🎄https://qiita.com/advent-calendar/2024/andfactory 16日目の記事です🍗
概要
SVD(特異値分解)で特定ユーザーをターゲットに映画を推薦する推薦システムを作ってみたのでその手順をチュートリアルっぽくまとめました。
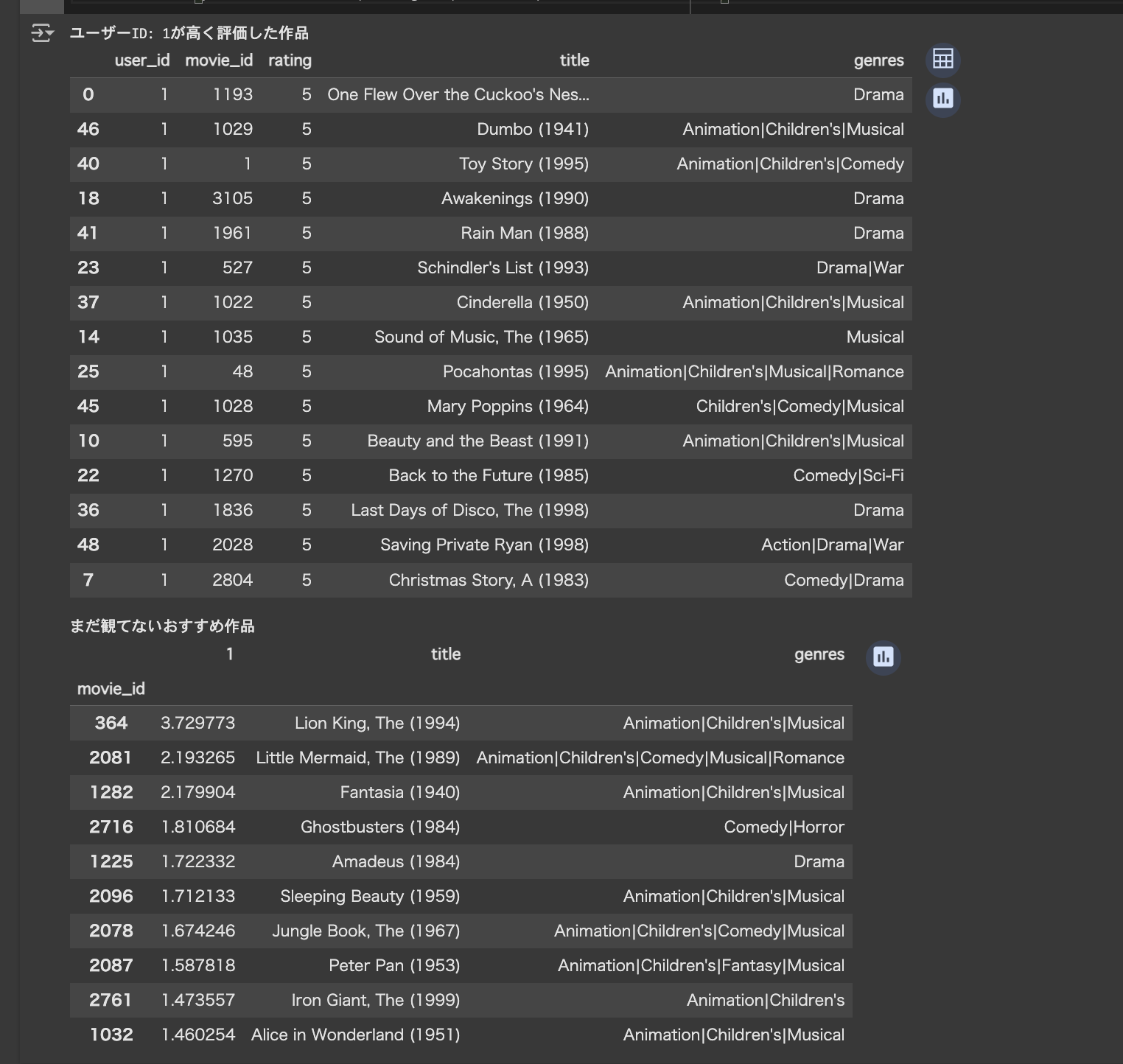
完成物を先出ししておきます。
SVD(特異値分解)について
特異値分解(SVD、singular value decomposition)とは、ある行列を3つの行列に分解し、その中の「特異値行列」のサイズを小さくする(次元削減する)ことで低次元の行列から元の行列の近似値を計算可能にする計算方法です。
(参考:https://cha-kabu.hatenablog.com/entry/2020/10/31/215515 )
推薦システムのコンテキストにおいては、アイテム数、ユーザー数が膨大なデータセットにおいて効力を発揮する手法だと言われています。
アイテム情報の行とユーザー情報の列からなる評価履歴の行列(本記事では便宜上「評価行列」と呼びます)があった場合に、これを3つの行列に分解することでアイテムとユーザーの傾向を表す潜在因子をベクトルの形で取り出すことができます。そしてこれら3つの行列から元のサイズの行列を再構成することで、ユーザーがまだ評価してないアイテムの評価値を予測することができます。この予測評価値の中からユーザーがまだ評価してないアイテムを抽出し、これを降順に並び替えることでターゲットがより高く評価しそうなアイテムを推薦できるという仕組みです。
行列の式としては下図のようになります。
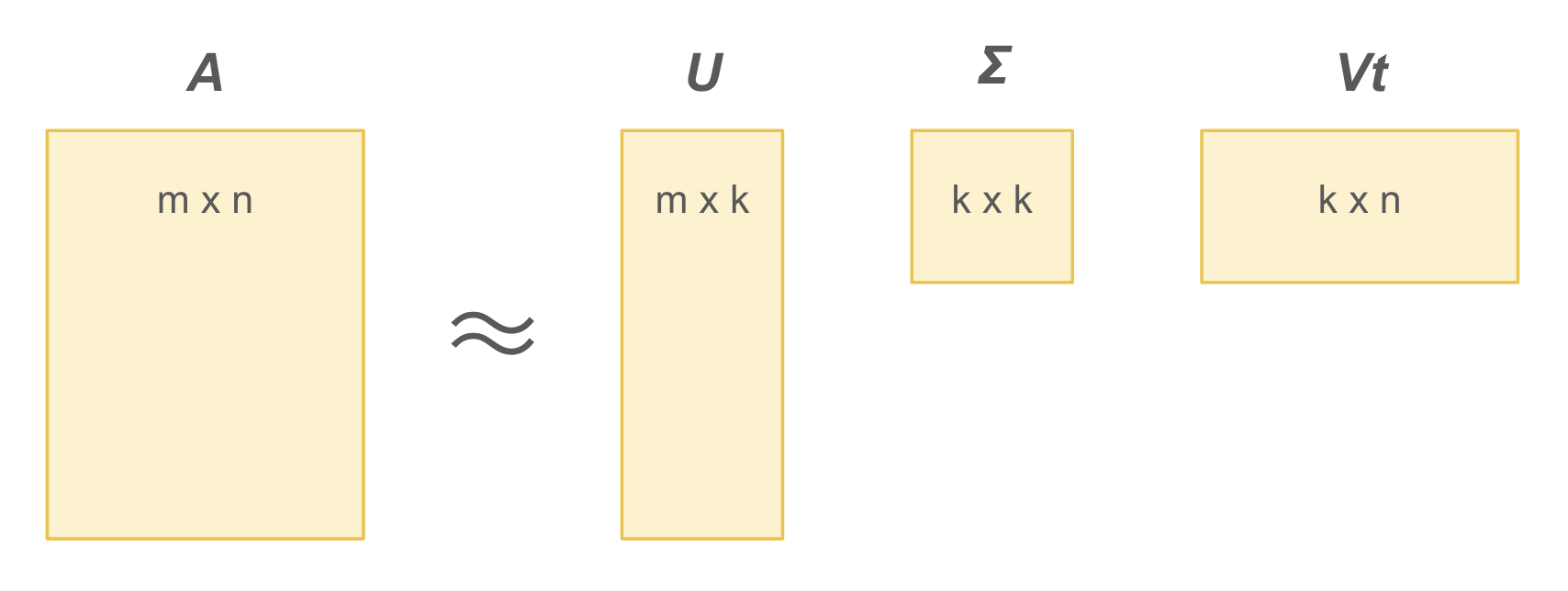
上の図で、A がアイテム情報を行に、ユーザー情報を列に持つオリジナル評価行列で、右の3つの行列がそれを分解した行列です。3つの行列はそれぞれ次のように説明されます。
- U : アイテムの潜在因子を表す m x k の行列
- Σ : それぞれの潜在因子の重み(重要度)である特異値を持つ k x k の対角行列
- Vt : ユーザーの潜在因子を表す k x n の行列
潜在因子は、イメージとしては「子ども向け」とか「デート向け」といった属性を数値の形で表現したものと考えれば分かりやすいでしょう(実際は具体的に説明できるものではありません)。
この特異値行列Σ のk値を小さくすることにより、大規模なアイテム群、ユーザー群に対する予測値計算を高速化することができるというのがSVDの最大の強みです。
数学的に詳しい説明はこちらの記事などを参照してみてください。
今回は実際にMovieLensのデータセットでSVDを試してみた結果を書いていきたいと思います。
実装
MovieLensの1M Datasetを使って作っていきます。作業はGoogle Colaboratoryで行いました。
セットアップ
ライブラリをインポートして、データセットをDLしColaboratoryのディレクトリに配置します。
import pandas as pd
import numpy as np
from scipy.sparse.linalg import svds
import requests
import zipfile
import os
import time
# データセットをダウンロードし解凍
url = "https://files.grouplens.org/datasets/movielens/ml-1m.zip"
zip_path = "ml-1m.zip"
response = requests.get(url)
with open(zip_path, "wb") as f:
f.write(response.content)
with zipfile.ZipFile(zip_path, "r") as zip_ref:
zip_ref.extractall(".")
作品情報、評価情報のDataFrame準備
SVDの処理自体はレビュー情報のcsvだけでも十分ですが、最後に作品タイトルと照合したりしたいので作品情報のDataFrameもスタンバイしておきます。
# 作品情報
movie_columns = ["movie_id", "title", "genres"]
movies_df = pd.read_csv(
"./ml-1m/movies.dat",
sep="::",
engine="python",
names=movie_columns,
index_col=0,
encoding="latin1"
)
# 文字列を20文字に制限して省略する関数(出力を見やすくするため)
def truncate_title(title, length=30):
if len(title) > length:
return title[:length] + "..."
return title
movies_df['title'] = movies_df['title'].apply(truncate_title)
# レビュー情報
ratings_columns = ["user_id", "movie_id", "rating", "timestamp"]
ratings_df = pd.read_csv(
"./ml-1m/ratings.dat",
sep="::",
engine="python",
names=ratings_columns
)
# timestampは不要
ratings_df = ratings_df.drop("timestamp", axis=1)
# 評価行列の作成
item_indexed_rating_df = pd.pivot_table(
data=ratings_df,
index="movie_id",
columns="user_id",
values="rating"
)
item_indexed_rating_df = item_indexed_rating_df.fillna(0)
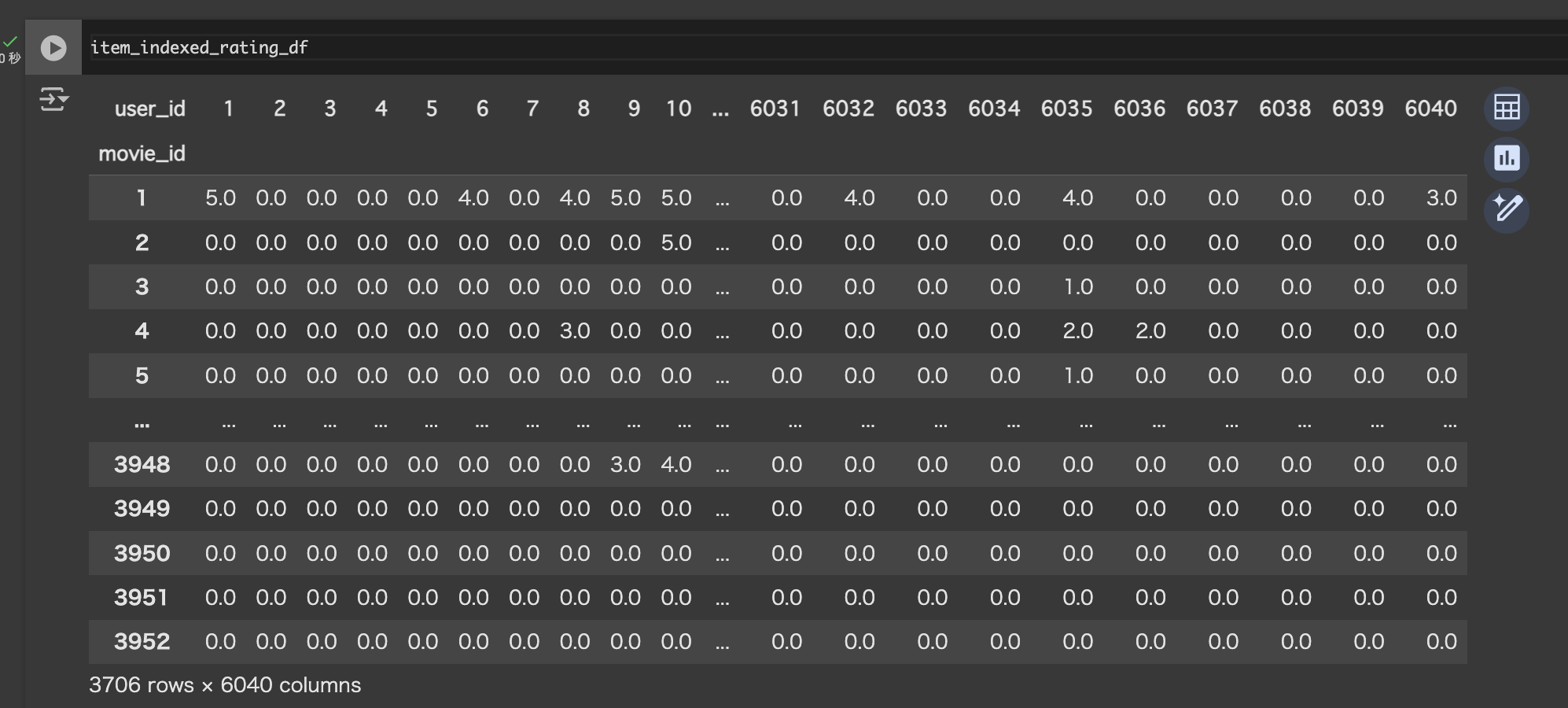
評価行列の作成
ユーザーIDを列に、映画IDを行にして、各ユーザーが各映画につけた評価値を格納した評価行列を作成します。まだ評価していない映画に対しては今回は0埋めで進めます(平均値で埋める手法も推奨されてます)。3706行、6040列のDataFrameができていればOKです。
# 評価行列の作成
item_indexed_rating_df = pd.pivot_table(
data=ratings_df,
index="movie_id",
columns="user_id",
values="rating"
)
item_indexed_rating_df = item_indexed_rating_df.fillna(0)
SVD(特異値分解)処理
それでは本題の特異値分解です。今回はSciPyライブラリのsvds関数を使います。
SVDを実現するのにsurpriseライブラリやnumpy.linalg.svd関数を使うやり方もありますが、SciPyのsvds関数は引数で特異値を指定することができ、精度は落ちつつも短時間で処理が完了するのが良いと思ったので今回はこちらを採用しました(このタイプのSVDは「部分特異値分解 partial singular value decomposition」と呼ばれるようです)。
評価行列のDataFrameをndarrayに変換し、svds関数に渡して特異値分解を実行します。これにより評価値予測に必要なU、sigma、Vtの3つの行列が得られます。
# Convert to NumPy array
rating_matrix = item_indexed_rating_df.values
# 部分特異値分解の実行(特異値の数は今回は50を指定)
U, sigma, Vt = svds(rating_matrix, k=50)
Sigma = np.diag(sigma)
print("U shape:", U.shape, ", Sigma shape:", Sigma.shape, ", Vt shape:", Vt.shape)
# print> U shape: (3706, 50) , Sigma shape: (50, 50) , Vt shape: (50, 6040)
ちなみに実行時間の参考に、numpy.linalg.svd関数と比較した結果も置いておきます。特異値の数を絞っているので当然ですがsvdsの方が圧倒的に早く終わります。
# scipy.sparse.linalg.svds()の場合
start_time = time.time()
U, sigma, Vt = svds(rating_matrix, k=50)
Sigma = np.diag(sigma)
print("scipy.sparse.linalg.svds() 実行時間:", time.time() - start_time, "sec.")
# print> scipy.sparse.linalg.svds() 実行時間: 7.8313539028167725 sec.
# 参考:numpy.linalg.svd(full_matrices=False) の場合
start_time = time.time()
refU, refS, refVt = np.linalg.svd(rating_matrix, full_matrices=False)
print("numpy.linalg.svd() 実行時間:", time.time() - start_time, "sec.")
# print> numpy.linalg.svd() 実行時間: 101.87713575363159 sec.
ユーザーの評価値を予測
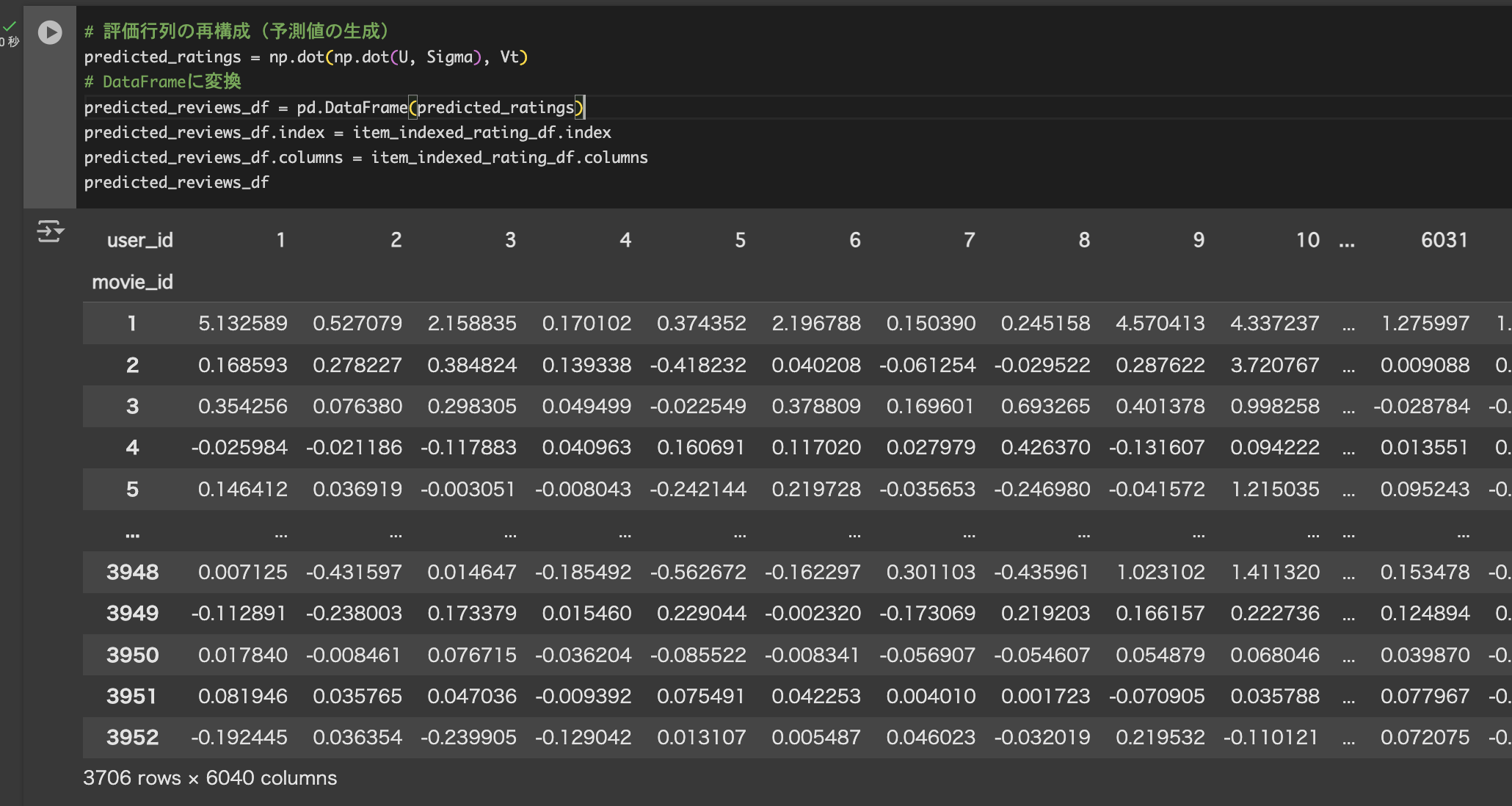
U、Σ、Vtが得られたのでこれらを元に予測評価行列を計算します。
分解した3行列をそのままドット積で掛け合わせることで評価値行列を計算します。計算結果のndarrayはDataFrame型に変換し、作品情報を照合できるようオリジナルの評価行列からmovie_idを持ってきてindexに格納します。
これでユーザーと映画の予測評価値テーブルの完成です。
# 評価行列の再構成(予測値の生成)
predicted_ratings = np.dot(np.dot(U, Sigma), Vt)
# DataFrameに変換
predicted_reviews_df = pd.DataFrame(predicted_ratings)
# indexラベルに"movie_id"、columnラベルに"user_id"を設定
predicted_reviews_df.index = item_indexed_rating_df.index
predicted_reviews_df.columns = item_indexed_rating_df.columns
predicted_reviews_df
ユーザーごとにおすすめ作品を抽出
あとはユーザーがまだ観てない作品から予測評価値が高い作品を以下の手順で抽出します。
- ユーザーがすでに観た映画のidをオリジナル評価値のDataFrameから取得
- 予測評価値のテーブルから指定のユーザー列を取り出す
- 取り出した列からすでに観た映画を取り除く
- 取り除いた上で予測評価値の高い順にソートし、上からn件を取り出す
こちらは関数にまとめました。
def recommend_movies(predicted_ratings_df, original_ratings_df, user_id: int, num_recommendations=10):
selected_user_id = user_id
# 選択したユーザーが見た映画のidの配列
item_list_user_watched = original_ratings_df[original_ratings_df['user_id'] == selected_user_id]['movie_id'].tolist()
# 選択したユーザーの全予測評価値を取得
all_predicted = predicted_ratings_df.loc[:, selected_user_id].sort_values(ascending=False)
# まだ観てない映画の予測評価値を取得
unwatched = all_predicted[~all_predicted.index.isin(item_list_user_watched)]
# 予測値の高い方からn件を取得
selected_user_recommends = unwatched.sort_values(ascending=False).head(num_recommendations)
# 選択したユーザーの過去の評価一覧をプレビュー
selected_user_ratings = original_ratings_df[original_ratings_df['user_id'] == selected_user_id]
user_history_df = pd.merge(
selected_user_ratings,
movies_df,
left_on="movie_id",
right_on="movie_id",
how="inner"
)
print(f"ユーザーID: {user_id}が高く評価した作品")
display(user_history_df.sort_values('rating', ascending=False).head(15))
# レコメンドされたタイトル一覧をプレビュー
new_recommends_df = pd.merge(
selected_user_recommends,
movies_df,
left_index=True,
right_index=True,
how="inner"
)
print("\nまだ観てないおすすめ作品")
display(new_recommends_df)
最後にレコメンド実行です。
# レコメンド実行
recommend_movies(predicted_reviews_df, ratings_df, user_id=1, num_recommendations=10)
おすすめされた作品を見ると『ライオンキング』『リトルマーメイド』『ファンタジア』とアニメ映画がかなり推薦されています。このユーザーが過去に高く評価した作品の方にも『ダンボ』『トイストーリー』『シンデレラ』とアニメのものが多いので、まずまず納得できる結果になったのではないでしょうか。
終わりに
SVDでそれなりに使えそうな推薦システムが作れました。
今回はSVDの中でも部分特異値分解の手法を取ることでパフォーマンスを高く保ちつつ、精度もそこそこなシステムを作れましたが、特異値をかなり狭めに取ったことでオリジナルの評価値と予測評価値の間にけっこうな誤差があることは留意しておいても良いでしょう。
本当ならこの辺りの精度評価をRSMEだとか何やらを使って客観的に行う必要があると思いますが、目視で個別ユーザーにフォーカスしてみて「それっぽい」と思えるならそれはそれで一つの正解なんじゃないかなと思います。ユーザーにとって嬉しいレコメンドが必ずしも予測制度と一致するとは限りませんので。
それから、最初に評価行列の欠損を0で埋めてしまいましたがユーザー評価の平均値で埋めた方がRSMEのスコアは上がると『推薦システム実践入門』では紹介されていました。こちらのやり方でもまた試してみたいですね。
あと、SVDの致命的な欠点としてレビュー情報存在しないアイテムは推薦できないコールドスタート問題があります。これについてはコンテンツベースフィルタリングなどの他の推薦システムを併用するアプローチを採用する必要があるかと思います。こちらもSVDとは別の話になってくるのでまた別の記事として書いてみようかなーと思ってます。
まだまだ浅学な身ですが、推薦システムは奥が深くて面白いですね。
ここまで読んでいただきありがとうございましたm(_ _)m
参考