この記事はAkatsuki Advent Calendar 2016の17日目です。
はじめまして。
株式会社アカツキでサーバエンジニアもどきをやっている@chostyです。
最近職場で「労働は健康に悪い」と言い続けています。
個人的に機械学習、データ解析に興味があって、ちょこちょこ取り組んでいます。
これまではこの辺のことをRでやっていたのだけど、Pythonも触ってみたいなーというところがあったので、Kaggleでさくっとチュートリアルなことをやってみたっていう記事を書きます。
Kaggleとは
データ解析系なコンペティションサイトです。公式サイトはこちら。
データセットとテーマ(目的)が企業や研究者から提示されていて、それに対してのスコアを競うものです。
いいスコアを出すと賞金が出たり、リクルーティングなお話がきたりするそうです。いい話ですね。
去年はリクルートが日本企業で初のコンペティションを開いていて話題になったりしていました。
当時で34万人ぐらいのデータ分析者がKaggleに登録してたみたいです。
と、そんな感じのサービスなのですが、企業や研究者が出しているコンペティション以外にも、Kaggle側が提供している学習用のコンペティションがあったりします。
今回はその中の一つをやってみようということで、タイタニック号の生存者予測問題に取り組んでみます。
https://www.kaggle.com/c/titanic
課題
タイタニック号の生存者予測問題は与えられたデータからタイタニックに乗船したその人の生死を予測するものでそのまんまです。
上記サイトからtrain.csvとtest.csvをダウンロードして、どのような特徴量が与えられているか見てみます。
| 特徴量 | 意味 |
|---|---|
| PassengerID | Kaggle側がつけたただのID |
| Survived | 生還したか(0 = NO, 1 = Yes) |
| Pclass | 客室クラス |
| Name | 名前 |
| Sex | 性別 |
| Age | 年齢 |
| SibSp | 一緒に乗った兄弟、配偶者の人数 |
| Parch | 一緒に乗った親、子供の人数 |
| Ticket | チケット番号 |
| Fare | 旅客運賃 |
| Cabin | キャビン |
| Embarked | 乗船箇所 |
上記の特徴量の中から予測に効きそうなものを探して、それを使って予測モデルを作る流れになりそう。
モデルを作る際には仮説を立てて調べていくのがよくて。例えば、ファーストクラスな客室にいた人は生存率高いとか、一緒に乗ってる家族が多く、かつ男性だと生存率が低いとか考えていくと良いかも。
その上で効かない特徴を削除して、何か効きそうなものを自分で加えるとかそういう方法をとった方が今回は筋がいい気がします。
ただ今回はさくっとやるのが目的なのでその辺は横においときます。
ちなみに当然なんですけどSurvivedはtrain.csvにしかないです。
データを眺めてとりあえずやってみる
ここからPythonでデータを取り込んで、どんな値が格納されているのかを見ていきます。
## 準備
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
train = pd.read_csv("train.csv")
train.head() #データの頭5行分出力する
train.info() #データの型確認
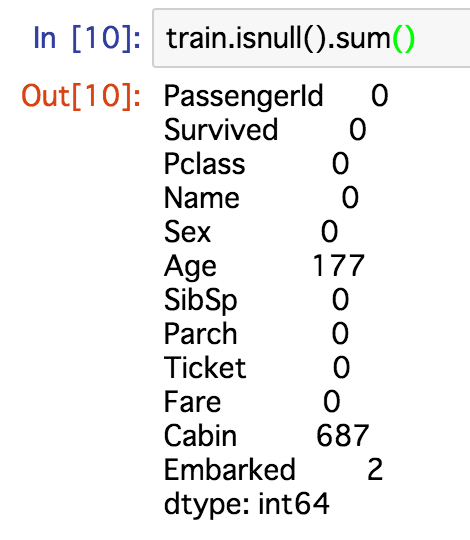
train.isnull().sum() #欠損値の確認
train.describe() #サマリ
こんな結果が返ってくる。



jupyter便利、最高。
Survivedのmeanが0.38とあるのでだいたい6割の人は亡くなってしまっていることがわかります。
とりあえず全員助からないとかにしてもそれなりに精度は出ます。
年齢に関する欠損値はなんとか補完しておきたい。
補完方法はいろいろあって、他のレコードとの類似性から決めたり、他の特徴量から推定してあげるといいんだろうけど、とりあえず中央値で置き換えておきます。
性別とか乗船箇所はダミーに変えようかな、キャビンは欠損値多すぎるから落としておくか、みたいなことも思ったのでやっておきます。
名前に関してはなんか処理してあげたいんですけど面倒なのでとりあえず落とします。
チケットも邪魔なので落としてしまいましょう。
最後に欠損値があるレコードを削除します。
精度が悪ければこのあたりのドロップした情報から役立つ特徴を作り出すとよさそう。
## データの整形
train.Age = train.Age.fillna(train.Age.mean())
train = train.replace("male",0).replace("female",1).replace("C",0).replace("Q",1).replace("S",2)
train = train.drop(["Name", "Ticket", "Cabin", "PassengerID"], axis=1)
train = train.dropna()
train_data = train.values
この状態で相関係数を見てみると以下のようになります。

Survivedに対して性別が一番相関高くて、次に乗船運賃、親、子供の人数、その後に客室クラスという感じ。
乗船運賃は正の相関があるのに客室クラスは負の相関があるのか...
(客室クラスは1 = 1st, 2 = 2nd, 3 = 3rdとなっています。)
特徴数が少なすぎるかなーと思いつつもそこそこ相関関係のある特徴があったので、そのまま整形したデータを使ってモデルを構築してみます。
今回はRandomForestを使ってモデルを構築し、テストデータにいる人の生死を予測をしてみます。
RandomForestについては濱田さんの資料とかみるとわかりやすくていいと思います。
http://www.slideshare.net/hamadakoichi/randomforest-web
原著あたるのもいいんですが結構量があってゴリゴリ実装したい!とか、詳しく知りたい!って人じゃなければ読まなくてよさそう。
めんどくさい人はとにかく決定木をたくさん作って多数決で決めるとかそんな感じに把握してればいいと思います。
## モデル構築
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators = 100)
forest = forest.fit(train_data[0::,1::],train_data[0::,0])
## 予測
test = pd.read_csv("test.csv")
ids = test["PassengerId"].values
test.Age = test.Age.fillna(test.Age.mean())
test.Fare = test.Fare.fillna(test.Fare.mean())
test = test.replace("male",0).replace("female",1).replace("C",0).replace("Q",1).replace("S",2)
test = test.drop(["Name", "Ticket", "Cabin", "PassengerId"], axis=1)
test_data = test.values
output = forest.predict(test_data)
## 書き出し
import csv
output_file = open("output.csv", "w")
file = csv.writer(output_file)
file.writerow(["PassengerId","Survived"])
file.writerows(zip(ids, output.astype(np.int64)))
output_file.close()
書き出されたcsvをkaggleにsubmitするとスコアが出てきます。
こんな感じ。

これで大体75%の精度でした。
全員亡くなったみたいな予測よりは精度いいけどそんなに高くない、まあ結構適当にやってもそれなりになるという感じですね。
ラダー眺めてるとわかるんだけど、上位14人ぐらい全部予測当ててる。
一体どうやったらそんなことになるんだ...
所感と今後
わりとSubmitまでの流れが楽で自分のスコアが見れることはもちろん、他の人のスコアと比較できるのがいいなーという感じです。
フォーラムも山ほど投稿があって、俺の考えた予測方法を見てくれ!!!とかいうの見てると楽しいし勉強になります。
今回はさくっとモデル構築して、予測して、Submitする、をゴールにしてたんですけど、もう少し時間かければよかった。
多分特徴量毎にプロットしたりなんやりするべきですね。
なので、今後も時間見つけてもう少しやってみようというのが感想です。
他の課題に挑戦してみるのもよさそう。
今回のチュートリアルについてはもう少し詳細なデータ分析をした上で、下記の項目について考慮するともっと精度あがるかなと思いました。
時間見つけてやってみようと思います。
- 年齢(欠損値)の補完方法
- 名前を用いた家族情報の紐付け
- RandomForestsのパラメータ調整
- などなど
おしまい