GoogleCloudが買収したことで巷を賑わせているDataform。
しかも、完全無料で利用できるらしい。。
Dataform が Google Cloud の傘下に: BigQuery で SQL を使用してデータ変換をデプロイする
年末の大掃除の合間をぬってBQML用のパイプラインを構築してみた内容をまとめて行こうと思います。

Dataformとは?
データパイプライン構築&スケジューリングツール的な感じです。(使ってみた感じ)
ジョブスケジューリングツールで言うと、最近はAirflow界隈が名前が上がってきますかね。クラウドサービスだと、GCPのCloud Composer、AWSならMWAA(Amazon Managed Workflows for Apache Airflow)と続々とマネージドが発表されていますね。
これらと比較するとスケジューリングという点では共通ですが、DataformはELT処理のTransformに特化したツールです。データウェアハウスに突っ込んだデータをSQLでごりごり加工していく、さらに依存関係の解釈や可視化など**「ELTでの痒いとこに手が届くような機能」**があったりといったところが大きな違いかと思います。
やってみたストーリー
Step1. MovieLensのデータからテーブルを作成
Step2. BQMLのMatrixFactorizationのモデルを作成
Step3. モデルから全ユーザーと全映画の評価値を予測を毎日実行する
上記を日次バッチでうがしてみようと思います。
結論
BQMLでのMatrixFactorizationのモデル構築がうまくいきませんでした。
要因としては、Dataform側でSQLをビルドしてエラー検出をしてくれるのですが、BQMLの文法は一般的なSQLの構文と多少異なるためその点でエラー扱いになりうまく実行されないと言うオチでした。。

Step1. MovieLensのデータからテーブルを作成
実際にはratingsテーブルでBQMLは実行できるのですが、Dataformの依存関係の解釈や可視化がどのような形になるかみたいので作成してみます。
投入済みテーブルの参照設定
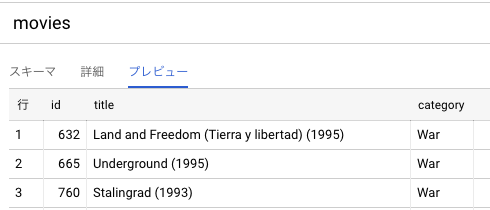
あらかじめ投入しているテーブルは下記になります。
また、Dataformで依存関係の解釈に必要なテーブルをsqlxファイルに定義しておきます。
- qiita_test.movies
config {
type: "declaration",
database: "****",
schema: "qiita_test",
name: "movies"
}
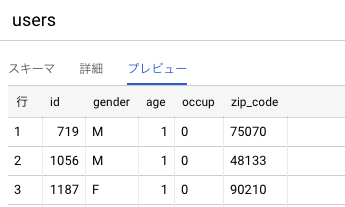
- qiita_test.users
config {
type: "declaration",
database: "****",
schema: "qiita_test",
name: "users"
}
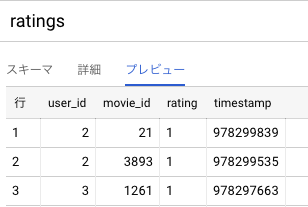
- qiita_test.ratings
config {
type: "declaration",
database: "****",
schema: "qiita_test",
name: "ratings"
}
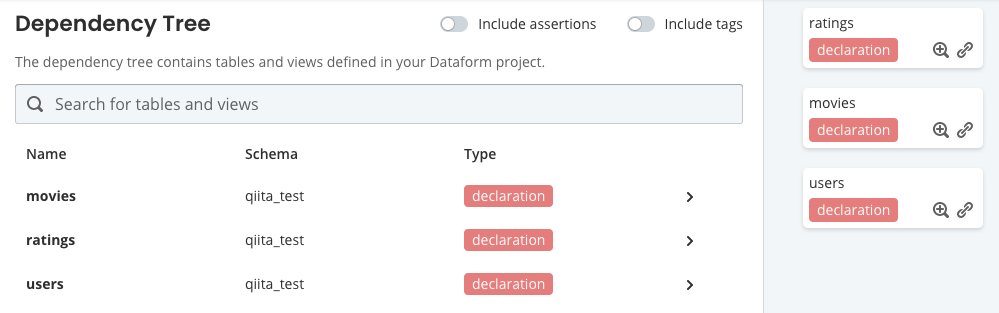
このようにsqlxを作成することで「Dependency Tree」に表示されます。
ビューの作成
上記のテーブルからratingsとusersをidで結合したratings_usersをビューとして作成します。
definitionsにsqlxファイルで定義しておくと${ref()}で参照できるようになります。
ビューの作成ではsqlxのconfigにtype: "view"を設定します。
このファイルに記載したSQLでビューが作成されます。
config {
type: "view",
schema: "qiita_test"
name: "ratings_users"
}
SELECT
a.user_id,
b.gender,
b.age,
a.movie_id,
rating
FROM
${ref("ratings")} AS a
INNER JOIN ${ref("users")} AS b ON a.user_id = b.id
テーブルの作成
テーブルはtype: "table"を設定します。
先ほど定義したqiita_test.ratings_usersは${ref("ratings_users")}で参照可能になっています。このテーブルではratings_usersビューにmoviesテーブルを結合して新たなテーブルを作成しています。
config {
type: "table",
name: "ratings_users_movies",
tags: "CREATE_TABLE2"
}
SELECT
a2.user_id,
a2.gender,
a2.age,
b2.id as movie_id,
b2.title,
b2.category,
CAST(a2.rating as FLOAT64) as rating
FROM
${ref("ratings_users")} AS a2
INNER JOIN ${ref("movies")} AS b2 ON a2.movie_id = b2.id
このように定義すると「Dependency Tree」は下記のようになります。
導出元がわかりやすくていい感じです。
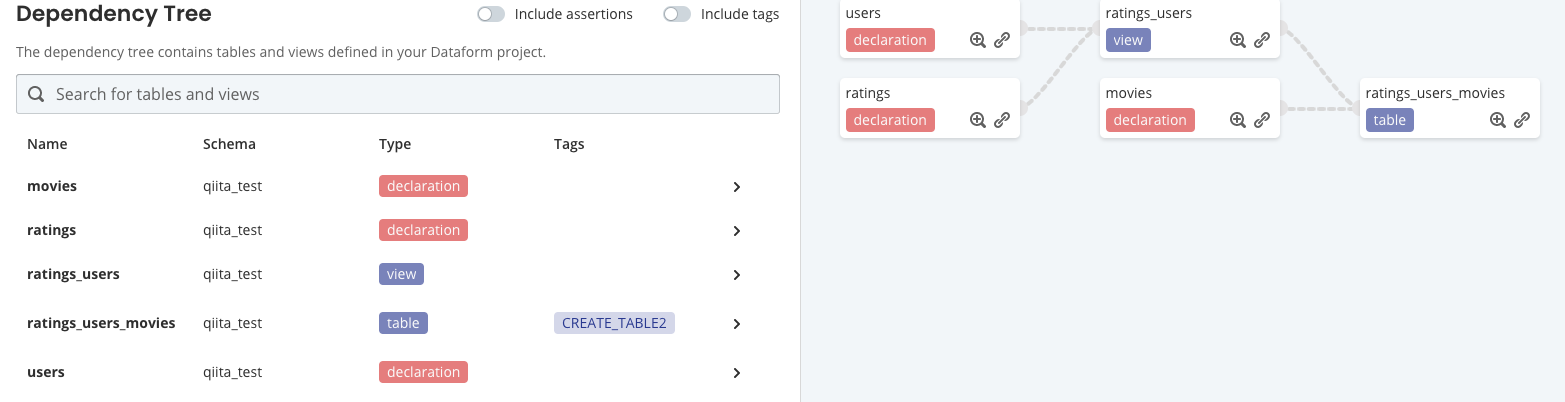
Step2. BQMLでMatrixFactorizationのモデルを作成
では、BQMLでモデルを作成してみます。今回はMatrixFactorizationでシンプルなモデル作成を記述します。
ここで気になったのがどうやってsqlxファイルでモデル作成を定義するかと言う点です。
現時点でファイルを作成しようとするとテンプレートでは、VIEW, TABLE, INCREMENTAL TABLE, ASSERTIONのこの4つです。
どれにも該当しなさそうなのでドキュメントを読んでみると、type: operationsで任意のSQLが実行できそうなのでこちら設定します。
https://docs.dataform.co/reference#IOperationConfig
config {
type: "operations",
schema: "qiita_test",
name: "mf_model",
tags: "CREATE_MF_MODEL",
hasOutput: true
}
CREATE OR REPLACE MODEL self() OPTIONS (
model_type = "matrix_factorization",
user_col = "user_id",
item_col = "movie_id",
l2_reg = 9.83,
num_factors = 24
) AS
SELECT
user_id,
movie_id,
CAST(rating as INT64) as rating
FROM
${ref("ratings_users_movies")}
ここでself()と記述すると、schemaとnameで設定した名称に置きかわります。
ここでは、MatrixFactorizationのモデルをqiita_test.mf_modelとして保存するように記述しました。
ここまでで「Dependency Tree」はこのようになります。
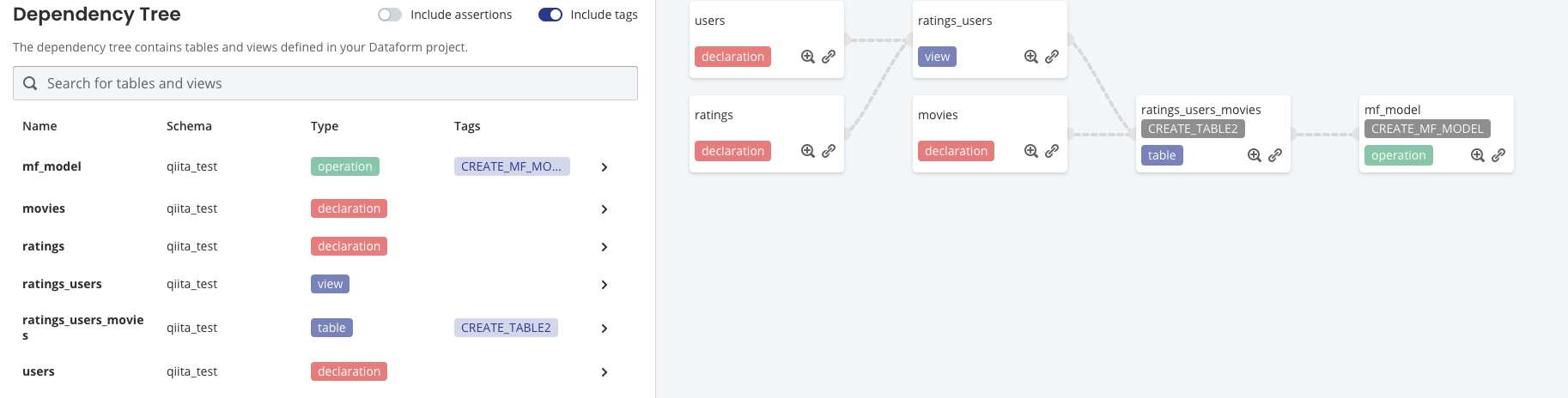
この図の「CREATE_TABLE2」や「CREATE_MF_MODEL」はタグになります。configのjsonの中でtags:に設定することができます。
このタグでスケジューリングするジョブを設定することが可能です。
こちらのSQLでは、${ref("ratings_users_movies")}というテーブルをモデル作成のデータ抽出元にしています。しかし、実際にはこのテーブルはまだ作成されていません。ただ、依存関係は存在するため画面上にはこのように表示されます。
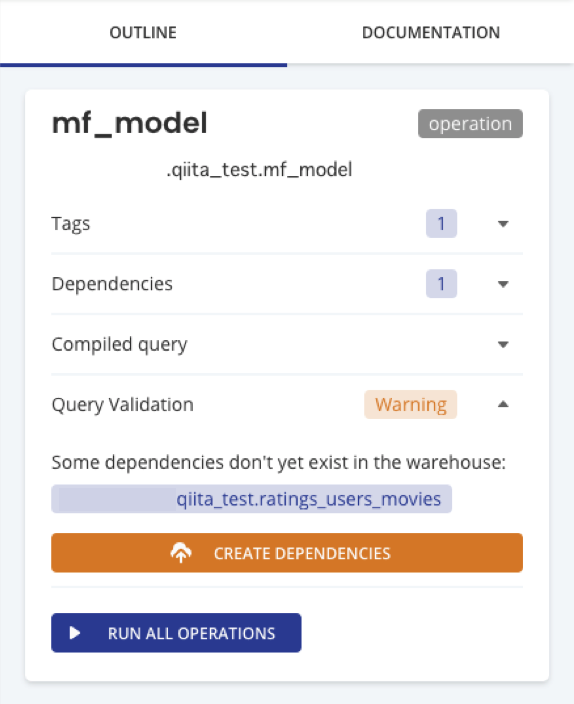
CREATE DEPENDENCIESをクリックするとこのSQL実行に必要な依存関係のあるテーブル作成を実行してくれます。これはとっても便利。
Step3. 全ユーザー×映画の評価値を予測を毎日実行する
モデル作成まで記述できたので最後に予測ジョブを定時実行させたいと思います。
予測結果のテーブル作成
予測ジョブは下記のように記述します。
config {
type: "table",
schema: "qiita_test",
name: "result_predict",
tags: "CREATE_PREDICT_RESULT"
}
SELECT
*
FROM
ML.PREDICT(MODEL ${ref("mf_model")},
(
SELECT
user_id,
movie_id,
FROM
${ref("all_users_movies")})
全てのユーザーと映画のidを入力するためのビューを作成します。
config {
type: "view",
schema: "qiita_test",
name: "all_users_movies"
}
SELECT
a.id as user_id, b.id as movie_id
FROM
${ref("users")} AS a CROSS JOIN ${ref("movies")} AS b
これで一通りの定義を作成できました。最終的な「Dependency Tree」がこちらになります。
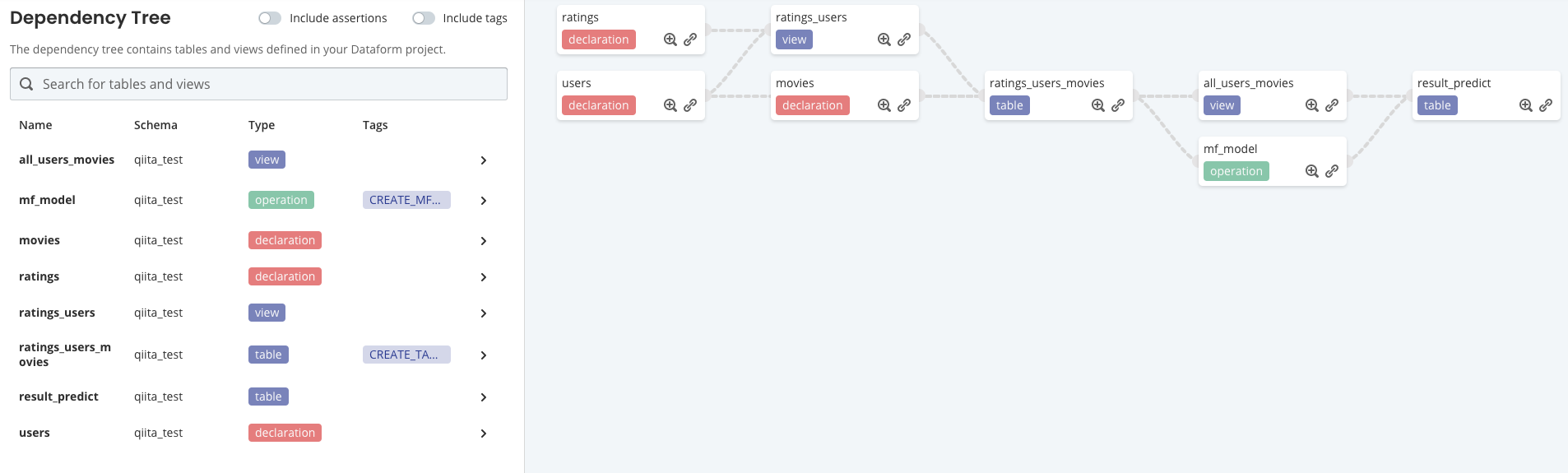
定時実行の設定
定時実行はデフォルト作成されているenviroments.jsonで定義します。
CREATE NEW SCHEDULEをクリックして、スケジュール名や実行時間及び実行対象のタグを指定します。
設定をjsonで表示すると、こんな感じです。イメージとしては、指定したタグまでの依存関係含めて実行してそれぞれのテーブルやビュー、モデルを作成しくれると嬉しいですね。
{
"environments": [
{
"name": "production",
"configOverride": {},
"schedules": [
{
"name": "CREATE_PREDICT_RESULT",
"cron": "0 0 * * *",
"tags": [
"CREATE_PREDICT_RESULT"
],
"options": {
"includeDependencies": true,
"includeDependents": true
}
}
],
"gitRef": "master"
}
]
}
定期実行の結果
あれ、、エラーだ。。Run logsで確認してみるとFailedの文字が。
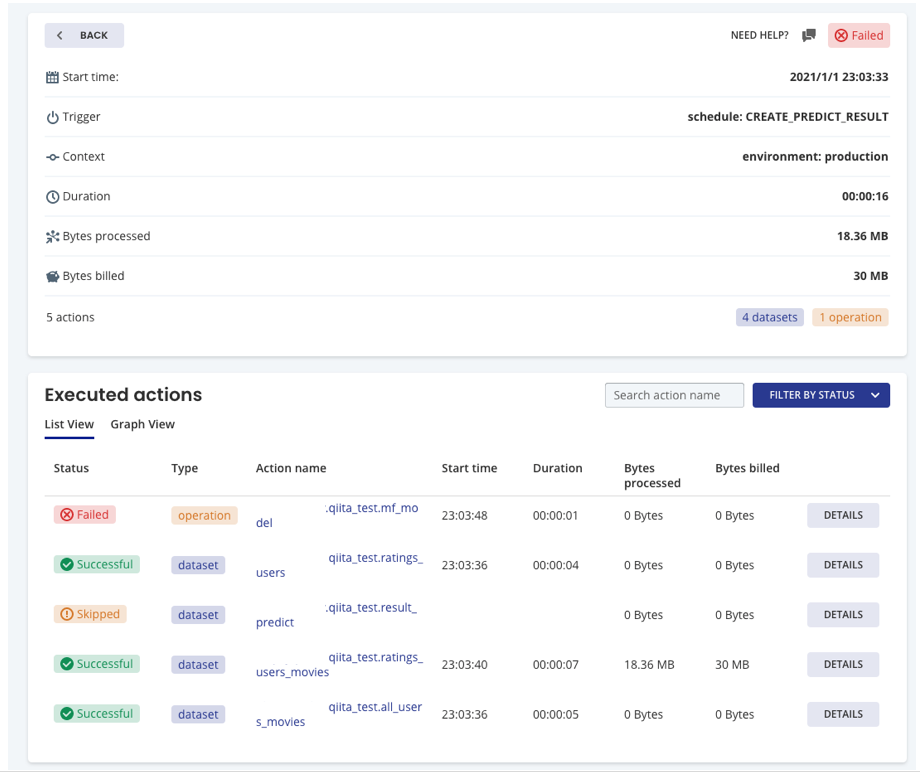
List ViewをGraph Viewに切り替えてみると。
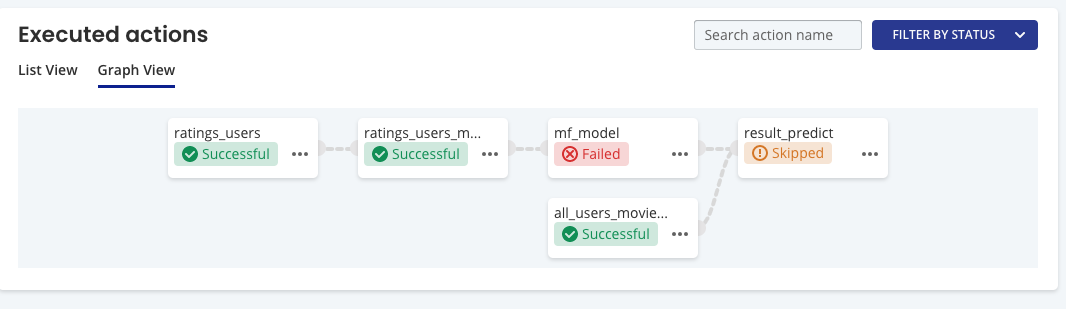
どこでジョブが失敗したか一目瞭然に。
MFモデルの作成を失敗して、結果出力の依存関係が成立せずスキップされた感じですね。
さらにFailedしたDetailsをクリックしてみると
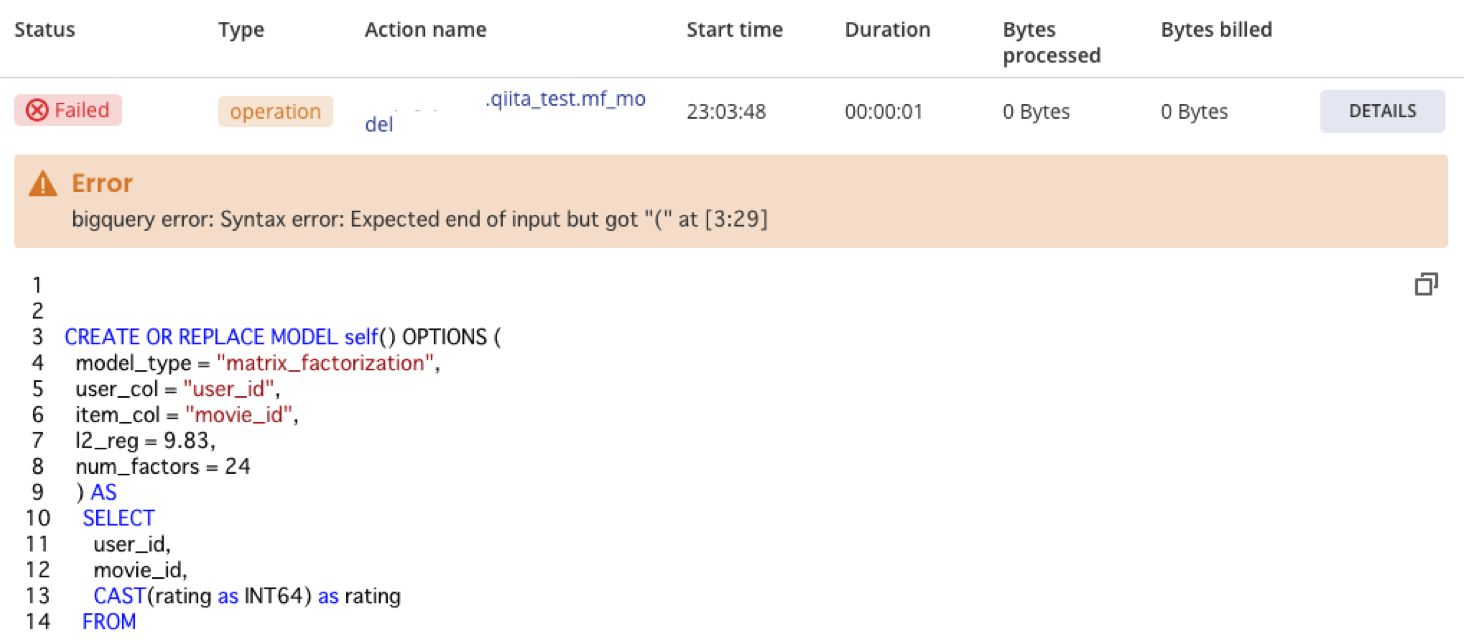
エラーを表示してくれます。
BigQueryUIでも確認したのでSQL表記には間違いなさそうですが、Dataform上ではエラーになってしまうみたいですね。非常に残念、これからのサポートに期待です。
先ほどは依存関係が成り立っていなかったので、そちらを優先してCREATE DEPENDENCIESが表示されていましたが、依存関係がなりたったあとだとクエリのビルドは失敗していました。
おわりに
BQMLを含んだデータパイプライン構築は失敗しましたが、依存関係の解釈や可視化, 定期実行の設定の簡単さなどは確認できたので非常にいい時間でした。
大規模なデータ分析基盤を運用していると、さまざなテーブルを作成して、導出元がよくわからなりカオスな状態になることが多いかと思います。
そこをDataformを使って依存関係の解釈や可視化を使って整理しやすくしたり、必要なテーブルやビューが作成され次第すぐにジョブが実行されるといった形にできると非常に便利だなと感じました。
年末年始の合間縫って触ってみましたが、今後の開発に非常に期待したくなるサービスでした。
今年も頑張りましょう!!
参考
すごいぞ Dataform
DataformでBigQueryのデータ変換を試してみた
DataformでBigQueryのデータパイプラインを構築する