GECシステムは昔からrecallが低い
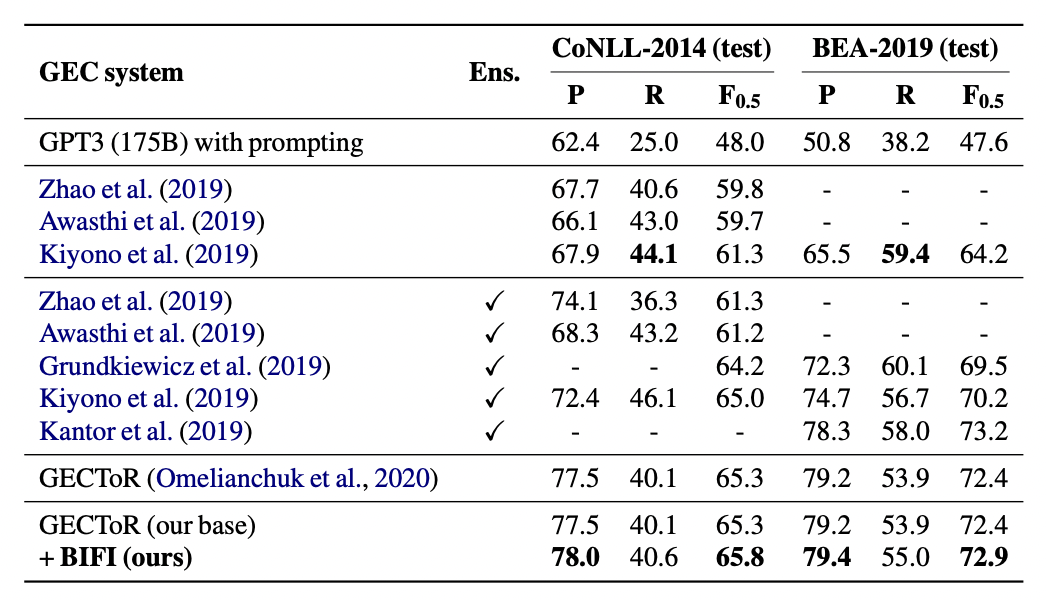
GECの古典的な問題の一つに、通称 "Low reacall(低再現率)問題" というものがあります。recallが低いというのはすなわちシステムのFalse Negative(=訂正すべき誤り箇所に対して、システムが誤りだと検知できていなケース)が多いということになります。下表は最近出た論文であるYasunaga et al. (2021)に記載のベンチマーク結果になりますが、今のニューラル時代においても全体的にその傾向が見て取れると思います。そのため、そこにはモデルうんぬんというよりはGEC特有の難しさがあると考えられます。
本記事では、このGECのLow recall問題に焦点をあて、「なぜrecallが低いのか」「何が難しくさせているのか」についてより理解を深めることを目的に簡単な分析をしてみます。なお、裏話をすると、今回紹介する分析自体は実は結構前(2019年頃?)に内向きに実施したものです。そのため、分析にSoTAシステムを使うと書いてますが当時におけるものなので今とは少しgapがあります。とはいえ、今にも通じる知見になっているだろうと個人的には思っているのと、このままお蔵入りするのはもったいないと思い今回書いてみました。
誤りの基準は人によって結構揺れる
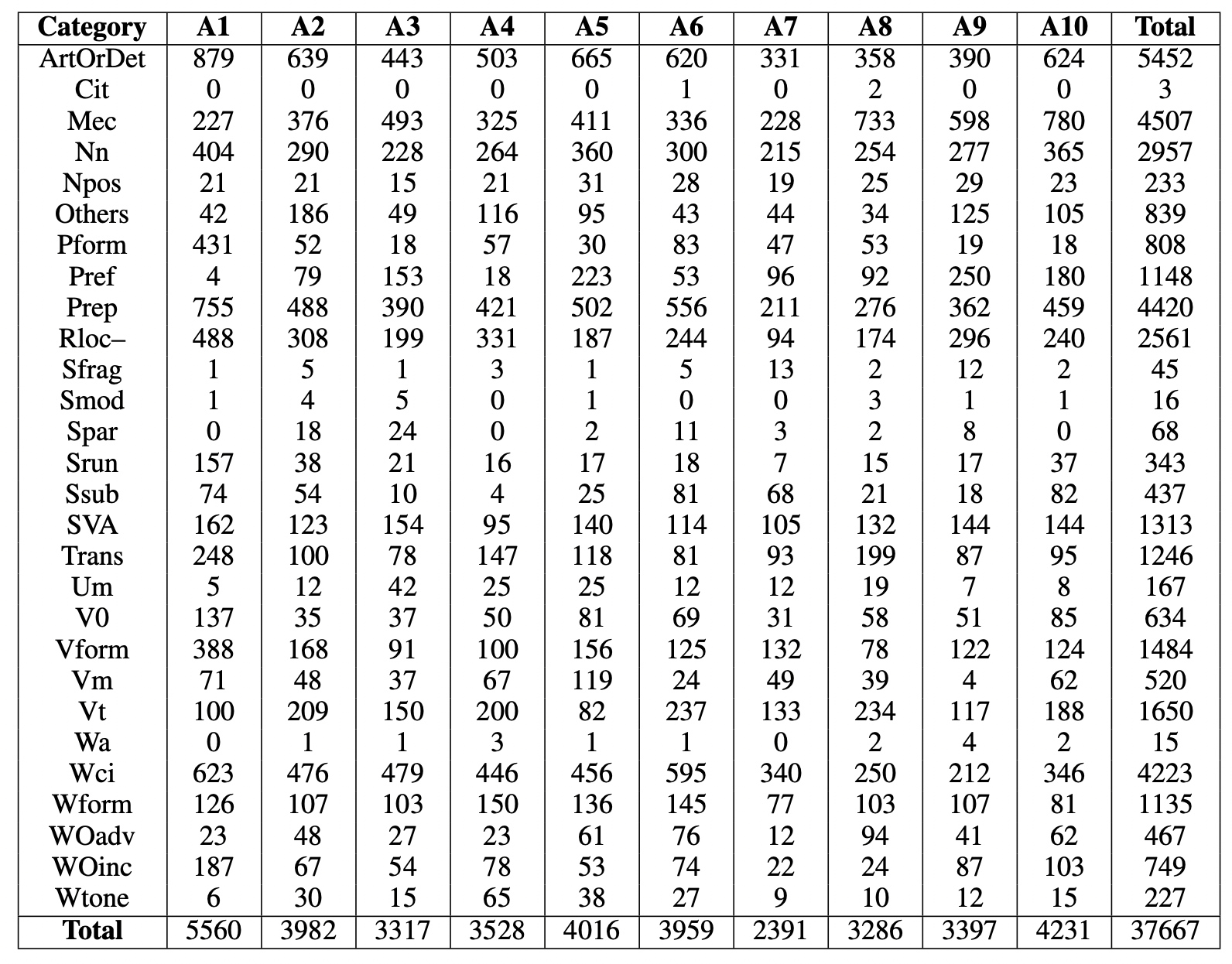
分析を始める前にまず押さえておかなければならないのは、そもそも何を誤りとするかは人間同士でも結構揺れるということです。下表は、Bryant ans Ng. (2015)が報告した、CoNLL-2014において、10人の各アノテータがどのようなアノテーションを行ったかを誤りタイプ別に示したものです。これをみると、例えばA1はこの文書にはArtOrDet(冠詞または限定詞に関する誤り)は計879あると言っているのに対し、A7は331しかないよと言っており、誤りの基準はアノテータ間でも思ったより揺れることがわかります。
実験1. アノテータ数を増やした時のシステム性能
CoNLL-2014の公式データセットには2人分のアノテーションしか提供されていないということもあり、従来GECシステムを評価するときは、せいぜい2つの正解データを用いた参照あり評価を行なってきました。しかし、先程の「異なるアノテータは異なるバイアスを持っている」という結果から、Low recallの原因の一つは評価側の問題にもあるような気がしてきます。
そこで、Bryant ans Ng. (2015)が提供した10つのアノテーション付きCoNLL-2014データ(通称CoNLL-10)を用いて、アノテータ数を増やした時のrecallの変動をまず調査してみます。なお、Bryant ans Ng. (2015)でも同様の実験はしているのですが、1) F0.5値しか報告しておらず特に今回着目しているrecallが不明、2) 実験に使用しているシステムも2014年頃のものと古い、という理由から当時のSoTAシステムであったGe et al. 2018を用いて改めて実験をした、という建て付けです。なお、誤りタイプは議論をしやすくするためにCoNLL-2013 Shared Taskで対象としていた、ArtOrDet (冠詞または限定詞に関する誤り)、 Nn (名詞の単複に関する誤り)、 Prep (前置詞誤り)、SVA (主語と動詞の一致誤り)、Vform (動詞の態に関する誤り)の計5種類の誤りタイプのみを扱うこととします。
以下に、アノテータ数を1から10に増やしたときのシステムおよび各誤りタイプ別のrecallの性能を示します。
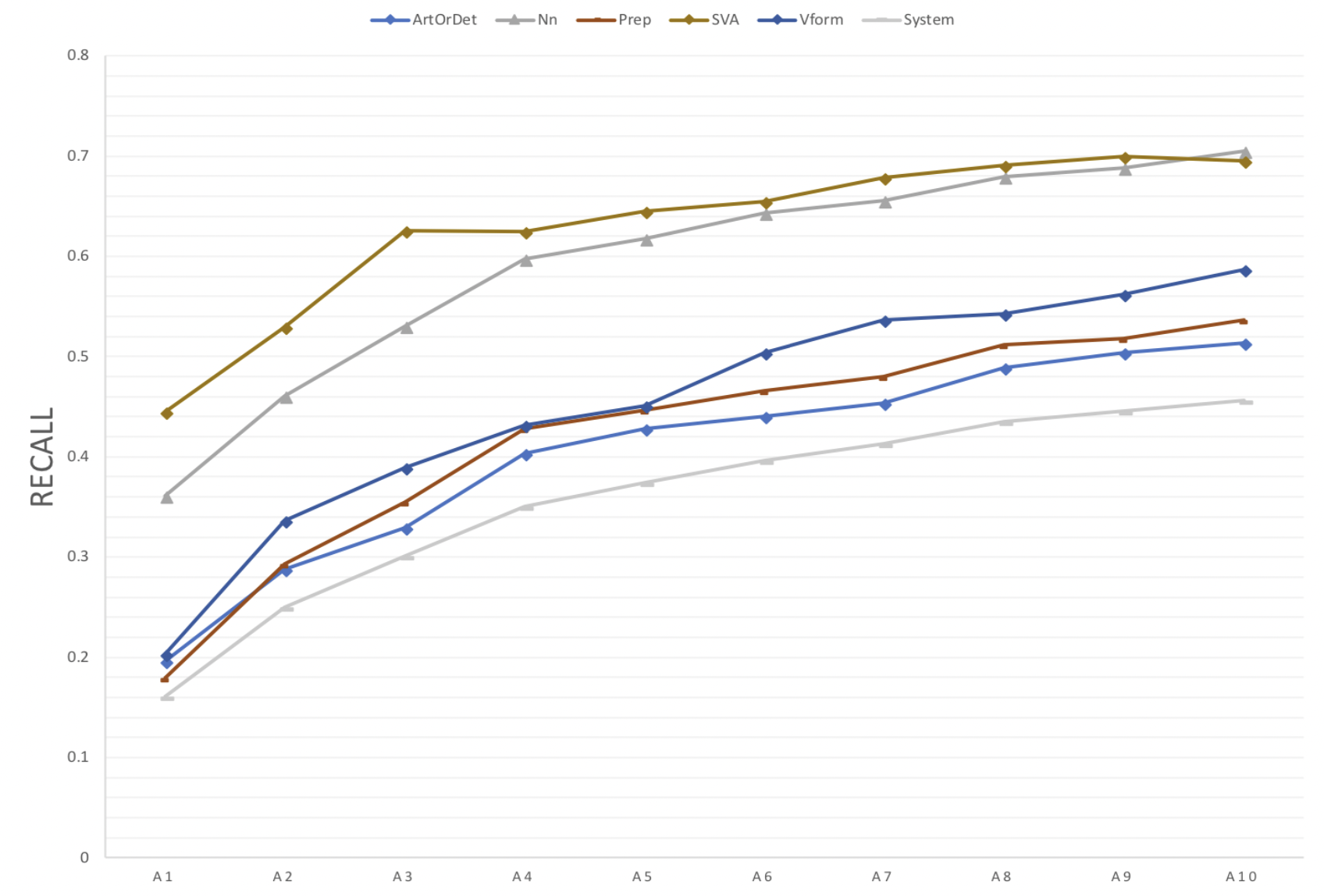
これをみると、アノテータ数が増えるほどrecallが上がっていることがわかります。逆にいうと、これまでベンチマークで見てきた"数値"は見かけ上低くなっていた(神のみぞ知る"真の値"はもっと高い)ということになるため、Low recall問題の要因の一つは評価の問題でもあることが言えます(※)。
※ このような評価の限界に関する問題意識は今に始まったことではなく、同様の議論も例えばSakaguchi et al. (2016)の中でもされています。
実験2. Difficulty分析
Low recallの要因の一つは評価の限界に起因していると話しましたが、しかし、アノテータ数を増やすと性能が上がるのは当然recallだけでなくprecisionにも言えます。つまり、絶対値が低いのは評価の問題も含まれますが、(precisionと比べて)相対的に低い傾向にあるのはそれだけが原因ではない(むしろそこがポイントではない)と考えられます。
2つ目の実験では、先ほどまでとは少し見方を変えて、アノテータ数=10の限りなく真の値に近い設定(評価側の問題を限りなく取り除いた上)で、それでもFalse Negativeになっているケースを今のGECにとっての"difficulty"だと仮定し、このようなdifficultyを解決するにはどのような情報があれば解けるのか?といった視点で分析してみます。調査方針および実験設定を以下の通りです。
調査方針
False Negativeに対して、「どのような情報があれば誤りだと検知できるか」といった観点で以下の5つのラベルを定義し、人手で分類。
- Local context is required(文内文脈が必要なもの)
- Global context is reqired(文外文脈が必要なもの)
- External knowledge is required(外部知識が必要なもの)
- It's not an error(そもそも誤りではないもの)
- Others(その他)
実験設定
- データ: CoNLL-10
- GECシステム: Ge et al. (2018)
- 対象とする誤りタイプ: ArtOrDet、 Nn、 Prep、SVA、Vfomの計5種類
- アノテータ数: 2名(*)
- 誤り数は以下の内訳で合計546個
| ArtOrDet | Nn | Prep | SVA | Vform | Total | |
|---|---|---|---|---|---|---|
| # erros | 224 | 81 | 149 | 40 | 52 | 546 |
*私と当時修士の学生(浅野君)の2名
結果
アノテーション結果は以下のようになります。なお、Inter-Annotator Agreementは0.716でした。
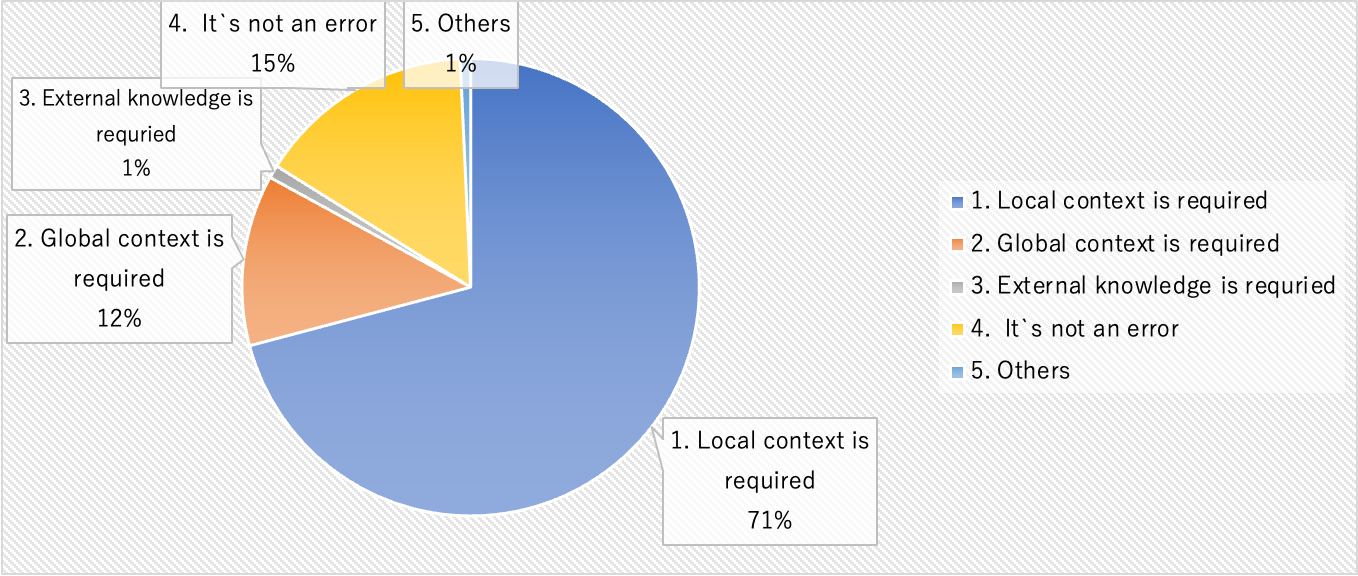
この結果をざっくりまとめると...
- 現行のモデルで解けそうなもの[1]: 71%
- 現行のモデルで原理的に解くのが難しそうなもの[2,3]: 13%
- 評価の問題によるもの[4]: 15%
という感じでしょうか(本当にざっくりですが)。あくまで今回対象とした5種類に限定した話になりますが、現行の方向性(文外文脈や外部知識を明示的に考慮しないない, 参照あり評価..etc)のままだと、見かけの数値上まだ解けていない問題(difficulty)の中の3割くらいは理論上解けない可能性があり、このあたりがGECのLow recall問題に関わっていそうだなという感じがします。とはいえ、見方を変えるとまだ7割も今の方向性でも改善をしていければいずれ解けるようになりそう(より正確にいうと誤りの検知ができるようになりそう)という見通しも同時に立ちます。実際、特に外部知識や文外文脈を明示的に考慮していないという意味でこの当時のモデルと変わらない最近のモデルたちもこのときと比べると着実に性能が上がってきています。
アノテーション例
最後に、アノテーション結果の実例(と雑感)をいくつか紹介します。
(1) Local context is required
From the example that I have mentioned earlier we can see that distance between us and our loved one [are → is] getting further apart.
=> subjectとverbの距離が離れていて、かつ 直前に「us and our loved one 」と並列表現がきていて難しそう
(2) Global context is required
On the other hand, there are also problems with the population of the social media.
=> 「social media」がFacebookやTwitterなどある特定を指している場合は theが必要だが文内の情報だけだと判別できない
(3) External knowledge is required
The notion of authority also [extended → extends] vertically.
=> 人間なら「この文はおそらく一般論だから現在形が自然」のような知識に基づく推論で訂正できる誤りを見逃している。
(というメモのもと当時は3に分類していたっぽいが、今改めて見ると2の可能性もあるような...英語難しい;)
(4) It's not an error
It is quite significant especially for those young teenagers since they would rather go to these sites to see the news and know what happened in [this → the] world than read the newspaper every day.
=> 「this」より「the」のほうがfluentなのかもしれないが文法的に誤りとは言えないはず
おわりに
当時学生にアノテーションを付き合ってもらったにも関わらず結局お蔵入りしてしまってことに対して若干の申し訳なさがあったので、今回このような形で成仏?できてよかったです。それと、今回の記事を書きながら改めて思いましたが、やはり「現在の(真の)到達点」は定期的に知りたくなるので、Bryant ans Ng. (2015)のCoNLL-10でも評価しないとだめだよなと思った次第でした(自戒も込めて...)。NLP-progressでも一応項目はあるようですがほとんど更新されていない...。