あまり日本語の記事がなかったので、書いてみました。
Livyをざっくり要約すると、Sparkの処理をRESTサーバ経由(API)でリクエストできるソフトウェアになります。
本家サイトより
Submit Jobs from Anywhere
Livy enables programmatic, fault-tolerant, multi-tenant submission of Spark jobs from web/mobile apps (no Spark client needed). So, multiple users can interact with your Spark cluster concurrently and reliably.
Use Interactive Scala or Python
Livy speaks either Scala or Python, so clients can communicate with your Spark cluster via either language remotely. Also, batch job submissions can be done in Scala, Java, or Python.
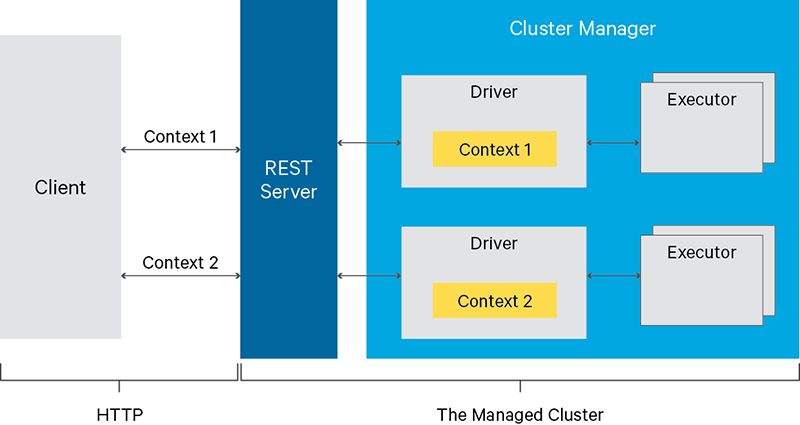
本記事では、インストールとAPIでのSpark実行方法について簡単に記載しています。
全てローカルのMacマシンで実行しています。
なお、本記事ではSparkのインストール方法については割愛していますので、Sparkのインストール方法については、以下記事をご参考にしていただければと思います。
(参考)
Spark/ScalaをJupyter Notebookから実行する - Qiita
Livyのインストールと起動
以下のサイトからzipファイルをダウンロード・解答します。
zipファイル解凍後、ディレクトリを移動してLivyプロセスを起動します。
# 起動
./bin/livy-server start
# 起動状態確認
./bin/livy-server status
デフォルトでlocalhost:8998で起動しています。
Livy APIを試してみる
- (参考) Livy Docs - REST API
インタラクティブに処理を実行する
Sparkコンテキストを生成し、インタラクティブに処理を実行してみます。
Sparkコンテキストはセッションを払い出してセッションで共有されるようなので、まずはセッションを作成します。
セッションの作成
# リクエスト
curl -XPOST -H 'Content-Type: application/json' localhost:8998/sessions -d \
'{
"driverMemory": "2G",
"driverCores": 1,
"executorMemory": "2G",
"executorCores": 1,
"numExecutors": 1
}'
# レスポンス
{"id":0,"appId":null,"owner":null,"proxyUser":null,"state":"starting","kind":"shared","appInfo":{"driverLogUrl":null,"sparkUiUrl":null},"log":["stdout: ","\nstderr: "]}
"id":0の0がセッションIDなので、このセッションIDを使って、次節でコードを実行してみます。
コードの実行
払い出されたセッションID0を使ってコードを何回か実行してみます。
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d \
'{
"code":"val x = 1 + 2",
"kind": "scala"
}'
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d \
'{
"code":"val y = 1 + x",
"kind": "scala"
}'
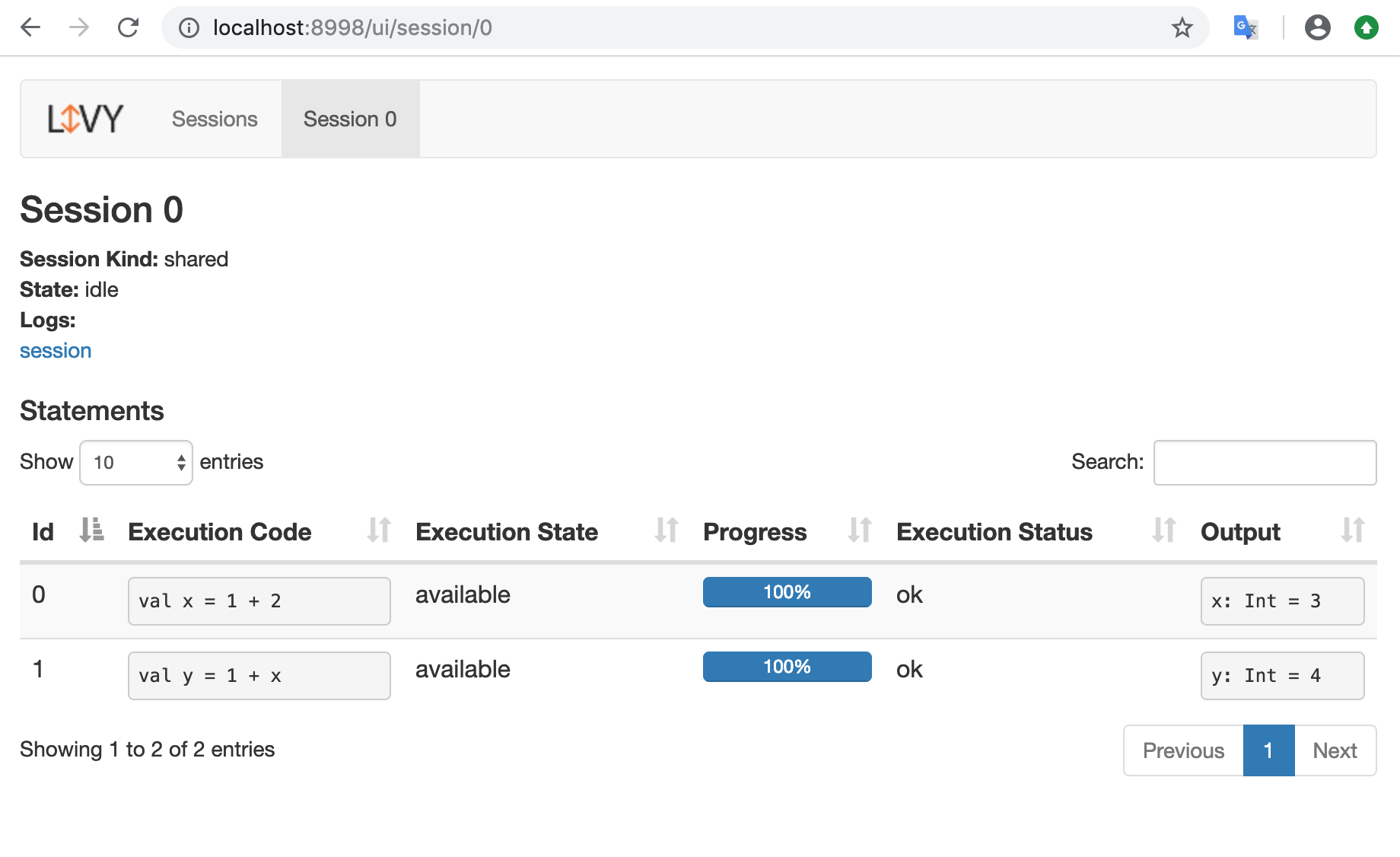
UI(今回の場合はhttp://localhost:8998)にアクセスすると、実行結果が確認できます。
セッションの削除
使い終わったらセッションを削除しておきます。
curl -XDELETE localhost:8998/sessions/0
バッチ処理を実行する
次にjarファイルを使ってバッチ処理を起動してみます。
以下、Livyサーバに/workディレクトリを作成し、そこにjarファイルを置いてバッチアプリを実行してみます。
事前の設定
まずは準備が必要になります。
# 実行したいjarファイルを今回はSparkに同梱されているexampleのものを利用する
# /workディレクトリは、このあとのconfファイルでホワイトリストに追加する必要がある
mkdir -p /work
cp $SPARK_HOME/examples/jars/spark-examples_2.11-2.4.0.jar /work
ローカルで実行するためには、以下の設定が必要です。
cp conf/livy.conf.template conf/livy.conf
vi conf/livy.conf
以下の2行を設定します。
livy.spark.master = local
livy.file.local-dir-whitelist = /work
conf/livy.confファイルを設定後、設定を反映するためにLivyプロセスを再起動します。
# プロセスの再起動
bin/livy-server stop
bin/livy-server start
バッチ処理実行
準備が整ったので実行します。
# バッチ処理のリクエスト
curl localhost:8998/batches -XPOST -H 'Content-Type: application/json' -d \
'{
"file": "/work/spark-examples_2.11-2.4.0.jar",
"className": "org.apache.spark.examples.SparkPi",
"conf": {
"spark.master": "local[1]"
},
"name": "example-app"
}'
# レスポンス
{"id":1,"state":"running","appId":null,"appInfo":{"driverLogUrl":null,"sparkUiUrl":null},"log":["stdout: ","\nstderr: "]}%
実行すると、バッチ処理のIDが払い出されます。
バッチIDを指定して実行ログを取得することができます。
# リクエスト
# ログを見やすくするためにPythonのjson.toolで整形しています
curl localhost:8998/batches/1/log | python -m json.tool
# レスポンス
{
"id": 1,
"from": 3,
"total": 103,
"log": [
"2019-03-21 23:45:48 INFO SparkContext:54 - Submitted application: Spark Pi",
"2019-03-21 23:45:48 INFO SecurityManager:54 - Changing view acls to: chocomint",
"2019-03-21 23:45:48 INFO SecurityManager:54 - Changing modify acls to: chocomint",
"2019-03-21 23:45:48 INFO SecurityManager:54 - Changing view acls groups to: ",
...
ログはLivyのUIからも確認できます。

まとめ
バッチ処理をAPIで起動できるようになるので、便利かなと思いました。実業務で使えれば使っていきたいです。