はじめに
PostgreSQLはいろいろ機能がありますが、ウィンドウ関数は比較的に新しい機能でした。(PostgreSQL 8.4から導入)
ランキングでは5位以内です。今後もよりよい製品になるでしょう
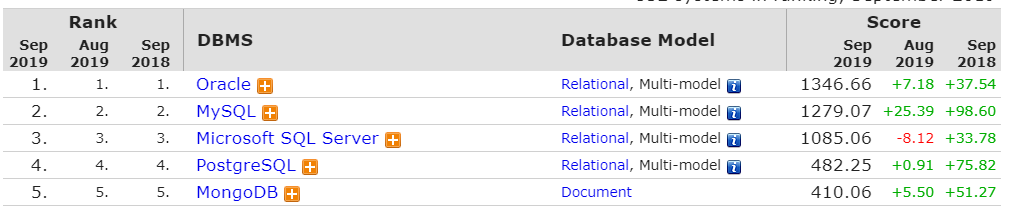
出典:https://db-engines.com/en/ranking
ウィンドウ関数は集計に役立つ機能なので、まとめてみます。
ウィンドウ関数とは
ウィンドウ関数は現在の問い合わせ行に関連した行集合に渡っての計算処理機能を提供します。
ウィンドウ関数は問い合わせ結果による現在行だけでなく、それ以上の行にアクセスすることができます。
集計関数は全件データを対象とし、ウィンドウ関数は関連する部分データを対象として処理できるのです。
汎用ウィンドウ関数
| 関数 | 戻り値 | 説明 |
|---|---|---|
| row_number() | bigint | 現在行のパーティション内での行番号(1から数える) |
| rank() | bigint | ギャップを含んだ現在行の順位。先頭ピアのrow_numberと同じになる。 |
| dense_rank() | bigint | ギャップを含まない現在行の順位。この関数はピアのグループ数を数える。 |
| percent_rank() | double precision | 現在行の相対順位。 (rank - 1) / (パーティションの総行数 - 1) |
| cume_dist() | double precision | 現在行の相対順位。 (現在行より先行する行およびピアの行数) / (パーティションの総行数) |
| ntile(num_buckets integer) | integer | できるだけ等価にパーティションを分割した、1から引数値までの整数 |
| lag(value anyelement [, offset integer [, default anyelement ]]) | valueと同じ型 | パーティション内の現在行よりoffset行だけ前の行で評価されたvalueを返す。 該当する行がない場合、その代わりとしてdefault(valueと同じ型でなければならない)を返す。 offsetとdefaultは共に現在行について評価される。 省略された場合、offsetは1となり、defaultはNULLになる。 |
| lead(value anyelement [, offset integer [, default anyelement ]]) | valueと同じ型 | パーティション内の現在行よりoffset行だけ後の行で評価されたvalueを返す。 該当する行がない場合、その代わりとしてdefault(valueと同じ型でなければならない)を返す。 offsetとdefaultは共に現在行について評価される。 省略された場合、offsetは1となり、defaultはNULLになる。 |
| first_value(value any) | valueと同じ型 | ウィンドウフレームの最初の行である行で評価されたvalue を返す |
| last_value(value any) | valueと同じ型 | ウィンドウフレームの最後の行である行で評価されたvalue を返す |
| nth_value(value any, nth integer) | valueと同じ型 | ウィンドウフレームの(1から数えて)nth番目の行である行で評価されたvalueを返す。行が存在しない場合はNULLを返す |
|
出典:https://www.postgresql.jp/document/11/html/functions-window.html
使い方
ウィンドウ関数呼び出しの構文
function_name ([expression [, expression ... ]]) [ FILTER ( WHERE filter_clause ) ] OVER window_name
function_name ([expression [, expression ... ]]) [ FILTER ( WHERE filter_clause ) ] OVER ( window_definition )
function_name ( * ) [ FILTER ( WHERE filter_clause ) ] OVER window_name
function_name ( * ) [ FILTER ( WHERE filter_clause ) ] OVER ( window_definition )
window_definition構文
[ existing_window_name ]
[ PARTITION BY expression [, ...] ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ frame_clause ]
frame_clause構文(いずれか)
{ RANGE | ROWS | GROUPS } frame_start [ frame_exclusion ]
{ RANGE | ROWS | GROUPS } BETWEEN frame_start AND frame_end [ frame_exclusion ]
フレームモード
- ROWSモード: 現在行の前あるいは後の指定した数の行でフレームが開始あるいは終了すること
- GROUPSモード: 在行のピアグループ(peer group)の前あるいは後の指定した数のピアグループでフレームが開始あるいは終了すること
- RANGEモード: 現在行の列の値と、フレーム中の前あるいは後ろの行の値の最大の差を指定
frame_startおよびframe_end構文(いずれか)
UNBOUNDED PRECEDING -- 先頭の行
n PRECEDING -- 現在行より<n>行前、RANGEの場合は<n>値前
CURRENT ROW -- 現在行
n FOLLOWING -- 現在行より<n>行後、RANGEの場合は<n>値後
UNBOUNDED FOLLOWING -- 末尾の行
ROWSモード例として、rows between unbounded preceding and unbounded followingと書くと条件と合致するデータの全行範囲で集計します。
RANGEモード例として、順序付け列の型がdateあるいはtimestampなら、RANGE BETWEEN '1 day' PRECEDING AND '10 days' FOLLOWINGと書くことができます。
また、ROWSとGROUPSモードでは、0 PRECEDINGと0 FOLLOWINGはCURRENT ROWと同じであること
frame_exclusion構文(いずれか)
EXCLUDE CURRENT ROW
EXCLUDE GROUP
EXCLUDE TIES
EXCLUDE NO OTHERS
サンプル
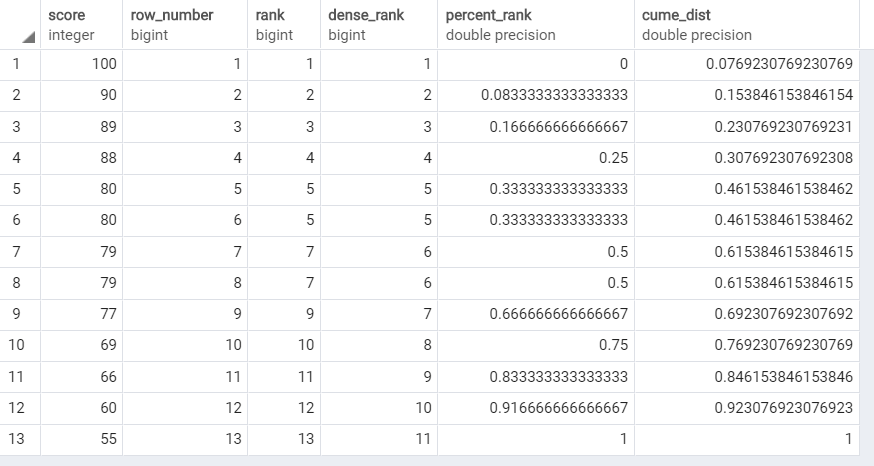
点数でランキングを確認する例
select
score,
row_number() OVER (ORDER BY score desc),
rank() OVER (ORDER BY score desc),
dense_rank() OVER (ORDER BY score desc),
percent_rank() OVER (ORDER BY score desc),
cume_dist() OVER (ORDER BY score desc)
from scores
結果
同じ年齢の平均点数、最高点数、最低点数
select
age,
score,
first_value(score) over (PARTITION BY age ORDER BY score DESC rows between unbounded preceding and unbounded following) as "最高点数",
last_value(score) over (PARTITION BY age ORDER BY score DESC rows between unbounded preceding and unbounded following) as "最低点数",
avg(score) over (PARTITION BY age ORDER BY score DESC) as "平均点数"
from scores
order by score desc
結果:
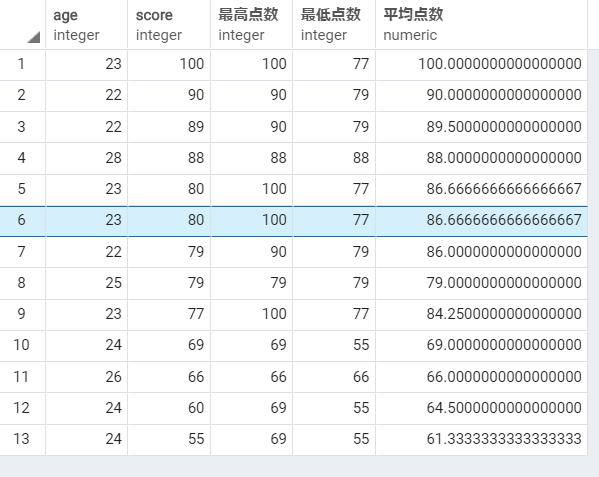
※点数の降順でソートしているため、first_valueは最高点数、last_valueは最低点数とみなします。
参考URL
ウィンドウ関数呼び出し:https://www.postgresql.jp/document/11/html/sql-expressions.html#SYNTAX-WINDOW-FUNCTIONS
ウィンドウ関数:https://www.postgresql.jp/document/11/html/tutorial-window.html
ウィンドウ関数:https://www.postgresql.jp/document/11/html/functions-window.html
以上