はじめに
MLOpsという、「機械学習モデルが陳腐化してシステムがゴミにならないように、ちゃんと機械学習の技術が含まれたシステムを運用するための基盤をつくりましょうね」というような話がある。
参考記事:小さく始めて大きく育てるMLOps2020
その助けになるように作られたツールとしてMLFlowというものがある。
MLflowの一つの機能、MLflow Trackingを使う機会があったので、いろいろ調べながら使ってみたらこれは良いものだなぁ、と思ったのでここに記す。まあ使い方自体は他にたくさん記事があるのでそれを見ていただくとして、「こういう感じでモデル作成の記録を残していくのはどうよ?」とモデル構築のログの残し方のアイデアの種にでもなればハッピー。MLflowはバージョン1.8.0を使った。
MLflowについては以下の記事がわかりやすい。
mlflowを使ってデータ分析サイクルの効率化する方法を考える
MLflow 1.0.0 リリース!機械学習ライフサイクルを始めよう!
使用データ
KaggleのTelco Customer Churnのデータを使用する。
https://www.kaggle.com/blastchar/telco-customer-churn
これは電話会社の顧客に関するデータであり、解約するか否かを目的変数とした2値分類問題。
各行は顧客を表し、各列には顧客の属性が含まれている。
使うパッケージと関数の定義
集計結果を可視化する関数や、モデルを作る関数などを作成。
本題ではないので説明は省略。
使用パッケージ
# package
import numpy as np
import scipy
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import seaborn as sns
import pandas as pd
from pandas.plotting import register_matplotlib_converters
import xgboost
import xgboost.sklearn as xgb
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.metrics import auc
from sklearn.metrics import roc_curve
from sklearn.metrics import log_loss
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_validate
from sklearn.cluster import KMeans
from sklearn.metrics import confusion_matrix
from sklearn.metrics import make_scorer
from sklearn.metrics import precision_recall_curve
import time
import os
import glob
from tqdm import tqdm
import copy
import mlflow
from mlflow.sklearn import log_model
from mlflow.sklearn import load_model
定義した関数群
# ヒストグラム作成
def plot_many_hist(df_qiita,ex_col,ob_col,clip=[0, 99.],defalt_bin=10,png='tmp.png', visual = True):
fig=plt.figure(figsize=(15,10))
for i in range(len(ex_col)):
df_qiita_clip=df_qiita.copy()
col=ex_col[i]
# クリッピング
upperbound, lowerbound = np.percentile(df_qiita[col].values, clip)
col_clip = np.clip(df_qiita[col].values, upperbound, lowerbound)
df_qiita_clip['col_clip']=col_clip
# ビンの数調整
if len(df_qiita_clip['col_clip'].unique())<10:
bins=len(df_qiita_clip['col_clip'].unique())
else:
bins=defalt_bin
# ヒストグラムプロット
ax=plt.subplot(3,3,i+1)
for u in range(len(df_qiita_clip[ob_col].unique())):
ln1=ax.hist(df_qiita_clip[df_qiita_clip[ob_col]==u]['col_clip'], bins=bins,label=u, alpha=0.7)
ax.set_title(col)
h1, l1 = ax.get_legend_handles_labels()
ax.legend(loc='upper right')
ax.grid(True)
plt.tight_layout()
fig.suptitle("hist", fontsize=15)
plt.subplots_adjust(top=0.92)
plt.savefig(png)
if visual == True:
print('Cluster Hist')
plt.show()
else:
plt.close()
# 標準化
def sc_trans(X):
ss = StandardScaler()
X_sc = ss.fit_transform(X)
return X_sc
# kmeansモデル作成
def km_cluster(X, k):
km=KMeans(n_clusters=k,\
init="k-means++",\
random_state=0)
y_km=km.fit_predict(X)
return y_km,km
# 円グラフ作成
def pct_abs(pct, raw_data):
absolute = int(np.sum(raw_data)*(pct/100.))
return '{:d}\n({:.0f}%)'.format(absolute, pct) if pct > 5 else ''
def plot_chart(y_km, png='tmp.png', visual = True):
km_label=pd.DataFrame(y_km).rename(columns={0:'cluster'})
km_label['val']=1
km_label=km_label.groupby('cluster')[['val']].count().reset_index()
fig=plt.figure(figsize=(5,5))
ax=plt.subplot(1,1,1)
ax.pie(km_label['val'],labels=km_label['cluster'], autopct=lambda p: pct_abs(p, km_label['val']))#, autopct="%1.1f%%")
ax.axis('equal')
ax.set_title('Cluster Chart (ALL UU:{})'.format(km_label['val'].sum()),fontsize=14)
plt.savefig(png)
if visual == True:
print('Cluster Structure')
plt.show()
else:
plt.close()
# 表作成
def plot_table(df_qiita, cluster_name, png='tmp.png', visual = True):
fig, ax = plt.subplots(figsize=(10,10))
ax.axis('off')
ax.axis('tight')
tab=ax.table(cellText=np.round(df_qiita.groupby(cluster_name).mean().reset_index().values, 2),\
colLabels=df_qiita.groupby(cluster_name).mean().reset_index().columns,\
loc='center',\
bbox=[0,0,1,1])
tab.auto_set_font_size(False)
tab.set_fontsize(12)
tab.scale(5,5)
plt.savefig(png)
if visual == True:
print('Cluster Stats Mean')
plt.show()
else:
plt.close()
# XGBモデル作成
def xgb_model(X_train, y_train, X_test):
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
y_pred=model.predict(X_test)
y_pred_proba=model.predict_proba(X_test)[:, 1]
y_pred_proba_both=model.predict_proba(X_test)
return model, y_pred, y_pred_proba, y_pred_proba_both
# 学習データとテストデータ作成
def createXy(df, exp_col, ob_col, test_size=0.3, random_state=0, stratify=True):
dfx=df[exp_col].copy()
dfy=df[ob_col].copy()
print('exp_col:',dfx.columns.values)
print('ob_col:',ob_col)
if stratify == True:
X_train, X_test, y_train, y_test = train_test_split(dfx, dfy, test_size=test_size, random_state=random_state, stratify=dfy)
else:
X_train, X_test, y_train, y_test = train_test_split(dfx, dfy, test_size=test_size, random_state=random_state)
print('Original Size is {}'.format(dfx.shape))
print('TrainX Size is {}'.format(X_train.shape))
print('TestX Size is {}'.format(X_test.shape))
print('TrainY Size is {}'.format(y_train.shape))
print('TestY Size is {}'.format(y_test.shape))
return X_train, y_train, X_test, y_test
# 分類評価指標の結果返す
def eval_list(y_test, y_pred, y_pred_proba, y_pred_proba_both):
# eval
log_loss_=log_loss(y_test, y_pred_proba_both)
accuracy=accuracy_score(y_test, y_pred)
precision=precision_score(y_test, y_pred)
recall=recall_score(y_test, y_pred)
# FPR, TPR, thresholds
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
# AUC
auc_ = auc(fpr, tpr)
# roc_curve
fig, ax = plt.subplots(figsize=(10,10))
ax.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %.2f)'%auc_)
ax.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.legend()
plt.title('ROC curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.grid(True)
plt.savefig('ROC_curve.png')
plt.close()
return log_loss_, accuracy, precision, recall, auc_
# Recall-Precision曲線返す
def threshold_pre_rec(test, prediction, save_name='threshold_pre_rec.png'):
precision, recall, threshold = precision_recall_curve(test, prediction)
thresholds = threshold
user_cnt=[prediction[prediction>=i].shape[0] for i in thresholds]
fig=plt.figure(figsize=(10,6))
ax1 = plt.subplot(1,1,1)
ax2=ax1.twinx()
ax1.plot(thresholds, precision[:-1], color=sns.color_palette()[0],marker='+', label="precision")
ax1.plot(thresholds, recall[:-1], color=sns.color_palette()[2],marker='+', label="recall")
ax2.plot(thresholds, user_cnt, linestyle='dashed', color=sns.color_palette()[6], label="user_cnt")
handler1, label1 = ax1.get_legend_handles_labels()
handler2, label2 = ax2.get_legend_handles_labels()
ax1.legend(handler1 + handler2, label1 + label2, loc='lower left')
ax1.set_xlim(-0.05,1.05)
ax1.set_ylim(-0.05,1.05)
ax1.set_xlabel('threshold')
ax1.set_ylabel('%')
ax2.set_ylabel('user_cnt')
ax2.grid(False)
plt.savefig(save_name)
plt.close()
# 予測確率-実測確率曲線を返す
def calib_curve(y_tests, y_pred_probas, save_name='calib_curve.png'):
y_pred_proba_all=y_pred_probas.copy()
y_tests_all=y_tests.copy()
proba_check=pd.DataFrame(y_tests_all.values,columns=['real'])
proba_check['pred']=y_pred_proba_all
s_cut, bins = pd.cut(proba_check['pred'], list(np.linspace(0,1,11)), right=False, retbins=True)
labels=bins[:-1]
s_cut = pd.cut(proba_check['pred'], list(np.linspace(0,1,11)), right=False, labels=labels)
proba_check['period']=s_cut.values
proba_check = pd.merge(proba_check.groupby(['period'])[['real']].mean().reset_index().rename(columns={'real':'real_ratio'})\
, proba_check.groupby(['period'])[['real']].count().reset_index().rename(columns={'real':'UU'})\
, on=['period'], how='left')
proba_check['period']=proba_check['period'].astype(str)
proba_check['period']=proba_check['period'].astype(float)
fig=plt.figure(figsize=(10,6))
ax1 = plt.subplot(1,1,1)
ax2=ax1.twinx()
ax2.bar(proba_check['period'].values, proba_check['UU'].values, color='gray', label="user_cnt", width=0.05, alpha=0.5)
ax1.plot(proba_check['period'].values, proba_check['real_ratio'].values, color=sns.color_palette()[0],marker='+', label="real_ratio")
ax1.plot(proba_check['period'].values, proba_check['period'].values, color=sns.color_palette()[2], label="ideal_line")
handler1, label1 = ax1.get_legend_handles_labels()
handler2, label2 = ax2.get_legend_handles_labels()
ax1.legend(handler1 + handler2, label1 + label2, loc='center right')
ax1.set_xlim(-0.05,1.05)
ax1.set_ylim(-0.05,1.05)
ax1.set_xlabel('period')
ax1.set_ylabel('real_ratio %')
ax2.set_ylabel('user_cnt')
ax2.grid(False)
plt.savefig(save_name)
plt.close()
# 混合行列を出力
def print_cmx(y_true, y_pred, save_name='tmp.png'):
labels = sorted(list(set(y_true)))
cmx_data = confusion_matrix(y_true, y_pred, labels=labels)
df_cmx = pd.DataFrame(cmx_data, index=labels, columns=labels)
plt.figure(figsize = (10,6))
sns.heatmap(df_cmx, annot=True, fmt='d', cmap='coolwarm', annot_kws={'fontsize':20},alpha=0.8)
plt.xlabel('pred', fontsize=18)
plt.ylabel('real', fontsize=18)
plt.savefig(save_name)
plt.close()
データの読み込み
本題ではないので、欠損行はそのまま削除。
# データ読み込み
df=pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv')
churn=df.copy()
# 半角空白をNanに変更
churn.loc[churn['TotalCharges']==' ', 'TotalCharges']=np.nan
# floatに変更
churn['TotalCharges']=churn['TotalCharges'].astype(float)
# 面倒なので欠損行がある場合、その行は削除する
churn=churn.dropna()
print(churn.info())
display(churn.head())
MLflowでクラスタリング結果を記録
kmenasなどでクラスタリングした後は、クラスタごとの特徴を見て、人間がクラスタリング結果の解釈を行う。しかし試行錯誤していく中で毎回可視化したり表を作ったりしてクラスタの特徴を見るのは面倒だし、前の結果がどんなものだったのか忘れてしまうかもしれない。この問題を解決するためにMLflowを活用できる。説明変数を連続値の'tenure', 'MonthlyCharges', 'TotalCharges'に絞ってクラスタリングを実施して、その結果をMLflowに記録する。
#### クラスタリング実施
exp_col=['tenure','MonthlyCharges','TotalCharges']
df_km=churn.copy()[exp_col]
df_cluster=df_km.copy()
cluster_name = 'My_Cluster'
k=5
ob_col = cluster_name
# クラスタリング結果をmlflowに記録
mlflow.set_experiment('My Clustering')# 実験の名前を定義
with mlflow.start_run():# mlflow記録開始
# 標準化
X=sc_trans(df_cluster)
# kmeansモデル作成
y_km, km=km_cluster(X, k)
# paramsをmlflowに記録
mlflow.log_param("method_name",km.__class__.__name__)
mlflow.log_param("k", k)
mlflow.log_param("features", df_cluster.columns.values)
# modelをmlflowに保存
log_model(km, "model")
df_cluster[cluster_name]=y_km
# クラスタリング結果を可視化
# クラスタ構成比
plot_chart(y_km, png='Cluster_Chart.png', visual = False)# カレントディレクトリに図を保存
mlflow.log_artifact('Cluster_Chart.png')# カレントディレクトリにある図を記録
os.remove('Cluster_Chart.png')# 記録した後にカレントディレクトリの図は削除した
# クラスタごとの平均値
plot_table(df_cluster, ob_col, png='Cluster_Stats_Mean.png', visual = False)# カレントディレクトリに図を保存
mlflow.log_artifact('Cluster_Stats_Mean.png')# カレントディレクトリにある図を記録
os.remove('Cluster_Stats_Mean.png')# 記録した後にカレントディレクトリの図は削除した
# クラスタごとのヒストグラム
plot_many_hist(df_cluster,exp_col,ob_col,clip=[0, 99.],defalt_bin=20, png='Cluster_Hist.png', visual = False)# カレントディレクトリに図を保存
mlflow.log_artifact('Cluster_Hist.png')# カレントディレクトリにある図を記録
os.remove('Cluster_Hist.png')# 記録した後にカレントディレクトリの図は削除した
上記のように、アルゴリズム名や、説明変数名、ハイパラの値、クラスタごとの特徴を可視化した図表を記録するように記述したコードを実行すると、カレントディレクトリに"mlruns"というフォルダが作成される。記録した結果はすべてこの"mlruns"というフォルダに保存されている。
"mlruns"フォルダがあるディレクトリでターミナルを開き"mlflow ui"と記述して実行すると、localhostの5000番が立ち上がる。ブラウザでlocalhostの5000番にアクセスすると、MLflowのリッチなUIを通して作ったモデルの記録を確認できる。
"mlruns"フォルダ

"mlruns"というフォルダがあるディレクトリで"mlflow ui"と記述
mlflow uiトップ画面
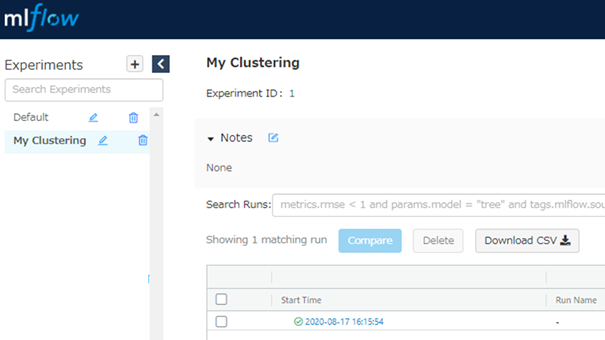
My Clusteringという名前の部屋にクラスタリング結果は記録されている。記録した内容を見るため、記録日時が書かれたリンクの中を確認してみる。
Parameters, Metrics

Artifacts

Artifacts

Artifacts
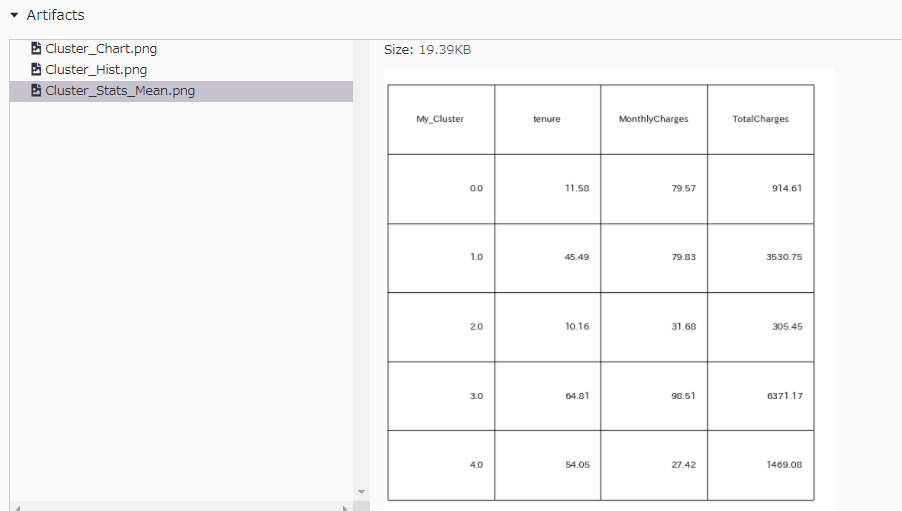
記録するように設定したアルゴリズム名や、説明変数名、ハイパラの値はParametersに記録されていることが確認できる。また図表などはArtifactsに記録されている。
このように記録していくと、説明変数を変えたり、kの値を変えたりした時も、以前のモデルの結果と比較することが容易くなる。
予測結果をMLflowに記録
分類モデルを作るときも同様に記録できる。
#### 予測モデルを構築
exp_col=['tenure','MonthlyCharges','TotalCharges']
ob_col = 'Churn'
df_pred=churn.copy()
df_pred.loc[df_pred[ob_col]=='Yes', ob_col]=1
df_pred.loc[df_pred[ob_col]=='No', ob_col]=0
df_pred[ob_col]=df_pred[ob_col].astype(int)
df_pred[cluster_name]=y_km
X_tests, y_tests, y_preds, y_pred_probas, y_pred_proba_boths = [],[],[],[],[]
for cluster_num in np.sort(df_pred[cluster_name].unique()):
# 1つのクラスタのデータを抽出
df_n=df_pred[df_pred[cluster_name]==cluster_num].copy()
# 学習データとテストデータ作成
X_train, y_train, X_test, y_test=createXy(df_n, exp_col, ob_col, test_size=0.3, random_state=0, stratify=True)
# モデル作成
model, y_pred, y_pred_proba, y_pred_proba_both = xgb_model(X_train, y_train, X_test)
# 評価指標計算
log_loss_, accuracy, precision, recall, auc_ = eval_list(y_test, y_pred, y_pred_proba, y_pred_proba_both)
# データを空のリストに挿入
X_tests.append(X_test)
y_tests.append(y_test)
y_preds.append(y_pred)
y_pred_probas.append(y_pred_proba)
y_pred_proba_boths.append(y_pred_proba_both)
# 混合行列
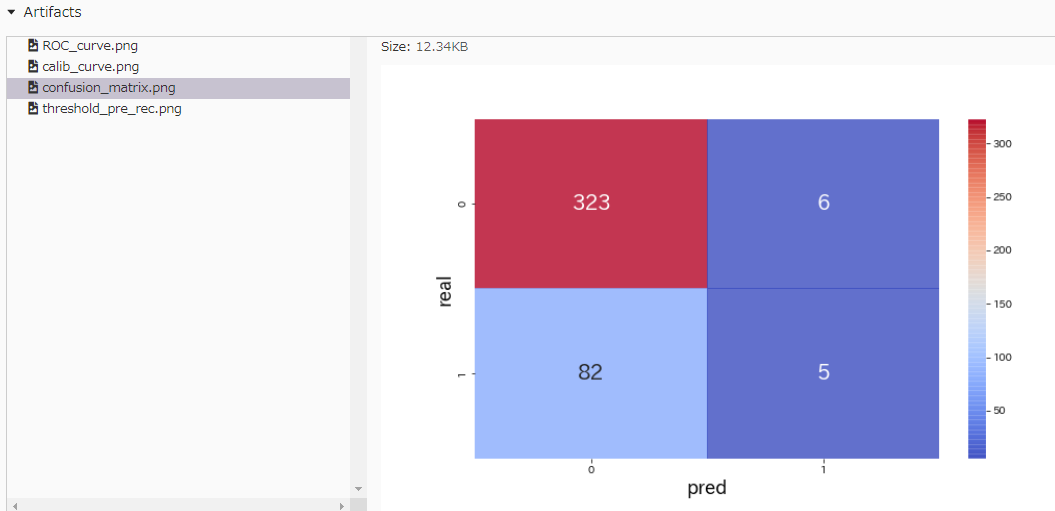
print_cmx(y_test.values, y_pred, save_name='confusion_matrix.png')
# Recall-Precision曲線
threshold_pre_rec(y_test, y_pred_proba, save_name='threshold_pre_rec.png')
# Pred Prob曲線
calib_curve(y_test,y_pred_proba, save_name='calib_curve.png')
# 予測結果をmlflowに記録
mlflow.set_experiment('xgb_predict_cluster'+str(cluster_num))# 実験の名前を定義
with mlflow.start_run():# mlflow記録開始
mlflow.log_param("01_method_name", model.__class__.__name__)
mlflow.log_param("02_features", exp_col)
mlflow.log_param("03_objective_col", ob_col)
mlflow.log_params(model.get_xgb_params())
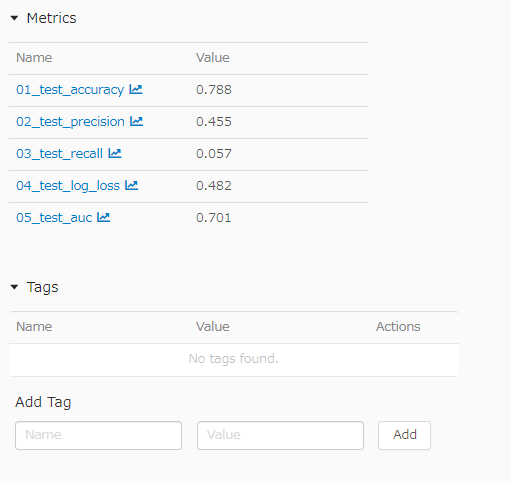
mlflow.log_metrics({"01_accuracy": accuracy})
mlflow.log_metrics({"02_precision": precision})
mlflow.log_metrics({"03_recall": recall})
mlflow.log_metrics({"04_log_loss": log_loss_})
mlflow.log_metrics({"05_auc": auc_})
mlflow.log_artifact('ROC_curve.png')
os.remove('ROC_curve.png')
mlflow.log_artifact('confusion_matrix.png')
os.remove('confusion_matrix.png')
mlflow.log_artifact('threshold_pre_rec.png')
os.remove('threshold_pre_rec.png')
mlflow.log_artifact('calib_curve.png')
os.remove('calib_curve.png')
log_model(model, "model")
# クラスタごとのデータをconcatして全データをまとめる
y_pred_all=np.hstack((y_preds))
y_pred_proba_all=np.hstack((y_pred_probas))
y_pred_proba_both_all=np.concatenate(y_pred_proba_boths)
y_tests_all=pd.concat(y_tests)
# 評価指標計算
log_loss_, accuracy, precision, recall, auc_ = eval_list(y_tests_all.values, y_pred_all, y_pred_proba_all, y_pred_proba_both_all)
# 混合行列
print_cmx(y_tests_all.values, y_pred_all, save_name='confusion_matrix.png')
# Pred Prob曲線
calib_curve(y_tests_all, y_pred_proba_all, save_name='calib_curve.png')
# 全データでの予測結果をmlflowに記録
mlflow.set_experiment('xgb_predict_all')# 実験の名前を定義
with mlflow.start_run():# mlflow記録開始
mlflow.log_param("01_method_name", model.__class__.__name__)
mlflow.log_param("02_features", exp_col)
mlflow.log_param("03_objective_col", ob_col)
mlflow.log_params(model.get_xgb_params())
mlflow.log_metrics({"01_accuracy": accuracy})
mlflow.log_metrics({"02_precision": precision})
mlflow.log_metrics({"03_recall": recall})
mlflow.log_metrics({"04_log_loss": log_loss_})
mlflow.log_metrics({"05_auc": auc_})
mlflow.log_artifact('ROC_curve.png')
os.remove('ROC_curve.png')
mlflow.log_artifact('confusion_matrix.png')
os.remove('confusion_matrix.png')
mlflow.log_artifact('calib_curve.png')
os.remove('calib_curve.png')
上記のコードを実行すると、先ほどのクラスタごとにモデルが作られ、MLflowに記録される。
アルゴリズム名や、説明変数名、ハイパラの値、損失関数、様々な指標の分類精度、ROCカーブ、Calibrationカーブ、Recall, Precisionカーブ、混合行列などを記録できる。
mlflowトップ画面
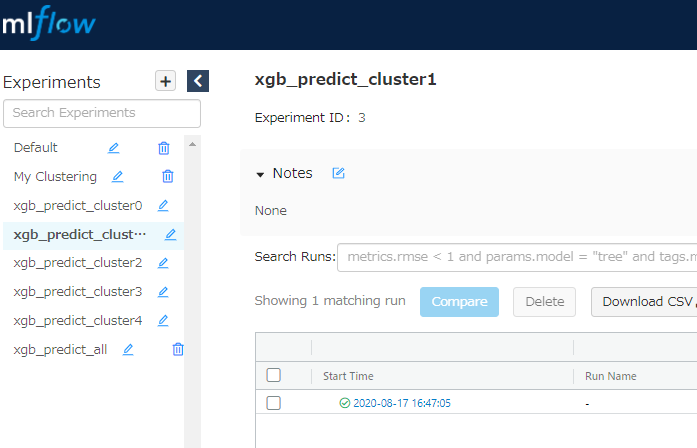
Parameters

Metrics
Artifacts
このように記録していくと、説明変数を変えたり、ハイパラ調整をしたり、アルゴリズムを変えたりした時などに、以前のモデルの結果と比較することが容易くなる。
おわりに
備忘録的なことも兼ねているが、MLflowの説明は一切せず、こんな感じで使えるよという活用方法をメインに示した。これから使おうかなと考えている人の活用イメージが湧くような内容になっていたら嬉しい。興味が湧いた人は他の記事などでも調べて使ってみることをオススメ。
おまけ
"mlruns"フォルダの中身
1をクリック
b3fa3eb983044a259e6cae4f149f32c8をクリック
artifactsをクリック
図が保存されている
mlflow uiで確認できるものはこのようにLocalに保存されている。
クラウドサービスと連携していろんな人とモデルの記録を共有することもできるみたい。
個人で使う分にはLocalで問題ないかな。
以上!