はじめに
割と素人寄りの人が調べて書いてるので、正しくない情報もあるかもですm(__)m
前回の記事では、Proxmoxクラスタを支える「クォーラム(多数決)」や、Corosyncの厳格なタイムアウト設定について解説しました。「ノードが死んだと判断される仕組み」や「フェンシングが発動するまでの時間」といった、クラスタの外側から見た挙動の話でしたね。
今回は、その続編として、Proxmoxクラスタの内側に踏み込みます。
Proxmox VE のクラスタ機能は非常に強力ですが、その中身が具体的にどう動いているのか、ブラックボックスに感じている方も多いのではないでしょうか。
今回もっと勉強する機会があったので、この記事ではProxmoxの心臓部である Corosync と pmxcfs の内部実装に踏み込み、データがどのように同期され、整合性が保たれているのかを解説します。特に、ソースコード(totem, cpg, pmxcfs)のロジックに基づき、「いつ、どこで、何が」起きているのかを明らかにします。
1. アーキテクチャ概観:2つの主要コンポーネント
Proxmoxクラスタの動作は、大きく2つのレイヤーの協調によって成り立っています。
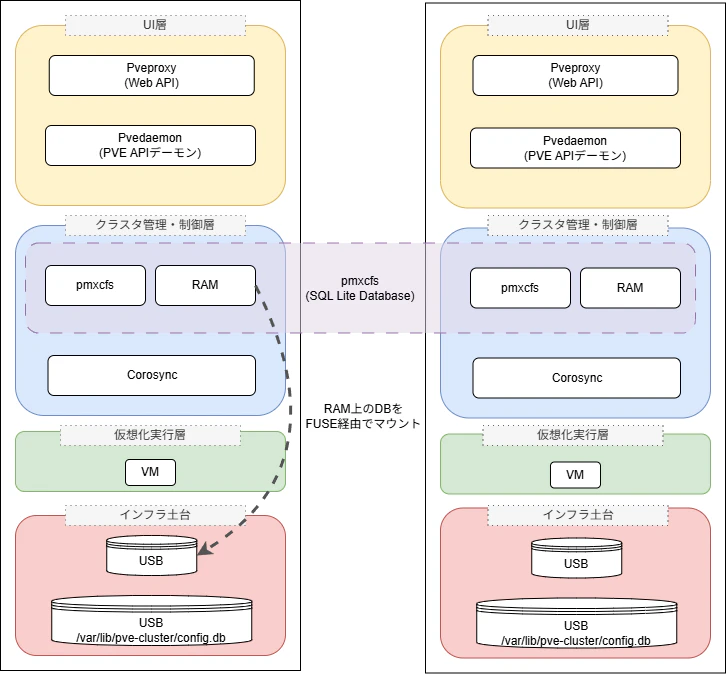
Corosync (Totemプロトコル)
役割: クラスタメンバーシップの管理、メッセージの順序保証
機能: 全ノードが同じ順番でメッセージを受け取る「仮想同期 (Virtual Synchrony)」を提供します。前回の記事で解説したトークン・パッシングの仕組みにより、クラスタ全体で一貫した順序でのメッセージ配信を実現しています。
pmxcfs (Proxmox Cluster File System)
役割: 設定ファイル (/etc/pve) の実体を管理する分散ファイルシステム
実体: 各ノードのメモリ上で動作する SQLiteデータベース です。FUSEを使ってファイルシステムに見せかけています。
2. Corosync/Totemプロトコルの詳細
Corosyncの核心は Totem シングルリングプロトコル です。これは、物理的な配線に関わらず、論理的な「リング」を構成し、トークンを巡回させることで通信を制御します。
2.1 トークン・パッシング (Token Passing)
前回の記事でも触れましたが、リング上を 「トークン (Token)」 という特殊なパケットが高速で巡回しています。
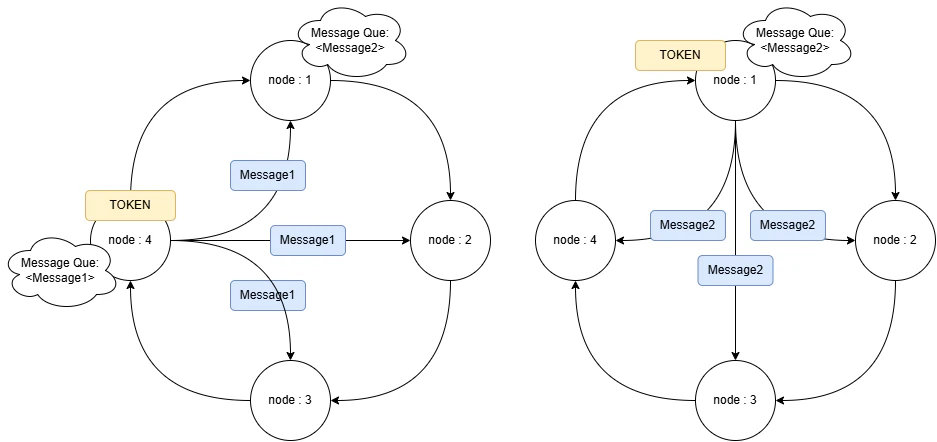
送信権の独占
トークンを持っているノードだけが、メッセージ(マルチキャスト)を送信できます。これにより、同時に複数のノードが書き込んでデータが競合することを防ぎます(シリアライズ)。
ARU (All Received Up to)
トークンには aru というシーケンス番号が含まれています。これは「リング内の全員が、ここまで受信しました」という確認印です。
トークンが一周して戻ってきた時、この aru が更新されていることで、送信者は「全員に届いた」と確信できます。
2.2 通信フロー(ソースコードレベル)
exec/totemsrp.c の実装に基づくと、トークン受信時の処理は以下のようになります。
- トークン受信: 前のノードからトークンを受け取る
- 再送制御: 自分が取りこぼしたメッセージがあれば、再送要求 (Retransmit Request) を出す
- マルチキャスト送信: 送信待ちキューにあるメッセージ(pmxcfsからのデータなど)をネットワークに送出する
- トークン更新: 送信した分だけシーケンス番号を進め、トークンを次のノードへ渡す
3. pmxcfsによるデータ同期:書き込みの旅
では、ユーザーが「VMの設定を変更」した時、データは具体的にどう流れるのでしょうか?ここがProxmoxの整合性を担保する最重要ポイントです。
Step 1: アプリケーションからの書き込み要求
pvedaemon などのプロセスが /etc/pve/qemu-server/100.conf に書き込みを行います。これはFUSE経由で pmxcfs プロセスにフックされます。
Step 2: CPGによる配信 (Corosync)
pmxcfs は、変更内容をトランザクションとしてまとめ、Corosyncの CPG (Closed Process Group) APIを通じて全ノードへ送信依頼を出します。
このデータはCorosyncの送信バッファに入り、トークンが回ってくるのを待ちます。
Step 3: 受信と「即時永続化」 (重要)
ここが最もクリティカルな部分です。データを受信した全ノード(送信元含む)の pmxcfs は、以下の処理を行います。
メモリ更新
受信したデータを自身のインメモリSQLite DBに適用します。
永続化 (fsync)
pmxcfs はデータの消失を防ぐため、即座にバックエンドのSQLiteファイル(物理ディスク上)へ書き込みを行います。
この際、fsync() システムコールを発行し、「物理ディスクへの書き込みが完了するまで処理をブロック」します。
Step 4: コミット完了
全員の fsync() が完了し、トークンが一周してARUが更新されると、そのトランザクションはクラスタ全体で「コミット済み」となり、整合性が保証されます。
4. I/O性能とクラスタ安定性の関係
この仕組みからわかる通り、Proxmoxクラスタは「全員がディスクに書き終わるのを待つ」という挙動を基本としています。
なぜI/O遅延が問題になるのか
もし1台でもディスク書き込み(fsync)が遅いノードがいると、そのノードで処理がブロックされます。
ブロックされている間、Corosyncなどの通信プロセスも巻き添えで停止することがあります。
結果として、トークンの巡回が遅延し、最悪の場合は前回の記事で解説したタイムアウト(ノードダウン判定)につながります。
自宅ラボでの注意点
特に自宅サーバー(Homelab)環境では要注意!
- 安価なUSBストレージをシステムディスクに使っている
- 古いHDDを使用している
- ネットワークストレージ経由でシステムが動作している
こうした環境では、fsync のレイテンシが大きくなりがちです。VMやコンテナのストレージは多少遅くても問題ありませんが、Proxmox本体のシステムディスクは、できるだけ高速なSSDを使うことを強くお勧めします。
可能であれば、PLP(Power Loss Protection)付きのSSDや、エンタープライズグレードのSSDを選定すると、より安定したクラスタ運用が可能になります。
まとめ
この記事では、Proxmoxクラスタの内部構造を深掘りしました。
要点のおさらい
- Corosync/Totem: トークン・パッシングにより、メッセージの順序保証とメンバーシップ管理を実現
- ARU(All Received Up to): 全ノードがメッセージを受信したことを確認する仕組み
- pmxcfs: メモリ上のSQLiteデータベースをFUSE経由でファイルシステムとして提供
-
即時永続化: 全ノードが
fsync()でディスクに書き込むまでトランザクションが完了しない - I/O性能の重要性: システムディスクのI/O遅延がクラスタ全体の安定性に直結する
実践的なアドバイス
本番環境では、CPUやメモリだけでなく、「同期書き込み(fsync)のレイテンシ」が低いストレージを選定することが、アーキテクチャ上極めて重要です。
※標準搭載のコマンド「pveperf」というベンチマークツールで自分のマシンが1秒間で何回fsyncできるかを測れます!自分で測った感じだとUSBが30~50くらいで、SSDで3千以上でしたので百倍近く違いますね。。。
自宅ラボでも、システムディスクだけは高速なSSDを使うことで、より安定したProxmoxクラスタを構築できます。
前回の記事で解説したタイムアウト設定と合わせて、この内部構造を理解することで、より堅牢なクラスタ運用が可能になります。
参考資料
-
The Totem Single-Ring Ordering and Membership Protocol
https://corosync.github.io/corosync/doc/tocssrp95.pdf -
Corosync Source Code (exec/totemsrp.c, lib/cpg.c)
https://github.com/corosync/corosync -
Proxmox VE 公式ドキュメント - Cluster Network
https://pve.proxmox.com/pve-docs/pve-admin-guide.html#pvecm_cluster_network