Born-Again Neural Network論文まとめ
- 2018年5月にsubmitされた論文で、従来のKnowledgeDistillation(以下KD)と異なる応用方法についての考察です。
- arXivはこちら
- Born-Againは「生まれ変わり」の意味です。
この記事で説明すること
- KDの概要
- 従来のKDの扱い
- 本論文の特徴
この記事で説明しないこと
- 用いられたモデルの構造(DenseNet,Wide-ResNet)
- 実験の詳細
ザックリとまとめていきます。サクッと見ていきましょう。
KnowledgeDistillation(KD)とは
日本語に直すと「知識蒸留」ということになります。蒸留というのは、「混合物を一度蒸発させ、後で再び凝縮させることで、沸点の異なる成分を分離・濃縮する操作をいう。」らしいです。(Wikipedia「蒸留」より)
それを「知識」に対して行うのがKDです。元となる混合物の役割をするのが「教師モデル」、そこから蒸留した「知識」を移す先が「生徒モデル」と呼ばれるものです。
※教師・生徒モデルは特定の構造を持ったモデルを指すわけではないことに注意。
これを具体的にどうやるかと言いますと、十分な量の訓練データで訓練した教師モデルの出力を、生徒モデルの出力の正解ラベルにするという方法が一般的です。(ここではクラス分類を例に考えていきます。)
教師モデルの出力した予測分布には、教師モデルが学習で得た知見が反映されているはずであり、ただのone-hotラベルよりも多くの情報を含むことが期待されます。(例 クラス分類を考えるとき、犬と猫の出力は犬と車の出力よりも近いものと想定される。そのような クラス間の関係が教師モデルの出力には含まれていると想定される。)
上記の正解以外の情報のことを「Dark Knowledge」と言ったりします。
従来のKDの扱い
上記で見たKDですが、従来では「大きくて複雑な構造のモデル」から「計算資源が少なくても機能するコンパクトなモデル」に対して行うことが想定されています。
(その前提があったために、「教師」「生徒」という、ある意味で「教師>生徒」を仮定したような名前になったのかなぁなどと思ったりします)
KDを提案した論文では、大きなモデルから小さなモデルへ知識を移すことに成功し、モデル構造を大幅に小さくしながらも精度の減少を抑えることを実現しています。
本論文の特徴
従来では「大きな教師モデル」から「小さな生徒モデル」へのKDを行っており、その題目は「精度の減少を小さく抑えてコンパクトなモデルを作る」ことでした。
それに対してBorn-Again Netでは「教師モデル」と同じ構造を持った「生徒モデル」を利用し、生徒モデルが教師モデルよりも優れたモデルになることを示しています。(生徒>教師という関係になります。師匠モデルと弟子モデルとかの方が個人的にはしっくりきます)
つまりこの論文では「モデルを小さく・精度も維持」という目的ではなく「モデルはそのまま・精度を高く」することを目的としています。
実際の手法については論文内の以下の図がわかりやすかったので引用します。
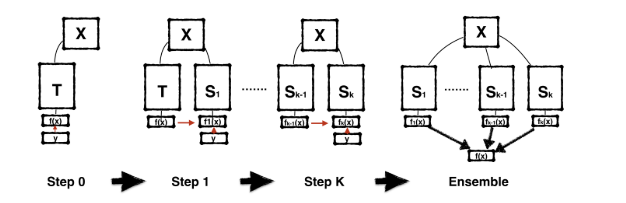
Tが教師(Teacher)を、Sが生徒(Student)を示しており、生徒から生徒へのKDも連続的に行われます。
数回のKDの後に、それぞれの生徒モデルのアンサンブル(上図の右端)が最終的なモデルになります。
教師モデル・生徒モデルともに同じ構造を持っているので「Born-Again」(生まれ変わり)と表現しているものと思います。
関連論文
実験で用いられたモデル構造に関して
「DenseNet」 2016年発表
Densely Connected Convolutional Networks
「ResNet」 2015年発表
Deep Residual Learning for Image Recognition
「Knowledge Distillation」に関して 2015年発表
Distilling the Knowledge in a Neural Network
補足・所感
- この記事では詳細結果について省略しましたが、多くの場合は生徒モデルが教師モデルを上回るものの、必ずしも教師モデルより良い結果が出るとは限らないようです。(詳細に考察されているので結果だけ読んでも面白いと思います。)
- 蒸留の由来は「Softmax温度を上げること」にあります。関連論文の「Distilling the knowledge」論文にSoftmax温度について詳しく記載されています。
- この論文では同じ形のモデル同士以外にも、似たキャパシティを持った別のモデルへのKDも行っています。
- 上記でもちらっと書きましたが「師匠モデル」と「弟子モデル」の方が、蒸留先が蒸留元を超えていく感があって良いと思います!(ジャンプの読みすぎ)。
- 昨日投稿したザックリまとめ Full-body High-resolution Anime Generation論文もそうなんですが、モデル構造そのものではなく、入力データだったり、出力のターゲットに関する論文も読んでて面白いなぁと思います。
- モデルの構造によって学習で得る知見が変わると思うので、複数の異なる構造を持つ教師モデルからKDしても面白そうだなと思いました。
最後までお読みいただきありがとうございました!
間違い等あればご指摘のほどよろしくお願い致します!