0. NLPとは
NLPはNatural Language Processingの略称であり、日本語では自然言語処理といいます。我々が普段使うような言語(日本語、英語など)を自然言語といい、それをコンピューターが読めるようにする処理のことをNLPといいます。
実は最近用いられる自然言語処理手法の歴史は浅く、
2013年~ DeepLearningが急速に発展
2018年 Transformer、BERTといった現在のNLPを構成する技術が誕生
2020年代~ GPTモデル・ChatGPT大流行
といった具合に、比較的最近開発された手法も多いことがわかります。
今回はその基礎の基礎であるトークン化 (Tokenization) についてお話しできればと思います。
1. トークン化・形態素解析
まずいくつかの単語について。
トークン化
=> 文章を単語ごとに分解すること です。
形態素解析
形態素とは → 文字よりは大きく、かつ意味を持つ表現要素の最小単位
=> 最小の単位に分解すること です。
例えば経済学というがワードについて形態素解析を行うと、“経済学”とはならずあくまで最小単位の”経済”と”学”に分解されます
※固有名詞も辞書に載っていれば認識可能である
仕組み
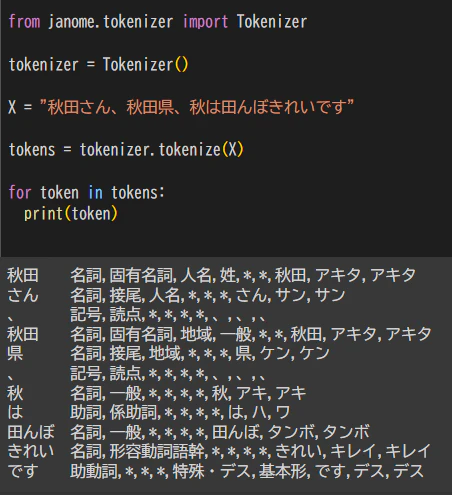
例)単語”秋田” 地
域名”秋田”
人名 ”秋田”
秋(季節)&田(たんぼ) など可能性はいくつもある?
※英語などの屈折型言語だと単語で区切られているので起こりえない問題
HMM(Hidden MarKov Model)を用いた動的計画法で単語・品詞の同時確率が最も高くなるものを出力している
直感的に分割について説明
①品詞ごとのマルコフ過程
P( 助詞|名詞) = 0.5 名詞の後に助詞が来る確率
②品詞の中での単語出現確率
P(の|助詞) = 0.3
P(走る|動詞) = 0.04 みたいなこと
文字列S =(c1 , c2 ….. )が与えられた時の、
単語列 W=(w1, w2 ….)
品詞列 T=(t1, t2 ……) が想定できる
$$
(W', T') = \arg \max_{W, T} P(W, T | S)
$$
$$
\
P(W, T) = \prod_{i=1}^{n} p(t_i | t_{i-1}) p(w_i | t_i)
{i=1}^{n} p(t_i | t_{i-1}) p(w_i | t_i)
$$
この同時確率を最大にするように単語の分割・品詞の組を決めている
2. Word2Vec
一意に単語をベクトル化したもの
あくまで各成分が意味を持っているわけではないが、近いワード[シチュー、カレー]が近い座標に分布するようにベクトル化している
- 分布仮説
ある単語の意味は周囲の単語によって決められている、という仮説。この仮説をもとにベクトル化が行われる。
- CBOW &Skip-Gram
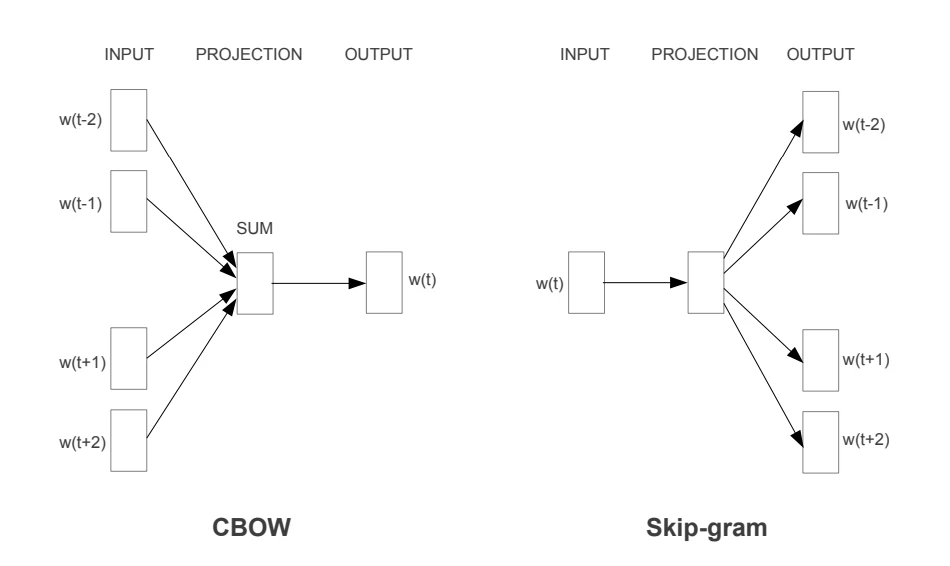
—Efficient Estimation of Word Representations in Vector Space, Tomas Mikolov(2013)
2.1 CBOW(Continuous bag of words)
ある文章中の単語iをi -C ~ i +Cの範囲の単語を使いニューラルネットワークモデルで予測する
EX) , ~ I sometimes go to [MASK] with my friends to get ~~~
学習に使用した文章中に単語が10000種類のとき、[MASK]を予測したいと考える。この時C=1 (前後1つずつ)の単語を用いて予測したい。単語の成分が
to 2番目
with 8番目だとすると
Input Layer
one hot encoding が用いられている。例えばこの場合、toが2番目、withが8番目の成分なので
h1 = [0,0,1,0 ,…..0] ⇒ one hot vector(”to”)
h2 = [0,0,0,…. 1 …0] ⇒ one hot vector(”with”)[
それぞれ2番目と8番目のみ1のようなベクトルとなる。
*このベクトルは10000次元
Hidden Layer
①埋め込み行列(重み行列)を使って先ほどのone hot encoding で表されたものを埋め込みベクトルに変換
例えば埋め込み行列Wiが10000(V)×100(N)行列だとすると
$$
E(w_i) = W_{\text{in}} \cdot \text{one hot vector}(w_i)
$$
を計算することで以下のように100次元ベクトルで表現できる
$$
E(\text{"to"}) = [0.34, -0.67, 1.23, \dots, 0.98]
$$
② ①で得た埋め込みベクトルを平均化する (中間層の出力)
$$
h = \frac{1}{C} \sum_{i=1}^{C} E(w_i)
$$
なおC は予測のために使いたい前後の単語数、E(Wi )は①で算出した埋め込みベクトルのことである
※埋め込み行列はランダムに設定される。後に勾配降下法と誤差伝播法を用いて埋め込み行列を最適化していく。なお、この時最適化されたinput ⇒ hidden layerでの埋め込み行列が、事前学習済みモデルで用いられている単語ごとのベクトルになる。
Output Layer
先ほhidden layerで100次元まで圧縮したので元の次元に戻さないといけない
つまり今回の例では100(N) ×10000(V)の重み行列をかけることになる
$$
W_{\text{out}} : N \times V
$$
$$
z = W_{\text{out}}\cdot h
$$
出現確率の導出
ソフトマックス関数を適用する(0~1 で表現できるようになる)
$$
P(w_i) = \frac{e^{z_i}}{\sum_j e^{z_j}}
$$
これが最も高い値が予測結果となるが、、
この過程を勾配降下法と誤差伝播法を用いて重みWを最適化していく!
2.2 Skip-Gram
簡潔に言うと、CBOWの逆をやっている
ある単語i から周りの単語C (i-1), C(i +1)を予測するモデル
やってることと理論自体はCBOWとあんま変わらないので説明は省く
3. Word2Vecで可能なこと
単語同士の類似性をとらえることに優れている!
良い点
it was shown for example that vector(”King”) - vector(”Man”) + vector(”Woman”) results in a vector that is closest to the vector representation of the word Queen
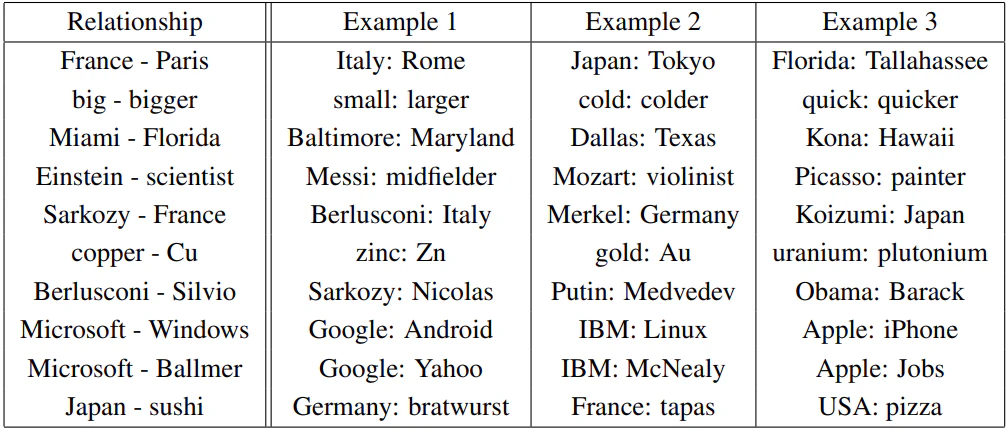
—Efficient Estimation of Word Representations in Vector Space, Tomas Mikolov(2013)
学習したすべての単語が同じ次元のベクトルで表されているので、
France - Paris = Japan - ? を出したければ
? = Japan-France +Paris を算出すればいい
実際にgenismの事前学習済みモデルで検証すると
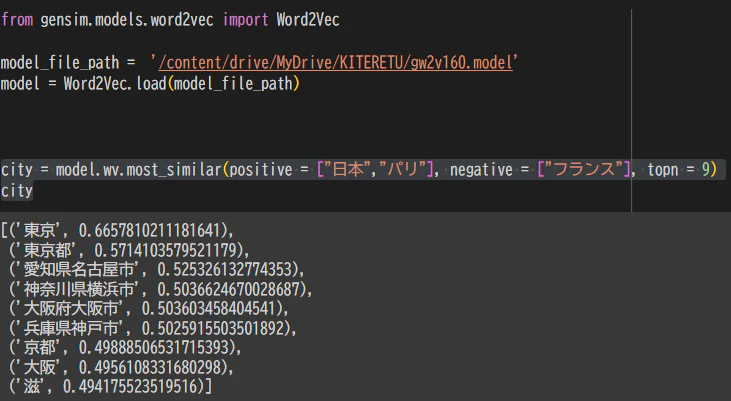
東京の類似性が最も高いと出力された
ほかにも
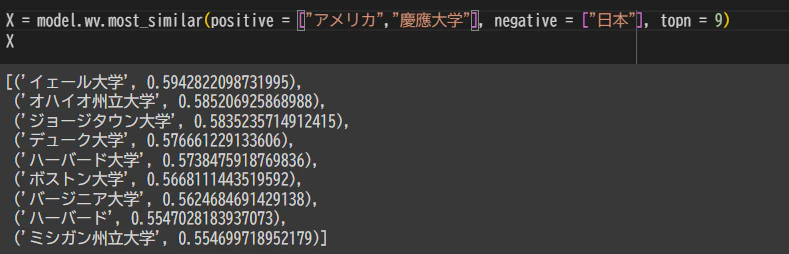
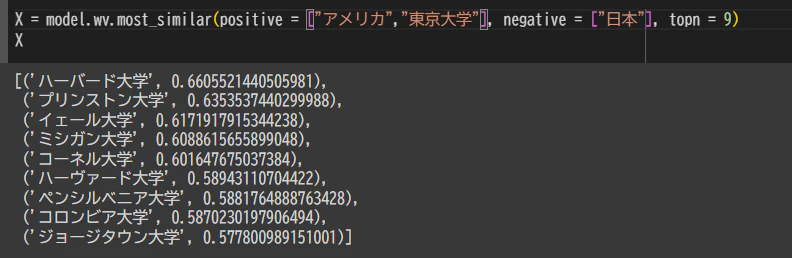
4. 問題点
①文脈依存的でないこと
各単語に対し一意なベクトルを与えるから、文脈に関わらず意味が同じになってしまうこと。
ex) 舞台の上手、料理が上手 は同じじゃないよねって話
②語順を無視していること
CBOWの過程でInput*重みベクトルを平均化した
The dog chased the cat" と "The cat chased the dog" は全く意味が異なるが、その違いをとらえることはできない。
③一度学習すると変えることができない静的なモデルである
単語ベクトルが一度学習されると、それが固定されてしまう
=>異なるタスクや領域に対応することが難しい
5. 参考文献
Efficient Estimation of Word Representations in Vector Space, Tomas Mikolov(2013)
arxiv.org
Introduction to Deep Learning (MIT)
introtodeeplearning.com
東大情報基盤センター 自然言語処理入門
ocw.u-tokyo.ac.jp
Qiita
ゼロから作るDeep Learning 自然言語処理編を理解する Chap3 - Qiita
Medium CBOWについての記事
CBOW — Word2Vec