020-12-22 追記あり
はじめに
この記事は GLOBIS Advent Calendar 2020 - Qiita 17日目の記事です。
GLOBIS SRE チームでは2020年初頭より、 Kubernetes (Amazon EKS) を用いたインフラ環境の全面的な刷新に取り組んでいます。この新たな環境では Infrastructure as Code で環境の9割はコード化するという目標を立てており、 Terraform を積極的に活用しています。
この記事では、そんな弊チームでの Terraform の使い方についてまとめていきます。書き始めたら書きたいことが湯水のように湧いてきてしまったので、FAQ形式でまとめてみました。気になるところを拾い読みしてみてください。
Terraform 全般
Q. Terraform で何を管理していますか
AWS がメインの環境なので、書いている Terraform のうち8〜9割は AWS を対象としています。あとは Datadog の監視設定、ちょっとだけ GCP の IAM 管理もやっています。
Q. Amazon EKS の構成はどのようになっていますか
ざっくりこんな感じです。
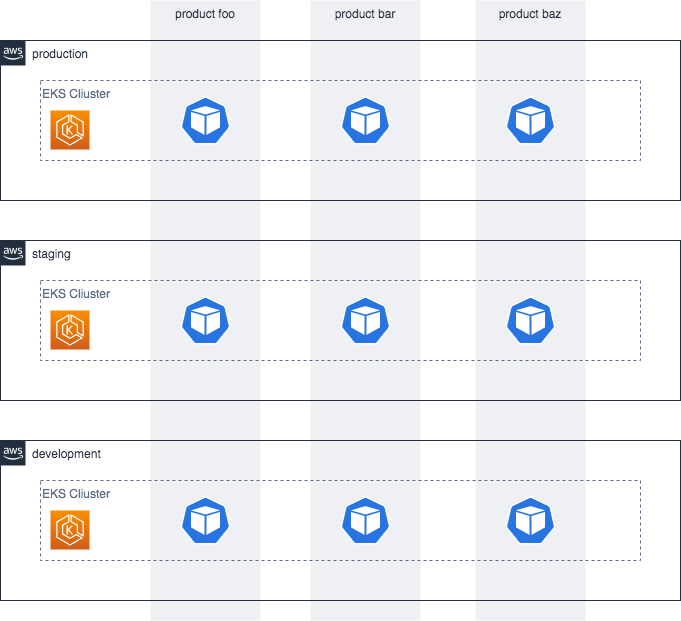
AWS アカウントは本番環境、ステージング環境、開発環境の単位で分割しています。それぞれ EKS cluster が1つずつ存在していて、各プロダクトで共用しています。図には表せませんでしたが、プロダクト間は Namespace により分離しています。
Q. 誰が Terraform を書いていますか
SRE チームのメンバー全員で書いています。非 SRE のエンジニアが書くことは現時点ではほぼありません。
ただ、例えば IAM user の払い出しなど、チーム外からの「依頼」をトリガーに SRE が Terraform へ起こしているものがあるのですが、こういったものは少しずつ Terraform への PR で受ける形に変えられるのではないか、ということで試みつつあるところです。
Q. なぜ Terraform を選んだのですか
デファクトスタンダードに近い位置を占めているツールなので、正直比較検討はほぼ行わずに選んでいます。代わりうるツールとしては CloudFormation (CFn) 、 aws-cdk 、 pulumi あたりかなと思いますが、 Terraform で大いに苦しんでいるわけでもないので、移行検討することもまず無さそうです。ここまでエコシステムが大きくなると、その居心地の良さからは抜け出せそうにないです。
cdk はちゃんと触れたことがないのですが、型のある、本当のプログラミング言語を用いた as code というのはちょっと気になっています。 CFn については、直接使うものというよりは、 cdk や Serverless Framework などから間接的に呼ばれるものになりつつあるな、という認識が個人的には強いです。
Terraform を責任分界する
Q. Kubernetes と Terraform はどのように棲み分けていますか
Kubernetes (k8s) manifest と Terraform では、管理可能なリソースがバッティングします。 AWS Service Operator を使えば k8s manifest で AWS リソースが管理できますし、 Kubernetes Provider を使えばその逆もできます。
従って Terraform は何を管理するのか? という、他ツールとの責任分界点の定義が必要になりますが、弊チームではシンプルに言えば以下を原則としています。
- k8s manifest で AWS リソースは管理しない
- Terraform で k8s のレイヤーは管理しない
理由としてはライフサイクルの違いです。弊チームでは EKS cluster は使い捨てるものです。 Kubernetes version up を B/G deploy の概念で実施しており、3か月に1回、新たな cluster を作って乗り換えています。 EKS cluster 外にある Aurora 、 S3 、 ALB といったリソースは、そのサイクルと運命を共にする必要はありません。従って k8s 上から、 cluster 外にある AWS リソースは管理しないこととしています。
端的な例としては、 ALB Ingress Controller を採用しなかったことが挙げられます。 ALB 配下で B/G deploy を行いたい関係上、 ALB が k8s のライフサイクルに縛られる状況は避ける必要がありました。代替策として、泣く泣く NodePort を使っていたので、 AWS Load Balancer Controller の登場は本当に朗報でした。
Q. k8s と Terraform の間で依存関係が発生したりしませんか
無くはないです。
例えば Secrets の管理は、 Kubernetes External Secrets と AWS Parameter Store の SecureString を組み合わせて使っています。 external secrets を呼び出したけど、連動する Parameter Store をまだ設定してなかったので、 Secrets が生成できてない、ですとか、たまにあります。とはいえ、そんなに大きな問題というわけでもないです。
他にも セキュリティグループを Pod に設定可能になったり ですとか、 k8s と AWS リソースの境界は常に揺らいでます。その中で両者をどう依存させてどう管理するかは、ずっと考え続けながら運用するんだろうな、と思っています。
Q. Terraform (state) はどのように分割していますか
state の分割境界は Terraform 界隈だと昔からホットなテーマです。結論から言うと以下のように、かなりシンプルな構成になっています。
├── account_bootstrap
│ ├── dev
│ ├── modules
│ ├── prod
│ └── stg
├── base
│ ├── dev
│ ├── modules
│ ├── prod
│ └── stg
├── product_foo
│ ├── dev
│ ├── modules
│ ├── prod
│ └── stg
└── product_bar
├── dev
├── modules
├── prod
└── stg
プロダクト関係のリソースは、開発環境、ステージング環境、本番環境、という形で分割されています。基本的にはこれだけです。よく耳にするのは、同じプロダクトの中でもライフサイクルによって state を分割するパターンですが、頻繁に変更が入るリソースは k8s 上に存在する形になったため、その観点が無くともあまり困ってはいない現状です。
プロダクト以外では account_bootstrap と base という2つが存在し、いずれもプロダクトを横断して、 AWS アカウントの基盤を担っています。 account_bootstrap は、 AWS アカウントを作成後一番最初に実行するべき、 budget alert や AWS config などの設定が入っています。 base は EKS cluster などの基盤リソースです。違いがよくわからん、とチームメンバーに言われた記憶もありますが、例えば AWS organization の root 用アカウントでは account_bootstrap は必要ですが、インフラ環境はホストしないので base は不要です。
これらは1つのレポジトリの中で管理しています。唯一別レポジトリに切り出しているものとしては、インフラとはまったくライフサイクルが異なる IAM user があります。
Q. Terraform で管理していない AWS リソースはありますか
ほとんどないです。ないはずです。 AWS Chatbot など、 API が公開されていないが故に導入をやめたサービスすらあります( API 公開待ってます)。それぐらいには Terraform 管理が大原則になっています。
どうしても Terraform が対応していない、手動でやらなくちゃいけない、というときはチームメンバーに確認取った上で実施して、手順を残すようにしています。
Terraform を実行する
Q. terraform apply は誰が実行していますか
すべて自動実行です。弊チームでは terraform コマンドを手動で実行することは極力避けています。以下のように、手動実行は煩雑な側面が避けられないからです。
- Terraform は state にバージョン情報が埋め込まれるので、個人のローカルで実行するとバージョン切り替えの問題が大きい。
- state ごとに適切な AWS profile に切り替えて実行するコストが大きい。
自動実行には Terraform Cloud を活用しています。採用理由としては、現在のメンバー数であれば無料で使用を始められたことと、自分たちでパイプラインを組まなくても、 Terraform Cloud と対象の GitHub レポジトリを連携させるだけで、簡単に自動実行可能になるという手軽さがありました( PR に合わせて plan が、 default branch への merge に合わせて apply が自動実行されます。 apply 前に承認フェーズも挟めます)。
Q. Terraform Cloud ってどうですか
先述したとおり、簡単に自動実行が組めるのはとてもよいです。これを導入するだけで、チームの Terraform 実行サイクルに秩序が生まれます。
不満点はざっくり3つあります。
同時実行数制限
同時実行数がかなり厳しいです。1つの state の排他制御の話ではなく、別の state に対する実行であっても、同時実行数制限がかかります。詳しくは Pricing に書かれていますが、無料だと同時実行は一切できません。
さすがにしんどいので、今は Team & Governance plan を使っています。さらに上のプランも見積もってもらったことはあるのですが、価格面で断念しました。どれぐらいの価格か気になる方は、先日 HashiCorp Japan の方が参考価格を開示していたので、そちらをご参照ください。
まだ k8s へ移行したプロダクトの数が多くないのでなんとかなっていますが、本格的に耐えられなくなったらパイプラインは Codebuild か GitHub Actions あたりに移すかもしれないな、というぐらいには大きいつらみです。
workspace の名前重複問題
Terraform state 1つに対して、 Terraform Cloud 上に実行環境を1つ作るのですが、これが workspace と呼ばれます。そして terraform workspace コマンドとは何も関係がありません。 The Path to Terraform 1.0 の中で HashiCorp が自己言及しているので、どこかで直るだろうとは思っていますが。
Did you know that workspaces in Terraform Cloud, and workspaces in the Open Source CLI, are two different things? That's a pain point.
terraform import が面倒
Terraform の実行を普段は Cloud に任せているので、 API キーなども Cloud 側 へ設定することになります。 plan や apply を Cloud 上で実行するときは、この Cloud 側の変数が読まれることになります。
問題は import のときで、このコマンドは Cloud 上ではなく local で実行されるのですが、 変数は Cloud のものを読む という形になります。 Terraform Cloud と連携している限り、変数は常に Cloud のものが最優先で使われ、 local 側で上書きはできません。
しかし、 API キーなどは sensitive な変数として Cloud に登録するので、 local からは読めません。読み出そうとするのですが、読めません。結果 API キーを設定する手段がなく、 import は失敗します。
回避策としては provider に直接 API キーを埋め込む形へ書き換えたりする必要があります。 local で設定した変数を最優先にするよう、 priority の調整をしてほしいな、と思っています。
provider "aws" {
region = "ap-northeast-1"
# access_key = var.AWS_ACCESS_KEY
access_key = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
# secret_key = var.AWS_SECRET_KEY
secret_key = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
}
2020-12-22 追記
その後の調べで、 Terraform の variables ではなく、環境変数であればローカル側で上書きできることがわかりました。したがって provider "aws" 内の access_key 等の記述を削除して、 workspace に AWS_ACCESS_KEY_ID 等の環境変数を設定しておけば OK です。
ただし、当然ながら複数 AWS アカウントにまたがって実行する workspace の場合は、この方法では対応できません。
Q. Terraform の CI/CD で、他に実施していることはありますか
Terraform Cloud による自動 plan apply 以外だと、 PR を作成した際に、 GitHub Actions で terraform fmt -check を自動実行しています。
Terraform を書く
Q. module って使っていますか
使っています。ほぼお手製の private module です。
Q. Terraform Registry の公開 module は使わないんですか
Terraform Registry 上の module ……仮に public module と呼びますが、 public module を使っていないわけではないです。 terraform-aws-eks なんかは最初見たときわりと感動しましたし、とても便利に使っています。
private module がメインになっている大きな理由の1つには、なるべく設定を標準化したい、というのがあります。例えば CloudFront であれば古い暗号スイート使いたくないよね、であれば module の default に最新暗号スイートを設定してあげて、それとなく促します。つまり我々のベストプラクティス設定の集合として private module を使っています。手順書や設定書がなくとも、 private module を使えば自然とあるべき形でインフラ構築が可能になっています。
Q. さっき、 product のディレクトリの中にも modules ってありましたけど?
ここ での話ですよね。そうですね。
複数プロダクトで共有しない、する必要のない module は private module registry に登録せず、プロダクト内に内包してしまっています。変更による影響範囲が小さいからです。
Q. 汎用的な module を作るの難しくないですか
難しいです。いろいろ意識はしています。
- 認知負荷を上げない
- 変更容易性を保つ
- 安易な DRY で使わない
それでも最初から完全な汎用性を実現するのはやはり難しいので、やりたいことが増えたら適宜 module を更新するサイクルとしています。わりとガンガン更新は入っています。
Q. module をガンガン更新すると影響が大きくなりませんか
module は複数プロダクトでまたがって使うので、ただ変更を加えると影響範囲が大きくなります。なので Terraform Cloud の private module registry を使っています。
これは要するに Terraform Registry の private 版です。 GitHub に private module のレポジトリを作成し、それと連携させることで、 Terraform Cloud 経由で module のダウンロードが可能になります。
module "elasticache" {
source = "app.terraform.io/globis/elasticache/aws"
version = "2.0.0"
}
ポイントは git tag と連動して version 管理ができるようになることです。これにより、 module の更新が即時的に大きな影響をもたらすことは避けられます。一方で「追従が面倒」という側面も確かではあります。
Q. module を更新する際、動作確認はどうしていますか
主に2つあります。1つは module のレポジトリに、その module を source としたダミーの terraform file を example として置くことにしています。 PR を作成した際、 GitHub Actions からこの example を対象に terraform validate が実行されるようになっており、最低限 validate は通る形を維持しています。
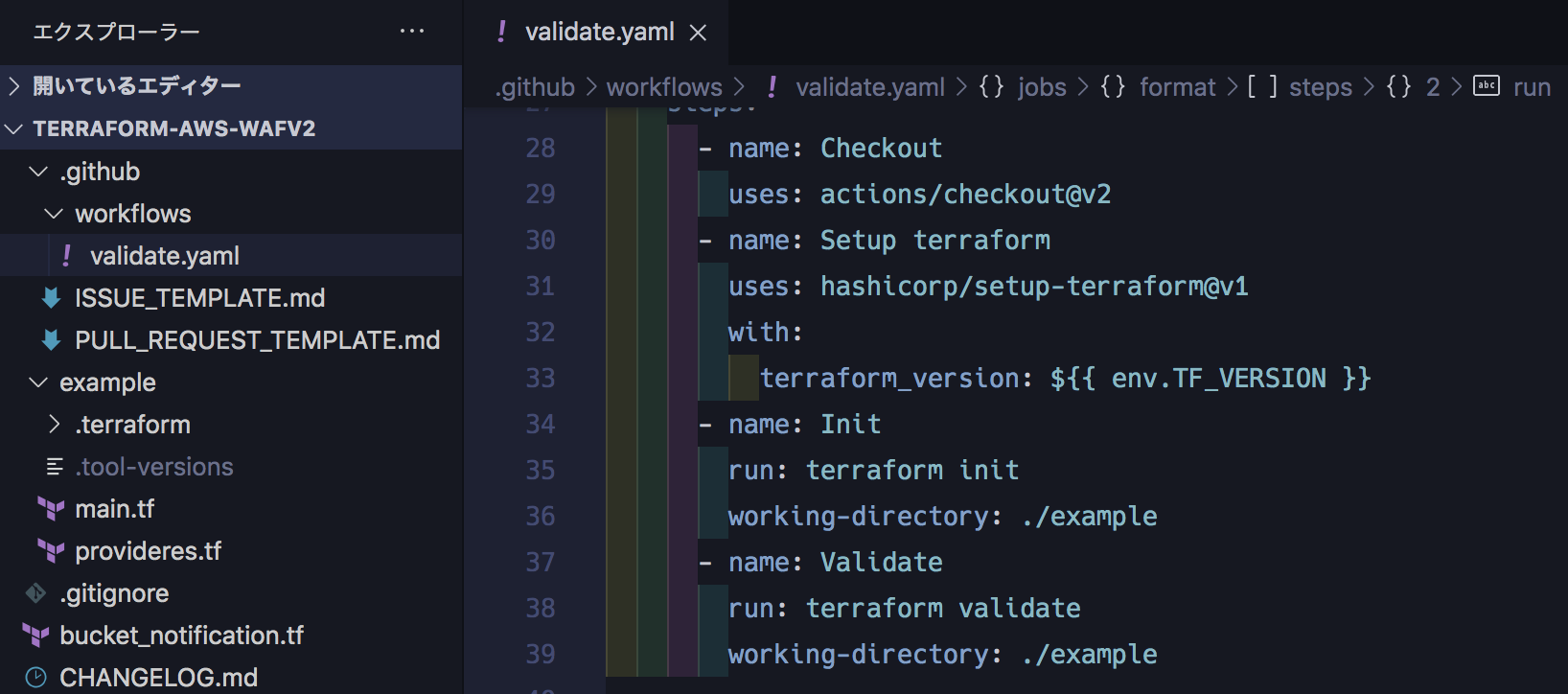
もうひとつはバージョニングの工夫です。1つ前の質問で、 private module registry によりバージョン管理が可能と書きましたが、これは 2.0.0-alpha のようなプレリリースバージョンの記法にも対応しています。開発中はプレリリースバージョンとして発行してもらい、その上で開発環境で挙動を確認して、問題がなければ正式版リリース、という流れを組んでいます。
Q. 平文で HCL に書けない情報はどうしていますか
sops を使っています。ダイレクトに宣伝ですが、拙ブログをどうぞ。
Q. エディタは何を使っていますか
VSCode 派と IntelliJ IDEA 派がいます。僕は VSCode 派です。 terraform-ls が徐々に良くなってきましたね。
Q. 他に Terraform の書き方で気をつけていることはありますか
よく言われることも含まれていますが、以下あたりです。
- remote state はあまり使わない(参照されている側が、何を参照されているのか把握するのが難しく、依存関係が管理しづらい)
-
countではなくfor_eachを使う - required_version は
~>で指定して、不意のメジャーバージョンアップを防ぐ - function は積極的に使っているが、可読性が極端に落ちそうであれば要相談
Terraform について、いつかやる
Q. Terraform Version は最新に追随できていますか
できていません。 面倒くさいですよね? とはいえ何もやっていないわけではなく、現状ほぼ 0.13 系ではあります。最新は 0.14.2 らしいですけど。
単純に作業量の多さがネックになっています。 tfupdate などで解決するかと言うと、それだけの話でもないのです。手順は以下のようになります。
- module の
required_versionを上げる。 - 各 Terraform file 側の使用バージョンを上げる。
- Terraform Cloud が実行時に使うバージョンを、各 workspace ごとに上げる
Cloud を経由している関係もあって、なかなか手数が多いのです。特に GUI で Terraform Cloud のバージョンをポチポチするるのが面倒で CLI 作るまでしました(宣伝2回目)。 Cloud を GUI から操作するのは結構つらくて、別のメンバーも弊社向けの設定が一発で完了するコマンドツールを作っていました(公開はしていません)。
これに加えて provider のバージョンアップもあります。大変だけどやらなきゃね、としか今は言えていません。
Q. テストってどうしてますか
できていません。
夢の話をすると Serverspec みたいな感じで、 Terraform 実行後に AWS リソースが想定通りの状態にあるか動的に検証したいんですが、それはちょっとムリだと思うので tflint のような静的なチェックツールはそろそろ入れなきゃな、と思っています。来年の課題です。
現状は開発環境に apply して動作確認して、問題なければ他の環境へ展開、という手順です。