今回は、3D点群から物体を見つけるアルゴ、PointPillarsを解説するぞ。
え、なんのためにするかって?
自動運転に使うためさ!(そしてWaymoデータセットで訓練したいZE・ω・)
Waymoデータセット知りたい方はこちら
Waymo自動運転車のデータセットを可視化するんだよ!
Waymo大先生のデータセットつかって、物体検出したいけど、何を使えばいいのやら...
そしたら3D物体検出のState-of-the-artを調べると、PointPillarsがでてきて気になるぞ!
PointPillars
タピオカとPointPillarsどちらが素晴らしいのか!
それではPointPillarsの世界へようこそ!
- PointPillarsの仕組みは?
- 点群のData augmentationはどうやる?
- 計算の高速化テクニックは?
気になった人はLet's DIVE IN!!!!
(間違っているところあったら教えてね)

この記事ですること
- PointPillarsの解説
- Abstract
- Introduction
- PointPillars Network
- Implementation Details
- Experimental Setup
- Realtime Inference
- まとめ
※論文に沿って原理、仕組みを解説していきます、実装関連は次回にします
論文リンク 発表は2018年末
PointPillars: Fast Encoders for Object Detection from Point Clouds
Abstract
PointPillarsの特徴
- 3Dの点群から物体検出を行う
- PointNetsと呼ばれるネットワーク構造を使用して、点群を縦の柱の集合体にみたてる
- LIDAR点群のみ使ったアルゴだが、フュージョンアルゴと比べてもいい性能が出る
- 動作が早い、KITTIベンチマーク(3D,bird's Eye view)を62Hz
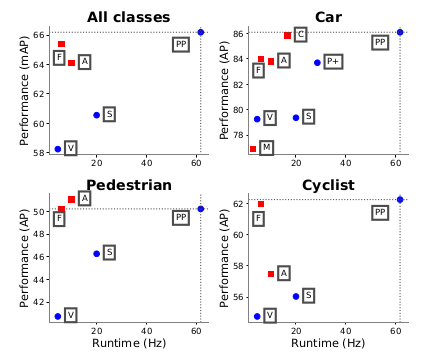
上図では”PP"(PointPillars)がKITTIテストデータの各種物体検出において
検出性能と検出速度の両方において優れているのがわかる。
対抗馬は
M: MV3D
A: AVOD
C: ContFuse
V: VoxelNet
F: Frunstum PointNet
S: SECOND
P+: PIXOR++
Introduction
DeepLearningの技術が3D点群を処理する方法は過去に考えられてきた。
過去の点群から物体検出する論文に共通する点は
- 点群はスパースであること、画像は非常に密であること
- 点群は3Dで、画像は2Dであること
点群を2Dに見立てる研究は過去にもされており、下記のような種類がある
- 点群を鳥瞰視点に変換して物体検出するもの
- 点群を主観視点に変換して物体検出するもの
最近では鳥瞰視点を用いたものが流行っている
長所:
- サイズがはっきりわかる
- 近傍ではオクルージョンが少ない
短所:
- 非常に点がスパースであるため、単純にCNNに入れるのではうまくいかない
上記の短所を解決するために、
VoxelNetやPointNetという手法がある、
しかしそれらは処理速度が非常に遅いのが問題点であった。
上記問題点を解決するために、PointPillarsを提案する。
下記は特徴:
- 2D convolution layerを用いたend2end 3D物体検出、2Dベースのため計算が高速
- 点群を縦柱(pillar)に見立てて3Dで物体の検出をする
- pillarで扱うことによりvoxelのように点群の高さを区切るビンの高さ設定が不要になった
Point Pillars Network
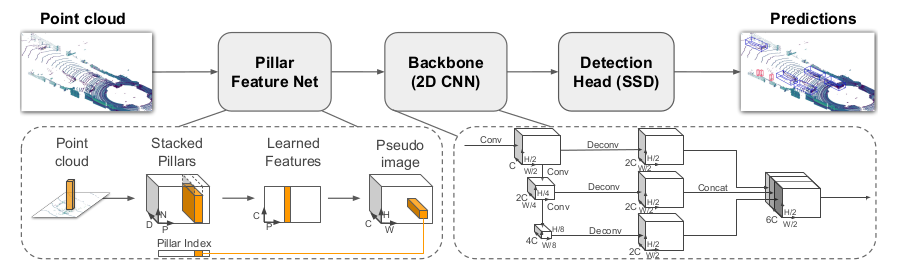
PointPillarsの入出力
入力:3D点群
出力:3Dバウンディングボックス(車、歩行者、サイクリスト)
3つのメインステージ
- Pillar Feature Net: 点群をスパースなpseudo imageに変換する
- Backbone (2D CNN): pseudo imageをハイレベル特徴量へ変換する
- Detection Head(SSD): 検出と3Dボックスへの回帰を行う
PointCloud to Pseudo-Image
2D CNNで点群を扱うためには、まず点群をpseudo-imageへ変換する。
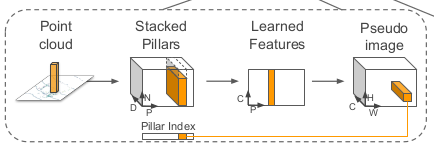
l:点群の中の点
x,y,z,r: 点に付随する位置と、反射強度の値
xy平面上をpillar, Pで分割する。(pillarで表現するため、Z側の高さは必要ない)
(例:0.16m * 0.16m等)
pillar内の点は下記の値を計算する
xc, yc, zc: pillar内のすべての点の座標の平均からの距離
xp, yp: pillar中心からのオフセット
上記の計算を終えて、点lは9次元の値を持つ。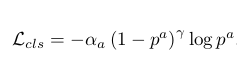
これにより、tensor sizeは、size(D,P,N)となる
D x P x N = 単点が保有する次元数(9) x 点の存在するpillarの数 x pillarに存在する点の数
(D, P, N) tensorをPointNetにかけて(Linear layer→Batch-Norm→ReLu)、(C, P, N) tensorを取得
CはPointNet出力の全結合層のレイヤ数に依存する
Cを取得した後、(C,H,W)のpseudo-imageに変換する(H,W)は鳥瞰視点でみたキャンバスサイズ。
(C,H,W)にすることで、通常の色画像と似た扱いが可能になる。
Backbone(2D CNN)
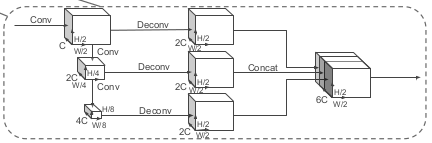
Backboneは主に2つのネットワークで構成されている
- top-down network: 段階的に次元数を下げていき、各段階で特徴抽出する。
- second network: top-downの各段階の特徴量のupsampling, concatenationを行う
(C,H,W)のpsuedo画像を、(6C, H/2, W/2)のtensorに変換する
Detection Head(SSD)
ここではsingle shot detectorを使用する。
SSDのprior boxと、真値2D BoxのIoUを使用してマッチングさせる。
マッチング結果から、クラス分類、物体の位置と高さを推論する
Implementation Details
Loss Functions
ロス関数は、SECONDの論文に準拠する
3つの要素のロス関数がある
- 位置
- クラス
- 向き
3D boxは、ground truthとanchor box含め下記で表現する
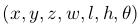
各要素のerrorは下記で計算する
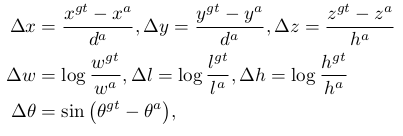
gtはground truth, aはanchor boxを示す
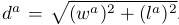
【位置のロス関数】
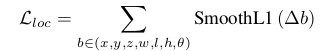
【向きのロス関数】
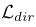
方位角をクラス化したものの、分類ロス計算する
【クラス分類のロス関数】
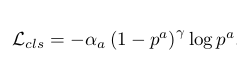
$p^a$は、anchor boxのクラス確率
$\alpha$ = 0.25
$\gamma$ = 0.2
【総合のロス関数】
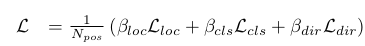
$\beta$loc = 2
$\beta$cls = 1
$\beta$dir = 0.2
Experimental Setup
Setting
pillarの寸法:0.16m * 0.16m
pillarの最大数:12000
ひとつのpillarにおける最大の点数: 100
Data Augmentation
訓練はKITTIデータ・セットを用いて行う
augmentationはどうやるのか?
以下の手順で行う
- 各クラスに所属する点群リストのテーブルをデータセット全体から作成する
- 例:車、というクラスに対して、フレーム0~100の車属性の物体が並び、それぞれに点群が紐付いている
- 訓練するフレームに、ランダムで上記テーブルから物体を呼び出す
- さらにフレームに存在するground truthと、付け加えた物体の位置をずらす、回転を加える
- 車両進行方向へのミラーリング、点群全体の回転、スケーリング
- 点群全体の並進移動
Realtime Inference
計算のステップと処理時間は下記の通り
実装はpytorchで行われている
- 点群の読み込み、距離のクロッピング 1.4ms
- 点をピラーに分割する 2.7ms
- PointPillar tensorがGPUへアップロードされる 2.9ms
- encoding 1.3ms
- pseudo-imageへ変換する 0.1ms
- backbone & detection head 7.7ms
- non maximum suppression 0.1ms
PointPillarsはi7 Intel CPU + GTX1080Tiにて、16.2ms/frameの処理速度(車両前方の点群のみ)
高速化のテクニックは?
Encoding
前述のPillar feature netの処理にかかる時間が1.3ms
(厳密には(D,P,N)tensorを(C,H,W)tensorに変換するまでの時間)
VoxelNet(190ms)やSECOND(50ms)のエンコード処理時間を大幅に短縮
Slimmer Design
PointPillarsはPointNetの使用を一回に抑えている。
VoxelNetはPointNetを2回連続で使用しているのに対して高速。
また、PointsNetの出力である(C,H,W)tensor のC項を64に設定することで高速化、
さらに、2D CNN back boneではアップサンプリングを128に設定することで高速化。
この値はどれもオリジナルの半分以下だが、検出性能の低下がなかった。
TensorRT
前述のPointPillarsの処理パイプライン:
- Pillar Feature Net: 点群をスパースなpseudo imageに変換する
- Backbone (2D CNN): pseudo imageをハイレベル特徴量へ変換する
- Detection Head(SSD): 検出と3Dボックスへの回帰を行う
これらGPUを使用する処理をTensorRT(GPU推論に最適化されたライブラリ)を使用して高速化。
これにより50%の高速化に成功。
まとめ
以上がPointPillars論文の解説でした、
簡単にまとめると
- 3D点群から3D物体ボックスを出力するアルゴリズム
- 3D点群を、pillarで分割し、2D CNNに入力できるように畳み込み、クラス分類と検出を行う
- 2Dでの取扱いを行うエンコーダと、PointNetの使用回数を1回に留めること、TensorRTの利用で非常に高速な処理が可能になった
3D点群の処理は非常に重く、どうやって高速化しているのかが非常に気になっていました。
3Dを柱に分割して、畳み込んで2Dのフレームワークに落とし込む、というのがPointPillarsのキモみたい。
また点群のdata augmentationも、他のフレームの物体を召喚する!感じでなかなか面白い!
デスクトップPCで62Hz~105Hz出るアルゴなので、車両搭載では、組み込み端末であること、全周囲の点群があることを差し引いて
どれくらいの速度で動くのかカギになりますね
2Dに畳み込むというアイデアを応用すれば、
Waymoデータセットに付随しているLIDARのelongationなんかも、足してみると検出性能あがったり...?
夢が膨らむよね。(処理速度落ちるんだろうな...)

次回はPointPillars実装を見ていくぞ!(Waymo datasetで使えるようになるのを目指すぞ!)
それでは〜