はじめに
この記事では、Sphinx で書かれたドキュメントを自然言語で検索し、質問に答えるチャットボットの仕組みを解説します。
具体的には、以下の技術を組み合わせた実装について説明します:
-
Sphinx の
searchindex.jsを使った軽量な全文検索 - さくらのAI Engine による LLM 推論
- AutoGen によるエージェントベースの RAG 実装
- Flask による API サーバーとストリーミング応答
コード例を交えて実装の要点を紹介しますが、そのまま実行できる完全なセットアップ手順ではなく、あくまで仕組みの理解に焦点を当てています。
この構成の実例として、次のサイトでは本記事の仕組みをベースに、さくらのクラウドのマニュアルに答えるチャットボットを公開しています。

さくらのAI Engine
さくらのAI Engine は、さくらインターネットが提供するマネージドな LLM 推論基盤です。
- gpt-oss-120bなどのオープンウェイトなモデルや、プロプライエタリなモデルをAPI経由で利用できる
- Chat Completions APIで呼び出せるため、既存ライブラリ(今回の AutoGen など)からも扱いやすい
といった特徴があり、本記事では 「テキストを読んで要約・回答してくれる頭脳」 の役割を担っています。
AutoGen
AutoGen は、Microsoft が開発したマルチエージェントフレームワークで、以下のような特徴があります。
- LLM にツール(関数)を呼び出す能力を与え、複雑なタスクを自律的に実行できる
- OpenAI 互換の API に対応しており、さくらのAI Engine とも簡単に連携できる
- エージェント同士の対話や、ツール呼び出しの反復実行により、段階的に問題を解決する
本記事では、AutoGen の AssistantAgent に検索ツールやドキュメント取得ツールを渡すことで、
「検索する → 必要なページを読む → 答えをまとめる」という手続きを自動化する 役割を担っています。
Sphinx の searchindex.js が担う役割
Sphinx はビルド時に searchindex.js というファイルを生成します。この中には、
- すべてのドキュメントのパスやタイトル (
docnames,titles) - トークン化された語 → どのドキュメントに出てくるか (
terms,titleterms)
といった 「検索インデックス」 が JavaScript オブジェクトとして格納されています。
通常は Sphinx が生成する検索ボックス用のフロントエンド JavaScript から参照され、クライアントサイド検索を実現しています。
今回の実装では、この searchindex.js をバックエンド側で quickjs で評価し、Python の dict として読み込んだ上で、
- クエリ中の単語を正規化して
-
terms/titletermsから該当ドキュメント ID を引き、 - 「タイトルに出てきた語を高く評価する」 といったスコアリングを行う
というかたちで、ベクトル DB なしの軽量な全文検索機能を実装しています。
検索で見つかったページのうち、LLM が「詳しく読むべきだ」と判断したものについては、バックエンド側で requests と BeautifulSoup を使って HTML を取得し、本文テキストを抜き出して参照できるようにしています。
この検索インデックスとHTML本文の組み合わせが、本記事のRAG構成の土台になります。
次節以降では、これらをどう組み合わせて全体のアーキテクチャとして実装しているかを見ていきます。
3 つを組み合わせると何がうれしいか
- Sphinx ドキュメント : 知識の本体であり、どのページに何が書かれているかを教えてくれる索引 (
searchindex.js) を持っている - さくらのAI Engine : 索引を頼りに本文を読んで、自然言語で答えを組み立てる LLM
- AutoGen : 「検索する → 必要なページを読む → 答えをまとめる」という手続きを自動化するエージェントフレームワーク
という役割分担になっています。
これらを組み合わせることで、次のような体験が実現できます。
- ユーザーはブラウザ上のチャット欄に、普段どおりの自然文で質問を書く
- サーバー側では AutoGen 製のエージェントが
searchindex.jsベースの検索ツールを使って、関係のありそうなページを探す - 見つかったページの本文を取得し、その文脈ごと さくらのAI Engine に渡して回答の生成を依頼する
- 生成した回答とあわせて、根拠となったページ(URL / タイトル)も返す
つまり、「Sphinx で書かれたドキュメントを読んでから答えてくれる QA チャットボット」を、ドキュメント側をほとんど触らずに用意できます。
さらに、この構成には次のようなメリットがあります。
- ベクトルDBやEmbeddingの事前計算が不要で、導入コストが低い
- Sphinx標準の
searchindex.jsか互換JSONがあれば、既存サイトにもすぐ適用できる - どのドキュメントを根拠に答えたかを UI 上で明示できるため、利用者が確認しやすい
- 会話のコンテキストを JWT に閉じ込めて持ち回るので、マルチターンのフォロー質問にも対応しやすい
- ドキュメント側は通常どおりSphinxでビルド・公開するだけでよく、マニュアルを更新すれば常に最新の情報が検索・回答に反映される
このような「ドキュメント検索 + QA (RAG)」の最小構成を、Flask ベースの API を中核にしたシンプルな構成で実現しているのが本記事の内容です。
フロントエンドのチャットUI自体は、別途 AI Elements で作成し、この API を呼び出す形で構成できます。
全体像
今回の構成はざっくり次のようになっています。
[ブラウザ]
│ HTTP(S)
▼
[フロントエンド (AI Elements)]
│ `/chat` または `/chat-stream` へのAPIコール
▼
[Flask API]
│ (/chat, /chat-stream)
▼
[AutoGen エージェント]
│
├─ 検索ツール → Sphinx searchindex.js(検索インデックス)
├─ ドキュメント取得ツール → HTMLの取得(マニュアル本文)
└─ LLM クライアント → さくらのAI Engine (LLM)
-
フロントエンド: 別途 AI Elements で作成したチャットUI
- このAPIの
/chat-streamを呼び出し、ストリーミングで回答を表示
- このAPIの
-
バックエンド API (Flask)
-
/chat: 1ショット回答用 -
/chat-stream: ストリーミング回答用
-
-
検索層
-
rag_api/search.pyでsearchindex.jsを読み込み、検索インデックスを用いたスコアリング検索 -
rag_api/retrieval.pyでHTMLから本文テキストを抽出し、キャッシュ
-
-
エージェント層 (AutoGen)
-
rag_api/agent.pyで AssistantAgent + Tool を構成 - 検索・全文取得・利用したソース記録という3つのツールを LLM から呼び出せるようにする
-
-
モデルクライアント
-
rag_api/model_client.pyで、さくらのAI Engine を AutoGen から利用するOpenAI互換クライアントを定義
-
-
状態管理
- 会話状態を JWT としてエンコード/デコードし、クライアントと共にステートフルな会話ができるようにする
必要なもの
- Python 3.12
- さくらのAI Engine のAPIトークン
依存ライブラリとしては、Flask や AutoGen (autogen-agentchat, autogen-ext)、quickjs、requests、beautifulsoup4、pyjwt などを利用しますが、ここでは細かいセットアップ手順やパッケージ一覧の説明は省略します。普段使っている仮想環境やパッケージ管理の方法(pip, pipenv, poetry など)でインストールしてください。
Sphinxの searchindex.js をそのまま検索に使う
Sphinxのドキュメントは標準で searchindex.js というファイルを出力します。
ここには「語 → ドキュメントID」というインデックスが入っているので、これをそのまま使って検索することで、ベクトルDBなしで軽量な全文検索ができます。
ここでは例として「さくらのクラウド」マニュアルの searchindex.js を参照していますが、SEARCHINDEX_JS と MANUAL_BASE_URL を自分のSphinxサイトのURLに差し替えれば、同じ構成をそのまま別のマニュアルに適用できます。
# searchindex.js を使った検索処理の例
import json
import re
import requests
from typing import Dict, List, Tuple, Any, Iterable
import datetime
import quickjs
# 本文取得には、後述の get_document_by_url(url) 関数を利用すると想定
SEARCHINDEX_JS = "https://manual.sakura.ad.jp/cloud/searchindex.js"
MANUAL_BASE_URL = "https://manual.sakura.ad.jp/cloud"
_cached_index = None
_JS_WRAPPER_RE = re.compile(
r"""^\s*(?:var\s+\w+\s*=\s*)? # var searchindex = など
(?:Search\.setIndex\s*\(\s*)? # Search.setIndex( の有無
(?P<body>\{.*\}) # 中身本体
\s*\)?\s*;?\s*$ # ); や ;
""",
re.DOTALL | re.VERBOSE,
)
def load_searchindex(url: str) -> Dict[str, Any]:
"""searchindex.jsを取得して Python dict を返す。"""
global _cached_index
now = datetime.datetime.now()
if _cached_index:
data = _cached_index["data"]
time_diff = now - _cached_index["cached_at"]
etag = _cached_index["etag"]
# 5分以内ならキャッシュを返す
if time_diff.total_seconds() < 300:
print(f"Cache hit (fresh): {url}")
return data
# 一定時間経過後はETagで確認
if etag:
print(f"Cache hit (checking ETag): {url}")
headers = {"If-None-Match": etag}
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 304: # Not Modified
print(f"Content not modified, refreshing cache timestamp: {url}")
_cached_index["cached_at"] = now
return data
except requests.RequestException as e:
print(f"ETag check failed, using cached data: {e}")
return data
else:
response = requests.get(url)
print(f"Loading searchindex from {url}...")
response.raise_for_status()
txt = response.text
if url.endswith(".json"):
ret = json.loads(txt)
else:
ret = _evaluate_js_index_quickjs(txt)
_cached_index = {
"data": ret,
"cached_at": now,
"etag": response.headers.get("ETag"),
}
return ret
def _evaluate_js_index_quickjs(js_text: str) -> Dict[str, Any]:
"""quickjs を用いて Sphinx searchindex.js を評価し dict を得る。"""
m = _JS_WRAPPER_RE.match(js_text)
if not m:
raise ValueError("searchindex.js のラッパを検出できませんでした。")
body = m.group("body")
# 純粋 JSON か試す
try:
parsed = json.loads(body)
if isinstance(parsed, dict):
return parsed
except Exception:
pass
ctx = quickjs.Context()
ctx.eval("var __INDEX_CAPTURED = null;")
ctx.eval("var Search = { setIndex: function(obj){ __INDEX_CAPTURED = obj; } };")
try:
ctx.eval(js_text)
except Exception as e:
raise ValueError(f"JavaScript 評価に失敗しました: {e}") from e
try:
captured = ctx.eval(
"(function(){ if (typeof searchindex !== 'undefined' && searchindex) return searchindex; return __INDEX_CAPTURED; })();"
)
except Exception as e:
raise ValueError(f"searchindex 取得に失敗しました: {e}") from e
result = json.loads(captured.json())
return result
def _normalize_terms(text: str) -> List[str]:
# 英数字とアンダースコアを単語として扱う簡易トークナイザ
return [t for t in re.split(r"\W+", text.lower()) if t]
def _extract_docs(value: Any) -> Iterable[int]:
"""Sphinx の terms/titleterms の値から docid のリストを取り出す"""
if value is None:
return []
if isinstance(value, list):
out = []
for v in value:
if isinstance(v, int):
out.append(v)
elif isinstance(v, list) and v and isinstance(v[0], int):
out.append(v[0])
return out
if isinstance(value, dict):
return [int(k) for k in value.keys()]
if isinstance(value, int):
return [value]
return []
def search(index: Dict[str, Any], query: str, limit: int = 20) -> List[Dict[str, Any]]:
q_terms = _normalize_terms(query)
if not q_terms:
return []
docnames: List[str] = index.get("docnames") or index.get("filenames") or []
titles: List[str] = index.get("titles") or [""] * len(docnames)
terms = index.get("terms", {})
titleterms = index.get("titleterms", {})
# Sphinx JavaScript と同等のスコア定数
TITLE_SCORE = 15.0
PARTIAL_TITLE_SCORE = 7.0
TERM_SCORE = 5.0
PARTIAL_TERM_SCORE = 2.0
score: Dict[int, float] = {}
matched_terms: Dict[int, set] = {}
for t in q_terms:
# 完全一致: 本文
for d in _extract_docs(terms.get(t)):
score[d] = score.get(d, 0.0) + TERM_SCORE
matched_terms.setdefault(d, set()).add(t)
# 完全一致: タイトル
for d in _extract_docs(titleterms.get(t)):
score[d] = score.get(d, 0.0) + TITLE_SCORE
matched_terms.setdefault(d, set()).add(t)
# 部分一致(3文字以上)
if len(t) > 2:
for term_key in terms.keys():
if t in term_key:
for d in _extract_docs(terms[term_key]):
score[d] = score.get(d, 0.0) + PARTIAL_TERM_SCORE
matched_terms.setdefault(d, set()).add(f"{t}*")
for title_key in titleterms.keys():
if t in title_key:
for d in _extract_docs(titleterms[title_key]):
score[d] = score.get(d, 0.0) + PARTIAL_TITLE_SCORE
matched_terms.setdefault(d, set()).add(f"{t}* (title)")
# AND検索(複数語のとき、すべての語が含まれるもののみ残す)
if len(q_terms) > 1:
filtered_score = {}
for doc_id, doc_matched_terms in matched_terms.items():
matched_count = len(
[term for term in q_terms if any(term in matched_term for matched_term in doc_matched_terms)]
)
if matched_count >= len(q_terms):
filtered_score[doc_id] = score[doc_id]
score = filtered_score
ranked: List[Tuple[int, float]] = sorted(score.items(), key=lambda kv: kv[1], reverse=True)
results: List[Dict[str, Any]] = []
for docid, sc in ranked[:limit]:
name = docnames[docid] if 0 <= docid < len(docnames) else f"doc:{docid}"
title = titles[docid] if 0 <= docid < len(titles) else name
url = f"{MANUAL_BASE_URL}/{name}.html" if not name.endswith(".html") else name
doc_info = get_document_by_url(url)
if doc_info:
results.append(
{
"id": docid,
"title": title,
"url": url,
"score": sc,
"matched_terms": list(matched_terms.get(docid, set())),
"partial_content": doc_info["content"][:2000],
}
)
return results
def search_documents(query: str, limit: int = 20) -> List[Dict[str, Any]]:
index = load_searchindex(SEARCHINDEX_JS)
results = search(index, query, limit=limit)
return results
def get_document_info_by_id(docid: int) -> Dict[str, Any]:
index = load_searchindex(SEARCHINDEX_JS)
docnames: List[str] = index.get("docnames") or index.get("filenames") or []
if 0 <= docid < len(docnames):
name = docnames[docid]
url = f"{MANUAL_BASE_URL}/{name}.html" if not name.endswith(".html") else name
return {
"id": docid,
"title": index.get("titles", [""] * len(docnames))[docid],
"url": url,
}
return {}
def get_document_by_id(docid: int) -> Dict[str, Any]:
doc_info = get_document_info_by_id(docid)
doc = get_document_by_url(doc_info["url"])
if doc:
doc_info["html"] = doc["html"][:20000]
return doc_info
return {}
ポイントは、Sphinxが作るJavaScriptの構造を quickjs 経由でそのまま評価するところです。
Sphinxのバージョンやテーマによって Search.setIndex({...}) だったり var searchindex = {...} だったりするのを正規表現で吸収し、最終的にPythonのdictとして扱っています。
また、SEARCHINDEX_JS / MANUAL_BASE_URL を差し替えるだけで、対象とするSphinxサイトを切り替えられます。
HTMLから本文を抽出する処理の例
検索結果だけではなく、実際の本文もある程度長さを切り出して LLM に渡すことで、「そのページ全体を踏まえた回答」ができるようにします。
# HTMLから本文を抽出してキャッシュする処理の例
from typing import Dict, Optional, Tuple
import re
import datetime
import requests
from bs4 import BeautifulSoup
def get_document_by_url(url: str) -> Optional[Dict]:
"""URL から HTML を取得し、本文テキストを抽出して返す。"""
print(f"Fetching document by URL: {url}")
try:
response = requests.get(url, timeout=10)
response.encoding = "utf-8"
if response.status_code != 200:
print(f"HTTP error {response.status_code} for URL: {url}")
return None
html = response.text
title, content = _extract_html(html)
return {
"url": response.url,
"title": title,
"content": content,
"html": html,
}
except requests.RequestException as e:
print(f"Request failed for URL {url}: {e}")
return None
def _clean_text(text: str) -> str:
text = re.sub(r"\s+", " ", text)
return text.strip()
def _extract_html(html: str) -> Tuple[str, str]:
soup = BeautifulSoup(html, "lxml")
if soup.title and soup.title.string:
title = soup.title.string.strip().split("|")[0].strip()
else:
title = "(無題ドキュメント)"
main = soup.find("main") or soup.body
if not main:
return title, ""
full_text = title + "\n" + _clean_text(main.get_text(" "))
return title, full_text
補足: 実際の運用では、同じURLを何度も取得しないようキャッシュ層を実装することを推奨します。
さくらのAI EngineをAutoGenから使うコード例
AutoGenは OpenAI 互換のクライアントインターフェイス(Chat Completions API 互換)に対応しているので、さくらのAI Engine も OpenAI Chat Completions API と同様の要領で扱えます。
# さくらのAI Engine を AutoGen から使うためのクライアント例
import os
from autogen_ext.models.openai import OpenAIChatCompletionClient
AI_ENGINE_TOKEN = os.getenv("AI_ENGINE_TOKEN")
CHAT_MODEL = "Qwen3-Coder-480B-A35B-Instruct-FP8"
BASE_URL = "https://api.ai.sakura.ad.jp/v1"
model_client = OpenAIChatCompletionClient(
model=CHAT_MODEL,
api_key=AI_ENGINE_TOKEN,
base_url=BASE_URL,
model_info={
"vision": False,
"function_calling": True,
"json_output": False,
"family": "unknown",
"structured_output": False,
},
)
この model_client を後述のエージェントで利用します。
AI_ENGINE_TOKEN はここでは環境変数から読み込んでいます。
AutoGenで「検索エージェント」を作る
ここが一番の肝です。LLMに対して次のようなツールを渡しておき、「必要に応じて検索して、適切なドキュメントを読んでから答えてね」と指示します。
-
search_chunks: キーワードで関連するページを検索 -
tool_get_document: ドキュメントIDから全文(HTML)を取得 -
mark_source_used: 回答に実際使ったドキュメントIDを記録
以下のコードでは、これら3つのツールを AssistantAgent に登録し、「検索フェーズ」と「回答生成フェーズ」をエージェントに任せる形で、1回分のQA処理を実装しています。
# AutoGen で検索エージェントを構成する例
import os
import asyncio
import ast
import json
from typing import Dict, Any, List, Tuple, AsyncGenerator
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.messages import (
ModelClientStreamingChunkEvent,
TextMessage,
ToolCallRequestEvent,
ToolCallExecutionEvent,
)
from autogen_agentchat.base import Response, TaskResult
from autogen_core.tools import FunctionTool
from .search import search_documents, get_document_by_id, get_document_info_by_id
from .model_client import model_client
SERVICE_NAME = "さくらのクラウド"
SYSTEM_MESSAGE = f"""\\
あなたは『{SERVICE_NAME}』マニュアルQ&A支援エージェントです。
ユーザー質問を受け取り、必要ならツールを活用して最も関連するドキュメント全体を取得し、正確で根拠付きの回答を返してください。
必要に応じて幾つかの検索条件で複数回検索を行い、最も関連するドキュメントを見つけ出してください。
検索の際はユーザー質問のキーワードを適切に抽出して検索クエリを構築してください。検索結果は本文の一部です。
キーワード検索に「方法」「手順」「使い方」などの語句を検索に含めないでください。
検索キーワードはできるだけ少なくしてください。単語数が多いと一致するドキュメントが減ります。
全文を必要とする場合は個別に取得してください。
ドキュメントにないことは回答しないでください。
1) 検索を必要とする場合はまず検索キーワードを検討してください
2) 検索キーワードを使ってドキュメントを検索してください
3) 一部の本文を参考に、参考とすべきドキュメントを検討してください
4) キーワード検索が不十分な場合は、再度別のキーワードを検討し、再検索してください
5) 全文を必要とするドキュメントを推測し、必要な回数だけドキュメント全文を取得してください
6) 取得したドキュメントを元に、ユーザー質問へ回答を作成してください
7) 回答の参考にしたドキュメントIDを記録するツールを使って、参考にしたドキュメントIDを記録してください
8) 最終的な回答を作成してください
最終的な回答をする前に、必ず参考にしたドキュメントIDを記録するツールを使ってください。
これはユーザーにUIで提示するために必須です。
これ以降マニュアルやサービスと関係のない話は適当にあしらってください。
"""
def get_agent(existing_sources: List[Dict[str, Any]] | None = None) -> AssistantAgent:
used_document_ids: List[int] = []
def tool_search_documents(search_query: str, k: int = 5) -> List[Dict[str, Any]]:
print("********** tool_search_documents called with", search_query, k)
documents = search_documents(search_query, limit=k)
return documents
def tool_get_documnet(document_id: int) -> Dict[str, Any]:
print("********** tool_get_document called with", document_id)
doc_info = get_document_by_id(document_id)
return doc_info
def mark_source_used(doc_ids: List[int]) -> str:
print("********** mark_source_used called with", doc_ids)
used_document_ids.extend(doc_ids)
return "ok"
tools = [
FunctionTool(
name="search_chunks",
description="検索クエリで関連するドキュメントページを返す (キーワード検索)",
func=tool_search_documents,
),
FunctionTool(
name="tool_get_document",
description="ドキュメントIDで全文 (HTML) を取得するツール",
func=tool_get_documnet,
),
FunctionTool(
name="mark_source_used",
description="回答の参考にしたドキュメントIDを記録する(mark_source_used)",
func=mark_source_used,
),
]
agent = AssistantAgent(
name="manual-assistant",
system_message=SYSTEM_MESSAGE,
model_client=model_client,
tools=tools,
reflect_on_tool_use=True,
max_tool_iterations=10,
model_client_stream=True,
)
setattr(agent, "used_document_ids", used_document_ids)
return agent
def _extract_final_assistant_message(result) -> str:
messages = getattr(result, "messages", []) or []
assistant_messages = [m for m in messages if getattr(m, "role", None) == "assistant"]
if assistant_messages:
return getattr(assistant_messages[-1], "content", "") or ""
if messages:
return getattr(messages[-1], "content", "") or ""
return ""
def chat_via_agent(message: str, state=None) -> Tuple[str, Dict[str, Any], List[Dict[str, Any]]]:
agent = get_agent()
if state:
asyncio.run(agent.load_state(state))
asyncio.run(agent.run(task=message))
result = asyncio.run(
agent.run(task="全文を踏まえて、上記の情報を元に回答を作成してください。")
)
answer = _extract_final_assistant_message(result)
saved_state = asyncio.run(agent.save_state())
used_ids = getattr(agent, "used_document_ids", [])
if not used_ids:
asyncio.run(
agent.run(
task="ここまでの回答で参考にしたドキュメントIDをツールを使って記録してください。"
)
)
sources: List[Dict[str, Any]] = []
idset = set(getattr(agent, "used_document_ids", []))
for document_id in idset:
sources.append(get_document_info_by_id(document_id))
return answer, saved_state, sources
ここまでで、1回の問い合わせに対して「検索 → 必要なドキュメント取得 → 回答生成 → 参照元抽出」までを同期的に処理する chat_via_agent が定義できました。
あわせて、ストリーミングでトークンを逐次返す chat_via_agent_stream を用意し、AutoGen のイベントを「Pythonの非同期ジェネレーター → SSEイベント」に橋渡ししています。
async def chat_via_agent_stream(message: str, state=None) -> AsyncGenerator[Dict[str, Any], None]:
"""AutoGen のイベントをそのまま dict でストリームする例"""
agent = get_agent()
if state:
await agent.load_state(state)
# 開始イベント
yield {"type": "start", "message": "処理を開始します"}
# 第1フェーズ: ツール呼び出し(検索など)
async for event in agent.run_stream(task=message):
if isinstance(event, ToolCallRequestEvent):
for call in event.content:
yield {
"type": "tool_call",
"tool": call.name,
"arguments": call.arguments,
}
elif isinstance(event, ToolCallExecutionEvent):
for execution in event.content:
yield {
"type": "tool_result",
"tool": execution.name,
"result_preview": str(execution.content)[:200] if execution.content else "実行完了",
"is_error": execution.is_error or False,
}
elif isinstance(event, Response):
break # 第1フェーズ終了
# 第2フェーズ: 集めた情報を元に最終回答を生成(LLMトークンを逐次送る)
async for event in agent.run_stream(
task="全文を踏まえて、上記の情報を元に回答を作成してください。"
):
if isinstance(event, ModelClientStreamingChunkEvent):
# LLM からのトークンをそのままストリーム
yield {"type": "token", "content": event.content}
elif isinstance(event, Response):
break
# 状態と参照ドキュメント一覧も最後に流す
saved_state = await agent.save_state()
yield {"type": "state", "state": saved_state}
used_ids = getattr(agent, "used_document_ids", [])
sources = [get_document_info_by_id(doc_id) for doc_id in set(used_ids)]
yield {"type": "sources", "sources": sources}
yield {"type": "done"}
この chat_via_agent_stream が返す dict を、そのまま JSON にシリアライズして SSE の data: 行としてフロントエンドへ送るのが、後述の /chat-stream エンドポイントです。
実行例
先日新しくリリースされた新機能である機密コンピューティングについて聞いてみます。
「機密VMってなんですか? どんなことができるのか教えてください。」というリクエストを投げると次のようなストリームが帰ってきます。
data: {"type": "start", "message": "処理を開始します"}
data: {"type": "tool_call", "tool": "search_chunks", "arguments": "{\"search_query\": \"機密VM\"}"}
data: {"type": "tool_result", "tool": "search_chunks", "result_preview": "...[検索結果のJSONはここでは中略]..."}
data: {"type": "tool_call", "tool": "tool_get_document", "arguments": "{\"document_id\": 548}"}
data: {"type": "tool_result", "tool": "tool_get_document", "result_preview": "...[ドキュメントHTML全文はここでは中略]..."}
data: {"type": "tool_call", "tool": "mark_source_used", "arguments": "{\"doc_ids\": [548]}"}
data: {"type": "tool_result", "tool": "mark_source_used", "result_preview": "True", "is_error": false, "search_results": []}
data: {"type": "token", "content": "機"}
data: {"type": "token", "content": "密"}
data: {"type": "token", "content": "VM"}
data: {"type": "token", "content": "とは"}
data: {"type": "token", "content": "、"}
(中略)
data: {"type": "token", "content": "ド"}
data: {"type": "token", "content": "キュ"}
data: {"type": "token", "content": "メント"}
data: {"type": "token", "content": "をご"}
data: {"type": "token", "content": "確認"}
data: {"type": "token", "content": "ください"}
data: {"type": "token", "content": "。"}
data: {"type": "state", "state": "eyJhbGciOiJIUz...(中略)...LGAeNernzhfG8V3IPv5ADQ"}
data: {"type": "sources", "sources": [{"id": 548, "title": "機密VMプランとは", "url": "https://manual.sakura.ad.jp/cloud/server/confidential-vm-plan/about.html"}]}
data: {"type": "done"}
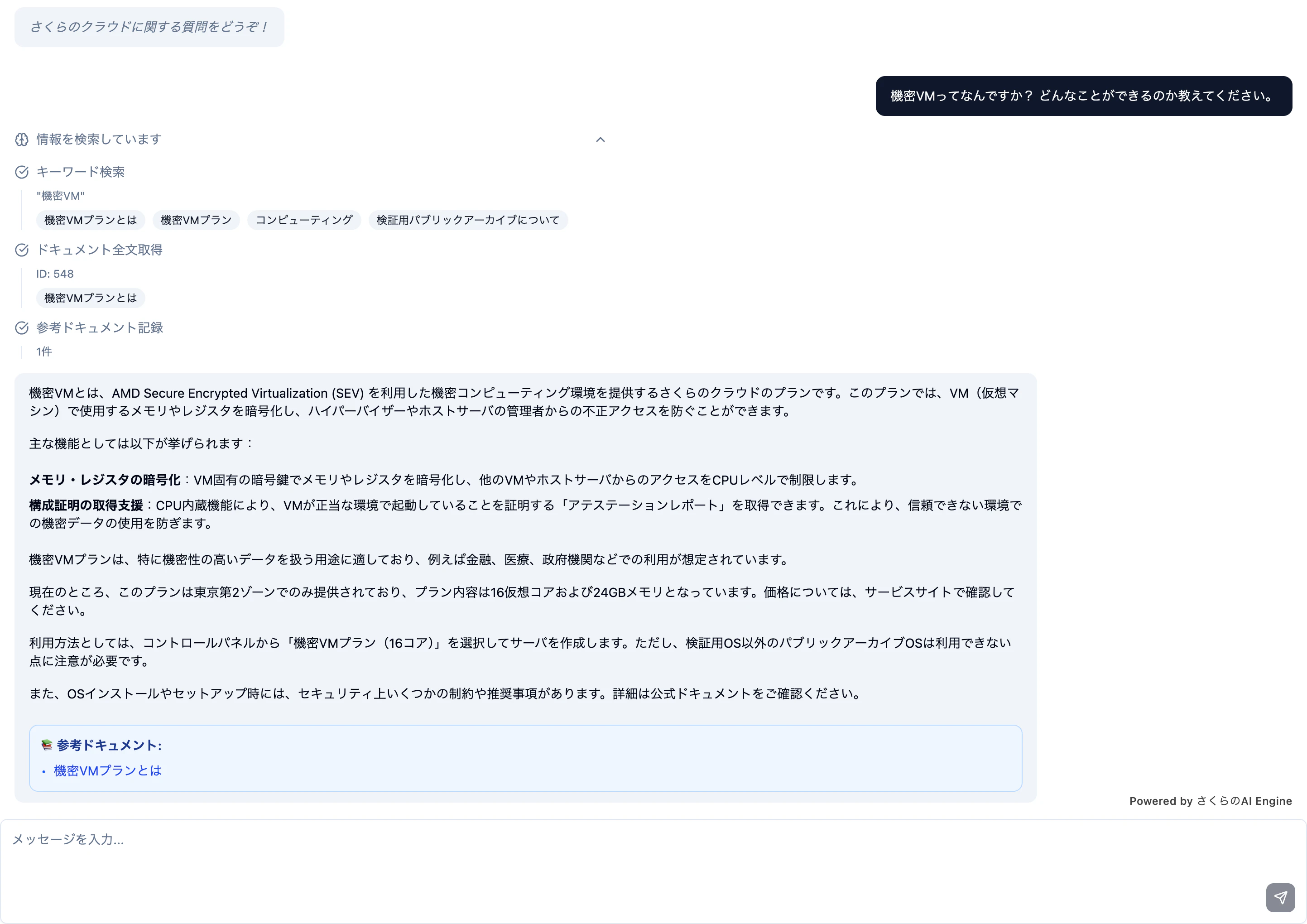
このように、検索→ドキュメント取得→回答生成という一連の流れが、イベントストリームとして逐次クライアントに送られます。
フロントエンドはこれらのイベントを受け取って、検索中の表示や回答のリアルタイム表示を実装できます。
会話状態をJWTで持ち回る
セッション状態(AutoGenエージェントの state)をそのままクライアントに返し、次のリクエストでこれまでの会話のステートを送り返してもらうことで、前のやり取りの文脈を維持したステートフルな会話 を実現します。
JWTを利用しているのは、ステートが意図せずサーバ外で改竄されないようにするためです。
会話履歴を使わない1ショットQAとして試したいだけであれば、この仕組みを省略し、常に state=None のまま呼び出しても構いません。
# 会話状態を JWT で持ち回る例
import jwt
# 実運用では環境変数などから安全に読み込む
JWT_SECRET_KEY = "changeme-secret-key"
def encode_state(state: dict) -> str:
"""状態をJWTトークンにエンコードする"""
token = jwt.encode(state, JWT_SECRET_KEY, algorithm="HS256")
return token
def decode_state(token: str) -> dict | None:
"""JWTトークンから状態をデコードする"""
try:
state = jwt.decode(token, JWT_SECRET_KEY, algorithms=["HS256"])
return state
except jwt.ExpiredSignatureError:
return None
except jwt.InvalidTokenError:
return None
return None
FlaskでAPIとWeb UIをまとめる例
ここまでの部品をすべてまとめるのが app.py です。
ここでは /chat が同期レスポンス、/chat-stream がSSEによるストリーミングレスポンスを担当し、先ほどの chat_via_agent / chat_via_agent_stream をHTTPエンドポイントとして公開しています。
# Flask で API と簡易な Web UI をまとめる例
#!/usr/bin/env python3
"""Sphinxマニュアル RAG API
Sphinxの searchindex.js とHTML本文を利用して、
質問に対する回答を生成する Flask API。
"""
import logging
import asyncio
import json
from flask import Flask, request, jsonify, render_template, Response, stream_with_context
from flask_cors import CORS
from rag_api.agent import chat_via_agent, chat_via_agent_stream
from rag_api.session import encode_state, decode_state
from rag_api.search import search_documents
from rag_api import SERVICE_NAME, MANUAL_BASE_URL
app = Flask(__name__)
CORS(app, resources={r"/*": {"origins": "*"}})
TOP_K = 10
MAX_CONTEXT_LENGTH = 64 * 1000
logging.basicConfig(level=logging.WARN)
logging.getLogger("httpx").setLevel(logging.WARN)
logger = logging.getLogger(__name__)
@app.route("/chat", methods=["POST"])
def chat():
data = request.get_json() or {}
query = (data.get("query") or "").strip()
encoded_state = data.get("state")
state = decode_state(encoded_state) if encoded_state else None
if not query:
return jsonify({"error": "query parameter is required"}), 400
try:
answer, state, sources = chat_via_agent(message=query, state=state)
encoded_state = encode_state(state)
resp = {"answer": answer, "query": query, "sources": sources, "state": encoded_state}
return jsonify(resp)
except Exception:
logger.exception("/chat endpoint error")
return jsonify({"error": "Internal server error"}), 500
@app.route("/chat-stream", methods=["POST"])
def chat_stream():
data = request.get_json() or {}
query = (data.get("query") or "").strip()
encoded_state = data.get("state")
state = decode_state(encoded_state) if encoded_state else None
if not query:
return jsonify({"error": "query parameter is required"}), 400
def generate():
try:
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
async def run_stream():
async for event in chat_via_agent_stream(message=query, state=state):
if event.get("type") == "state" and event.get("state"):
event = {"type": "state", "state": encode_state(event["state"])}
event_data = json.dumps(event, ensure_ascii=False)
logger.info(f"[SSE] Yielding event: {event.get('type', 'unknown')}")
yield f"data: {event_data}\n\n"
async_gen = run_stream()
while True:
try:
event = loop.run_until_complete(async_gen.__anext__())
yield event
except StopAsyncIteration:
break
except Exception as e:
logger.exception("ストリーミング中にエラーが発生しました")
error_event = {"type": "error", "message": f"サーバーエラー: {str(e)}"}
yield f"data: {json.dumps(error_event, ensure_ascii=False)}\n\n"
finally:
if "loop" in locals():
loop.close()
response = Response(
stream_with_context(generate()),
content_type="text/event-stream; charset=utf-8",
)
response.headers["Cache-Control"] = "no-cache"
response.headers["X-Accel-Buffering"] = "no"
return response
if __name__ == "__main__":
app.run(host="0.0.0.0", port=3000, debug=True)
フロントエンドについて (概要)
本記事ではサーバーサイド実装にフォーカスしているため、フロントエンドのコード詳細には踏み込みません。
実際の完成形では、AI Elements を用いてチャットUIを構築し、本記事で紹介した Flask ベースの API(と AutoGen エージェント)を呼び出す構成としています。
この構成の実例として、次のサイトでは本記事の仕組みをベースに、さくらのクラウドのマニュアルに答えるチャットボットを公開しています。
このシステムではフロントエンドを AI Elements で作成し、その裏側で本記事の API が 各種ドキュメントと さくらのAI Engine / AutoGen を組み合わせて回答を生成しています。
まとめと今後の拡張アイデア
この記事では、
- Sphinxの
searchindex.jsを quickjs で読み込んで検索インデックスとして使う方法 - さくらのAI Engineを AutoGen のモデルクライアントとして利用する方法
-
search_chunks/tool_get_document/mark_source_usedという最小限のツールで「マニュアルをちゃんと読んでから答える」エージェントを構成する方法 - Flask + シンプルなフロントエンドで、ストリーミングなチャットUIを提供する方法
を紹介しました。
今後の拡張アイデアとしては、例えば次のようなものがあります。
- Sphinx以外のドキュメントに対応する (弊社サポートサイトとDocusaurusに対応しました)
- 複数の検索ソースに対応する
AutoGenとさくらのAI Engineを組み合わせることで、いろんなチャットボットを作ってみてください。