YouTubeの再生回数をひたすら記録したいときってありますよね?
わたしはあるダンス動画にドはまりし、その再生回数がメディア露出と紐づくのか気になったので取得しようと思い、Youtube Data APIとLambdaとCloud WatchとGoogle スプレッドシートを使ってひたすら回数を記録するようにしました。
Python 3.7、環境はWindowsです。Macの場合コマンドなどを読み替えてください。
参考
下記を参考にして作りました
https://qiita.com/akabei/items/0eac37cb852ad476c6b9
https://qiita.com/masaha03/items/fab8c8411a020ff2bd42
APIを有効にする
Youtube、Googleドライブ、GoogleスプレッドシートのAPIを有効にします。
-
GCPの利用登録をする
APIのみの利用でもGCP上でプロジェクトの登録が必要です。プロジェクト名は任意で大丈夫です。 -
APIのライブラリからAPIを有効にする
「APIとサービス」のライブラリより、APIを検索する。
Youtube Data API、Google Drive API、Google Sheets APIを検索し、有効にします。 -
認証キーを取得
「認証情報」からキーを作成します。
Youtube Data APIはAPIキー、Google Drive API、Google Sheets APIはサービスアカウントで認証します。
サービスアカウントはJSONファイルで保存しておきます。
スプレッドシートの用意
スプレッドシートを用意します。
(今回シート名は初期設定で作成しています)
- スプレッドシートの設定
スプレッドシートを共有化します。
作成したスプレッドシートの「共有」より、サービスアカウントで取得したJSONに記載されている「client_email」のメールアドレスを入力します。
Youtube再生回数の取得とスプレッドシートへの書き込み
再生回数とコメント数をスプレッドシートに書き込みする。
再生数とコメント数の間に再生数の差分をスプレッドシート側で設定するため、書き込み時では空欄とする。
import gspread
import json
import const
from datetime import datetime
from googleapiclient.discovery import build
from oauth2client.service_account import ServiceAccountCredentials
def youtube_count(request, context):
YOUTUBE_API_KEY = const.getYoutubeApiKey()
# 取得したいYoutubeの動画ID
YOUTUBE_MOVIE_ID = '動画ID'
# APIキーで認証
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
# 再生回数、コメント数を取得(これに加えていいね数も取得可能)
statistics = youtube.videos().list(part = 'statistics', id = YOUTUBE_MOVIE_ID).execute()['items'][0]['statistics']
#下記の通り記載しないとリフレッシュトークンを発行し続けなければならないらしい
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
#ダウンロードしたjsonファイル名を設定
credentials = ServiceAccountCredentials.from_json_keyfile_name('ファイル名', scope)
#OAuth2の資格情報を使用してGoogle APIにログインします。
gc = gspread.authorize(credentials)
#共有設定したスプレッドシートキーを変数[SPREADSHEET_KEY]に格納する。
SPREADSHEET_KEY = const.getSpleadsheetKey()
#共有設定したスプレッドシートのシート1を開く
worksheet = gc.open_by_key(SPREADSHEET_KEY).sheet1
# 現在時刻
now_date = datetime.now().strftime("%Y/%m/%d %H:%M")
# 書く
worksheet.append_row([now_date,statistics['viewCount'], '', statistics['commentCount']])
メインファイルのほか、サービスアカウントのJSONファイル、記入するスプレッドシートのキーとYoutube Data APIのAPIキーを記載したconst.pyのファイルを同じ階層に配置する。
Lambdaに設定する
作成したPythonファイルをLambdaに設定する。
-
ライブラリをLambda Layersに設定
結構詰まったので別の記事にしています。
https://qiita.com/chr36/items/eb6e98f81c8d358ae64c -
Lambdaを設定する
(AWSのアカウント作成は割愛)
Lambdaより「新しい関数」を選択し、関数を作成する。
上記で作成したコードと設定ファイルをデプロイし、登録したLayersを紐づける。 -
タイムゾーンの設定
日付と時間を出力するため、タイムゾーンを設定する必要がある。
今回は環境変数でタイムゾーンを「Asia/Tokyo」と変更していますが、公式では非推奨だそうです。
http://blog.serverworks.co.jp/tech/2019/10/30/lambda-timezone-2/ -
その他設定
Youtube API、取得にちょっと時間がかかることがあるらしく、タイムアウト初期設定の3秒だと取得に失敗することがある。
また、失敗時の再実行は初期設定で2回のため、初期設定のままだと2回同じ内容が記録されてしまうことがある。
そのため、タイムアウト時間を10秒程度、取得できなくてもよいのであれば再実行を1回以下にしておく。
CloudWatch Eventsの設定
CloudWatch Eventsをトリガーとしました。
今回はとりあえず1時間に1回取得すればいいと思ったので、スケジュール式で1時間に1回取得するようにする。
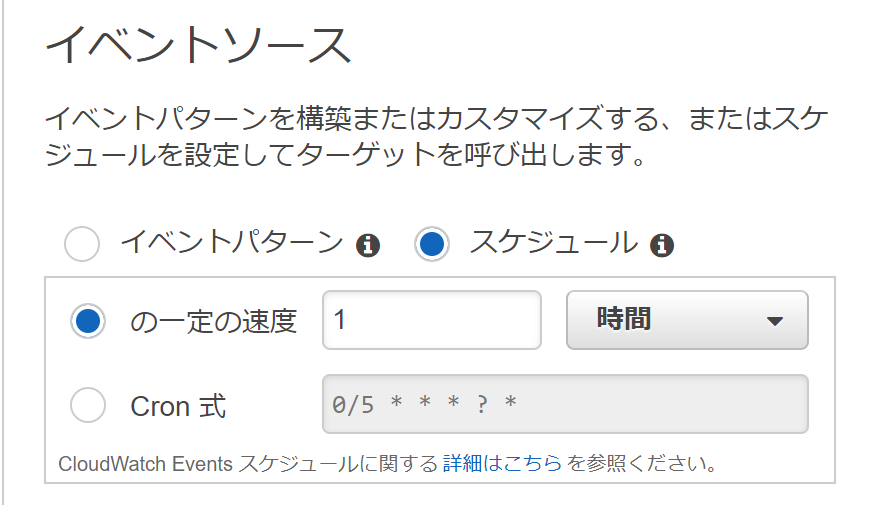
これでスプレッドシートに自動で書き込みがされる。
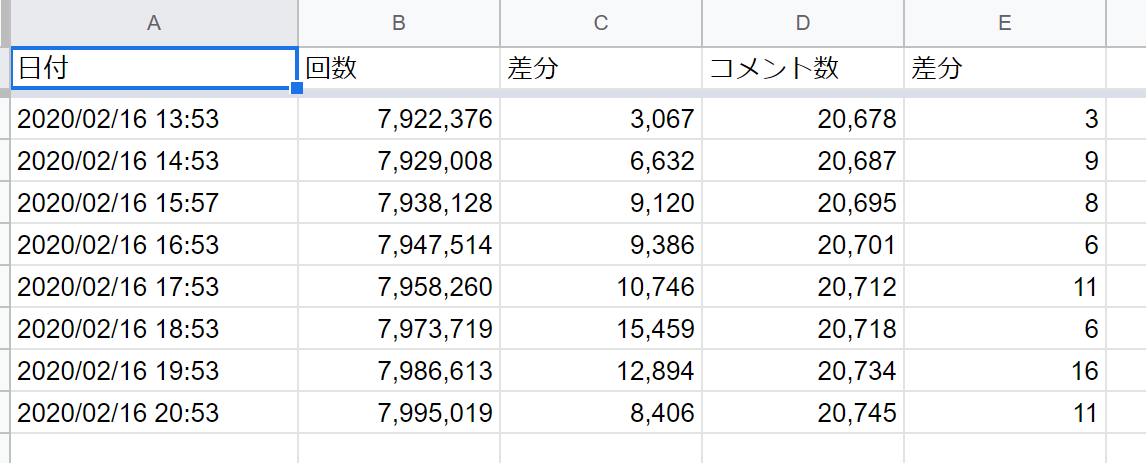
スプレッドシートに書き込まれた後、書式設定や再生回数の差分をGASを使い自動計算するようにしていますが、これはまた後日。
最後に
はまった動画はこちら。Snow Manの「Crazy F-R-E-S-H Beat」です。
https://www.youtube.com/watch?v=lfVfBqkk2Vo