Action Branching Architecture for Deep Reinforcement Learning論文まとめ
- 2017年11月にsubmitされた論文です。
- arXivはこちら
Abstract
- DQNのような離散行動アルゴリズムは高次元の行動タスクに適用しようとすると、選択可能な行動が組み合わせ的に増加してしまう。
- 本論文は、意思決定共有モジュール(shared decision module)の後にいくつかのnetwork branchが続くArchitectureを提案する。一つのbranchが一つの行動の次元に対応している。
- 上記の構造により、それぞれの行動次元に対して独立のレベルを認めることで、自由度の増加に対してnetworkのoutputの増加を線形の増加に抑えることができる。(よくわからなかったので直訳...)
- この手法をBranching Dueling Q-Network(BDQ)として提案。
- 得られた実験結果より、BDQは行動次元の増加に対してうまくスケールしていた。タスクによってはSoTA(当時)のDDPGよりも良い結果を出した。
Intrduction
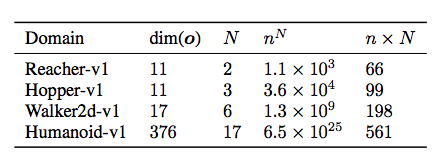
- N次元の行動空間において、各次元に$n_d$の離散的なsub-actionがある場合、既存の離散行動アルゴリズムを適用すると、$\prod^N_{d=1}n_d$の行動が可能である。そしてこれは次元数が大きくなると探索困難に陥ってしまう。
- この制限は多くの離散行動アルゴリズムにとって問題になる。しかし、離散行動アルゴリズムは方策勾配法よりもサンプル効率が良いため、できるなら離散行動アルゴリズムを利用したい。
- 本手法の目指すところは、高次元の場合に離散行動アルゴリズムを適用することであり、そのためにaction controllersをそれぞれのbranchに分散させ、状態理解の把握にshared decision moduleを利用する。(これにより、探索空間を線形の増加に抑えることができた)
- 本手法により、高次元の離散行動・連続空間に離散行動アルゴリズムを効率的に適用することができるようになった。
- 結果として、$n^N = 6.5×10^{25}$のタスクにも適用することができ、DDPGの結果を上回った。
- Shared decision moduleの有用性を示すために、BDQとIndependence Dueling Q-Network(IDQ)との結果を比較した。IDQは次元数の増加に対して急激に結果が悪化し、その有用性が示唆された。
- IDQは各行動次元に対して一つのQ-Networkを割り当てる方法であり、BDQに対して、独立した複数のNetworkを上手く学習させることが難しいことが上記の結果の理由ではないかと考えられる。
Related works
- Durac-Arnold 2015 Deep reinforcement learinig in large discrete action space
→DDPGとapproximate nearest neighbor(近似最近傍探索)を組み合わせた手法。
→連続行動アルゴリズムを必要とするので、離散空間ドメインでは適していない。
→Q学習を高次元タスクに適用した。自己回帰ネットワークでsequntialに各行動次元の行動価値を予測した。
→これは、予測の順番を実験者が決める必要があること、また、次元数が増えるとQ-value推定のノイズが増えてしまう。
BDQは並列処理なので、予測の順番を決める必要がなく、推定ノイズの蓄積も気にしなくてよく、実装もシンプルになる。
Action Branching Architecture
- 単純に価値関数を独立して分散して学習させるとうまくいかないことが知られている。
※ここでいう分散はdistributed learning、複数エージェントに経験をさせる学習手法を指しているわけではありません。Q-valueを行動次元に対してそれぞれ独立した関数近似器(Deep RLではニューラルネット)を置くことを指しています。
- 本論文では、shared decision moduleを使うことでcommmon state inputをうまく潜在空間にencodeするようにした。
論文内の図を以下に引用します。かわいいです。(かわいいですが、次章の図の方がわかりやすいです。)
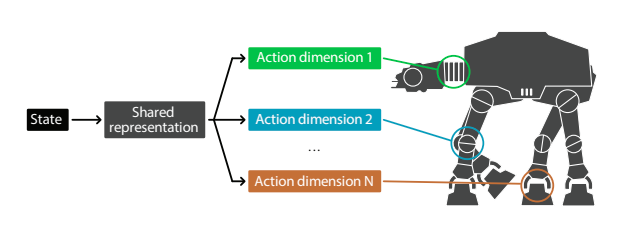
Branching Dueling Q-Network
ここではBDQのArchitectureについて見ていきます。以下の図がモデルの全体図です。
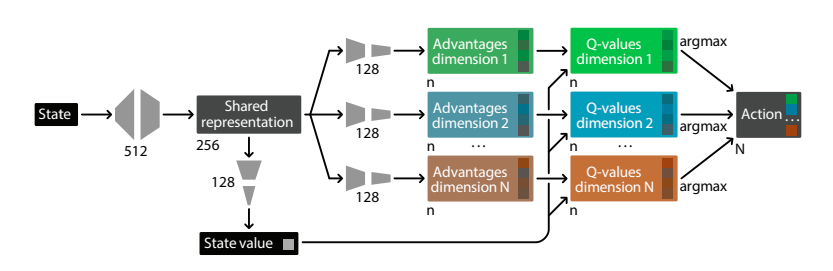
Background
- 以下ではサンプル効率・方策改善を改善させる三つのkey innovationsを紹介する。(今日、よく見られる手法なので簡単に紹介して通り過ぎることにします。)
Double Q-Learning
- DQNは行動価値のover estimationをしてしまうことが知られている。詳しくは以下のQiita記事の参照をお願いします。Deep Reinforcement Learning with Double Q-learningを読んだ
Prioritized Experience Replay
- Off-Policyでの学習の旨味である経験の蓄積を、より効率的に行う手法。数式的な表現については後述。(R2D2はRNNでの経験再生を上手にやったことで学習成果を大きく向上させています。個人的には画像処理系のData augmentationみたいなイメージを持ってます。大事な処理・工夫。)
Dueling Network Architecture
- common feature-learning moduleを共有しながら、状態価値・(状態に依存した)行動のアドバンテージを別のbranchで明示的に分けて学習させる手法。こちらのQiita記事がわかりやすかったです。【強化学習中級者向け】実装例から学ぶDueling Network DQN 【CartPoleで棒立て:1ファイルで完結】
Methods
ここではDQNをaction branching architectureに適用するためのいくつかの拡張を紹介する。基本的には一番良い結果を残した手法・試行を中心に述べる。
Common State-Value Estimator
- 上記の図で見たように、BDQではcommon state-value estimatorを全てのaction branchに利用している。
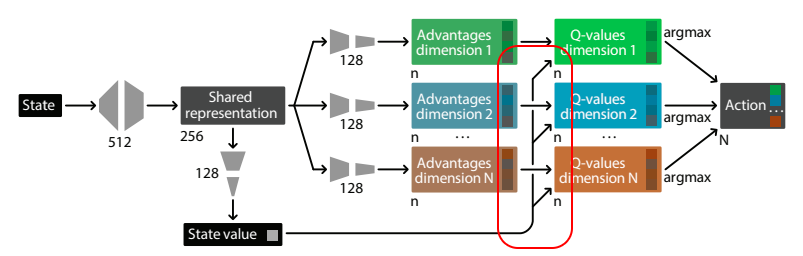
- ある意味でこれはdueling networkを適用しているように考えることができ、良いパフォーマンスを出す。
- dueling networkを利用することは、大きな行動空間ではより良い影響をもたらす。これはdueling networkは行動の冗長性な部分を素早く同定し(行動価値を明示的に計算するため)、似た行動に共通するgeneral valueを効率良く学習することができる。
- 今回の実験の中では行動価値関数を$Q_d(s,a_d) = V(s) + (A_d(s,a_d) - \frac{1}{n}\sum_{a'_d\in{A_d}}A_d(s,a'))$として計算するのが、単純にアドバンテージ関数と状態価値の和とするよりも良い結果を生んだ。
Temporal-Difference Target
- ここでも色々なTD targetの計算を試した。(TD targetは状態sの価値を、状態sで選んだ行動による即時報酬と、次状態s'での状態価値の和として表現したものになります。ここでは状態価値ではなく状態行動価値(Q-value)になります。)
- 今回の実験ではTD targetを$y = r + \gamma \frac{1}{N} \sum_dQ_d^-(s',argmax_{a_d'\in{A_d}}Q_d(s',a'_d))$として計算するのが良い結果を生んだ。この計算の前にmaximum DDQN-based targetを計算しており、その式の中のmax演算子をmeanの計算に変更した。
Loss Function
- 分散したTD errorの損失計算も色々な手法がある。
- シンプルにbranch全体のTD errorの平均値を取ってしまうと、符号の違いによるキャンセリングが起きてしまい、損失のインパクトがなくなってしまう。
- 実験したところ、mean squared TD errorsが良いパフォーマンスを出した。
Gradient rescaling
- N-branch全てからshared decision moduleに誤差逆伝播が行われるので、$\frac{1}{N+1}$でRescaleしたものを流すようにした。(なぜN+1なのかはよくわかりませんでした。インデックスが0スタート的な...?)
Error for Experience Prioritization
- 経験再生では、学習効果が高いものを優先的に選ぶ方が効率が良い。そのために分散しているTD errorを適切に集積する方法が必要になる。
- 今回の手法の中ではabsolute TD errorの合計を利用した。$ e_D(s,a,r,s') = \sum_d|y_d - Q_d(s,a_d)| $
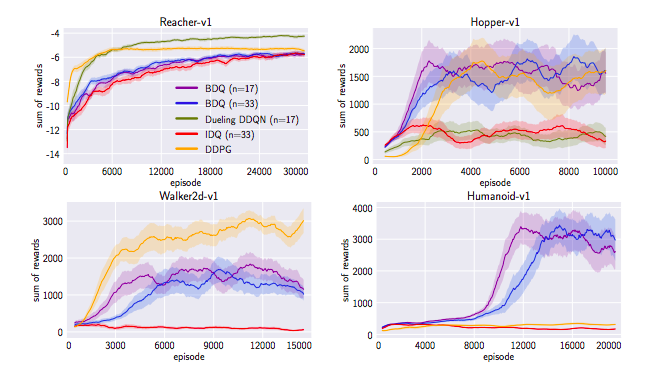
Experiments
- Mujucoで評価した。
- BDQ,DDQN,DDPG,IDQで比較した。
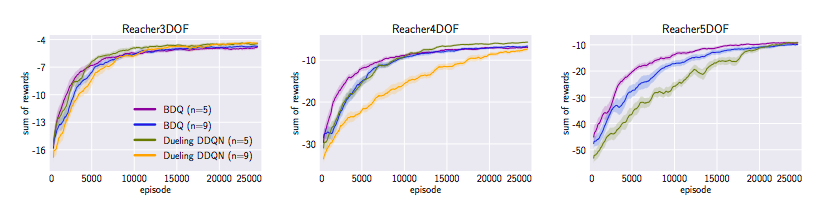
- タスクによっては他手法の方が優れた結果を残すこともあったが、BDQはどのタスクでも安定的な結果を残した。
- 特に高次元なタスクでは他の手法よりも圧倒的に良い成績を出した。
Conclusion
- shared decision moduleでcommon state valueを共有しながらも、方策もしくは価値関数の表現をbranchに分散させた新しいArchitectureを提案した。
- 上記のArchitectureにDQNアルゴリズムを、最新の手法に沿って適用した。(今だったらdistributed learningや報酬分布の計算とかも入りそうです。)
- 従来なら計算できないと考えられたものにも離散行動アルゴリズムの適用に成功した。
感想
- 最近ではBDQにPPOを適用した手法も提案されているようです。PDFはこちら
- 論文自体は2017年のものであり、少し古い(?)ものですが、強化学習の実用を考える際には考慮に入れるべき有用な手法だと思います。
- 図がかわいかったです。
- 最近の手法(Tips)を取り入れればもっと精度が上がるような気がします。
久々に読んだ論文をQiita記事にしました。ほぼ和訳みたいになりましたが、ただ読みっぱなしにするよりも(個人的には)理解が進んだように思います。
時間があるときは積極的にやっていきたいなぁ...