前置き
ついに三十路になりました。
それはさておき今回は当初書く予定だったGASについて放出してしまったので、ネタに困っていたところ兼ねてより画像のラベリングやりたいなっていう思いがあったので今回はGoogleのCloud Vision APIを試してみることにしました。
とりあえず公式へってところでAutoMLなんていうパーソナライズされたモデルが作れる様になった事を初めて知り、どうせならこっちやってみるか簡単にできるみたいだしって事で、予定を変更してAutoML試してみた記事です。
GoogleのAutoMLで誰もが機械学習を利用できる――プログラミング不要、ビジネス利用へも
https://jp.techcrunch.com/2018/01/18/2018-01-17-googles-automl-lets-you-train-custom-machine-learning-models-without-having-to-code/
試してみる
AutoMLはプラットフォーム上に独自のモデルを持てる事が特徴で、APIで提供されている画像解析系のサービスでは出来なかった目的に特化した独自モデルを作成することが出来るとのことです。
さらに継続した学習も有料ですが可能で、チューニングしながら目的に則したモデルを育てられる事が売りなようです。
詳しいこと使い方に関してはこちらを参考にさせていただきました。
- Cloud AutoML Vision が本当にノンプログラミングで使えるのか試してみた
- AutoML Visionをためしてみた
今回の目的は、以前の記事でも書いたTwitterから集めてきた画像へのラベリングです。
以前はハッシュタグで分類していましたが、紆余曲折を経てお気に入りした画像という対象にしてしまったため、その後の分類が面倒と感じていました。
それこそハッシュタグやテキスト解析やらの方が良い結果が得られそうなお代ですが、今回はAutoMLを使って、集めてきた画像が分類出来るか試してみます。
分類するラベルは以下の5つです。
- Fate:※FGO、Fate関連全て
- Azurlane
- Dolls
- Kancolle:後から追加
- Other:※その他全部
使い方
AutoMLの初期セットアップについては割愛します。
参考サイトの方を確認してください。
データセットの準備
今回はGASで収集していた画像、特にハッシュタグで分類済みの画像をGoogle Cloud Storageに格納します。
AutoMLに直でも可能ですが、ファイル一つづつになるのでGCSにアップロードして.csvファイルを作ったほうが楽です。
だいたい1ラベル辺り1000枚あると良いらしいです。
csvファイルにはGCSのバケット内に上げた画像のパス、それとラベルをセットします。
(アップロードする場所をプロジェクト名のディレクトリ外にすると取り込めないので注意です)
gs://対象バケット/ファイルパス/ファイル名,ラベル
アップロードファイルの一覧はCloudShellから
gsutil ls gs://対象バケット/ディレクトリ/ > list.txt
などで出力してアップロードすればいいと思います。
アップロードは
gsutil cp list.txt gs://対象バケット/
AutoMLへのインポートにはそれなりに時間がかかるので注意です。
インポートが完了すると対応するラベルなどが表示されます。
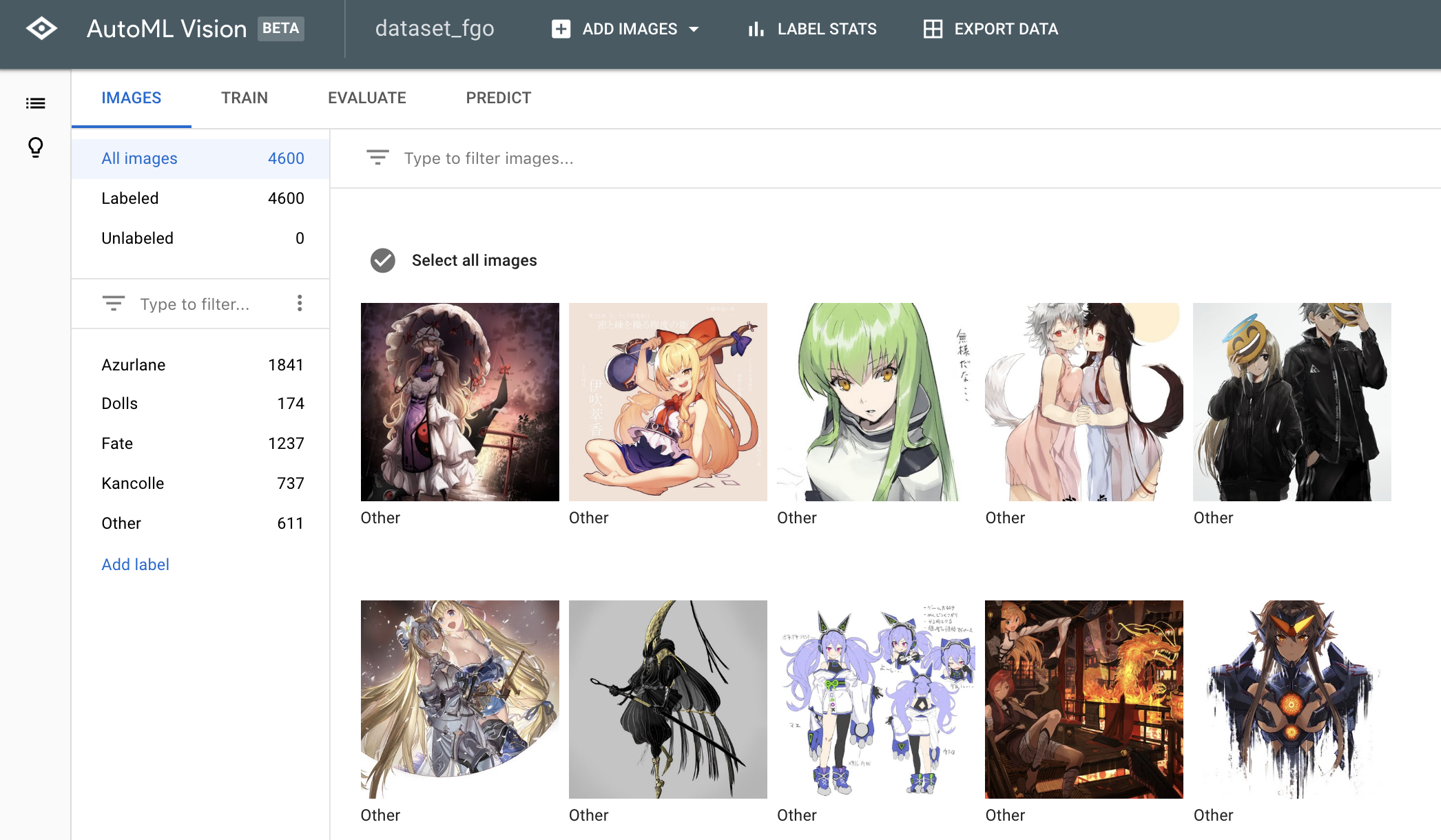
データセットの準備が終わったら、TRAINタブから TRAIN NEW MODELを押してモデルを作成します。
ちなみに10/月モデル、1時間のトレーニングであれば無料です。
継続して育てたり精度を求める場合は有料になります。
公式引用

https://cloud.google.com/vision/automl/pricing
モデルの作成結果とテスト
モデルを評価する各種指標がEVALUATEから確認できます。
作成したモデルでのテストはPREDICTから可能です。
評価について
作成したモデルの各種指標がここから確認できます。
画像のは最初に作ったモデルのものです。
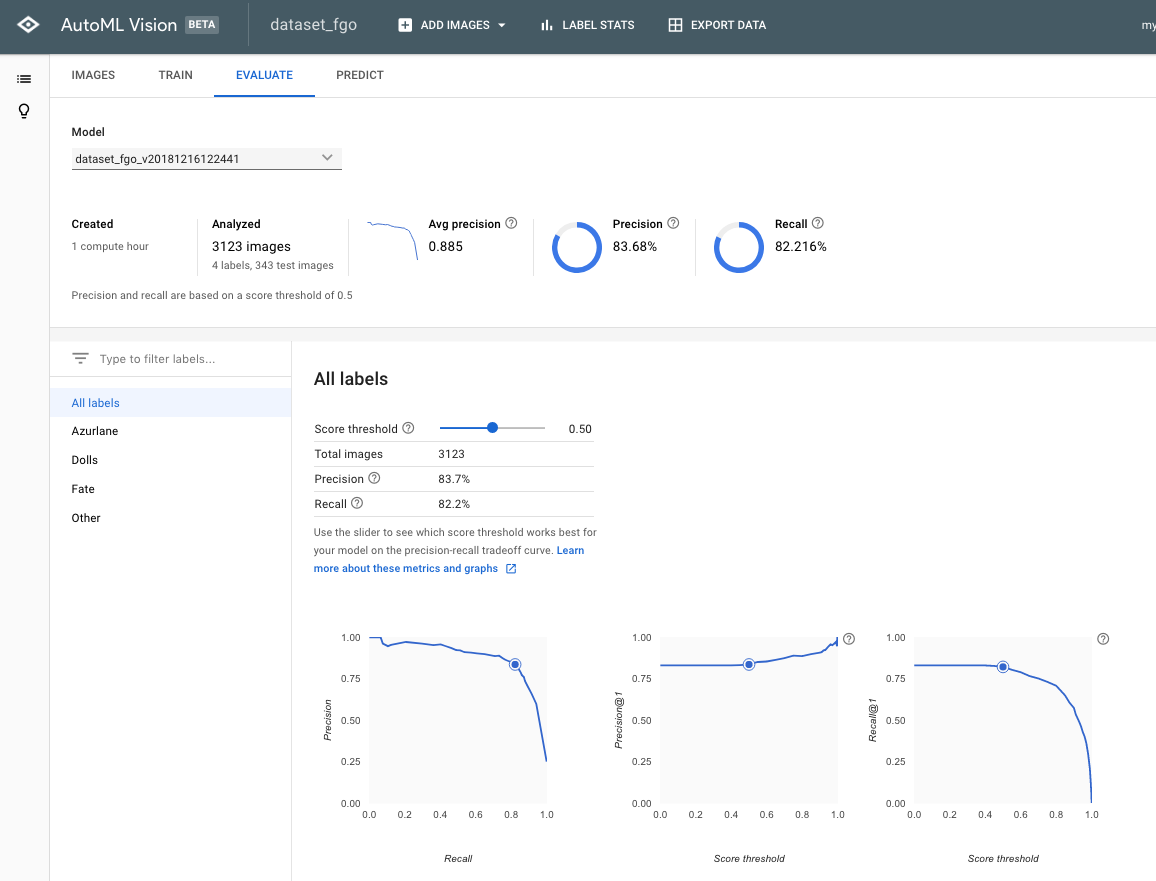
ざっくり指標の説明しますと(門外漢なので間違ってたらごめんなさい)
・Precision・・・正確さ、モデルが真としたときに、実際に真である割合
・Recall・・・網羅性、実際に真である集合からどれだけ真と識別できたか
単純にどっちも高ければ良いんですがトレードオフの関係にあります。
上にある画像のモデルは、両方とも8割を超えておりそれなりに有用そうに見えます。
(以前ガチでDeepLearningをやっている同僚に聞いたとき、8割はプレーンな状態で最低限らしいですが
また、各ラベルごとの精度についても確認が可能です。
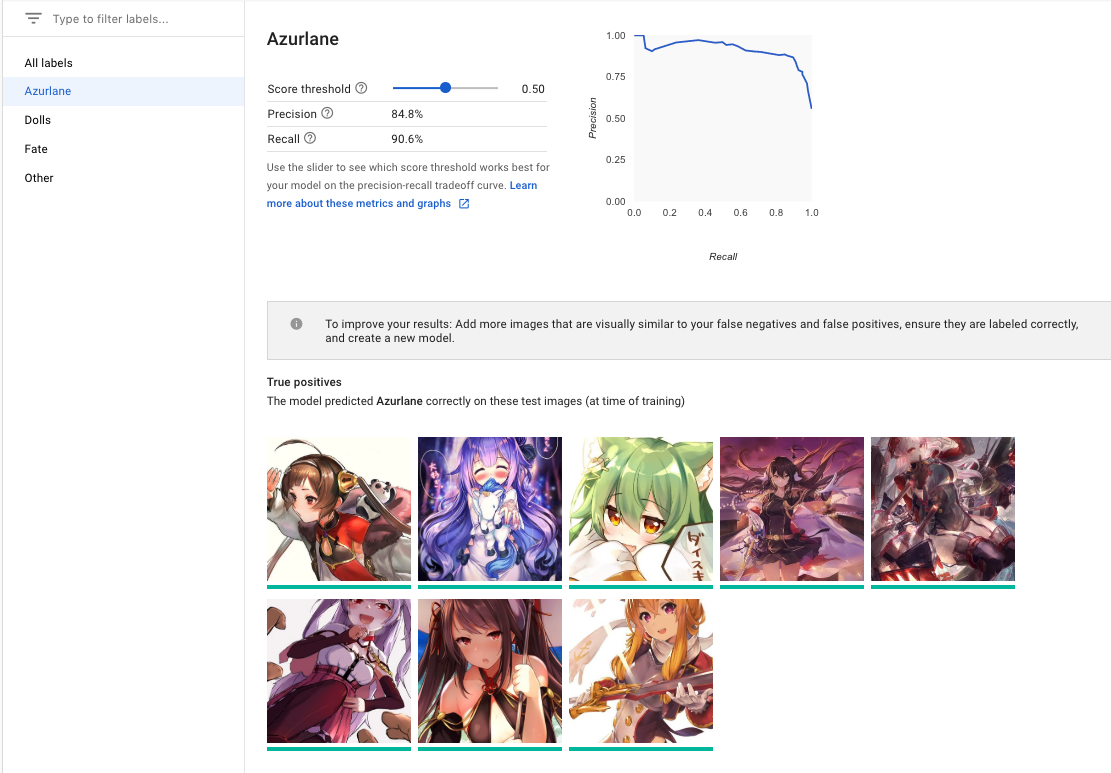
ラベルごとにテストデータを用いた際の結果が確認できます。
SSではTrue positiveの画像が出ていますが、false negative と false positive についても確認出来ます。
画像はFateラベルにおけるFalse Negativeとされたものです。

一枚目はおそらく巌窟王のネタ画像なのでさておき、2枚め3枚目辺りは結構特徴的なので違和感あります。
個別に確認してみたところ、どちらもAzurlaneのスコアが高くなっていたので、データセットの偏りが要因かもしれません。
false negative と false positive について
日本語だと偽陰性、偽陽性と呼ばれます。
false negativeは合っているのに間違っていると判断されたもの
false positiveは間違っているのに合っていると判断されたもの
かなりややこしいのですが、false negativeはAと判断されるべきものがAではない、違うとされてしまうもの。
画像はAzrulaneラベルにおいてスレッショルドは0.5としたときにfalse negativeと判断された画像です。
ようはAzrulaneなんだけどAzrulaneって判断されなかった、識別出来なかったというものになります。
ラベリングではそこまで気になりませんが、これが癌の診断など検知できない事によるリスクが大きくなる領域では重要な評価指標となります。

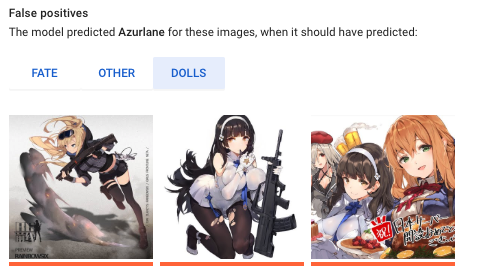
false positiveについては、AではないものがAと判断されたもの。
同じく下の画像はAzrulaneラベルにおけるfalse positiveとされたものになります。
本来ドルフロに分類される画像がAzrulaneと識別されていて、そのうえAzrulane単独0.9程度のスコアとなっていました。
(同じイラストレーターだし仕方ない感…)
実際にPredictしてみる
一部紹介済みですが他に試した画像についても掲載します。
最初に作ったモデルではOtherの画像数が少なかったため、Otherを増やしたモデルに付いても作成しています。
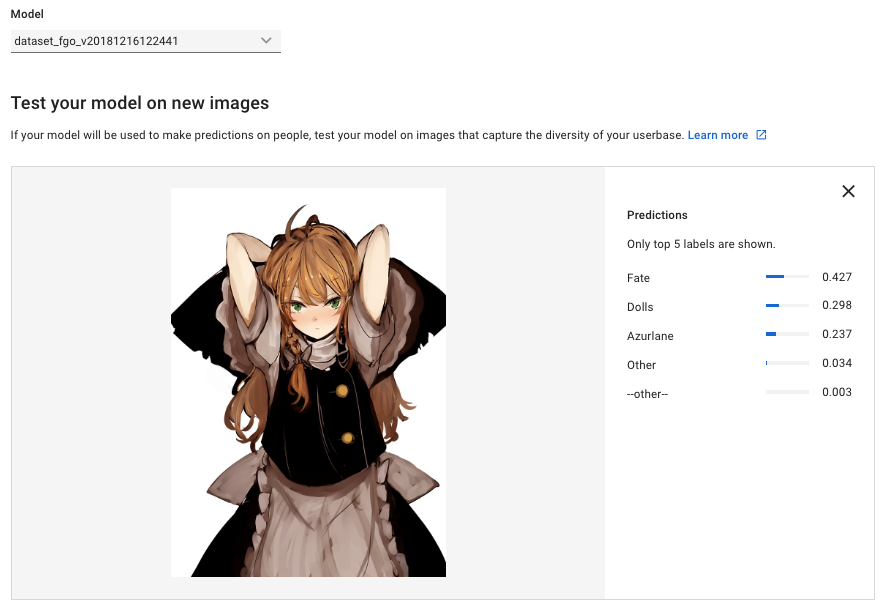
最初のモデルでの結果
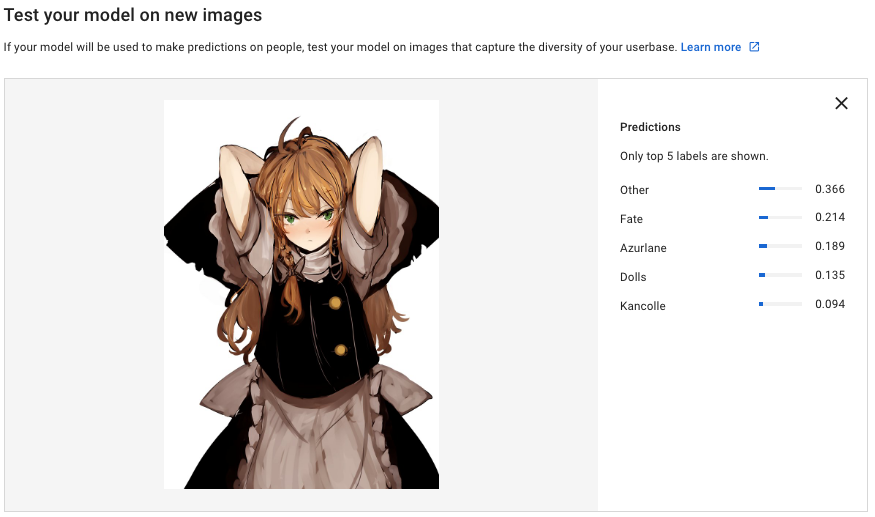
これはOtherを増量したモデルでの結果。スコアは低いもののOtherと正しく識別されている。
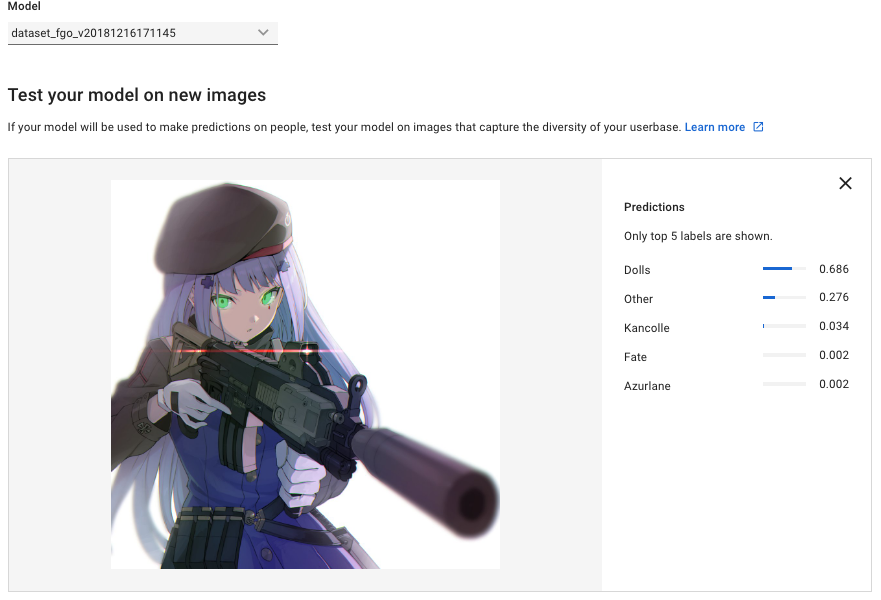
スコアの低さはデータセットが少ない事が原因か?
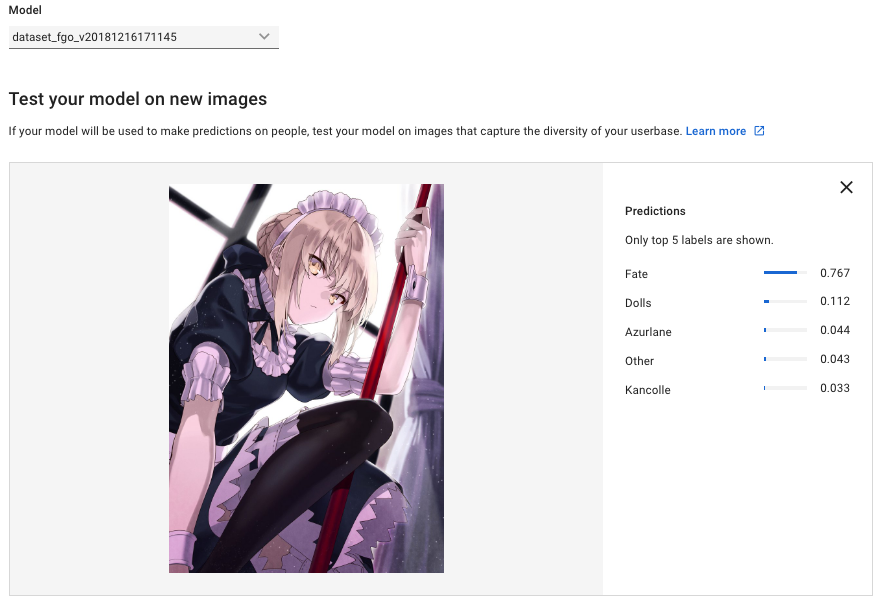
正解
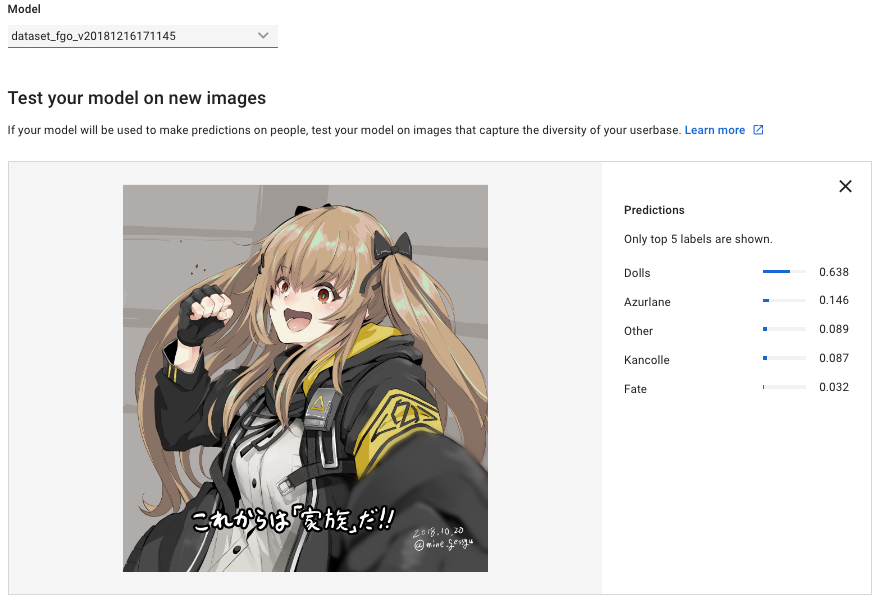
正解出来るんだ…
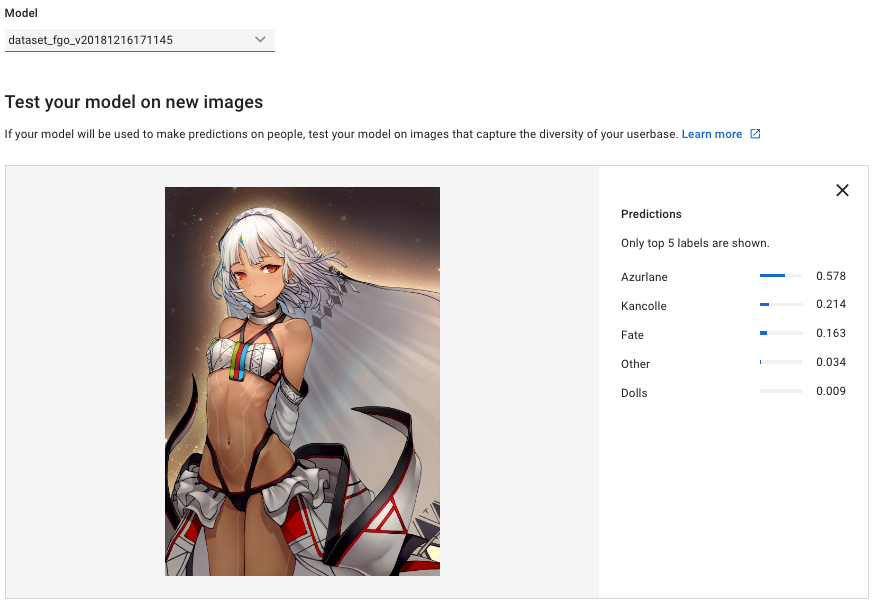
これは不正解。Fateスコア低い…
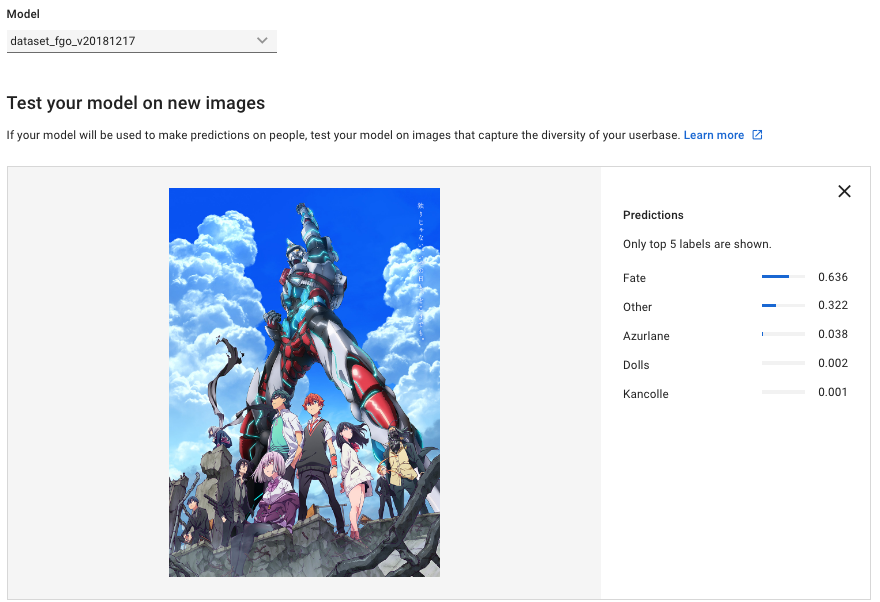
Fateではない…
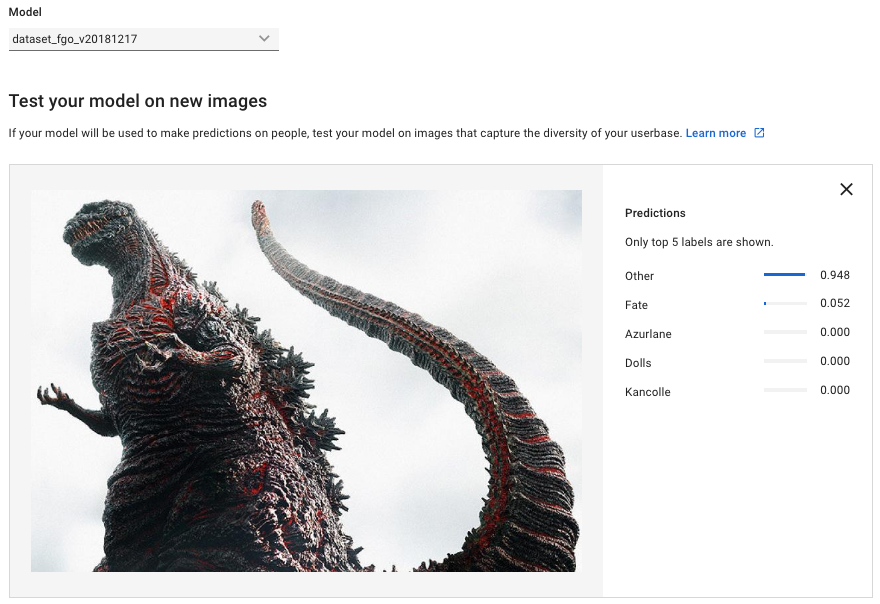
昨日やってたシン・ゴジラ。正しくOtherに分類
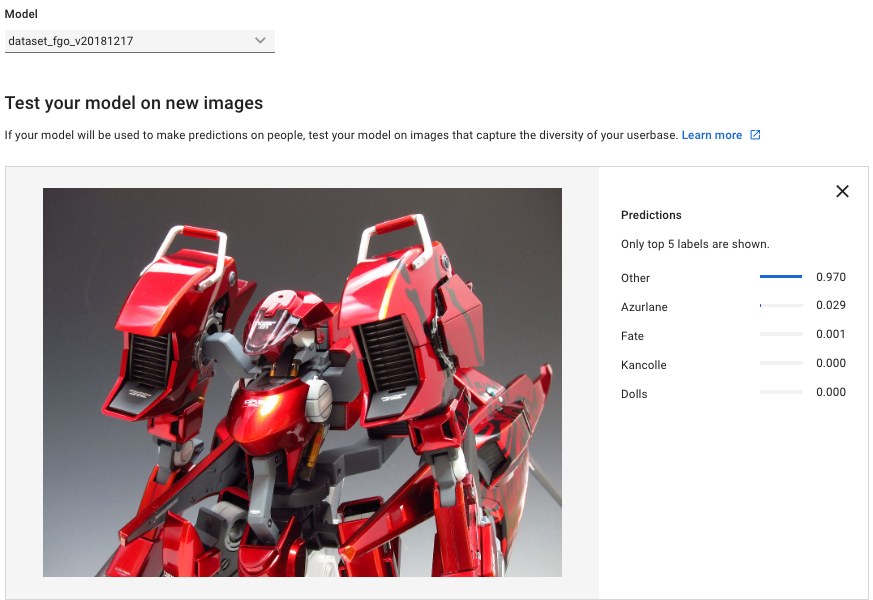
プラモの画像はOtherにしか居ないのでこのスコアと思われる
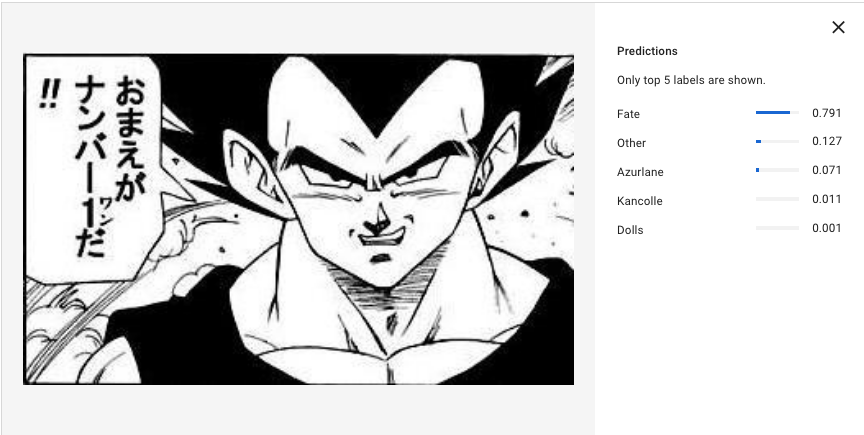
皇子は運命的な人生を送っているものの、FGOにサーヴァントとして実装されたりしない限りそれは無いんじゃ…
結果、精度について
最初のモデルについて
- Otherが少なかった
- 逆にFateやAzurlaneがかなり多め
- スレッショルド0.5のときのPrecisionは約84%、Recall 82%
- 精度・再現率あたりのスコアは悪くないが、Confusion matrixについて見てみると微妙である
- Other少なすぎて再現出来ない!再現できない精度100%とは
- おそらくデータセットに偏りがあるため、少ないものの判別?が出来ずに多いものに引きずられている

3つ目のモデルについて
- 2つ目については割愛
- Otherを600まで増やし、Kancolleを追加、多少バランスをとったもの
- ドルフロ画像については手元に殆どなかったのでそのまま
- スレッショルド0.5のときのPrecisionは約76%、Recall 61%
- 数値的にはだいぶ下がった
- Confusion matrix
- 分類については向上、とくに画像を増やしたOtherについては0から35%と大きく変化した
- スコアの低下は新しいLabelとデータセットを追加したことと思われ
- あとになって後悔
- 艦これとアズレンは自分でもどっちだか分からなくなる事があるので仕方がない感ある
- ドルフロも銃持ってないと誰だかわからないので(ry

- その他
- GCSにアップロードしたり面倒。もともとGoogleDriveに存在した画像だったため、GCSに移してインポートが
- データセットにある一部を使用せずにモデルの生成とか出来ないんだろうか?
- インポートに時間がかかり、ラベリングもしている関係でもったいないから消したくない…
- エクスポートして退避すればOK?
- インポートに時間がかかり、ラベリングもしている関係でもったいないから消したくない…
結論など
とにかくお題が悪かった…
今回複数のラベルを用意しましたが、それぞれの画像はかなりまちまちだったため、精度にばらつきが出たような気がします。
また、私の用意したデータセットは基本的にTwitterから集めた画像で、多くはイラストレーションですが中にはプラモデルだったりネタ画像だったりスクリーンショットだったりと、統一感のないものばかりだったのも要因かなと思います。
(2次画像といっても中には漫画だったりしますし、それでも一部は識別されていたのは驚きました。
どちらもなんで合ってるか分からないけど正解しているパターン
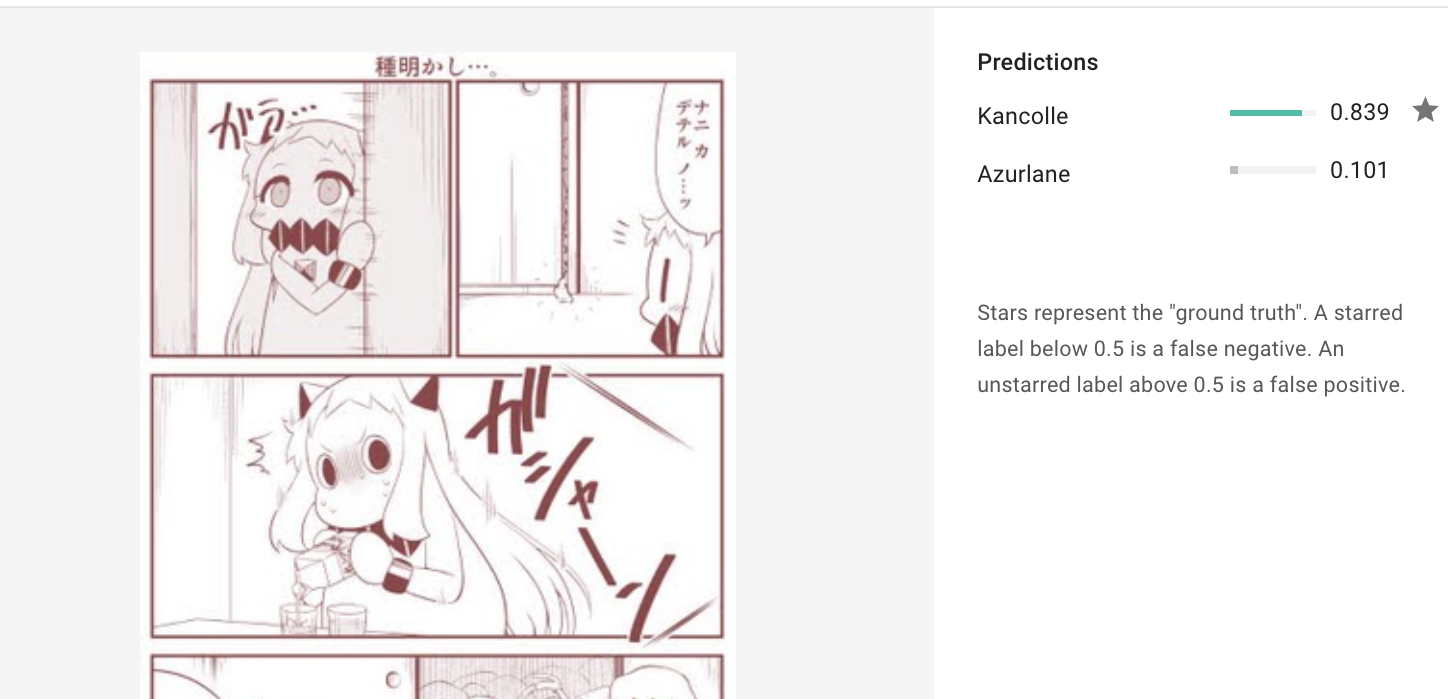

あとこれは後から気づいたことですが、公式にもデータセットについての解説がありまして…
 この辺りに気をつけてノイズ除去したものでモデルの作り直しが必要かなと思う次第です。
(全体で4k枚超えてるので非常に手間ですが…
この辺りに気をつけてノイズ除去したものでモデルの作り直しが必要かなと思う次第です。
(全体で4k枚超えてるので非常に手間ですが…
精度的には不十分な点もありますが、データセットの問題もあるので悪くはないですね。自前でモデル用意できるマシンもないですし。
そもそも検査など厳密性が求められるタスクではないですし、スコアが一定超えなければ採用しない運用にすればいいので全然ありな気がします。
とりあえず、ラベリング程度ならCloud Vision APIで十分ですね。
Webコンテンツサーチ?ではかなりの精度が期待できます。
GASでTwitterハッシュタグからの収集で問題となったSSの排除など十分に機能しそうです。
SSからの文字識別は流石に無理でしたが


参考
- OHP Cloud AutoML Vision ドキュメント
- Cloud AutoML Vision が本当にノンプログラミングで使えるのか試してみた
- AutoML Visionをためしてみた
指標について
- いまさら聞けない機械学習の評価関数