概要
本記事では,ゼロから作るDeep Learning 自然言語処理編を理解することを目指し,その箇所の引用・自分なりに大事だなと思ったこと・感想などをまとめていきます.(知識不足な所も多々ありますが,温かい目で見守って頂ければと思います)
これまでの記事はこちらから
1章:ニューラルネットワークの復習
2章:自然言語と単語の分散表現
本記事では,書籍の3章(word2vec)を扱います.
Chap3 - word2vec(pp. 93~129)
前章では,周囲の語の共起を元にした,カウントベース手法による単語分散表現を扱いました.
単語分散表現を得る手法として,カウントベース手法の他に,推論ベース手法があります.
本章では推論ベース手法の中でもword2vecを扱い,その仕組み,実装を理解するだけでなく,カウントベース手法との違いについて理解することがGoalになります.
3.1 推論ベースの手法とニューラルネットワーク
この節では,カウントベース手法の問題点と,推論ベース手法の強みについて理解することがGoalになります.
・ 推論ベース手法とは
推論ベースの手法では,「推論」することが主な作業になります.これは,周囲の単語(コンテキスト)が与えられた時に,「?」(周囲のコンテキストに対して中心の語)にどのような単語が出現するのかを推測する作業です.
推論ベースの手法では,あえて正解データに対して**「マスク」**をし,マスクをした部分に対する(推論問題)穴埋め問題を繰り返し解きます.その穴埋め問題に対するアプローチが「モデル」であり,穴埋めが正しいものとなるように学習させていきます.
そうした穴埋め問題による学習の結果得られるのが,単語の分散表現であり,あくまで学習の副産物に過ぎない点は要注意です.
3.2 シンプルなword2vec
この節では,word2vecを実現するNNの仕組み,具体的に入力層と中間層,出力層について理解することがGoalになります.
・ そもそもword2vecとは??
word2vecという言葉は,(中略)ニューラルネットワークのモデルを指す場合も多く見受けられます.正しくは,CBOWモデルとskip-gramモデルという2つのモデルがword2vecで使用されるニューラルネットワークです.
word2vecはEfficient Estimation of Word Representations in Vector Spaceという論文で提案されたNNモデルになります.
・ CBOWモデルについて
CBOWモデルは,コンテキストからターゲットを推測することを目的としてニューラルネットワークです.(「ターゲット」は中央の単語,その周囲の単語が「コンテキスト」).このCBOWモデルをできるだけ正確な推測ができるように訓練することで,私たちは単語の分散表現を獲得することができます.
CBOW(Continuous Bag-of-Words)とは,周辺の単語から中心の語を予測する教師あり学習モデルです.以下は,CBOWモデルの概略図で,参考【1】から引用しました.
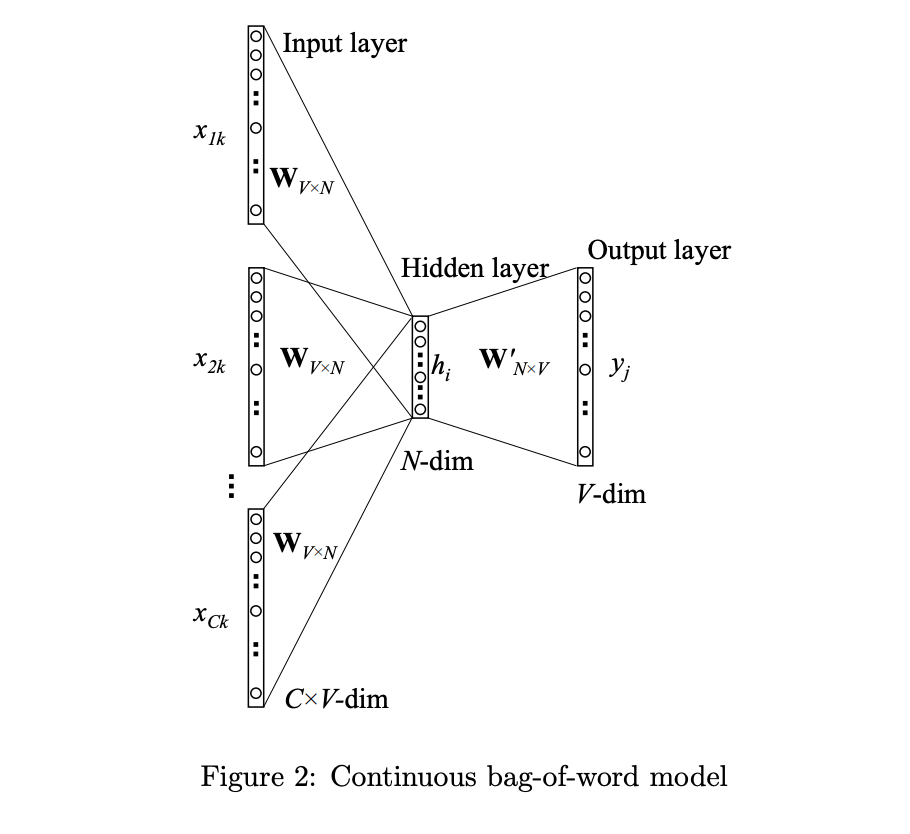
図にあるように,入力は周辺語であり出力は中心語になります.
簡単に各層について理解していきます.
-
Input Layer(入力層)
- $V$次元($V$=登場する語彙数)で,$C$個($C=$コンテキストの数)のニューロンからなります.
-
Hidden Layer(隠れ層,または中間層)
- $N$次元からなります
-
Output Layer(出力層)
- $V$次元のニューロンからなります.出力層のニューロンは$V$個ある単語のスコアになっており,その値が高いほどその単語が出現しやすいことを表しています.このスコアに対してSoftmax関数を当てはめると確率的な解釈を行うことができ,ある語を入力した時に出現しやすい語の**「確率」**を求めることができます.
ここで注目したいのが,全結合層が入力層→中間層の $W_{V×N}(W_{in})$ と,**中間層→出力層の$W_{N×V}(W_{out})$**の2種類存在する点です.
この全結合層の重み$W$の各行(行は語彙数$V$の数だけ存在)には,単語の分散表現が格納されていると考えることができます.
なぜなら,元々入力層の数だけあったニューロンをN次元に圧縮していると考えることができ,結果的に単語の情報がコンパクトにまとめられたと言える為です.
・ 利用する分散表現
word2vecで使用されるネットワークには2つの重みがあります.それは入力側の全結合層の重み($W_{in}$)と,出力層の全結合層の重み($W_{out}$)です.
Point : W_{in}\, or \,W_{out}
これまでも紹介したように,CBOWモデルで学習の結果得られる単語の分散表現には,入力側の重みである**$W_{in}$**と,出力側の重みである$W_{out}$の2種類があります.
ここで1つの疑問が湧きます.
それは,どちらの重みを使ったら良い結果が得られるのかという問題です.
多くの研究では,$W_{in}$だけを単語の分散表現として用いた方が良い結果が得られることが明らかにされていますが,$W_{out}$も使いようによっては,精度向上に役立つかもしれません.
3.3 学習データの準備
この節では,実際のコーパスを処理・分析する関数を理解することがGoalになります.
書籍では,実際のSentenceをどのようにNNに学習させるか,いわゆる前処理の段階を扱っています.
## 3.4 CBOWモデルの実装 この節では,word2vecをCBOWモデルを使って実装することを目指します. ~~CBOWモデルの学習を重ねるごとに,lossが小さくなるのを実感して喜ぶのがGoalになります~~ 実際に書籍のプログラムを回し,感動して見て下さい!!
3.5 word2vecに関する補足
この節では,word2vecのCBOWモデルを確率的な視点で見ること,また,word2vecのもう1つのモデルであるskip-gramモデルについて理解することがGoalになります.
・ CBOWモデルと確率
CBOWモデルが行うことは,コンテキストを与えるとターゲットとなる単語の確率を出力することでした.(中略)コンテキストとして$w_{t-1}$と$w_{t+1}$が与えられた時にターゲットが$w_{t}$となる確率は次のように表すことができます.
P(,w_{t}, |, w_{t-1},w_{t+1})
**コンテキスト($w_{t-1}$,$w_{t+1}$)からターゲット$w_{t}$が出現する確率を知りたい**,と考えた時にCBOWモデルは上の式をモデル化していると考えることができます.
### ・ skip-gramモデル
> word2vecでは2つのモデルが提案されています.1つはこれまで見てきたCBOWモデル,そしてもう1つはskip-gramと呼ばれるモデルです.skip-gramは,CBOWで扱うコンテキストとターゲットを逆転させたモデルです.
skip-gramモデルは,入力として中心語を与え,その周辺語を予測する教師あり学習モデルです.以下は,skip-gramモデルの概略図で,参考【1】から引用しました.

図にあるように,入力は中心語(1語)であり,出力は周辺語(コンテキストの数だけ存在)になります.
簡単に各層について理解していきます.
- Input Layer(入力層)
- $V$次元($V$=登場する語彙数)で,$1$つのニューロンからなります.
- Hidden Layer(隠れ層,または中間層)
- $N$次元からなります
- Output Layer(出力層)
- $V$次元($V$=登場する語彙数)で,$C$個($C=$コンテキストの数)のニューロンからなります.ある中心語に対する$C$つのコンテキストにおいて,出現されやすい語がスコアとして表されます.
先に示したCBOWモデルと比べてみると,skip-gramは入力が1ニューロンの一方で出力は周辺語の数だけ必要になり,**学習難しくない?? CBOWの方が絶対良いじゃん**と思いました.
そうした予想に反して,特に大規模なコーパスの場合にskip-gramモデルの方が良い精度を示す場合が多いそうです.以下のような理由からそのように考えられると思われます.
- 損失を計算する際に,コンテキストの数だけ求める必要があり1回の学習に時間がかかる
- これは一見デメリットのように思えますが,それだけしっかりと(??)学習しているとも捉えることができます.
- 大規模なコーパスの場合,低頻出な語(レアな語)が多い
- skip-gramはこうしたレアな語に対しても,良い感じに学習できるようです.
ちなみに,[こちらの論文](https://www.ai-gakkai.or.jp/jsai2016/webprogram/2016/pdf/436.pdf)ではCBOWモデルとskip-gramモデルの双方で実験を行ない,やはりskip-gramモデルの方が良い精度が出たそうです.
### ・カウントベースと推論ベースの比較
> カウントベースの手法は,コーパス全体の統計データから1回の学習で単語の分散表現を得ました.一方,推論ベースでは,コーパスの一部を何度も見ながら学習しました(ミニバッチ学習).
ここでは,カウントベース手法と推論ベース手法の比較を行いたいと思います.
- 新しい語彙を追加したい時:**推論ベースが良い**
- カウントベース
- ゼロから計算を行う為,大変(共起行列を作り直す必要があるため).
- 推論ベース
- これまで学習した「重み」を活かして,**再学習**できる
- 分散表現の性質・精度:**類似性に関する定量評価では遜色なし**
- カウントベース
- 単語の類似性を捉えることができる
- 類推問題は解けない
- 推論ベース
- 類似性&パターンも捉えることができる
- 例えば,「king - man + woman = queen」といった類推問題が解ける
<br>
## 3.6 まとめ
word2vecについて以下のようにまとめることができます.
### word2vecは・・・
- **複数層のNN**で構成される
- CBOWモデルとskip-gramモデルがあり,中心語(ターゲット)と周囲語(コンテキスト)の関係に注目する
- 重みの**再学習**が行える点で,カウントベース手法より優位
- ただし,精度においてカウントベースと**大きな差がある訳ではない**
---
# Chap3のまとめと所感
本章では,単語の分散表現を得るために**推論ベースの手法**,特に**word2vec**についての理解を深めることができました.
次章では,word2vecをより良いモデルにするための工夫について見ていきます.
それでは,次章Chapter4でお会いしましょう👋
---
# 参考文献
【1】[word2vec Parameter Learning Explained](https://arxiv.org/pdf/1411.2738.pdf)