概要
and factoryでiOSエンジニアをやってる@chitomo12です。
最近、個人的に推薦システムに対する熱量がヒートしており、普段はデータサイエンス的な業務にはほとんど携わってないですがちょっくら簡易的な推薦システムを作ってみることにしました。
完成物は下画像のようなものになります。

どんな推薦システムを作りたいか
現在参与しているのが漫画アプリのプロジェクトなので、いつかは漫画を推薦するシステムが作れたら〜というのが理想です。
残念ながら、学習目的で推薦システムを作るにあたり漫画のデータセットというのは世の中に存在しないので、代わりに映画のレビューのデータセットとして有名なMovieLensを使った映画の推薦システムを作ることにします。
今回はAmazonの「この商品に関連する商品」のようにユーザーではなく映画同士の類似性をもとに、ある映画に近い(類似度が高い)他の映画を推薦したいと思い、今回試してみたのが「協調フィルタリング」です。

協調フィルタリングについて
協調フィルタリングとは、あるユーザーに対してその人と好みの近い他ユーザーが好むアイテムを推薦する手法です。
たとえば、ニンテンドースイッチと「あつまれどうぶつの森」を買ったユーザーが沢山いたとすると、ニンテンドースイッチだけ買ったユーザーも「あつまれどうぶつの森」を気に入るだろうと予測して推薦する、という推薦手法です。
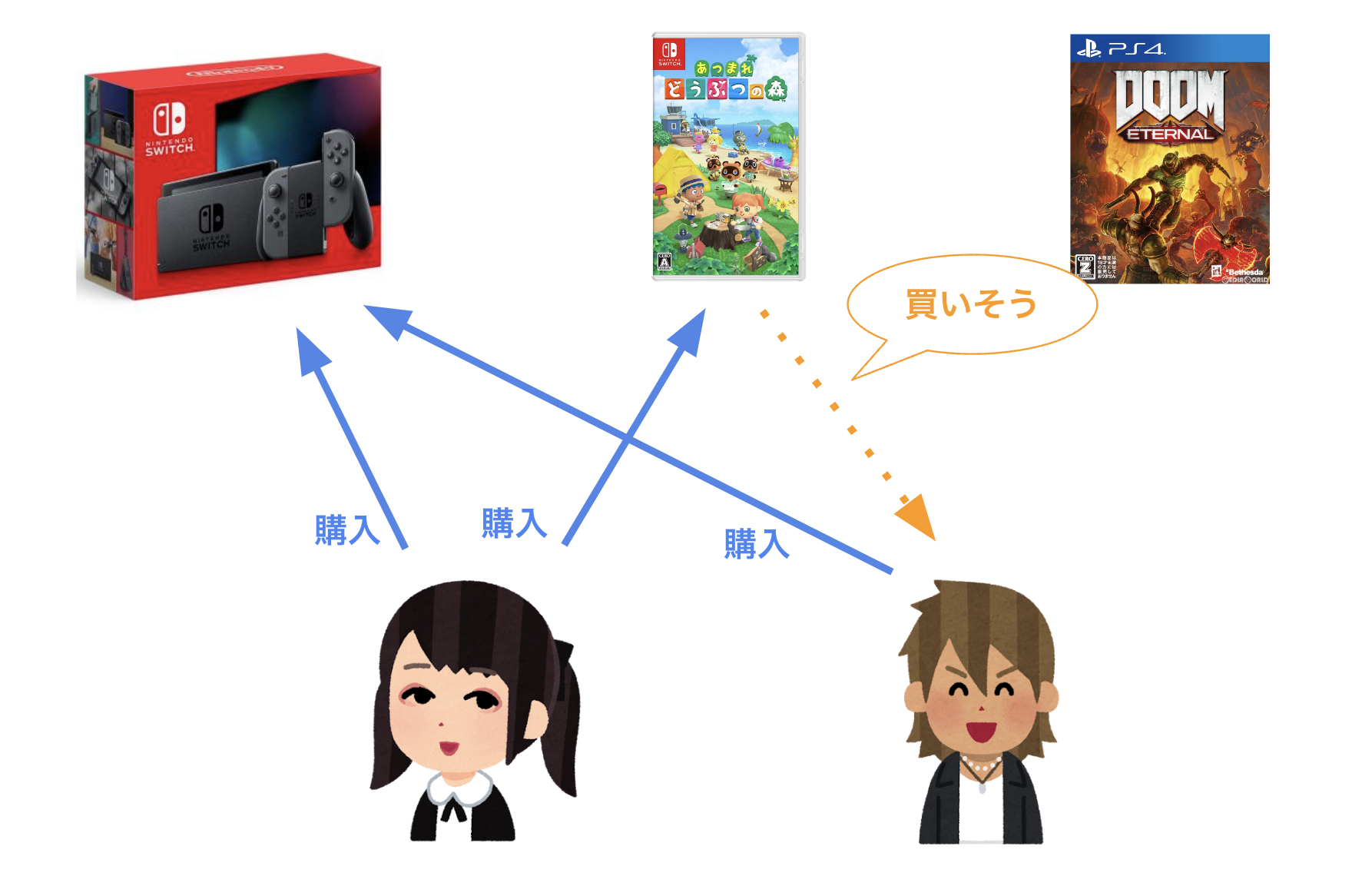
実際のWebサービスだとユーザーごとにパーソナライズしてアイテムを推薦したい場合に他ユーザーの行動を参考にアイテムを推薦すると良い結果が得られるということで協調フィルタリングが活用されている模様です。
今回はAmazonの「この商品に関連する商品」のように任意のアイテムが他アイテムにどれだけ類似しているかを割り出したいので、ユーザー同士の類似度を映画のレビュー値で測るのではなく、映画同士の類似度をユーザーからの評価値によって計ることにしました。
実装
ブラウザ上で完結するGoogle ColabでPythonを書いていきます。
必要なライブラリをインポート
# データセットのダウンロード用
import requests
import zipfile
# ベクトル計算用
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 処理時間計測用
import time
データセットをダウンロード
MovieLensのデータセットをダウンロードし、Colabのディレクトリに解答します。
使用するデータセットは、6000人のユーザーによる4000本の作品に対する100万のレビュー情報を収容したMovieLens 1M Dataset です。
# データセットをダウンロードし解凍
url = "https://files.grouplens.org/datasets/movielens/ml-1m.zip"
zip_path = "ml-1m.zip"
response = requests.get(url)
with open(zip_path, "wb") as f:
f.write(response.content)
with zipfile.ZipFile(zip_path, "r") as zip_ref:
zip_ref.extractall(".")
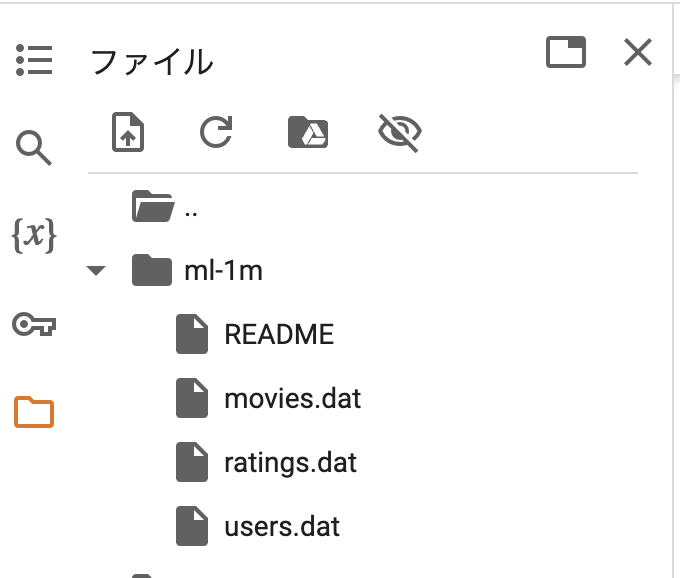
サイドバーのファイルにml-1mディレクトリが展開されていればOKです。
データセットの読み込み
レコメンド処理実行後に作品名を確認できるよう、movie_idとtitleが含まれるmovies.datを読み込みDataFrame化しておきます。
# 作品情報を読み込みデータフレーム化
movie_columns = ["movie_id", "title", "genres"]
movies_df = pd.read_csv(
"./ml-1m/movies.dat",
sep="::",
engine="python",
names=movie_columns,
encoding="latin1"
)
# 確認
movies_df.head()

よくあるチュートリアルだとmovie_idを吐き出して終わりで、「それらしい」推薦システムにどれくらい近づいたかの検証がされてない印象なので、冗長ですがこの処理を挟み込むことにしました。
次にレビューのデータを読み込みます。
レビュー情報が入ったratings.datはユーザーと映画のレビュー記録が縦に長く並んだ形式なので、これを後述するコサイン類似度の計算で扱えるようpd.pivot_tableで表形式に変換します。行にmovie_id、列にuser_id、値にratingを指定しています。
# レビュー情報を読み込み
ratings_columns = ["user_id", "movie_id", "rating", "timestamp"]
ratings_df = pd.read_csv(
"./ml-1m/ratings.dat",
sep="::",
engine="python",
names=ratings_columns
)
#
item_indexed_rating_df = pd.pivot_table(
data=ratings_df.drop("timestamp", axis=1),
index="movie_id",
columns="user_id",
values="rating"
)
# NaNは0で埋める
item_indexed_rating_df = item_indexed_rating_df.fillna(0)
# 確認
item_indexed_rating_df

コードを実行して、出力に3706行(映画のid数)、6040列(ユーザーのid数)のDataFrameが表示されていればOKです。
コサイン類似度計算によるレコメンド関数
ここから本題である協調フィルタリングのロジックを作っていきます。
おさらいですが、協調フィルタリングでは特定のアイテムの傾向をアイテム自体が持つ情報(アイテム名、カテゴリなど)ではなく、そのアイテムに対するユーザーの反応を元に、そのアイテムと近いアイテムを探索します。
この其々のアイテムに紐づくユーザーの反応(item:1に対するuser:1の評価、user:2の評価 etc…)をコンピュータで計算可能な形に変換したのが先のステップで作成したitem_indexed_rating_dfの各行の[0, 1, 1, …]といった数値の集合で、この数値の集合を数学的な「ベクトル」として扱い、ベクトル同士の類似度を計算することで特定のアイテムが他のアイテムとどれくらい近いかを数値として表すことができます。
ではベクトル同士の類似度を計算するのに何を類似度の尺度とするかということで、一般的に起用されるのが 「コサイン類似度」 です。
高校数学で数Cを学んだ人は 「内積」 という言葉に覚えがあるかと思います。
「ベクトルa・ベクトルb」で表される式を「ベクトルa、ベクトルbの内積」などと呼び、また下の式のようにも表現することができます(数式の証明は割愛します。気になる人はこの辺の資料を参考ください)。
$$
\vec{a}\cdot\vec{b}=|a||b|\cos\theta
$$
この式をcosθ基準の式にすればベクトルaとベクトルbの角度を求めることができます。
$$
\cos\theta=\dfrac{\vec{a}\cdot\vec{b}}{|a||b|}
$$
この公式を応用し、ベクトルaとベクトルbがなす角度θを類似度の尺度にしたものがコサイン類似度というものです。ベクトルaとベクトルbの角度が小さい(≒cosθが1に近似する)ほど、二つのベクトルは類似度が高いと考えられるわけです。
高校数学では2次元ベクトルか3次元ベクトルばかりが問題に出てきたかと思いますが、この公式を適用できるベクトルの次元数に理論上上限はありません。
つまり、MovieLensのデータセットから作られた6040次元ベクトルのユーザーレビューもこれで類似度を計算できるというわけです。
これを簡易的にPythonで書くと次のようなコードになります。
# サンプル
vector_A = np.array([1, 0, 1])
vector_B = np.array([0, 1, 1])
# 内積計算
dot_product = np.dot(vector_A, vector_B)
# ノルム(ベクトルの大きさ)の計算
norm_A = np.linalg.norm(vector_A)
norm_B = np.linalg.norm(vector_B)
# cos類似度計算
cosine_similarity = dot_product / (norm_A * norm_B)
print("Cosine_similarity:", cosine_similarity)
# Result -> Cosine_similarity: 0.4999999999999999
これはオープンソースの機械学習ライブラリであるscikit-learnのcosine_similarity()関数を使うとさらに短く書くこともできます。
# サンプル
vector_a = np.array([[1, 0, 1]])
vector_b = np.array([[0, 1, 1]])
# コサイン類似度を計算
similarity = cosine_similarity(vector_a, vector_b)
print("Cosine Similarity:", similarity[0][0])
# Result -> Cosine Similarity: 0.4999999999999999
以上を元に、レコメンドのロジックを実装していきます。
まずはアイテム同士のコサイン類似度を計算します。アイテムをindexに持つ行列をcosine_similarity関数に渡すことで全アイテム分のコサイン類似度を算出することができます。渡すときの型はnumpy.ndarrayです。
sim = cosine_similarity(item_indexed_rating_df.values)
similarity_df = pd.DataFrame(
sim,
index=item_indexed_rating_df.index,
columns=item_indexed_rating_df.index
)
similarity_df

次に作品のIDを渡して、その作品と他の全作品のコサイン類似度のSeriesから上位数件のアイテムを返す関数を作ります。
def recommend_similar_item(base_item_id: int, rating_df, movies_df, similarity_df):
"""
指定したitem_idに類似したitem_idを探索する関数.
Args:
base_item_id (int): 対象とする作品のID.
rating_df (DataFrame): 表形式のRating情報のDataFrame.
movies_df (DataFrame): IDとタイトル情報を持つDataFrame.
similarity_df (DataFrame): 類似度を格納したDataFrame.
Returns:
DataFrame: 最も類似度の高い11作品(元作品含む)のDataFrame.
"""
# 処理時間計測(任意)
start_time = time.time()
# base_item_idに合致する行が無い場合はエラーを返す(任意)
if base_item_id not in rating_df.index:
raise ValueError(f"base_item_id {base_item_id} is not found in rating_df.")
# ログ(任意)
base_item_title = movies_df[movies_df["movie_id"] == base_item_id]["title"]
print(base_item_title, "に近い作品を探索します...")
# 類似度を格納するDataFrameを作成
item_sim_list = pd.DataFrame(columns=['base_item_id', 'target_item_id', 'similarity'])
item_sim_list["similarity"] = similarity_df[base_item_id]
item_sim_list["target_item_id"] = similarity_df.index
item_sim_list["base_item_id"] = base_item_id
# item_sim_listとitem_master_dfを結合
item_sim_list_with_title = pd.merge(
left=item_sim_list,
right=movies_df,
left_on="target_item_id",
right_on="movie_id",
how="outer"
)
# 類似度の高い作品を抽出
recommends_top_ten = item_sim_list_with_title.sort_values(
by="similarity",
ascending=False
).head(11)[
["target_item_id",'title','similarity']
]
print("実行時間:", time.time() - start_time, "sec.")
return recommends_top_ten
実行します。サンプルでは『Men in Black』(id: 1580)と近い作品を探してもらいました。
# 推薦実行
recommend_similar_item(1580, item_indexed_rating_df, movies_df, similarity_df)

最もユーザー評価の近い3作品は『ジュラシックパーク』、『ターミネーター2』、『マトリックス』という結果が返ってきました。『メン・イン・ブラック』がアクションSF映画であることを踏まえるとそれなりに納得感のある結果になったのではないでしょうか。
おわりに
協調フィルタリングで良い感じの映画推薦システムを作ることができました。
ユーザーレビューが存在すること前提なので所謂コールドスタート問題は残っていますが、ある程度データの蓄積があるアイテムについては結構実用に耐えうるんじゃないかと思います。
今回はアイテム別に「この商品に似た商品」を出してみたので、次回はユーザー別におすすめ作品を提案する推薦システムを作ってみようかなと思います。
続き↓
参考
2024/12/22追記
最初に記事公開した時点で、cosine_similarity関数の引数を1つのndarrayにすることで全index分の類似度を一気に計算してくれることを知らず、for文で1行1行の類似度を計算するという冗長極まりないコードを書いていました。最新版では修正済みになってます。誤解を招いてしまいましたことお詫び致します。