MP-DQN論文まとめ
- 2019年5月にsubmitされた論文です
- arXivはこちら
- Parameterised Actionという行動の構造を持ったMDPへのDQN手法の適用論文
- 2018年にsubmitされているParametrized Deep Q-Networks Learning: Reinforcement Learning with Discrete-Continuous Hybrid Action Space論文の手法を改善したものになります。
Abstract
- Parameterised actionsは連続実数でparameteriseされている離散行動のことである。
→ soccer gameを例にすると、パス・走る・シュートの離散行動が、それぞれの行動について、速さ・方向などが連続値で表現されているようなもの。 - Parameterised actionsは複数の行動で微調整ができるので、複雑なタスクを解くことができる。
- 最近のParameterised DQNの手法は行動空間全体に対して学習するようにしているが、全てのaction parameterを一つの同時入力としてQ-Networkに入力してしまっており、理論的に好ましい方法ではない。
- 本論文では、上記アプローチの問題点を分析した上で、新しい手法Multi-Pass DQN(MP-DQN)を提案し、この手法が従来手法をはるかに上回ったことを示す。
Introduction
- Parameterised actionsへの学習手法は大きく分けて二種類の流れに分けられる。
- 一つは、離散行動を選択する方策と、その方策で選ばれた行動のパラメータを決定する方策を交互に学習させる方法。もう一つはparameterised action spaceを連続空間にcollapse intoさせる(上手い訳が分からないので、英語のままにしました)方法である。両者とも短所がある。
- 前者の手法は、行動と行動のパラメータ方策の間で情報を共有できていない(別々に学習してしまっている)こと、後者の手法はどの行動パラメータがどの行動に結びついているがを考慮していない。
- 最近提案されたP-DQN手法は、parameterised action spaceで挙動を直接学習させる方法であり、行動空間の性質をうまくレバレッジすることができ、現在、特定のドメインのタスクでSoTA。
- しかし、P-DQNは離散行動の価値が全ての行動パラメータに依存してしまっているので、対応しない行動の影響も受けてしまっている。
- そこで本論文では、P-DQNのその問題がどのように悪影響を及ぼしているかを示し、それを克服したMP-DQNがより良い成績を出したことを示す。
Background
- Parameterised actionsを考察した、2015年のReinforcement Learning with Parameterised Actions論文を参照されるのが一番わかりやすいと思います。
- 各時刻ごとに複数の離散行動の中から一つを選び、その行動のパラメータを決定するのがParameterised Action Markov Decision Process(PAMDP)とする。この時、行動空間を以下のように表現する。
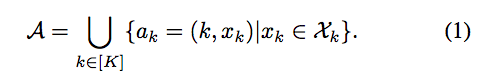
- kは離散行動を、$x_k$は行動kのパラメータを表しています。
Parameterised Deep Q-Networks
- ここでは2018年に提案されたP-DQNについて概観する。
- P-DQNはDQNとDDPGを組み合わせた手法で、Q-Valueをニューラルネットワークで関数近似(Q-Network)した手法である。
- PAMDPを直接的に定式化するためには、ベルマン方程式に行動の連続値のパラメータを組み込む必要がある。
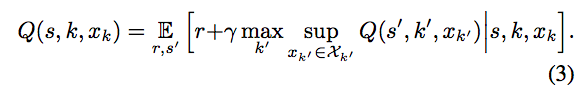
- 連続値パラメータ上の空間でsupを計算するのは難しい。これを回避するために、Q-functionが固定されているときに、$argsup_{x_k\in\chi_k}Q(s,k,x_k)$を$x_k^Q:S\rightarrow\chi_k$という関数と見ることができる。
- これを利用することで、上記のベルマン方程式は以下のように書き換えることができる。
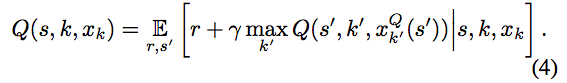
- P-DQNはDNNをパラメータ$\theta_Q$で表現される$Q(s,k,x_k;\theta_Q)$として利用した。また、行動の連続値パラメータを決定する方策を、DNNのパラメータを$\theta_x$として$x_k(s;\theta_x):S\rightarrow\chi_x$で表現する。
- 上記のように文字を設定することで、標準的なDQNによる、mean-squared Bellman errorの最小化を適用することができる。
- 離散行動の選択の損失、連続パラメータの出力の損失はそれぞれ以下のように表現できる。
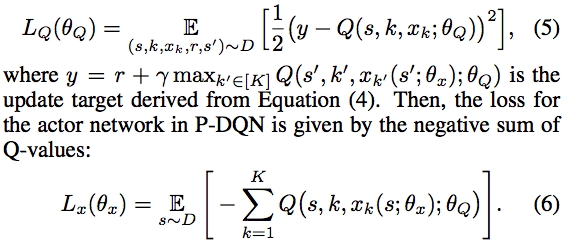
Problems with Joint Action-Parameters
- ここでは上記のP-DQNの手法の問題点を紹介する。
- P-DQNの概略図は以下のようになる。
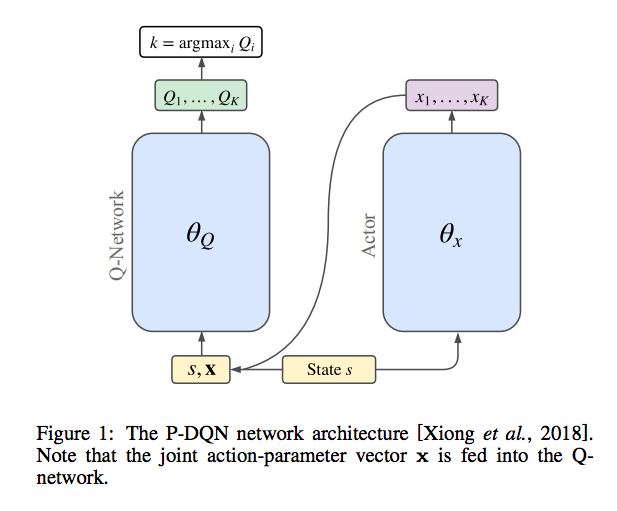
- 上記図から分かるように、Q-Network(その行動の連続パラメータを決定するニューラルネットワーク)への入力がjoint action-parameter vector over all actionsになっている。
- 実装上の些末な問題に見えるが、これは先ほど導出したベルマン方程式を変更してしまう問題であり、P-DQNは以下のベルマン方程式を考えていることと等しい。(上の式4と比較すると分かりやすいです。)
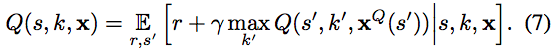
- これは、Q-Valueの更新・action parametersに影響を与えてしまう。
- action parametersへの影響は、以下の四つの式から考えることができる。
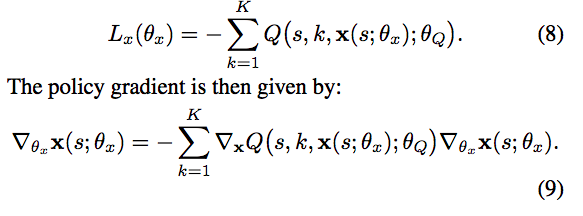

- 式8,9,10がP-DQNが計算しているものであり、式11が(P-DQNが)もともと目指していたものである。式10と式11で各行動の勾配が、その他の行動の影響を受けてしまっていることがわかる。
- 上記のQ-Valueが全ての行動に依存している問題は、連続値パラメータを決定する方策だけでなく、離散行動を選択する方策にも悪影響を与える。
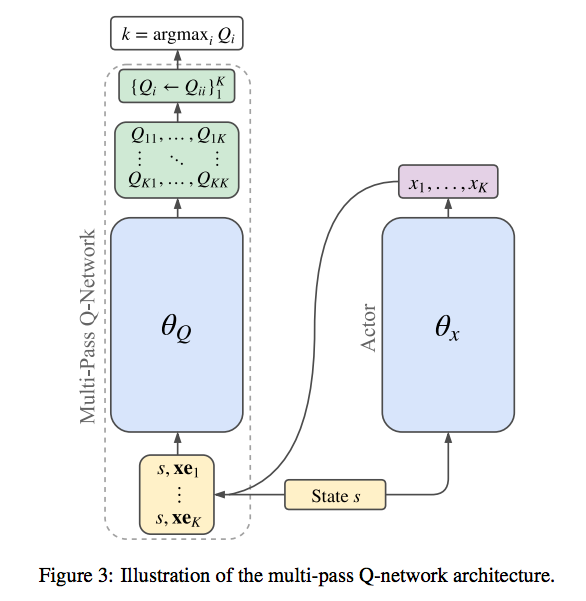
Multi-Pass Q-Networks
- ここではP-DQNの問題点を解消する方法を紹介する。
- 最も単純な手法は、それぞれの離散行動に対して別々のQ-Networkを用意することであるが、これは計算コスト・空間の複雑さが増加することから、学習するのが難しくなる。
- したがって、本論文ではもともとのP-DQNのarchitectureを変えないような手法も含めて検討した。
- Q-Networkを複数個用意するのではなく、離散行動ごとに順伝播計算をする方法を提案する。(Multi-pass)
- P-DQNのarchitectureを同じままに計算するので、以下のようone-hot vectorを利用して計算する。
$xe_k = (0,...,x_k,...,0)$
$ Q(s,k,xe_k)\cong Q(s,k,x_k) $
-
全部でKの順伝播計算は、一つのQ-Valueを予測する代わりに、全てのQ-Valuesを予測することを求められる。
-
PyTorch・Tensorflowのような並列ミニバッチ処理が可能なニューラルネットワークを実装するライブラリを利用することで、上記の処理も大きなコストをかけることなく可能。
-
Kの行動のmulti-passは、サイズがKのミニバッチ処理をすることと同様であり、以下のような式で効率よく表現することができる。
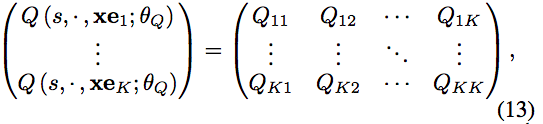
-
上式の行列は対角成分以外は0であり、$Q_i \leftarrow Q_{ii}$によって最終的な出力になる。
-
separate Q-Networksに比べて、Multi-Passは比較的少ないoverheadで計算することができ、逆伝播に関しては一度で済む。
-
したがって、計算の複雑さは行動の数と更新の際のミニバッチのサイズに対して線形にスケールする。
Experiments,Results
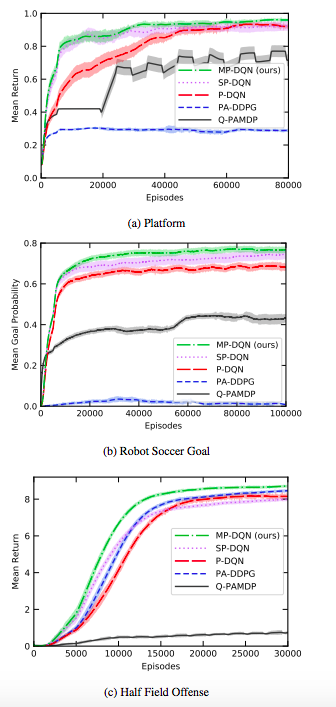
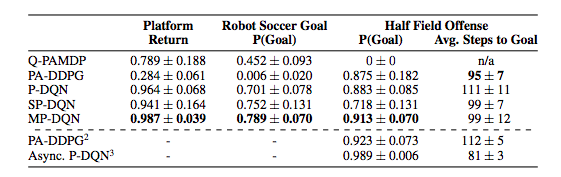
MP-DQNとQ-PAMDP,PA-DDPG,P-DQN,SP-DQNを、Platform,Robot Soccer Goal,Half Field Offenseで比較したところ、どのタスクでもMP-DQNが良い成績を残した。
Related Work
- ここでは二種類のParameterised actionに対する手法を紹介する。
- 一つはParameterised actionsを連続空間にcollapse intoする方法。LSTMを利用した模倣学習によって連続パラメータ方策を学習する方法(参考論文),multi-goal parameterised action space environmentsに対して、複数の目的を達成するための技術を紹介しているリサーチ論文などがある。
- もう一つはparameterised actionを2-level hierarchyと見る方法である。方策を決定する上位方策と、実際の行動を決定する下位方策を一つのネットワークで学習する手法(参考論文)や、本論文の手法に似たものだとこちらの手法がある。
感想
- 昨日Qiita記事にしたAction Branchingの手法でも代替できるような気もしました。ただ、Action Branchingでは離散行動の数だけ部分的にネットワークを追加するので、本論文でも述べられていたように学習が難しくなるのかもしれません。
- Parameterised actionは単純な離散行動による定式化よりも、広い範囲の現実問題に対応できそうです。
- 階層的強化学習(Hierarchical Reinforcement Learning)も勉強したいなと思いました。強化学習、奥が深い。